# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
本论文作者来自华为蒙特利尔诺亚方舟实验室的康计堃,李信择,陈熙, Amirreza Kazemi,陈博兴。
人工智能(AI)在过去十年里取得了长足进步,特别是在自然语言处理和计算机视觉领域。然而,如何提升 AI 的认知能力和推理能力,仍然是一个巨大的挑战。
近期,一篇题为《MindStar: Enhancing Math Reasoning in Pre-trained LLMs at Inference Time》的论文提出了基于树搜索的推理时间能力提升方法 MindStar [1],该方法在开源模型 Llama-13-B 与 Mistral-7B 上达到了近似闭源大模型 GPT-3.5 与 Grok-1 在数学问题上的推理能力。

MindStar 在数学问题上的应用效果:
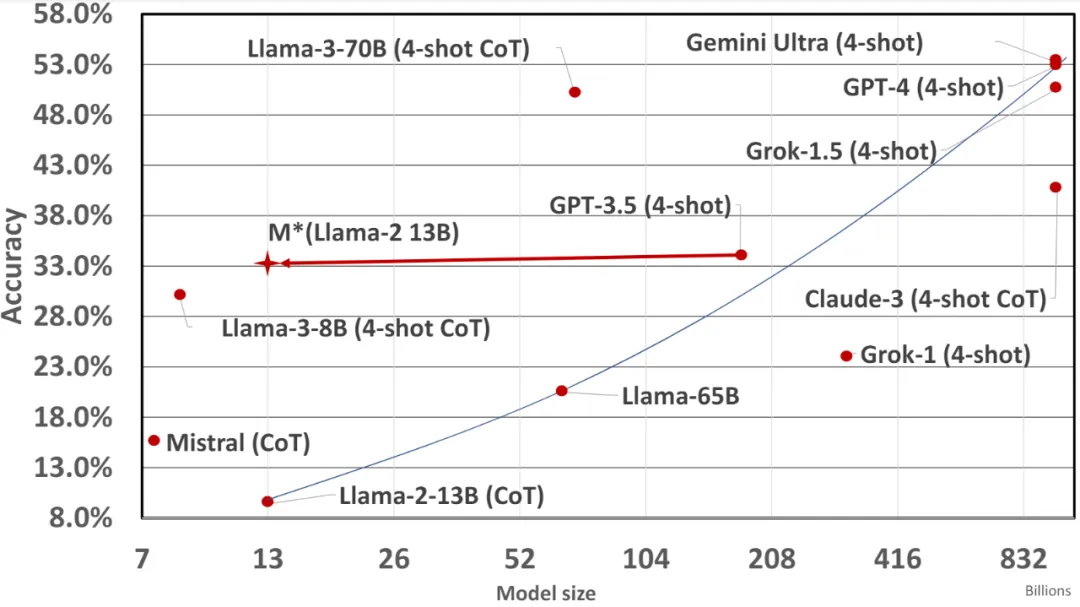
图 1 :不同大型语言模型的数学准确率。LLaMA-2-13B 在数学性能上与 GPT-3.5 (4-shot) 类似,但节省了大约 200 倍的计算资源。
1. 引言
随着模型规模的快速增长,基于 Transformer 的大型语言模型(LLMs)在指令遵循 [1,2]、编码辅助 [3,4] 和创意写作 [5] 等领域展示了令人印象深刻的成果。然而,解锁 LLMs 解决复杂推理任务的能力仍然是一大挑战。最近的一些研究 [6,7] 尝试通过监督微调(Supervised Fine-Tuning, SFT)来解决,通过将新的推理数据样本与原始数据集混合,使 LLMs 学习这些样本的底层分布,并尝试模仿所学逻辑来解决未见过的推理任务。尽管这种方法有性能提升,但它严重依赖于大量的训练和额外的数据准备 [8,9]。
Llama-3 报告 [10] 强调了一个重要的观察:当面对一个具有挑战性的推理问题时,模型有时会生成正确的推理轨迹。这表明模型知道如何产生正确答案,但在选择上存在困难。基于这一发现,我们提出了一个简单的问题:我们能否通过帮助 LLMs 选择正确的输出来增强它们的推理能力?为探索这一点,我们进行了一项实验,利用不同的奖励模型进行 LLMs 输出选择。实验结果表明,步骤级选择显著优于传统的 CoT 方法。
2. MindStar 方法
