# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
现在,各位二次元萌新们,不用再等「太太」出图啦!
我们不仅可以自己产粮,而且还是会动的那种。


如今,AI视频生成这个赛道,可谓是杀得如火如荼。这些更新更强的模型,思路和Scaling Law一脉相承,主打一个「又大又全」。
然而出图效果如何,全靠「抽卡」运气,更别提真实视频生成的恐怖谷效应、动漫视频生成的画风突变。

和大语言模型类似,在应用落地上想要全盘通吃的,就很难根据行业特征和专属诉求去进行专注的服务。
尤其是对于「二刺螈」小编来说,一直以来都没有找到合适的模型。
毕竟,作为普通动漫爱好者,想要和喜爱的角色同框出镜,或二创,没有绘画技能也只能空想。
从脚本构思、关键帧绘图、骨骼绑定到动态渲染,都需要付出大量的时间和精力。
来源网络
最近,小编发现了一个专为二次元打造的创作网站「YoYo」——
只需通过文字提示或者上传图片等简单操作,即可一键获得生成高质量一致性强的动漫内容,让喜欢的角色栩栩如生地出现在「同人视频」中了!

大陆站传送门:yoyo.avolutionai.com
国际站传送门:yoyo.art
同人视频一键get
可以看到,YoYo不仅创作界面简洁,而且操作起来也非常容易上手。
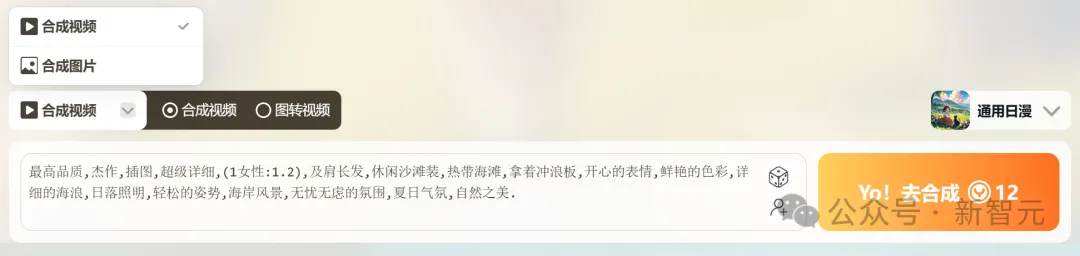
而且最重要的是,对于动漫爱好者和创作者来说,二次元氛围沉浸感极强。
不管是提示词还是图片,都有着非常丰富的高质量素材——几十个流行人物角色,以及通用、平涂、机甲等各种风格,可谓是一站式集齐,让人直呼过瘾。
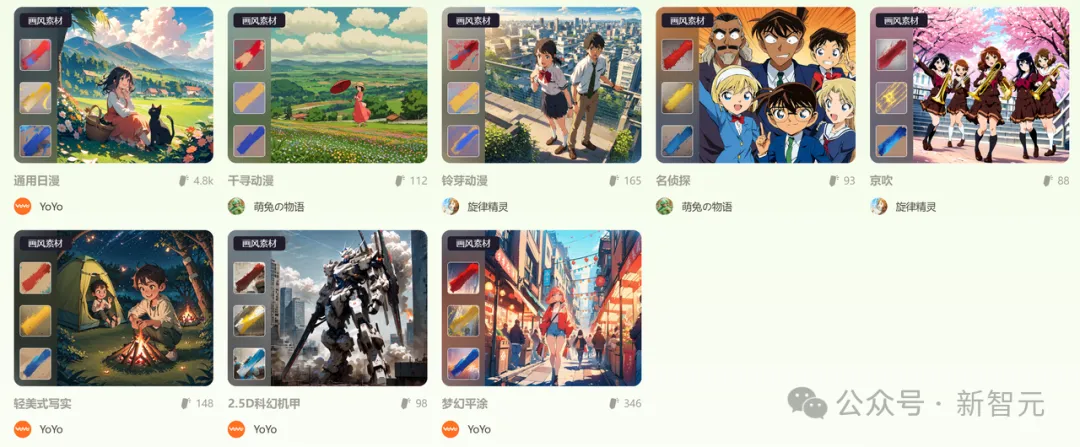
这些定制选择,可以在生成过程中控制角色的设计、故事走向,甚至是每一个细微的动画效果。

