# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
做最有挑战的事:把生成式 AI 送到每个人手上。
没想到,生成式 AI 爆发后,产业格局的变化居然这么快。
一个月前,微软向全世界介绍了专为 AI 设计的「Copilot + PC」,AI PC 这个新品类突然有了标准款。
这是迄今为止速度最快、最智能化的 Windows 个人电脑。凭借搭载的新型芯片,它能够实现超过 40 TOPS(每秒万亿次操作)AI 算力、电池续航时间长达一整天,而且无缝接入了世界最先进的人工智能模型。其发布之时,只有骁龙 X 系列的 45TOPS 能够满足这样的 Windows 11 AI PC 新品类。
目前基于骁龙 X 系列平台的各品牌 Windows 11 AI PC 已经开始在国内陆续开卖,拥有很多独特的 AI 能力,例如通过回顾功能对浏览过的内部存储资料进行 AI 搜索,设备端的 AI 图像生成与优化,给视频和在线会议加实时翻译字幕、背景滤镜等等。

结合终端侧最先进的大模型技术,人们可以在新型设备上与 AI 轻松地进行交互。AI 大模型可以实时看到、听到系统内外的信息,并给与有效回应,大幅提升你的工作效率。
还记得 OpenAI CEO 山姆・奥特曼发布 GPT-4o 的时候曾经说过「与电脑交互从来都不是很自然的事情」,似乎话音未落,变革已经来到了。
在兴奋于人机交互方式的颠覆之后,人们发现,这些新形态设备的内在也有些许不同之处:常年由 X86 架构主导的 Windows 笔记本,到了 AI PC 时代却是一水的高通骁龙 X 系列芯片。
而且,这还不是简单的替换。微软官方后续进行了说明:Windows 11 中的部分生成式 AI 能力,只有在搭载骁龙芯片上才能正常运行。
为什么到了生成式 AI 时代,计算机内部的「C 位」忽然换了人?
7 月 4 日,世界人工智能大会暨人工智能全球治理高级别会议 WAIC 2024 正式召开,在这次大会上,高通展示的一系列终端侧生成式 AI 能力给了我们答案。
芯片 AI 能力,带动设备形态变革
自 ChatGPT 问世以来,人们就一直在期待大模型等新技术带来的变革。
不过这条道路异常艰难,在技术进步的过程中,人们面临着数据、算法和算力的三重挑战。生成式 AI 极度消耗算力,用于计算大模型的 GPU 都成了稀缺品。面向 AI 计算的芯片迅速成为各家硬件公司的探索方向。
在终端侧算力上,动作最快的就是高通。
