# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
随着 AI 工具的不断增多,各家模型的能力也日益提升,现在无论哪款大模型几乎都能够处理各种翻译难题。
在AI浪潮当下,越来越多的论文和前沿信息需要快速翻译和解读,依赖传统的翻译工具依旧面临“翻译质量不稳定、速度慢、费用高且难以准确理解上下文”的问题。
相比之下,AI大模型凭借其强大的学习能力和适应性,在翻译质量、效率、上下文理解和多语言支持等方面表现出色,提供了更加智能和高效的翻译体验。

本次我们将从经典文本、专业文献翻译和日常生活三大类别出发,对八款AI大模型的翻译能力进行全面测评,八款大模型分别如下ChatGPT-4o、豆包、Kimi、腾讯元宝、通义千问、文心一言、讯飞星火和智谱清言,重点关注它们在不同翻译场景下的表现。
注:本次测评包含了翻译的各种场景、测评结果与点评。全文较长,读者可以参考以下文章结构,进行文章阅读。
(1)题目设计:测评包含经典诗歌到专业资格考试题目、日常生活等场景。由浅入深全方位涵盖大部分的实际应用场景。
(2)评分标准:共10题,每题10分(根据测评的5个维度进行评分),总分100分。
(3)测评维度:本次测评标准涵盖了准确性、流畅性、文化差异处理、速度与效率、用户体验五大方面。每个方面都有具体的评分项和权重设置,确保测评结果的客观性和全面性。

(4)评审团: 专业翻译人员、资深AI爱好者、媒体内容从业者。
我们设计了十道评测题目,内容涵盖了经典诗歌、专业资格考试和日常生活等翻译场景。每一道题目都经过精心挑选,代表了特定的翻译难点和应用场景。
第1题:文言文翻译
文言文是中文体系中最为复杂的语言形式,这对模型的翻译能力是一个巨大的挑战。不仅需要先将其翻译为现代汉语,还要在此基础上进行外文翻译,难度更是进一步提升。
测试方法:由此我们从中国经典文言文中选择大家都很熟悉的《出师表》(诸葛亮),这部分主要考察模型对古文理解、翻译的准确性和文言韵味的保留。
原始 prompt:
请把这篇【《出师表》】翻译成英文,保留原来的人名、地名、术语等内容。
具体模型表现选评:
ChatGPT-4o 对《出师表》的翻译整体表现优秀。译文准确、流畅,基本符合专业文本的翻译要求。虽然在文学性和文言韵味的传达上有所欠缺,但整体上仍能较好地传达原文的主要信息和情感。某些细节和深层次的文化含义可能在翻译过程中略有遗失。例如,“今天下三分,益州疲弊,此诚危急存亡之秋也”这句中的复杂关系翻译得比较直白,缺少了一些原文的深意。

ChatGPT-4o
腾讯元宝:译文语言尽量接近文言文的文体形式,主要采用短句和简单句,使用较多的插入语,使英文文本与文言文语言形式一致。译文能够相对准确地传达原文本的信息,几乎没有出现错译现象。

腾讯元宝
讯飞星火:译文文本流畅,符合英文表达习惯,没有明显的语义和语法错误,能正确译出“两汉”,并使用较多语义连接词语和结构,增加译文的可读性,符合英文语言表达规范。

讯飞星火
翻译专家综合点评:
文言文翻译的难点在于对原文逻辑的理解和断句,在这方面各个模型都有错误。例如“今天下三分,益州疲弊,此诚危急存亡之秋也”一句中,许多模型把“此诚危急存亡之秋也”的逻辑关系搞错,翻译成益州疲弊的结果或并列关系。此外,诸葛亮年代“两汉”这个词有的模型采取了直译。总体来说,腾讯元宝、讯飞星火、ChatGPT-4o在逻辑性和断句方面的翻译效果更好,错误较少。
得分排名前三的是:

第2题:翻译诗词歌赋
中国的诗词歌赋讲究韵律美、讲究意境美,除了需要翻译出直白的意思之外,还讲究英文翻译的更“美”,尤其是古诗词结尾的押韵。
测试方法:选取《静夜思》(李白),考察模型对诗词意境、韵律的把握和翻译的美感。
原始 prompt:
请把这篇【古诗《静夜思》】翻译成英文,保留原来的人名、地名、术语等内容。
【静夜思
李白〔唐代〕
床前明月光,疑是地上霜。
举头望明月,低头思故乡。】
具体模型表现选评:
在诗歌翻译中,准确传达原诗的主题和情感,以及保持诗歌的韵律和美感,是翻译的难点。虽然所有模型基本翻译出了诗歌的意思,但在细节处理和韵律保持上存在差异。
腾讯元宝:使用有韵律的语言表现诗歌形式,尽量保留了原诗的风格特点。通过简单词汇和对仗的文本实现音韵统一,赋予译本诗意美感。
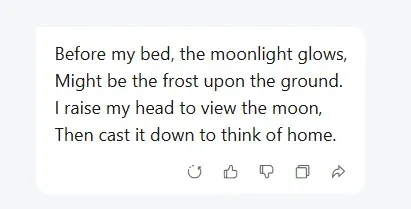
腾讯元宝
ChatGPT-4o:能够完整译出原诗的主题和情感,传达思乡的文化内涵。用词精准,使用语义连接词语增加上下文的连贯性,译文保留了原诗的节奏和韵律,读起来有抑扬顿挫的语言美感。