话不多说,先来一波实测。
樱花飘落、颔首浅笑,再加上精致的的背景和服装,日漫的氛围感一下就出来了。

prompt:穿着和服的女子在开满印花的庭院
燃烧的蜡烛,火焰般的眼眸,黑色的lolita,诡异的氛围,拿捏得十分到位。

prompt:最高品质,杰作,插图,超级详细,(1女性:1.2),及肩长发,哥特服饰,闹鬼的大厦,拿着蜡烛,诡异
接下来,再看看出色的人物一致性。(白毛控狂喜)
从嫉恶如仇的屠龙少女——

prompt:1girl ,hair between eyes ,white hair, blue eyes,long hair,no hat,white dress ,elf,pointy ears, fight with a big dragon, sword
到林间散步的青涩女孩——

prompt:1girl,white hair,elf,blue eyes,long hair,pointy ears,sitting in river,stars,white dress,pink canvas backpack,taking a walk in the forest
亦或是坐在水中的精灵公主——

prompt:1girl,white hair,elf,blue eyes,long hair,pointy ears,sitting in river,stars,white dress,sitting quietly on the water
顺便一提,中英混合的prompt也是可以支持的。

prompt:1girl,hair between eyes,white hair,blue eyes,long hair,no hat,white dress,elf,pointy ears,瀑布,坐在瀑布下面,双手合十,闭眼
从上面这些动图可见,AI还原出了精准而富有表现力的人物表情,让短短几秒的视频充满了故事感。
头发、蒲公英和身上的裙子,一同在随风飘动非常自然。

prompt:一个紫色长发的女孩,在长满蒲公英的草原迎风微笑,天空中闪烁极光
落下的雪和杯中的热气升腾,即使相互交织在一起也能一眼分清。

prompt:一个围着围巾的短发女孩,在大雪天喝着热茶
一台巨大的「萝卜」矗立在城市里,林立的高楼描绘出震撼的场景。

prompt:机甲,无人,独自,云,武器,科幻,发光,天空,拿着武器,建筑物,城市
除了人物角色之外,背景的生成也非常有电影镜头的感觉。

prompt:梦幻的森林大陆的鸟瞰全貌,有森林湖泊,有小小的城镇,也有远远的高山

prompt:一个古朴小镇热闹的街市
从此,不论我们脑海有多么奇幻的场景,都可以让它在动画中还原出来了!

prompt:梦幻的森林大陆上的森林,小兔子,小松鼠,五彩的蘑菇

prompt:一只通体雪白,角生梅花的鹿站在雪山顶峰眺望远方,身边发出微光
在「风物」这个场景中,我们可以一键「复刻」同好们生成的心仪场景。
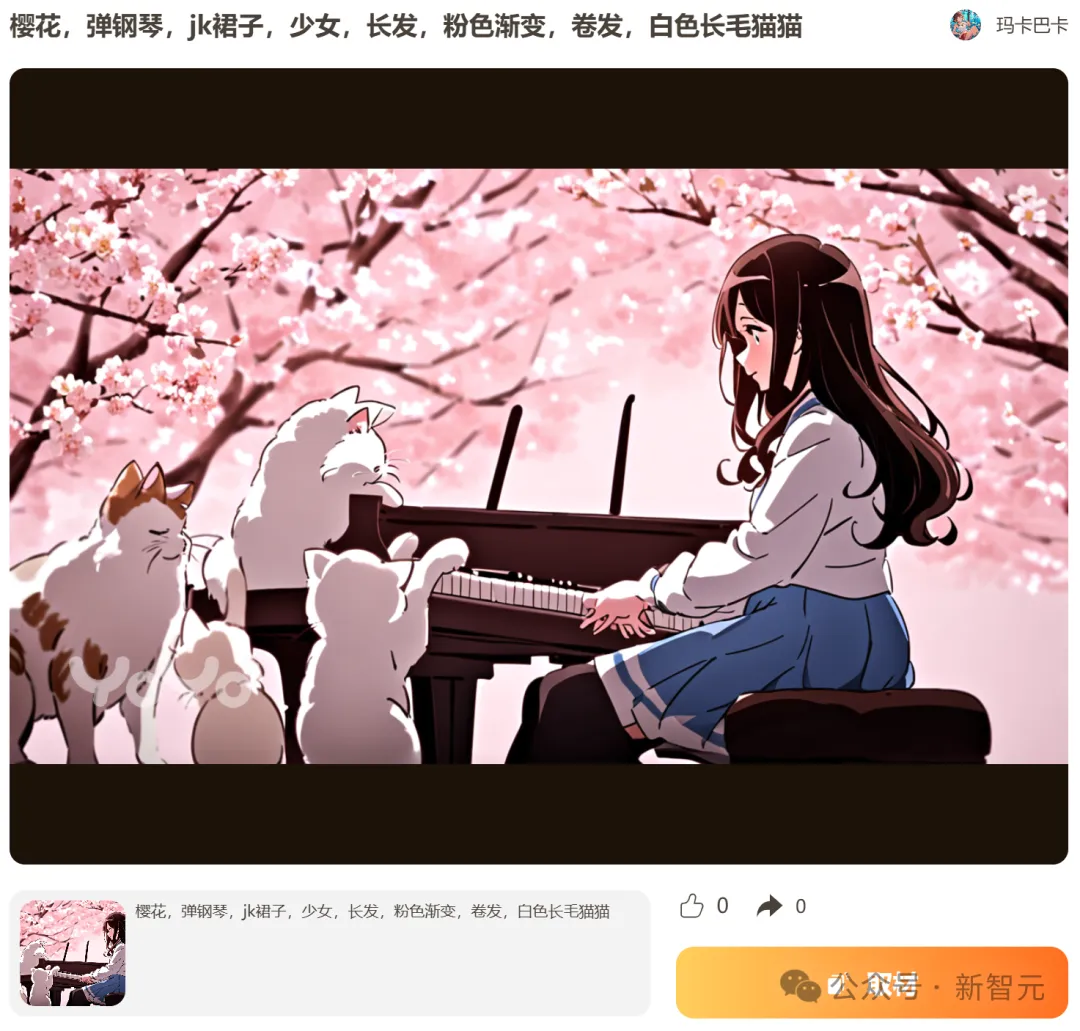
选择「取材」后,模型根据同样的prompt,就生成了类似风格的图。

