# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
沉睡了两千多年的兵马俑,苏醒了?

一句秦腔开场,将我们带到了黄土高原。如果不是亲眼所见,很多观众可能难以想象,有生之年还能看到兵马俑和宝石 Gem 同台对唱《从军行》。
「青海长云暗雪山,孤城遥望玉门关。」古调虽存音乐变,声音依旧动人情:

这场表演背后的「AI 复活召唤术」,叫做 EMO,来自阿里巴巴通义实验室。仅仅一张照片、一个音频,EMO 就能让静止形象变为惟妙惟肖的唱演视频,且精准卡点音频中的跌宕起伏、抑扬顿挫。
在央视《2024 中国・AI 盛典》中,同样基于 EMO 技术,北宋文学家苏轼被「复活」,与李玉刚同台合唱了一曲《水调歌头》。「AI 苏轼」动作古朴自然,仿佛穿越时空而来:

在 EMO 等 AI 领域前沿技术的激发下,首个以人工智能为核心的国家级科技盛宴《2024 中国・AI 盛典》盛大开幕,以「媒体 + 科技 + 艺术」的融合形式将最前沿的国产 AI 技术力量传递给节目前的每一位观众:

这不是 EMO 第一次「出圈」。曾在社交媒体爆火的「高启强化身罗翔普法」,也是出自 EMO 之手:
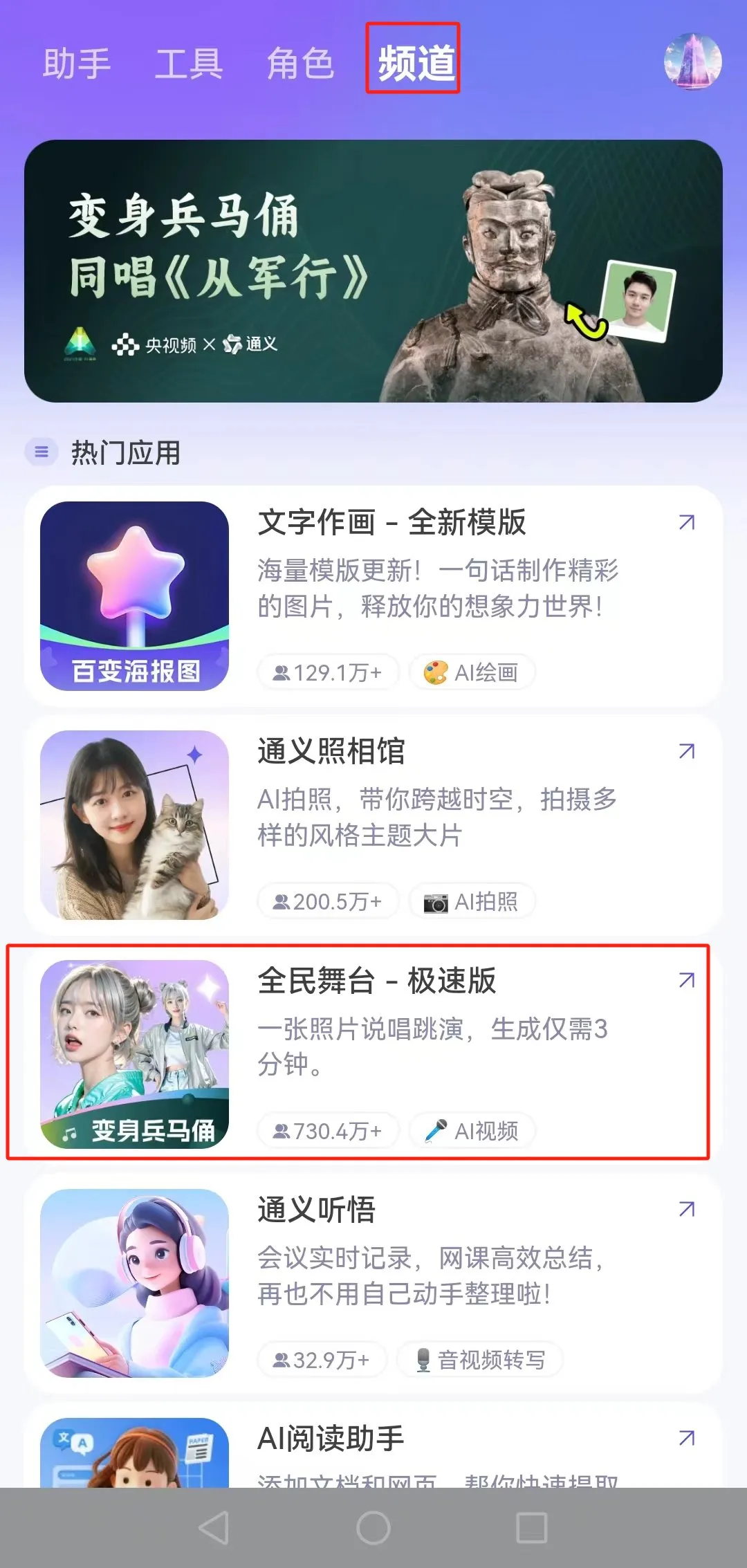
登陆通义 APP 之后,借助玩家各种脑洞大开的试玩,EMO 火热程度至今不减。还没有尝试的小伙伴可以前去下载这款应用,进入「频道」选择「全民舞台」,就可以丝滑体验了。
实际上,早在今年 2 月,通义实验室就公开了 EMO(Emote Portrait Alive) 相关论文。这篇论文上线之初就好评如潮,更是有人称赞:「EMO 是一项革命性的研究。」