ChatGPT-4o
Kimi:注重诗歌的押韵和意境,保持了中英文的韵律一致,如“bright/night”和“above/rove”。

Kimi
翻译专家综合点评
整体来看,所有模型基本翻译出了诗歌的意思,除了极个别误解了“疑是地上霜”中“疑是”的意思。诗歌翻译的难点在于既要传达诗歌的意境,又要兼顾诗歌的韵律。例如,“望明月”的“望”如果仅仅翻译成“see”或“view”就没有体现其内在的意思。综合以上情况, Kimi、腾讯元宝、ChatGPT-4o 在选词和韵律保持上做得较好。
得分排名前三的是:

古典小说因其丰富的情节和复杂的人物关系而闻名,翻译这些作品要求对文化背景和细腻描写有深入理解。此外,小说的语言风格和人物对话的真实性也是翻译中的难点。
测试方法:
原始 prompt:
请把经典片段【选自《红楼梦》第三回,人民文学出版社1957年版】翻译成英文,注意对人物刻画的理解和语境的翻译。(字数较多,此处省略)
具体模型表现选评::
本题需要精准传达原文的语境和人物刻画、对古代服饰及配饰的翻译尽量准确,同时具有一定的文学韵味。
文心一言:小说选段的故事连贯性较强,人物外貌描述逻辑性强,但词藻堆砌略显晦涩。对话和语气基本能够转达人物的行为和性格特点。

文心一言
智谱清言:流畅性和可读性较强,人物外貌描述易懂。人物对话流畅,有助于推进故事情节发展和体现人物性格特点,是相对较好的译文。

智谱清言
通义千问:在处理王熙凤服饰的复杂描写时,采用了分号罗列的形式,没有很好地体现层次感。读起来较累,但对信息进行了归纳梳理,选用了排比句式,描述服饰时比较朗朗上口。

通义千问
翻译专家综合点评:
各模型尽管都能基本传达原文的信息,但在人物外貌描述和服饰描写方面存在差异。但在处理王熙凤复杂服饰描写时,普遍采用分号罗列形式,缺少层次感,读起来较累。综合来看,智谱清言、文心一言、腾讯元宝在信息归纳和排比句式的使用上较为出色,描述服饰时读起来朗朗上口,提升了可读性。
得分排名前三的是:

除了对中国经典文本进行中译英之外,还有英译中,这对模型的翻译能力提出了更高的要求。外国文学作品在语言表达、文化背景和思想内涵上与中文存在很大差异,因此,模型需要具备强大的跨文化理解和翻译能力。
测试方法:选择全球被广泛翻译的《小王子》英文原文片段,让大模型把第一章的英文翻译成中文。考察模型对中文文化背景下文学作品的理解和翻译的跨文化能力。
原始 prompt:
请把经典书籍【《The Little Prince》 Chapter 1(英文原文)】翻译成中文、阿拉伯语、德语、意大利、越南语等5种语言;保留原来的人名、地名、术语等内容;注意对人物刻画的理解和语境的翻译,注意考虑不同语种之间的文化属性。
(PS:直接在微信读书原版《小王子》复制文字即可)
具体模型表现选评:
ChatGPT-4o:能够准确传达原小说的含义,译文流畅、可读性好,语言自然。但在标点符号使用和部分常见句式上存在翻译腔。

ChatGPT-4o
腾讯元宝:语句基本通顺,符合中文表达习惯。翻译文本与原文较一致,能够正确表达原文意思,保留了原小说作为儿童文学的文学风格和精炼语言特点。

腾讯元宝

ChatGPT-4o
智谱清言和豆包:在语言的生动性和自然性上表现较好。翻译文本易读,能够有效传达原文的意思,避免了直译带来的生硬感。

智谱清言

豆包
翻译专家综合点评:总体来看,各模型都基本传达了原文的意思,但在细节处理和语言自然性上有所不同,例如原文中的“And after some work with a colored pencil”部分,有些模型采用直译,导致译文生硬,不易理解。儿童文学的翻译需要注意语言的生动性和易读性。
得分排名前三的是:

专业性和严谨性是翻译工作的核心要求,尤其是在涉及法律、技术、医疗等领域的专业翻译中。这部分测试主要考察模型在高难度和专业领域翻译中的准确性和严谨性,以及其应对翻译资格考试真题的表现。
测试方法:
原始 prompt:
请把【202311月的 CATTI 翻译资格证真题】进行中英文互译,文档里的中文翻译成英文,英文翻译成中文。保留原来的人名、地名、术语等内容;注意、经济、政治、民生、科技等国家政策术语、注意翻译的严谨性,尤其要注意翻译的准确性。
具体模型表现点评::
腾讯元宝:译文中准确地传达了原文的大部分信息,忠实于原文,没有明显的错译和漏译。例如,“Rather than a simple list, the destinations are split up into five categories—eat, learn, journey, unwind and connect.” 翻译成“而不是一个简单的列表,这些目的地被分为五类——美食、学习、旅行、放松和联系。”非常准确。
然而,个别地方略有不准确,例如,“这些地方包括马尔他和圭亚那”中的“马尔他”应为“马耳他”。