接着点「生成视频」——穿着JK制服的长发女孩,和弹钢琴的白色猫猫,这画面简直不要太美。

生成模型
当前AI生成的视频存在两大技术缺陷,一是可控性,二是生成速度。
以往的模型大多使用图像或文本指令作为生成条件,但缺少对视频中动作的精确、交互式控制。在生成视频时速度也非常慢,这对于C端应用来说也会严重影响用户体验。
为了解决这些模型缺陷,鹿影团队长期专注于技术攻关,并取得了丰硕的成果,发表了多篇「干货满满」的高水平论文。
今年1月刚刚发表的Motion-I2V论文提出了创新的图生视频框架,对于复杂图像,也能生成一致且可控的视频。

论文地址:https://arxiv.org/abs/2401.15977
之前的方法,例如AnimateDiff架构,通常会让模型同时负责运动建模和视频生成,直接学习从图像到视频的映射关系。
论文提出,这种合二为一的做法会导致细节上的动作失真和时序不一致。Motion-I2V则选择解耦这两个过程。
第一阶段使用基于扩散模型的运动场预测器(motion field predictor),参考给定的图像和文本提示,专注于像素级的运动轨迹推断,预测参考帧和所有未来帧之间的运动场映射。
第二阶段则提出了一种新颖的运动增强时序层,用于增强模型中有限的一维时间注意力。这个操作可以扩大时序感受域,减轻了同时学习时空模式的复杂性。
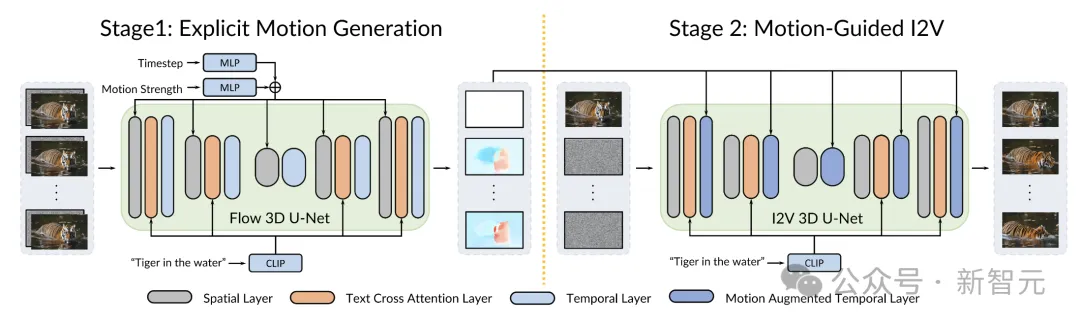
有了第一阶段轨迹预测的指导,第二阶段的模型能更有效地将所给图像的特征传播至合成的视频帧,加上稀疏的轨迹控制网络Control-Net,Motion-I2V还可以支持用户对运动轨迹和运动区域的精准控制。
与仅依赖文本prompt相比,这种方法为I2V过程提供了更多的可控性。此外,第二阶段的模型还天然地支持零样本生成,以及视频到视频的转换。
与现有方法相比,即使在运动幅度较大、视角变化的情况下,Motion-I2V也能生成更一致的视频。
从demo中可以明显看出,相比Pika、Gen-2等模型,Motion-I2V的确能模拟出更好的运动形态,视觉细节也更逼真。