去年 10 月,高通在骁龙峰会上推出了第三代骁龙 8 移动平台(骁龙 8Gen3),这块 SoC 在多核跑分中跑赢了苹果 A17 Pro,由于 CPU 和 GPU 性能的大幅提升,NPU 性能直接翻倍,它成为了旗舰 AI 手机芯片的首选。
如今,搭载新一代芯片的 AI 手机已经大卖,AI 手机很大程度上已经是「现在式」,与此同时还有一个「未来式」—— 同在骁龙大会上,我们看到高通花费大量篇幅,介绍了全新设计的高性能 PC 芯片骁龙 X 系列平台。
它的旗舰产品就是「骁龙 X Elite」,大幅提升了移动 PC 能力的上限。

这款芯片采用 4nm 制程打造,搭载了 12 大核的 Oryon CPU,。与英特尔 Ultra 7 155H 相比,Oryon CPU 的单核同功耗性能领先 54%,同性能水平的能耗可以降低 65%。在苹果 M3 芯片推出以后,骁龙 X Elite CPU 在 Geekbench 多线程中的测试结果要比苹果新品好上 28%。
GPU 方面,骁龙 X Elite 采用的 Adreno GPU 与 Ultra 7 155H 相比同功耗性能高出 36%,达到相同性能时,功耗只有竞品的一半。
这款芯片最突出的亮点是其面向下一代设备形态的 AI 算力。骁龙 X Elite 仅依靠 NPU 就可以实现 45TOPS 算力,结合 CPU、GPU、NPU 的异构计算可以输出更高算力。
根据测算,在骁龙 X Elite 的支持下,新一代 AI PC 可以在终端侧运行超过 130 亿参数的生成式 AI 模型。
这就让新一代笔记本电脑,拥有了跑大模型的底气。
骁龙峰会上,高通 CEO 克里斯蒂亚诺・安蒙与微软 CEO 萨提亚・纳德拉进行了面对面对话。两人展望了基于新硬件和大模型算法所能催生出的未来产品形态。

安蒙与纳德拉提到,新一代的 AI PC 就是要把只有新形态系统架构才能实现的体验统统结合在一起。在 AI 算力和大模型结合之后,我们使用 Windows 的体验就仿佛在 Windows 初生时遇见「开始」按钮一样 —— 所有的应用程序、体验都会有机地整合到一键之上。
几个月后,当初的预告就落地成为了现实。现在,我们可以使用 AI PC 快速直观地检索想要寻找的内容,亦或是借助实时字幕突破语言障碍,还可以使用 AI 的图像生成能力进行创作。
未来,AI PC 的能力还将覆盖人们的学习、搜索与创作,我们使用电脑的方式或许会被彻底改变。
在芯片突破的同时,在这几个月里,大模型技术的发展同样突飞猛进。
模型优化,完成最后一块拼图
最近一段时间,不论科技大厂还是创业公司都在加速研发「轻量级」AI 模型。