为什么它能获得如此高度的评价?这还要从当前视频生成技术的发展现状和 EMO 的底层技术创新说起。
如此出圈,EMO 凭什么?
过去几年,AI 在图像生成方面的成功是有目共睹的。当前,AI 领域的研究热点是攻克一个更困难的任务:视频生成。
EMO 面对的恰好是其中非常难的一项任务:基于音频驱动的人物视频生成。
不同于常见的文生视频和图生视频玩法,基于音频驱动的人物视频生成是一个从音频直接跨越到视频模态的过程。这类视频的生成往往涉及头部运动、凝视、眨眼、唇部运动等多个要素,且要保持视频内容的一致性和流畅度。
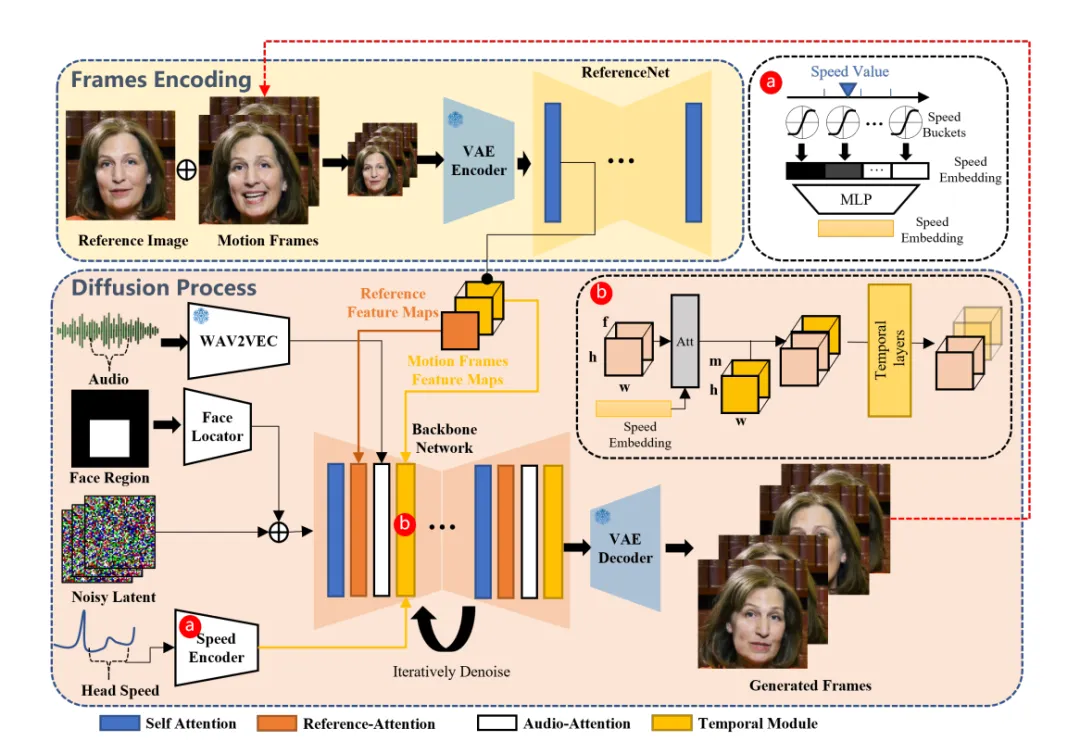
在此前的方法中,模型大多先针对人脸、人头或者身体部分做 3D 建模或人脸关键点标记,以此作为中间表达再生成最终的视频。但借助中间表达的方法可能会导致音频中的信息被过度压缩,影响最终生成视频中的情绪表达效果。
通义实验室应用视觉团队负责人薄列峰表示,EMO 的关键创新点「弱控制设计」很好地解决了上述问题,不仅降低视频生成成本,还大幅提升了视频生成质量。