在文生视频方面,今年2月发表的AnimateLCM模型公开了源代码和预训练权重,仅需4个迭代步骤就能生成质量优秀的动画,因此受到了开源社区的广泛欢迎,仅单月下载量就超过6万。
仓库地址:https://huggingface.co/wangfuyun/AnimateLCM
文章提出,扩散模型的虽然有优秀的生成效果,但其中迭代去噪过程包含30~50个步骤,计算量很大且比较费时,因而对实际应用造成了限制。
团队从潜在一致性模型(Latent Consistency Model,LCM)中得到启发,旨在用最少步骤生成高质量的逼真模型。

论文地址:https://arxiv.org/abs/2402.00769
AnimateLCM没有直接在原始的视频数据集上进行训练,而是从训练好的Stable Diffusion模型中蒸馏出先验知识。并且采用了解耦策略,将图像生成和运动生成的先验分开,再对图像模型进行3D膨胀,能够提高训练效率和生成质量。
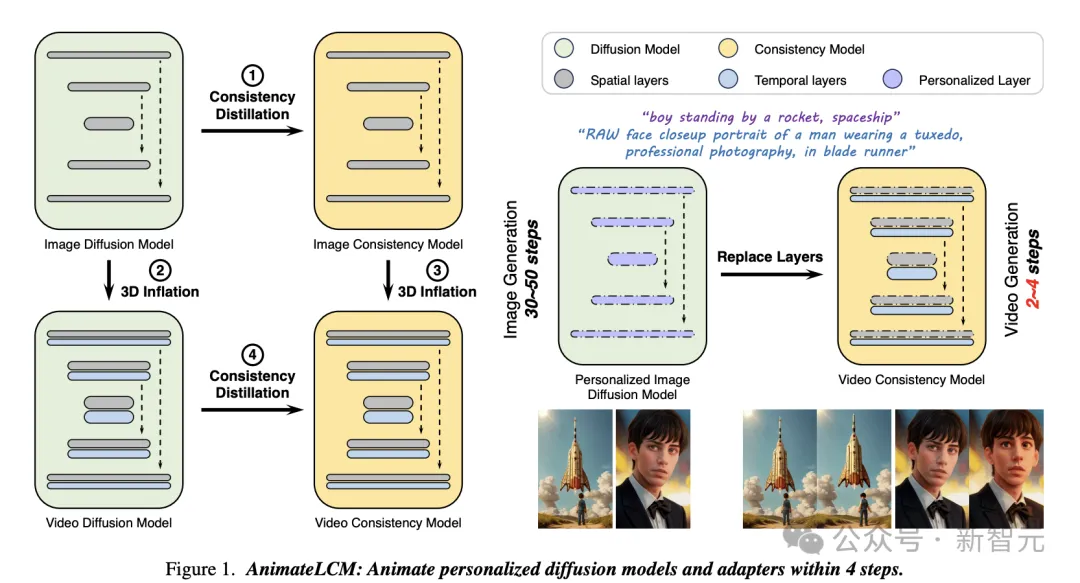
此外,为了让AnimateLCM模型更好地适应社区中被广泛应用的各种适配器(adapter),论文提出了一种不需要额外教师模型的「加速」策略来训练适配器。
实验证明,这种策略行之有效。搭配图像条件适配器或布局条件适配器时都有很好的兼容性,不仅没有损害采样效率,还实现了模型功能的扩展。
除了文生视频和图生视频,AnimateLCM还能在零样本情况下进行高效的视频风格迁移,或者用于扩展视频长度,最多可达到基本长度的4倍,并且实现了近乎完美的一致性。