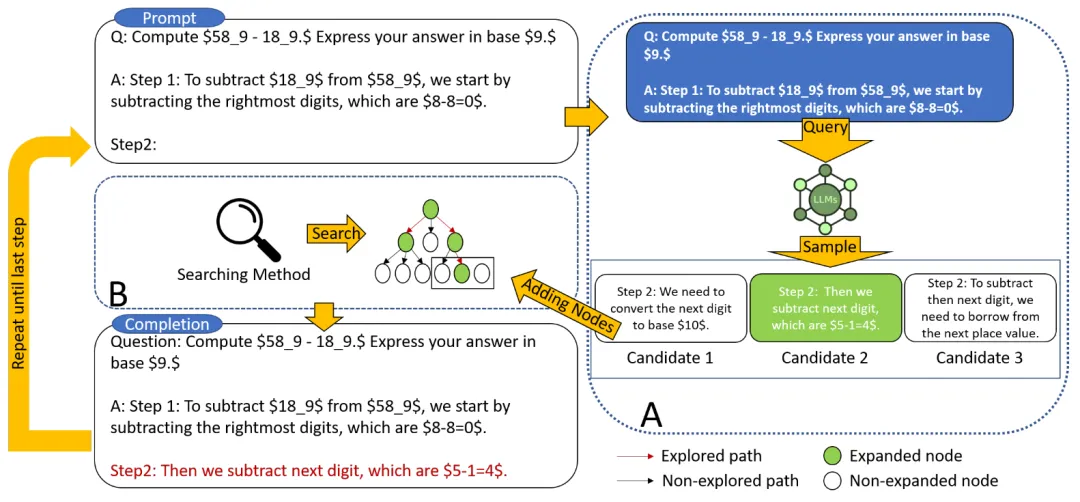
图 2 MindStar 的算法架构图
我们引入了一种新的推理搜索框架 ——MindStar(M*),通过将推理任务视为搜索问题,并利用过程监督的奖励模型(Process-supervised Reward Model, PRM),M * 在推理树空间中有效导航,识别近似最优路径。结合束搜索(Beam Search, BS)和 Levin 树搜索(Levin Tree Search, LevinTS)的思想,进一步增强了搜索效率,并保证在有限计算复杂度内找到最佳推理路径。
2.1 过程监督奖励模型
过程监督奖励模型 (PRM) 的设计目的是评估大语言模型 (LLM) 生成的中间步骤,以帮助选择正确的推理路径。这种方法借鉴了其他应用中 PRM 的成功经验。具体而言,PRM 以当前推理路径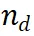 和潜在的下一步
和潜在的下一步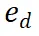 作为输入,并返回奖励值
作为输入,并返回奖励值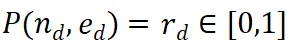 。
。
PRM 通过考虑整个当前推理轨迹来评估新步骤,鼓励与整体路径的一致性和忠实性。高奖励值表明,新的步骤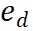 )对于给定的推理路径
)对于给定的推理路径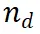 可能是正确的,从而使扩展路径值得进一步探索。相反,低奖励值则表示新步骤可能不正确,这意味着遵循此路径的解决方案也可能不正确。
可能是正确的,从而使扩展路径值得进一步探索。相反,低奖励值则表示新步骤可能不正确,这意味着遵循此路径的解决方案也可能不正确。
M* 算法包含两个主要步骤,迭代直到找到正确的解决方案:
1. 推理路径扩展:在每次迭代中,基础 LLM 生成当前推理路径的下一步。
2. 评估和选择:使用 PRM 评估生成的步骤,并根据这些评估选择下一次迭代的推理路径。
2.2 推理路径扩展

