# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在 2024 年世界人工智能大会的现场,很多人在一个展台前排队,只为让 AI 大模型给自己在天庭「安排」一个差事。

具体流程是这样的:首先, AI 会管你要一张个人照片,并参考《大闹天宫》画风生成你在仙界的形象照。接下来,它会引导你进入一个交互式的剧情选择和交谈环节(其实是 AI 大模型自己编的剧情),然后根据你的选择和回答评估出你的 MBTI 人格类型,并根据这个类型为你在天庭「安排」一个差事。
当然,除了现场排队,你还可以在线体验(扫描下方二维码即可)。

这是大模型创业公司阶跃星辰与上影合作的 AI 互动体验《AI + 大闹天宫》。但其实,这只是开胃菜,目的是让大众直观地感受大模型的魅力所在。在今年 WAIC 期间,他们还结结实实地亮了一些大招,包括万亿参数 MoE 大模型 ——Step-2 正式版、千亿参数的多模态大模型 ——Step-1.5V,以及图像生成大模型 Step-1X。
Step-2 这个模型最早是在 3 月份和阶跃星辰公司一起亮相的,当时还是预览版。如今,它进化出了全面逼近 GPT-4 体感的数理逻辑、编程、中文知识、英文知识、指令跟随等能力。
有了这个模型做基础,阶跃星辰进一步训练出了多模态大模型 Step-1.5V。它不仅拥有强大的感知和视频理解能力,还能够根据图像内容进行各类高级推理,如解答数学题、编写代码、创作诗歌等。
《AI + 大闹天宫》的图像生成则是由另一个模型 ——Step-1X 来完成的。从生成结果中,我们能感觉到这个模型针对中国元素所做的深度优化。此外,它还有良好的语义对齐和指令遵循能力。
在几家知名的国内大模型公司中,阶跃星辰几乎是亮相最晚的一个,但却抢先形成了「万亿参数 MoE 大模型 + 多模态大模型」的大模型矩阵,站稳了「大模型创业公司第一梯队」。这背后离不开他们对 Scaling Law 的坚持以及与之匹配的技术、资源实力。在这篇文章中,我们将详细介绍阶跃星辰此次公布的几款模型,以及其背后体现的技术思路。
从头训练的
Step-2 万亿参数大模型
当参数量突破万亿,模型的数学、编程等涉及推理的能力都会显著提升。就像当初,我们用过 GPT-4 就再也不想回头用 GPT-3.5 一样,Step-2 也完成了这种跳变。相比之前的千亿级别模型,它能解决的数理逻辑、编程问题明显比之前更难了。一些基准评测的量化结果也说明了这一点。
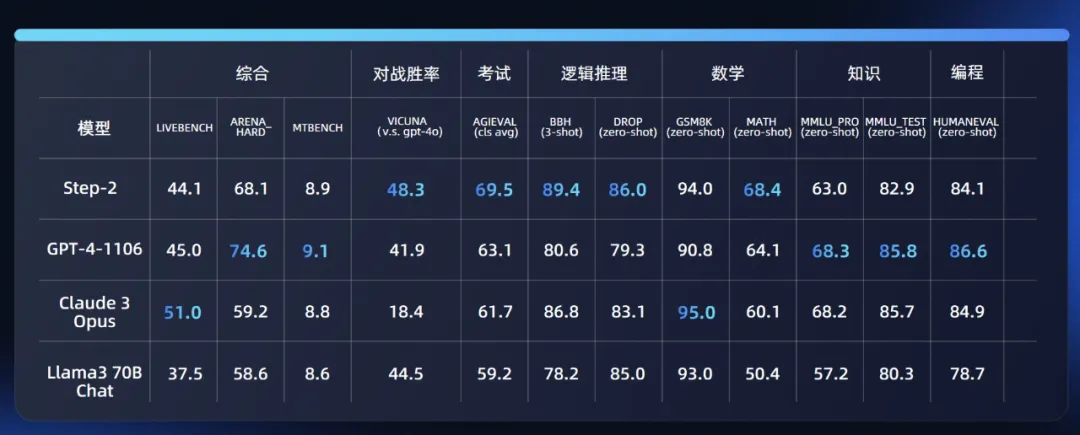
此外,它的中英文能力和指令跟随能力也实现了明显提升。
Step-2 之所以表现如此优异,一方面得益于它巨大的参数量,另一方面也得益于它的训练方法。
我们知道,训练 MoE 模型主要有两种方式。一种是 upcycle,即通过重新利用训练过程的中间结果或已经训练好的模型,以更高效和更经济的方式进一步提升模型性能。这种训练方式算力需求低,训练效率高,但训练出的模型往往上限要低一些。比如,在训练 MoE 模型时,如果多个专家模型是通过拷贝和微调相同的基础模型得到的,那么这些专家模型之间可能会存在高度相似性,这种同质化会限制 MoE 模型的性能提升空间。
考虑到这些局限,阶跃星辰选择了另一种方式 —— 完全自主研发,从头开始训练。这种方式虽然训练难度高、算力消耗大,但能获得更高的模型上限。
具体来说,他们首先在 MoE 架构设计方面做了一些创新,包括部分专家共享参数、异构化专家设计等。前者可以确保某些通用能力在多个专家之间共享,但同时每个专家仍然保留其独特性。后者通过设计不同类型的专家模型,使每个专家在特定任务上都有独特的优势,从而增加模型的多样性和整体性能。
基于这些创新,Step-2 不仅总参数量达到了万亿级别,每次训练或推理所激活的参数量也超过了市面上大部分的密集模型。
此外,从头训练这样一个万亿参数模型对于系统团队也是很大的考验。好在,阶跃星辰系统团队拥有丰富的系统建设与管理实践经验,这让他们在训练过程中顺利突破了 6D 并行、极致显存管理、完全自动化运维等关键技术,成功完成了 Step-2 的训练。
站在 Step-2 肩膀上的
Step-1.5V 多模态大模型
三个月前,阶跃星辰发布了 Step-1V 多模态大模型。最近,随着 Step-2 正式版的亮相,这个多模态大模型也升级到了 1.5 版本。
Step-1.5V 主要侧重多模态理解能力。与之前的版本相比,它的感知能力大大提升,能够理解复杂图表、流程图,准确感知物理空间复杂的几何位置,还能处理高分辨率和极限长宽比的图像。