虽然AnimateLCM已经取得了很好的效果,但开发团队并没有就此止步,而是选择在此基础上进一步探索。
在5月发表的最新论文中,作者指出,潜在一致性模型依旧存在一些本质缺陷。论文逐个调查了这些缺陷背后的成因,并提出了改进过的阶段一致性模型(Phased Consistency Model,PCM),实现了显著的提升。

论文地址:https://arxiv.org/abs/2405.18407
CM和LCM的设计局限主要体现在三方面:
1. 可控性:在图像和视频生成中,有一个名为CFG的重要参数(classifier-free guidance),控制文本提示对生成结果的影响程度。CFG值越高,图像或视频与提示的相关程度就越高,但也提高了画面失真的可能性。
Stable Diffusion模型在较大的CFG值范围内(2~15)都能生成出较好的画面,但LCM可接受的CFG值一般不能超过2,否则就会出现过度曝光问题。
无法提高CFG值,大大限制了文本提示对生成视频的可控性。此外,LCM对负面提示也非常不敏感,比如下图的第一个例子中,模型会「明目张胆」地无视提示要求,偏要生成一只带黑色毛的狗。
2. 一致性:这两种模型都只能使用随机的多步采样算法,因此即使采用同一个种子开始生成,在推理过程中也能看到各步骤之间明显的不一致。

3. 效率:除了上面两个硬伤之外,作者发现,LCM在少于4步的少步骤推理中无法给出较好的生成结果,因而限制了采样效率。
PCM的架构设计就很好地解决了以上三个缺陷:
实施了针对性的解决措施后,PCM在1~4步推理时生成的视频效果相比LCM有了肉眼可见的显著优化。后续的消融实验也证明了PCM这些创新设计的必要性。