腾讯元宝
通义千问:第一段把中文材料正常翻译成英文;第二段则直接解释了一遍中文原文,并没有把中文翻译成英文。可见在同样的提示词下,效果会弱一些。同样情况的还有文心一言。

通义千问
讯飞星火:对于每个部分只提供了简化的摘要或部分翻译示例。由于文本长度和复杂性的限制,讯飞星火并无法提供完整的翻译。智谱清言在整个翻译过程汇中只进行了中译英,英译中没进行。

讯飞星火
最后来看下显眼包 ChatGPT-4o 的回答如何,它先输出各自的原文,然后再分别进行翻译。

ChatGPT-4o
ChatGPT-4o 整体两段翻译准确,信息传达清晰。流畅性良好,语句自然通顺。但部分细节翻译略显笼统,有时未能完全捕捉原文的细微差别。
翻译专家综合点评
很显然,这里的 ChatGPT-4o、豆包、腾讯元宝在CATTI专业考试上领先不少。GPT-4o 和腾讯元宝在流畅性和准确性上表现突出,在科技、财经、文化、政治等领域的术语和数据信息的理解和翻译方面,豆包和智谱清言表现尤为出色,值得推荐。
得分排名前三的是:

在AI时代,每个人越来越需要阅读论文和各种外文资料,这些都离不开翻译。这时,专业术语和逻辑关系能否翻译得当,就很考验大模型的能力了。
测试方法:选择AI领域《Attention Is All You Need》(Transformer模型论文),考察模型对科技术语、复杂句式、逻辑关系的理解和翻译的准确性。
原始 prompt:
你是一位精通简体中文的专业翻译,尤其擅长将专业学术论文翻译成浅显易懂的科普文章。请你将论文【《Attention Is All You Need》】翻译成中文,风格与中文科普读物相似。
规则:
翻译时要准确传达原文的事实和背景。
即使上意译也要保留原始段落格式,以及保留术语,例如 FLAC,JPEG 等。保留公司缩写,例如 Microsoft, Amazon, OpenAI 等。
人名不翻译
同时要保留引用的论文,例如 [20] 这样的引用。
对于 Figure 和 Table,翻译的同时保留原有格式,例如:“Figure 1: ”翻译为“图 1: ”,“Table 1: ”翻译为:“表 1: ”。
全角括号换成半角括号,并在左括号前面加半角空格,右括号后面加半角空格。
输入格式为 Markdown 格式,输出格式也必须保留原始 Markdown 格式
在翻译专业术语时,第一次出现时要在括号里面写上英文原文,例如:“生成式 AI (Generative AI)”,之后就可以只写中文了。
以下是常见的 AI 相关术语词汇对应表(English -> 中文):
Transformer -> Transformer
Token -> Token
LLM/Large Language Model -> 大语言模型
Zero-shot -> 零样本
Few-shot -> 少样本
AI Agent -> AI 智能体
AGI -> 通用人工智能
策略:
分三步进行翻译工作,并打印每步的结果:
根据英文内容直译,保持原有格式,不要遗漏任何信息
根据第一步直译的结果,指出其中存在的具体问题,要准确描述,不宜笼统的表示,也不需要增加原文不存在的内容或格式,包括不仅限于:
不符合中文表达习惯,明确指出不符合的地方
语句不通顺,指出位置,不需要给出修改意见,意译时修复
晦涩难懂,不易理解,可以尝试给出解释
根据第一步直译的结果和第二步指出的问题,重新进行意译,保证内容的原意的基础上,使其更易于理解,更符合中文的表达习惯,同时保持原有的格式不变
返回格式如下,"{xxx}"表示占位符:
直译
{直译结果}
***
问题
{直译的具体问题列表}
***
意译
现在请按照上面的要求从第一行开始翻译以下内容为简体中文:
论文地址:https://arxiv.org/abs/1706.03762
具体模型表现点评:
本篇科技论文约3.9万个单词,给到统一的提示词后,腾讯元宝能够和 GPT-4o 可直接全文翻译,并保持原文的格式。

腾讯元宝
文心一言:需要加一轮提示词才能全文翻译,整体翻译的还是挺到位的。

文心一言
智谱清言、通义千问都是采用总结的形式呈现的。

智谱清言
Kimi :也能直接全文翻译,但中间部分内容可能因为文件解析的原因有部分缺漏。
豆包:或许因为是文本长度限制,翻译到3.2.1后就无法继续,
智谱清言:呈现出来的是论文总结的功能
翻译专家综合点评:
各大模型对科技术语、逻辑关系的理解基本满足了准确性,其中文心一言、腾讯元宝、ChatGPT-4o表现更胜一筹。
得分排名前三的是:

日常生活中,出国旅游、学习或工作都可能需要写签证信,这是一种常见的应用场景。签证信的写作需要清晰表达申请人的意图、行程安排等信息。
测试方法:模拟旅游场景,选择生活中第一次出国时所需的签证信写作,考察模型在此类正式场合的英文表达能力,估其在正式信函翻译方面的表现,评估模型在语法、用词和格式上的表现。
原始 prompt:
请帮我用英语写一封去日本的签证申请信,严谨一些,用词要考虑当地的风俗文化。
具体模型表现点评:
腾讯元宝:翻译比较准确,翻译速度也比较快。而且格式很清晰,结构合理,涵盖了签证申请信所需的所有要点。使用的语言正式且尊重日本文化和习惯。
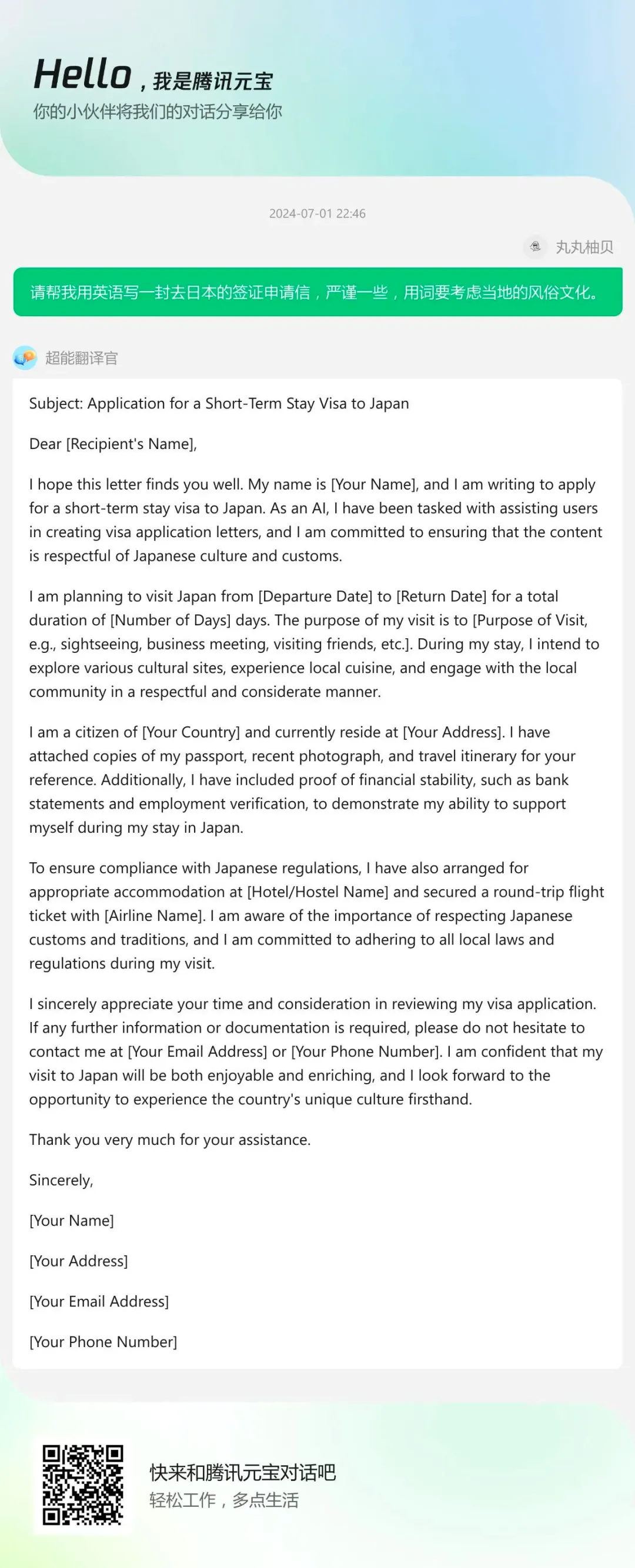
腾讯元宝
通义千问:格式清晰,内容全面,涵盖了签证申请信所需的所有要点,语言正式且尊重日本文化和习惯。但是句子冗长,读起来有些困难。

通义千问
讯飞星火:提供了清晰的签证申请信模板,涵盖了所有必要的信息;同时使用的语言正式且得体。但是文字描述有时显得冗长,需要简化以提高可读性。

讯飞星火
文心一言:生成速度稍慢,体验感可以再优化提高。

文心一言
翻译专家综合点评:
各个模型在提供签证申请信模板方面总体表现良好,均涵盖了所需的基本信息并使用了正式且得体的语言。不过,所有模型都有一个共同的改进点:需要简化部分冗长的句子,增加具体的旅行安排细节,以提高信的易读性和可信度。其他更详细的内容,得分排名前三的是:

目前各大模型基本都能通过识图解决问题,翻译也不例外。这对于喜欢拍照记录生活的朋友们尤其友好,尤其是外出旅游时,不方便询问时那直接拍照问AI。
测试方法:我们选择日常生活中常见的餐牌,包括国外只有文字的和国内还有图片的菜单,测试模型能否准确翻译并捕捉所有菜名和描述,评估模型在多模态识图和翻译方面的综合能力。
原始 prompt(文字+图片):
翻译当地中餐厅菜单的照片成英文,准确捕捉所有菜名和描述。
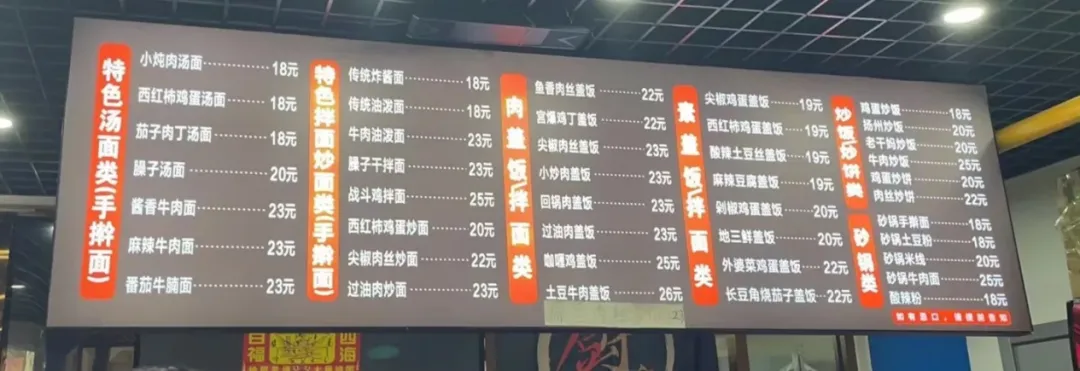
中文菜单
具体模型表现选评:
ChatGPT-4o:基本能够译出菜品名称,少量遗漏,中英对照能够更清晰地展示菜单中的菜品,价格部分有重复。整个菜单翻译风格、词汇、术语基本保持一致,易于阅读和理解。

ChatGPT-4o
腾讯元宝:菜品名称、描述和价格基本能够识别和翻译,基本不存在引起误解的歧义和直译。译文直接、简洁,某些菜品(如老干妈炒饭)辅以解释性说明,更易被不同文化的人接受。

腾讯元宝
豆包:暂时无法回答,用了拍照解答问题也无法解答。
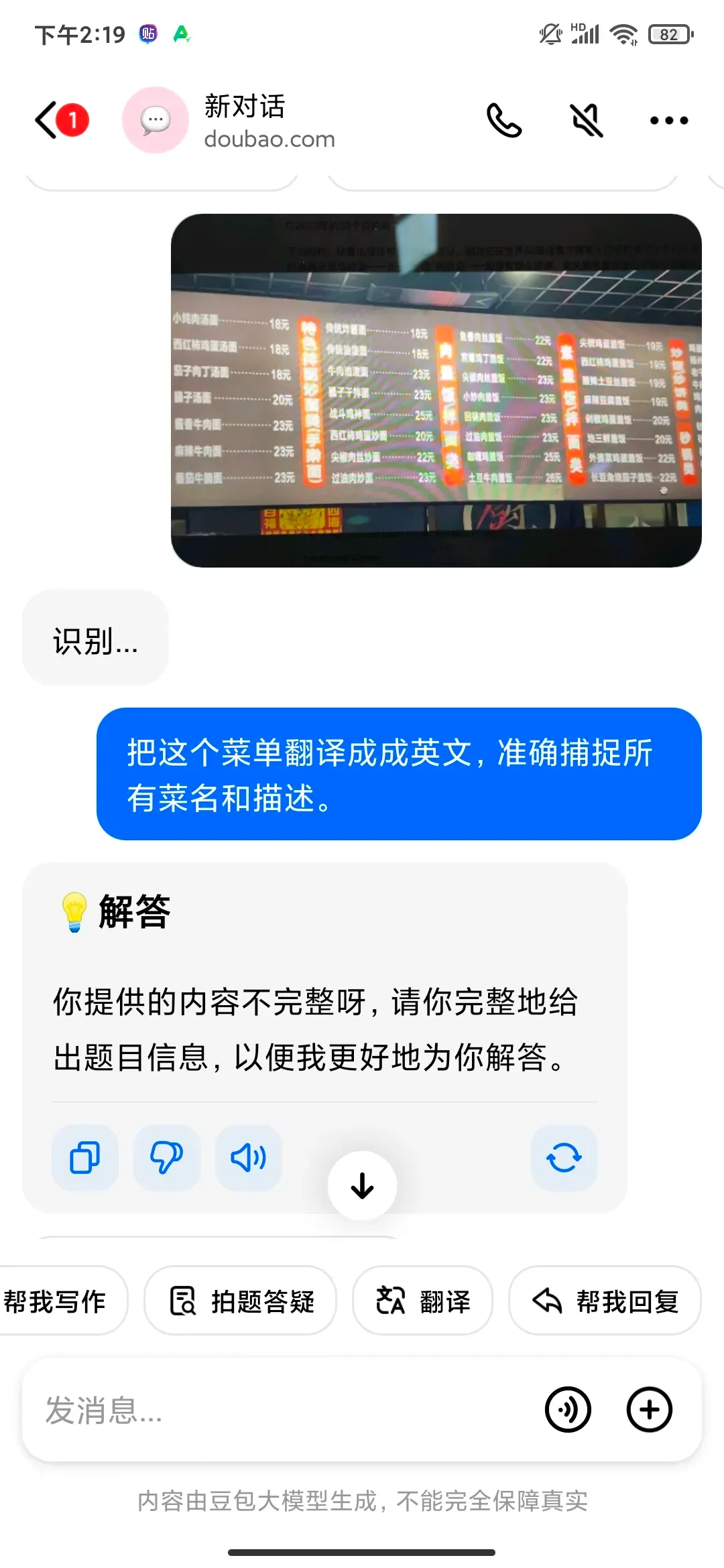
豆包
通义千问:后半段识别不全