去年 7 月,Meta 的开源模型 LLaMA-2 70B 模型性能已接近于 GPT-3.5,到今年 4 月,LLaMA-3 8B 做到了在 80 亿参数的体量上性能与 ChatGPT 3.5 基本相当。
上个星期,谷歌开源的 Gemma 2,已经可以使用单块 GPU 进行推理,性能还超过了体量大于自身两倍的竞品。
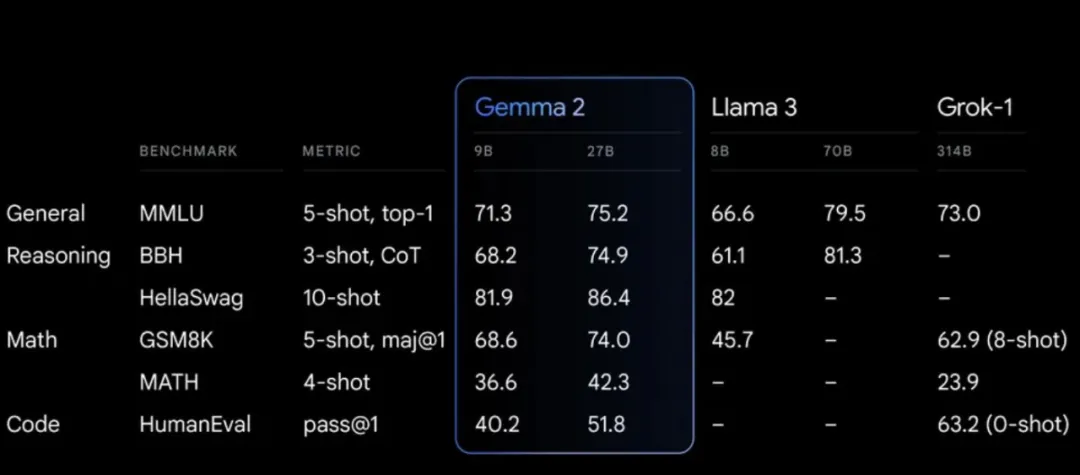
而在手机、电脑等常规终端设备上,现在我们也已经可以运行起与大型云端模型水平相当的 AI 模型了。
在世界人工智能大会 WAIC 2024 上,高通展示了首个在 Android 智能手机上运行的大语言和视觉助理大模型(LLaVA),拥有超过 70 亿参数,可以接收文字和图像内容的输入,并生成关于图像的多轮对话。LLaVA 在由骁龙 8 Gen 3 移动平台支持的工程机上运行,通过全栈的 AI 优化,实现了极高的响应速度。
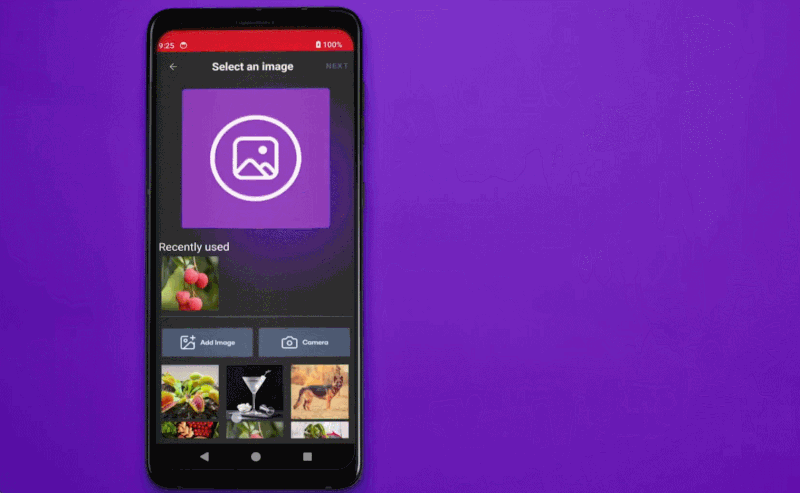
加入视觉理解能力的大模型可以为 AI 手机带来很多新的用法。在 WAIC 人工智能赋能新型工业化主题论坛上,高通公司中国区研发负责人徐晧分享了多模态终端侧 AI 的应用前景。
高通公司中国区研发负责人徐晧在 WAIC 上。
比如你可以给冰箱里的食材拍一张照片,然后问大语言模型「你看到了什么?」,AI 可以很快地识别所有物体;在此基础上还可以接着问「基于这些食材,请给我推荐一个菜谱」,让 AI 进行菜式和做法的推荐。这比以前的 AI 助手,只能问「今天天气怎么样」或者「给我讲一个笑话」要有用的多。
在搭载骁龙 X Elite 的 Windows PC 上,高通此前还展示过全球首个超过 70 亿参数的 LMM 设备端推理,它可以接受文本和环境音频输入(如音乐、交通声音等),然后生成关于音频的多轮对话。
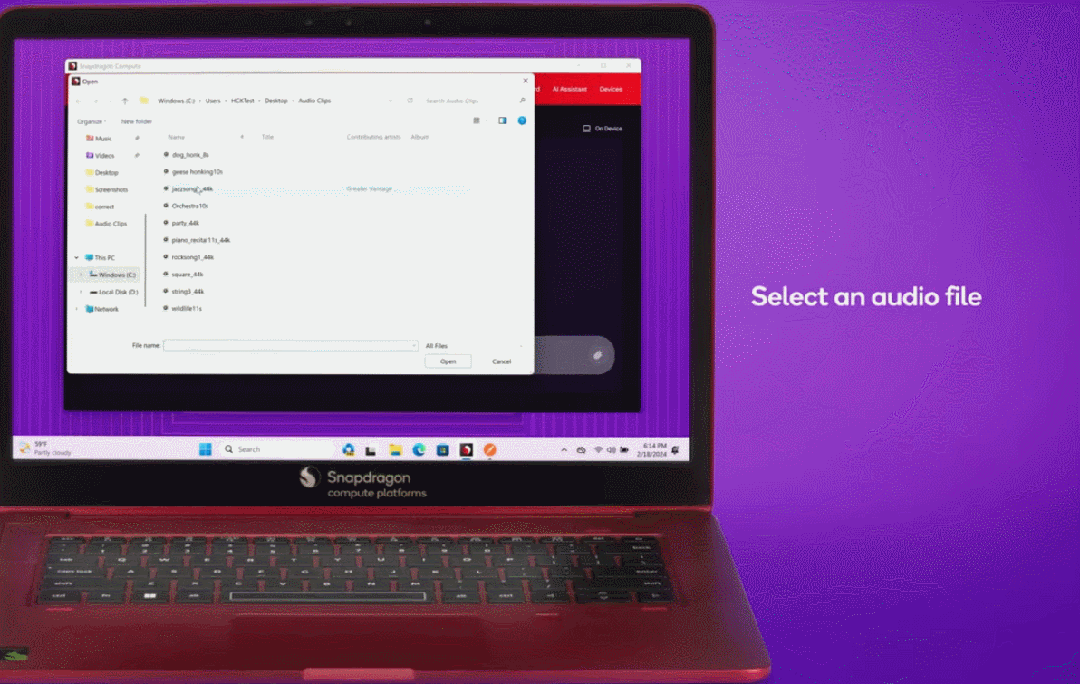
能够终端侧处理音频内容的方法,可以帮助 AI PC 更好地回答用户给出的指令。
为了把大模型微调的成本「打下来」,AI 学界提出的低秩自适应(LoRA)技术已经成为了先进大模型的主流方法,它能够在保证模型输出内容质量的前提下,大幅降低 AI 模型的可训练参数量。高通率先在安卓手机上实现了 LoRA 模型的终端侧运行,降低了大模型的训练成本,并演示了手机端运行支持 LoRA 适配器的图像生成模型 Stable Diffusion。
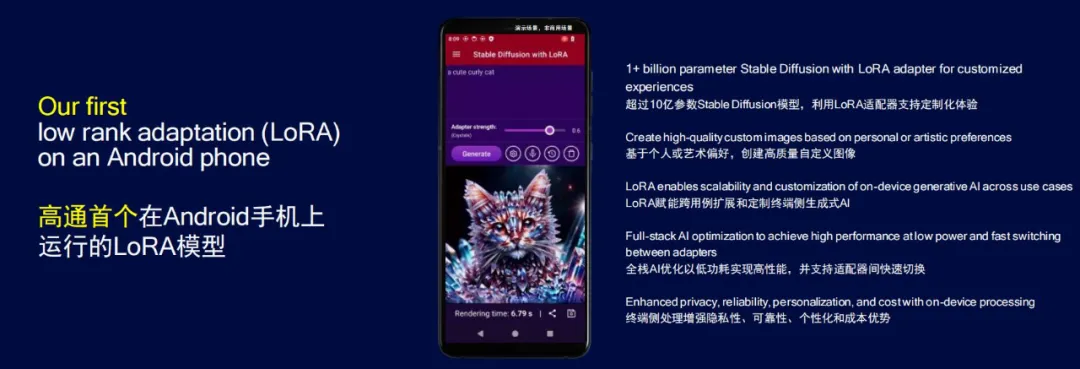