从MotionI2V到AnimateLCM,再到最新的PCM,鹿影团队逐步的迭代中不断寻求突破和提升,实现了PCM的惊艳效果,模型的先进性能从基准测试的得分和横向对比中就可见一斑。
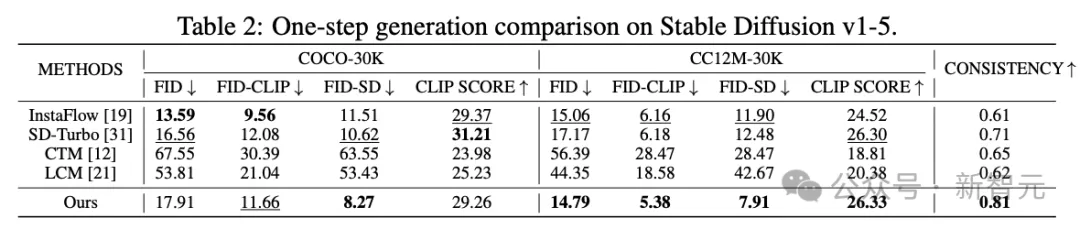
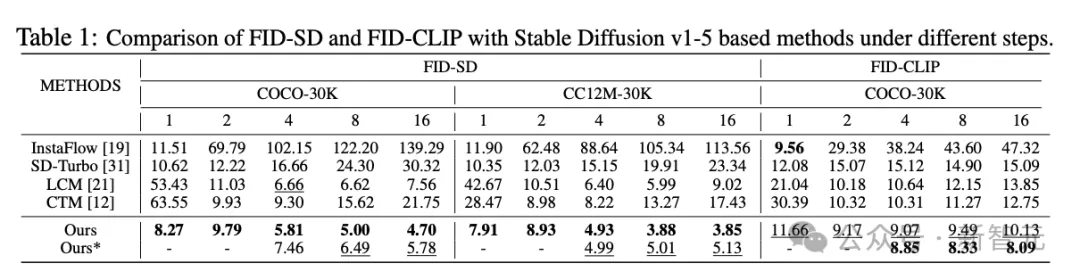
在单步推理生成图像时,PCM方法在2个数据集、5个指标上几乎都超过了Stable Diffusion-Turbo的得分,一致性得分的优势更加显著,从SD-Turbo的0.71提升至0.81。
当推理步骤从第1步逐渐增大到第16步时,这种优势依旧明显。多数情况下,使用普通ODE求解方法的更胜一筹。
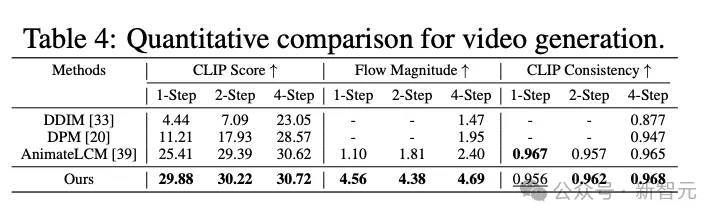
使用CLIP分数、光流估计、CLIP一致性三个指标量化评估视频生成质量时,PCM模型依旧在少步骤推理(≤4步)中取得了明显的优势,相比其他两个Diffusion架的构基线模型DDIM、DPM以及AnimateLCM都有大幅度提升。
值得一提的是,鹿影科技的研发并非一朝一夕之功,他们的技术创新持续数年并不断迭代。
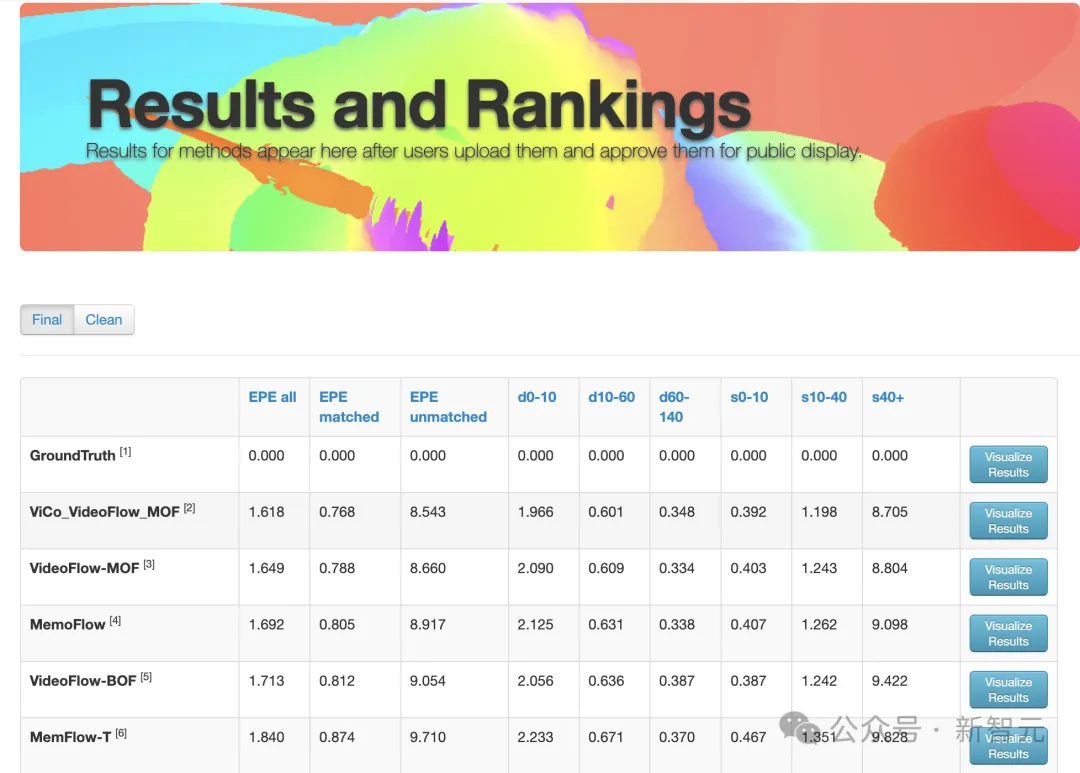
比如2022年提出的新颖架构FlowFormer在当时的Sintel光流基准测试中排名第一,2023年发布的视频光流估计框架VideoFlow在所有公共基准测试上刷新了SOTA。

论文地址:https://arxiv.org/abs/2203.16194

论文地址:https://arxiv.org/abs/2303.08340
MPI Sintel是由华盛顿大学、佐治亚理工学院和马克·普朗克研究所的多名研究人员共同开发的开源数据集,是目前光流算法领域使用最广泛的基准之一。其中的样本很好地代表了自然场景和运动,对当前的方法极具挑战性。
在最新的排行榜上,前五名中VideoFlow系列就占据了三个位置,其中ViCo_VideoFlow_MOF更是排名第一,足可见鹿影团队的技术沉淀和硬实力。
一直以来,我们高喊国漫崛起,但新作品发展迟缓,始终未能实现真正的突破。
未来,有了AI的入局,会让动漫制作的现状和创意,得到极大地改善。
对于鹿影科技,接下来要做的是,让科研成果迅速转化,让AI工具帮助原创动漫实现指数级增长。
文章来源于“新智元”,作者“新智元”




【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