「弱控制」体现在两个方面:首先,EMO 无需建模,直接从音频中提取信息来生成表情动态和嘴唇同步的视频,从而在不需要复杂预处理的情况下,端到端地创造出自然流畅且表情丰富的人像视频。其次,EMO 对生成表情和身体动作不做过多「控制」,最终生成结果的自然和流畅,都是源于模型本身对高质量数据的学习而训练出的泛化能力。
拿兵马俑和宝石 Gem 同框对唱《从军行》来说,歌声中所要传达的情绪(如激扬)在其面部得到了很好的展现,不会给人违和感:

基于弱控制的理念,研究团队为 EMO 模型构建了一个庞大而多样的音视频数据集,总计超过 250 小时的录影和超过 1.5 亿张图像,涵盖各种内容,包括演讲、电影和电视片段以及歌唱表演,包括中文和英文在内的多种语言,视频的丰富多样性确保了训练材料捕捉了广泛的人类表达和声音风格。
学界有一种观点是,对于一个数据集最好的无损压缩,就是对于数据集之外的数据最佳泛化。能够实现高效压缩的算法往往能够揭示数据的深层规律,这也是智能的一个重要表现。
因此,团队在训练过程中设计了高保真数据编码算法,保证了在压缩或处理数据的过程中,尽可能保持原始信息的丰富细节和动态范围。具体到 EMO 的训练上,只有音频信息完整,人物情绪才能很好的展现。
视频生成赛道风起云涌
通义实验室如何跻身全球第一梯队?
今年 2 月初,Sora 的发布点燃了视频生成赛道,背后的多项技术随之受到关注,其中就包括 DiT(Diffusion Transformer )。
我们知道,扩散模型中的 U-Net 能模拟信号从噪声中逐渐恢复的过程,理论上能够逼近任意复杂的数据分布,在图像质量方面优于生成对抗网络(GAN)和变分自编码器(VAE),生成具有更自然纹理和更准确细节的现实世界图像。但 DiT 论文表明,U-Net 归纳偏置对扩散模型的性能并非不可或缺,可以很容易地用标准设计(如 Transformer)取代,这就是该论文提出的基于 Transformer 架构的新型扩散模型 DiT。
最重要的是,以 DiT 为核心的 Sora 验证了视频生成模型中仍存在 Scaling Law ,研究者们可以通过增加更多的参数和数据来扩大模型规模实现更好的结果。
DiT 模型在生成真实视频方面的成功,让 AI 社区看到了这一方法的潜力,促使视频生成领域从经典 U-Net 架构转变到基于 Transformer 的扩散主干架构的范式。基于 Transformer 注意力机制的时序预测、大规模的高质量视频数据都是推动这一转变的关键力量。
但纵观当前的视频生成领域,尚未出现一个「大一统」架构。
EMO 并不是建立在类似 DiT 架构的基础上,也就是没有用 Transformer 去替代传统 U-Net,同样能够很好地模拟真实物理世界,这给整个研究领域带来了启发。
未来,视频生成领域会出现哪些技术路线?不管是理论研究者还是从业者,都可以保持「相对开放的期待」。
薄列峰表示,本质上,当前的语言模型、图像 / 视频生成模型都没有超越统计机器学习的框架。即使是 Scaling Law ,也有自身的限制。尽管各个模型对强关系和中等关系的生成把握比较精准,但对弱关系的学习仍然不足。如果研究者们不能持续提供足够多的高质量数据,模型的能力就难以有质的提升。