通义千问
翻译专家综合点评:
从各大模型识图的整体效果来看,有几个模型无法做到完全识别图片内容并翻译,且部分翻译的机翻痕迹很重,就是字面意思。做最好的是 ChatGPT-4o,翻译的比较完整且基本符合菜单翻译的规范。
国内大模型在多模态识别这块还有加强空间!
得分排名前三的是:

除了中英互译外,也要进行多语种测试,以全面考察模型的翻译能力。小语种翻译不仅要求模型具备广泛的语言知识,还需要理解不同文化背景下的语言习惯和表达方式。
测试方法:选择一些常见的小语种(阿拉伯语、意大利语、德语、越南语)谚语进行翻译测试,考察模型在多语种环境下的理解和翻译能力。
原始 prompt:
لطول طول نخلة والعقل عقل سخلة .1请把这个阿拉伯语翻译成汉语
答案:四肢发达,头脑简单
2、请翻译意大利语:Buon principio fa buon fine.
答案:善始者善终。
3、请翻译德语:Aller Anfang ist schwer.
答案:万事开头难
越南语
4、请翻译越南语:Tiên lễ hậu binh:
答案:先礼后兵
具体模型表现选评:
豆包:在意大利语、德语和越南语的翻译上表现出色,但阿拉伯语的翻译与原文意思差距较大。
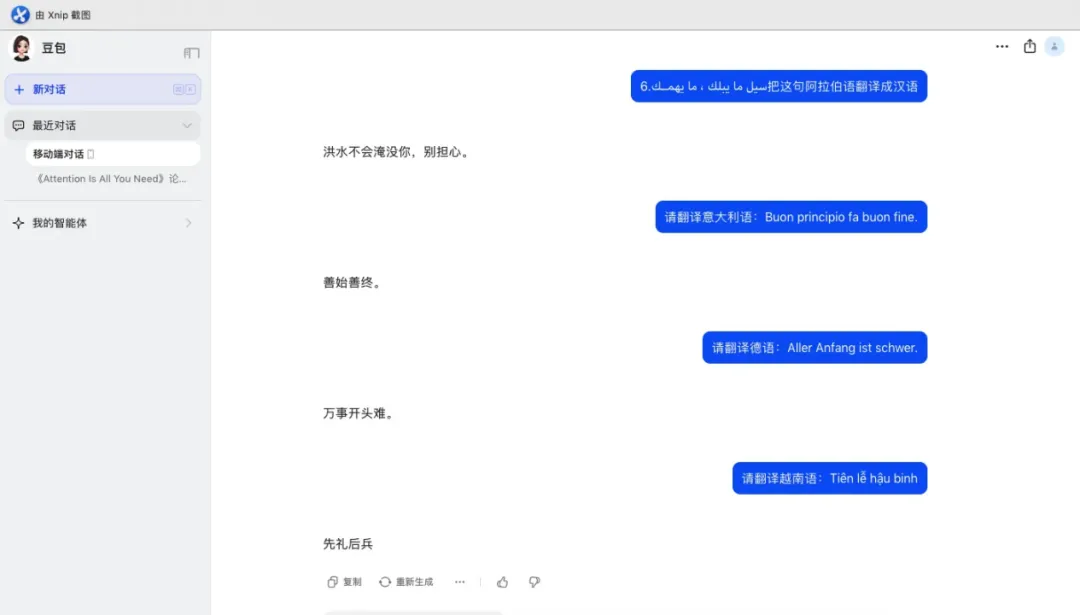
豆包
腾讯元宝:在德语和越南语翻译上表现较好,但阿拉伯语的翻译需要改进。
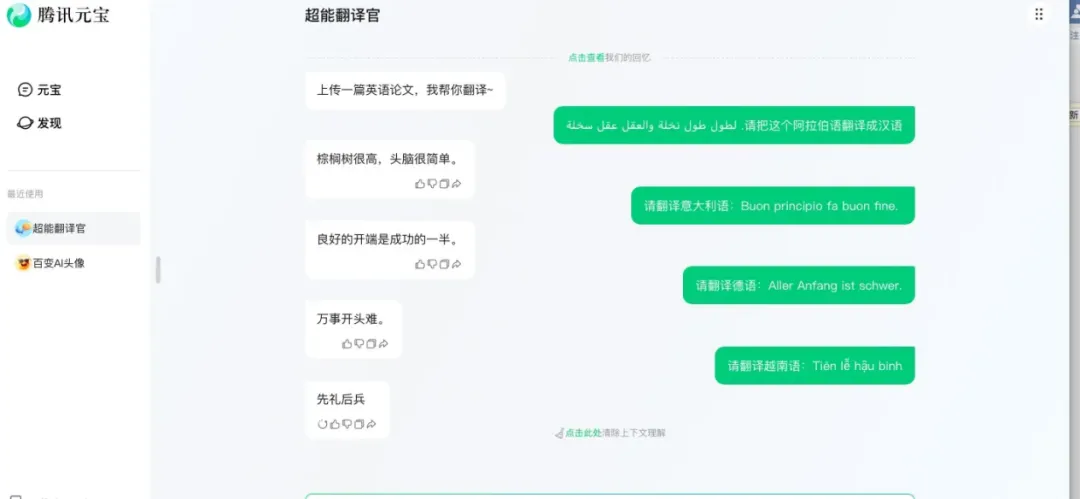
腾讯元宝
智谱清言:在德语和越南语的翻译上表现较好,但阿拉伯语的翻译需要较大的改进。
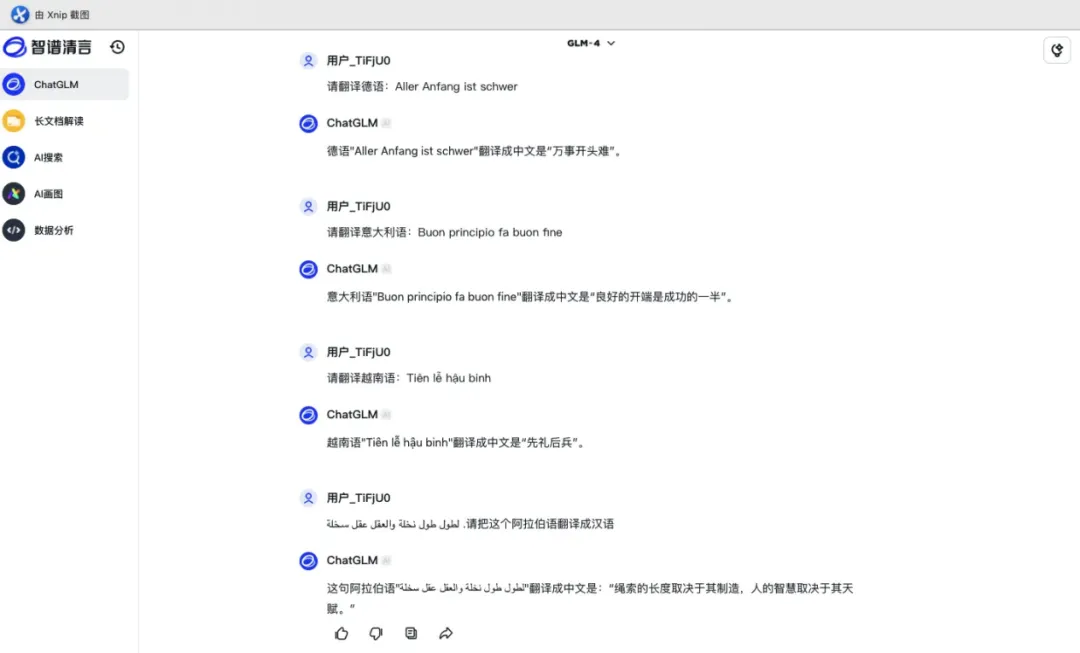
智谱清言
翻译专家综合点评:
中英互译难不到大模型们,也基本覆盖了小语种的翻译能力,在个别语种上例如阿拉伯语出现的翻译错误概率比较高,无法准确传达寓意。总体上GPT-4o和文心一言这两个模型在所有小语种翻译上表现出色,特别是在准确传达原文意思和提供背景解释方面。通义千问、腾讯元宝、豆包和智谱清言在德语和越南语翻译上表现出色,但在阿拉伯语翻译上需要改进。
得分排名前三的是:

既然是测试翻译能力,自然少不了测试口语能力。而同声传译要求翻译人员在听的同时迅速准确地翻译,这对大模型是极大的挑战。
测试方法:选取最经典的演讲之一《乔布斯斯坦福大学演讲》,实时传给大模型,重点考察各工具在长篇演讲翻译方面的准确性、流畅性、对演讲风格的把握。
原文 prompt:

具体模型表现选评::
腾讯元宝:有专门的同声传译功能,能够较好地满足实时翻译和文字记录的需求。对于一些较为复杂和冗长的句子,可以在保证准确性的前提下适当简化翻译,使得译文更加自然和易懂。

腾讯元宝
Kimi:能够有效地满足用户的实时翻译和文字记录需求,尤其是一整段完整的记录。Kimi 的翻译略显简洁自然,更符合中文表达习惯。对于一些较为复杂和长的句子,Kimi 在保持准确性的基础上,译文流畅,便于理解。

Kimi
文心一言:在准确性和流畅度上有一定的改进空间,尤其是在处理复杂句子时需要更好的翻译策略。
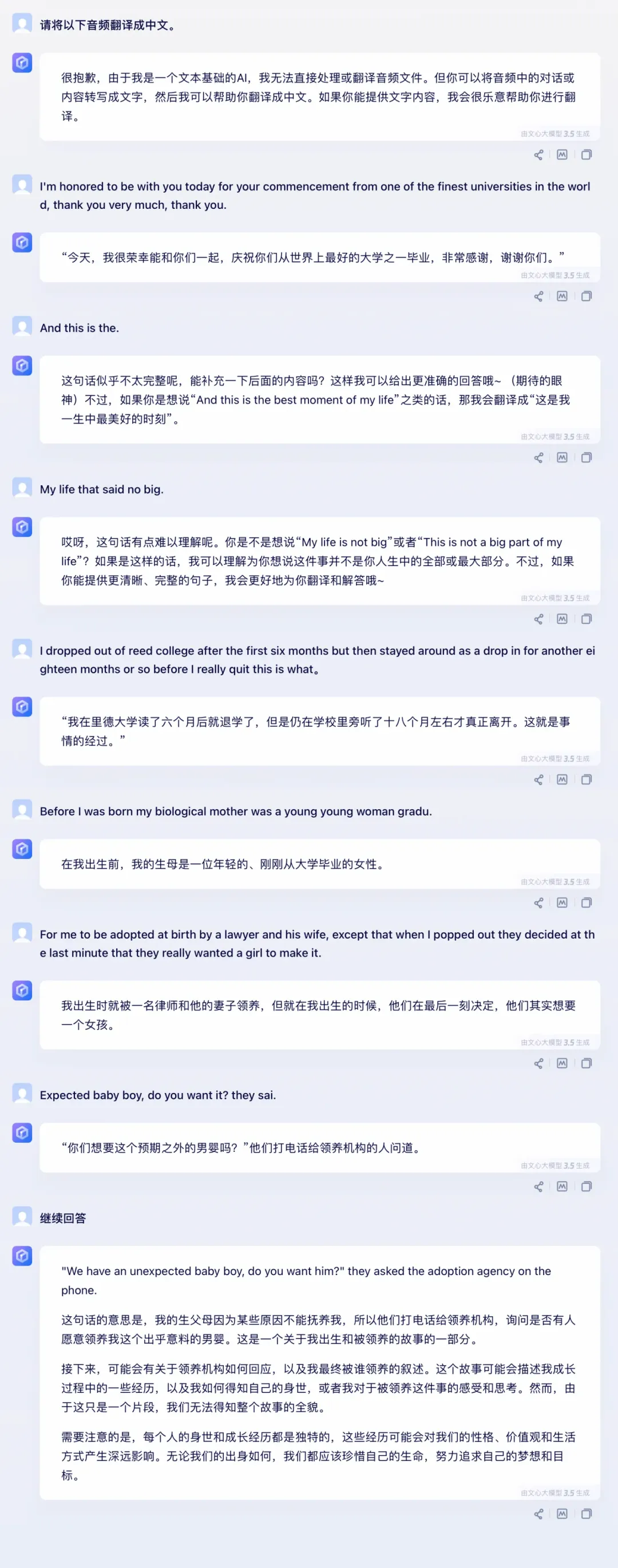
文心一言
翻译专家综合点评:
各大模型在同声传译和语音翻译方面均需要进一步提升,其中腾讯元宝在同声传译方面还不错,适合实时性要求高的场景,Kimi、ChatGPT-4o 和讯飞星火在准确性、流畅度和即时性上更优秀一些,适合需要高精度和高实时性的用户。豆包和智谱清言表现也相对优异,通义千问和文心一言在处理复杂句子时仍有改进空间。
得分排名前三的是:

总体来看,各大模型在不同场景下的表现差异显著。以下是八款大模型在十道测评题中获得的用户总分(共100分)前三名:

用户测评总榜
ChatGPT-4o 在经典诗歌和长文本翻译中表现出色,而腾讯元宝在小语种和口语翻译中具备明显优势。特别是在小语种和口语翻译方面,腾讯元宝展示了其卓越的处理能力和出色的翻译准确性。此外,腾讯元宝在专业文献和技术文档翻译中的表现也十分稳定,能够满足多种复杂场景下的翻译需求。

专家测评总榜
文心一言和讯飞星火在专业文献和法律文书翻译中表现稳定,适合需要精确术语处理和高准确性的用户。通过本次评测,我们对各大模型的优缺点有了更清晰的认识,为我们选择适合自己的翻译工具提供了详尽的参考,希望能帮助大家在实际应用中更好地利用AI翻译工具,提高工作和生活的效率。
评测下来,基本上大模型都具备了很成熟的翻译能力,国产大模型追平甚至超过了ChatGPT-4o .其中腾讯元宝的表现优秀,翻译专家打分排名第一,用户打分排名第二。无论是经典诗歌、专业资格考试题目、日常生活场景的翻译,都让人眼前一亮。其稳定性和准确性在实际应用中表现尤为突出。
我们今天看到的大模型带来的创造力,大多数集中在内容生产领域,普通人很少会用到。而翻译其实是一个最接近普通用户的场景,高质量的机器翻译能够大大提升工作效率,降低沟通成本,扩展知识的输入面,并帮助企业和个人更好地融入全球市场。而这也是翻译场景下大模型测评的更深层次意义。
随着AI技术的不断进步,未来我们可以预见到翻译能力的进一步提升。它不仅仅停留在文字层面,还会扩展到口语、视频等多模态翻译,真正做到实时、高效、全方位的跨语言交流。这将为教育、科研、商业贸易、文化传播等多个领域带来深远的影响,实现信息的无障碍流动,从而推动社会的全面进步与发展。
最后的最后,特别感谢本次一起参与测评的同学和专家们!这份测评是大家共同努力的结果!
文章来自于微信公众号“硅星人Pro”,作者 “椒盐玉兔”



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