此外,它还能理解视频,包括视频中的物体、人物、环境以及整体氛围和人物情绪。
前面提到,在 Step-1.5V 的诞生过程中,Step-2 功不可没。这指的是,在 Step-1.5V 进行 RLHF(基于人类反馈的强化学习)训练过程中,Step-2 是作为监督模型来用的,这相当于 Step-1.5V 有了一个万亿参数的模型当老师。在这个老师的指导下,Step-1.5V 的推理能力大大提升,能够根据图像内容进行各类高级推理任务,如解答数学题、编写代码、创作诗歌等。这也是 OpenAI GPT-4o 最近所展示的能力之一,这项能力让外界对于它的应用前景充满了期待。
多模态的生成能力主要体现在 Step-1X 这个新模型上。与一些同类模型相比,它有更好的语义对齐和指令跟随能力,同时针对中国元素做了深度优化,更适合国人的审美风格。
基于该模型打造的《大闹天宫》AI 互动体验的背后融合了图像理解、风格迁移、图像生成、剧情创作等多种能力,丰富立体地展现了阶跃星辰行业领先的多模态水平。例如,在初始角色生成时,系统首先会判断用户上传的照片是否符合「捏脸」要求,然后用非常《大闹天宫》的语言风格灵活给予反馈。这里就体现了模型的图片理解能力和大语言模型的能力。在大模型技术加持下,这款游戏就让玩家获得了和传统线上 H5 游戏完全不同的互动体验。因为所有的互动问题、用户形象、分析结果都是模型实时学习特征后生成的,真正做到了千人千面和无限剧情的可能。

这些优异的表现离不开阶跃星辰全链路自研的 DiT 模型架构(OpenAI 的 Sora 也是 DiT 架构)。为了让更多人用上该模型,阶跃星辰给 Step-1X 设计了 600M、2B、8B 三种不同的参数量,以满足不同算力场景的需求。
在 3 月份的亮相活动中,阶跃星辰创始人姜大昕曾明确指出,他认为大模型的演进会经历三个阶段:
这也是姜大昕等人从创业之初就在坚持的路线。在这条路上,「万亿参数」和「多模融合」缺一不可,Step-2 和 Step-1.5V、Step-1X 都是他们在这条路上达成的节点。
而且,这些节点是一环套一环的。以 OpenAI 为例,他们在年初发布的视频生成模型 Sora 使用了 OpenAI 的内部工具(很可能是 GPT-4V)进行标注;而 GPT-4V 又是以 GPT-4 相关技术为基础训练出来的。就目前来看,单模态模型的强大能力会为多模态打下基础;多模态的理解又会为生成打下基础。靠着这样的模型矩阵,OpenAI 实现了左脚踩右脚。而阶跃星辰正在国内印证这条路线。
我们期待这家公司给国内大模型领域带来更多惊喜。
文章来源于:微信公众号机器之心




【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