换个角度来看,即使视频生成领域会出现一种「占据半壁江山」的大一统架构,也并不意味其具备绝对的优越性。就像是自然语言领域,一直稳居 C 位的 Transformer 也会面临被 Mamba 超越的情况。
具体到视频生成领域,每种技术路线都有适合自身的应用场景。比如关键点驱动、视频驱动更适合表情迁移的场景,音频驱动更适合人物讲话、唱演的场景。从条件控制的程度来说,弱控制的方法很适合创意类任务,同时很多专业、具体的任务更能受益于强控制的方法。
通义实验室是国内最早布局视频生成技术的机构之一,目前已有文生视频、图生视频等多个方向的研发积累,特别是在人物视频生成方面,已经形成了包括人物动作视频生成框架 Animate Anyone、人物换装视频生成框架 Outfit Anyone、人物视频角色替换框架 Motionshop、人物唱演视频生成框架 Emote Portrait Alive 在内的完整研究矩阵。
更多项目请关注:https://github.com/HumanAIGC
比如在 EMO 之前,Animate Anyone 一度霸屏社交媒体和朋友圈。该模型解决了人物运动视频生成中保持人物外观短时连续性和长时一致性的问题,随后上线通义 App「全民舞王」功能,掀起了一波全民热舞小高潮。

从技术到现实世界
过去两年,语言模型展现了强大的对话、理解、总结、推理等文本方面的能力,图像生成模型展现了强大的自然生成、娱乐和艺术能力,两大赛道都诞生了很多爆款产品。这些模型的成功至少告诉我们一点:想在这个时代取得影响力的技术团队,需要学会「基础模型」和「超级应用」两条腿走路。
目前,视频内容呈现爆发式增长的趋势,人们都在期待能够出现一个人人「可用」且「实用」的 AI 视频生成平台。EMO 可能是打破这一局面的重要技术突破,通义 App 则提供了一个技术落地的广阔平台。
视频生成技术的下一个挑战,是如何攻克专业级的内容。
科技公司们希望将 AI 技术转化为真正的生产力工具,去服务短视频博主、影视制作人、广告和游戏创意人。这也是为什么视频生成应用不能只停留在「通用内容」的水准。
环顾目前大部分的视频生成应用,大多是基于 3 到 5 秒的视频生成模型,在应用和体验上的限制比较明显。但 EMO 技术对于音频时长的包容度很高,而且生成内容质量可以达到演播标准。比如登陆央视的这段「兵马俑唱演」,全程四分钟的兵马俑部分表演视频无一秒需要人工后期针对性「微调」。
如今看来,以 EMO 为代表的人物视频生成技术是最接近「专业级生成水准」的落地方向之一。相比于文生视频技术中用户 Prompt 存在的诸多不确定性,EMO 技术高度符合人物视频创作对内容连贯性和一致性的核心需求,展示了极具潜力的应用空间。
EMO 之所以「出圈」,人们看到的不光是研发团队的技术实力,更重要的是看到了视频生成技术落地的加速度。
「人均专业创作者」的时代,或许不远了。
文章来源于“机器之心”,作者“关注大模型的”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