在选择要扩展的推理路径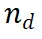 后,我们设计了一个提示模板(Example 3.1),以从 LLM 中收集下一步。正如示例所示,LLM 将原始问题作为 {question},将当前推理路径作为 {answer}。注意,在算法的第一次迭代中,所选择的节点是仅包含问题的根节点,因此 {answer} 为空。对于推理路径
后,我们设计了一个提示模板(Example 3.1),以从 LLM 中收集下一步。正如示例所示,LLM 将原始问题作为 {question},将当前推理路径作为 {answer}。注意,在算法的第一次迭代中,所选择的节点是仅包含问题的根节点,因此 {answer} 为空。对于推理路径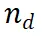 ,LLM 生成 N 个中间步骤,并将它们作为当前节点的子节点附加。在算法的下一步中,将评估这些新生成的子节点,并选择一个新的节点进行进一步扩展。我们还意识到,生成步骤的另一种方法是使用步骤标记对 LLM 进行微调。然而,这可能会降低 LLM 的推理能力,更重要的是,这与本文的重点 —— 在不修改权重的情况下增强 LLM 推理能力相悖。
,LLM 生成 N 个中间步骤,并将它们作为当前节点的子节点附加。在算法的下一步中,将评估这些新生成的子节点,并选择一个新的节点进行进一步扩展。我们还意识到,生成步骤的另一种方法是使用步骤标记对 LLM 进行微调。然而,这可能会降低 LLM 的推理能力,更重要的是,这与本文的重点 —— 在不修改权重的情况下增强 LLM 推理能力相悖。
2.3 推理路径选择
在扩展推理树后,我们使用预训练的过程监督奖励模型(PRM)来评估每个新生成的步骤。正如前面提到的,PRM 采用路径和步骤 ,并返回相应的奖励值。在评估之后,我们需要一种树搜索算法来选择下一个要扩展的节点。我们的框架不依赖于特定的搜索算法,在这项工作中,我们实例化了两种最佳优先搜索方法,即 Beam Search 和 Levin Tree Search。
3. 结果与讨论
在 GSM8K 和 MATH 数据集上的广泛评估显示,M * 显著提升了开源模型(如 LLaMA-2)的推理能力,其表现可与更大规模的闭源模型(如 GPT-3.5 和 Grok-1)媲美,同时大幅减少了模型规模和计算成本。这些发现突显了将计算资源从微调转移到推理时间搜索的潜力,为未来高效推理增强技术的研究开辟了新途径。
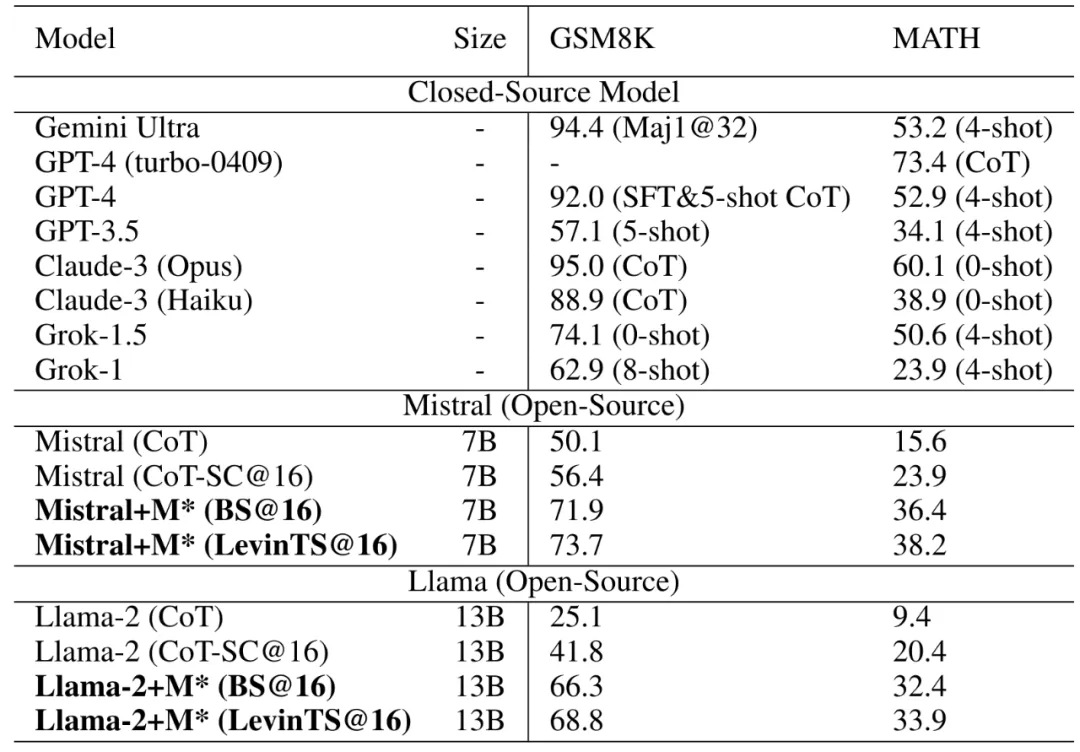
表 1 展示了各种方案在 GSM8K 和 MATH 推理基准上的对比结果。每个条目的数字表示问题解决的百分比。符号 SC@32 表示在 32 个候选结果中的自一致性,而 n-shot 表示少样本例子的结果。CoT-SC@16 指的是在 16 个思维链(CoT)候选结果中的自一致性。BS@16 代表束搜索方法,即在每个步骤级别涉及 16 个候选结果,而 LevinTS@16 详细说明了使用相同数量候选结果的 Levin 树搜索方法。值得注意的是,MATH 数据集上 GPT-4 的最新结果为 GPT-4-turbo-0409,我们特别强调这一点,因为它代表了 GPT-4 家族中的最佳性能。
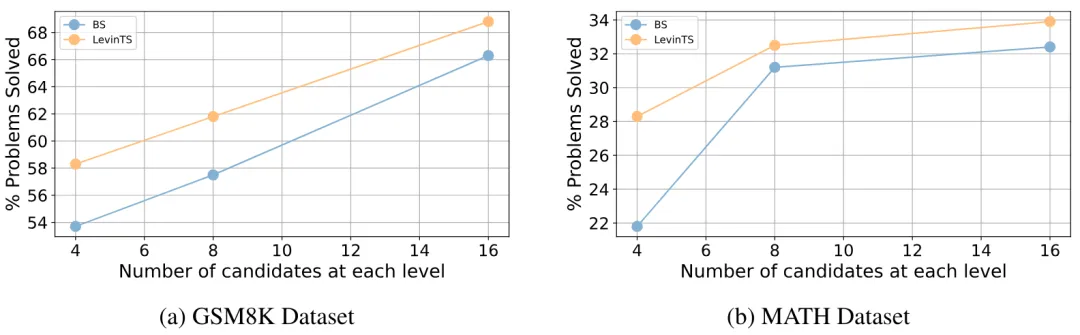
图 3 我们研究了 M * 性能如何随着步骤级别候选数量的变化而变化。我们选择 Llama-2-13B 作为基础模型,并分别选择束搜索(BS)作为搜索算法。
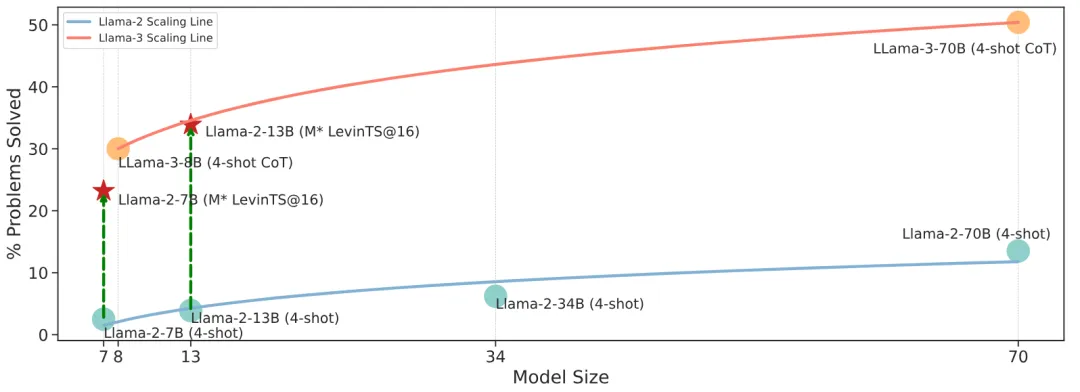
图 4 Llama-2 和 Llama-3 模型家族在 MATH 数据集上的尺度定律。所有结果均来自它们的原始资源。我们使用 Scipy 工具和对数函数来计算拟合曲线。
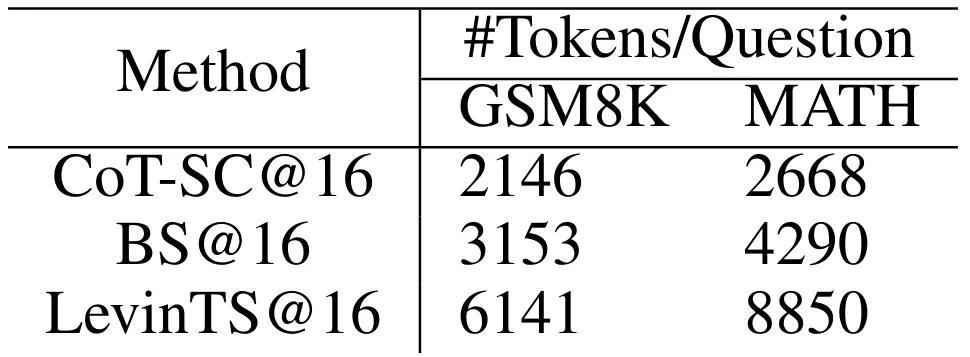
表 2 不同方法在回答问题时的平均 token 生产数量
4. 结论
本文介绍了 MindStar(M*),一种新颖的基于搜索的推理框架,用于增强预训练大型语言模型的推理能力。通过将推理任务视为搜索问题并利用过程监督的奖励模型,M* 在推理树空间中有效导航,识别近似最优路径。结合束搜索和 Levin 树搜索的思想,进一步增强了搜索效率,并保证在有限计算复杂度内找到最佳推理路径。广泛的实验结果表明,M* 显著提升了开源模型的推理能力,其表现可与更大规模的闭源模型媲美,同时大幅减少了模型规模和计算成本。
这些研究成果表明,将计算资源从微调转移到推理时间搜索具有巨大的潜力,为未来高效推理增强技术的研究开辟了新途径。
文章来源于“机器之心”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