在 WAIC 现场,高通展示了骁龙生态的更多可能性。抖音集团在骁龙 X Elite 平台的 AI PC 上跑起了自家的机器学习框架 ByteNN,对剪映客户端进行 AI 适配优化。通过 NPU 加速,剪映的智能抠像功能可以实现快速、轻松的一键移除视频背景,测试对两分钟时长的视频进行智能抠像,比使用 CPU 耗时降低 92%,完成抠像任务所消耗电量减少 85%。
另外,在剪映的美颜美体匀肤功能中,我们同样可以在本地 NPU 的加速下实现快速祛斑祛痘能力。
高通还展示了高度智能的 AI 服务机器人。告诉机器人「我想喝水」或是「我口渴」,机器人会提供不同的饮料选择。用户选择之后,机器人可以走到房间另一侧,识别饮料然后拿给用户。这样由人工智能驱动的机器人,已经可以在日常生活中提供帮助了。
有了多模态、LoRA 和能够支撑第三方应用的软件栈,高通可谓已经完成了终端侧生成式 AI 的全部拼图。
用「小模型」撬动大生态
上述这些研究、实践的共同目的,是为了让 AI 大模型更加轻量化,让终端侧设备承担起更多的计算任务。大模型虽然可以在云端运行,但在终端侧设备上运行生成式 AI 的推理可以带来很多好处。
从技术角度来看,终端侧处理 AI 任务具有保护隐私、个性化、降低成本、可靠性和快速响应的优势,每个方面对于大规模、常态化的部署都至关重要。
从实用角度来看,作为「通用化」的人工智能技术,在拥有更完善的能力后,终端侧大模型可以让手机等设备更全面地了解世界,AI 助理实现真正的智能化,把我们从很多繁杂的任务中解放出来。
不过,能做到从软到硬,布局完整体系,又有大规模生态的玩家并不多。
在国内,除了各家大厂打造的旗舰 AI 手机,部分玩家在 AI PC 上的角力才刚刚展开。把视线往远看,生成式 AI 的应用还要扩展到汽车、XR 设备和物联网上。
这其中,很多应用落地的背后都可以看见高通的身影。
WAIC 大会上,高通中国区董事长孟樸在产业发展主论坛上介绍了高通为推动终终端侧 AI 发展所做的努力。

高通中国区董事长孟樸在 WAIC 大会现场。
高通拥有超过 15 年的 AI 技术研发经验,凭借长期不懈的技术探索与实践,已经打造出了端云结合的混合 AI 能力。在生成式 AI 时代,高通充分发挥技术优势,为终端设备提供了性能领先的硬件,其可扩展的软硬件技术架构可以对多种 AI 算法实现性能、能效的极致优化,并快速部署到不同终端上。
在去年骁龙峰会上,高通便表示全球搭载骁龙芯片的设备已经超过了 30 亿台。背靠庞大的设备基数,先进的软硬件全栈优化体系,以及全球协作的生态系统,高通在生成式 AI 技术爆发的过程中,进一步扩展了对于前沿技术方向的探索,站在了引领潮流的高度。
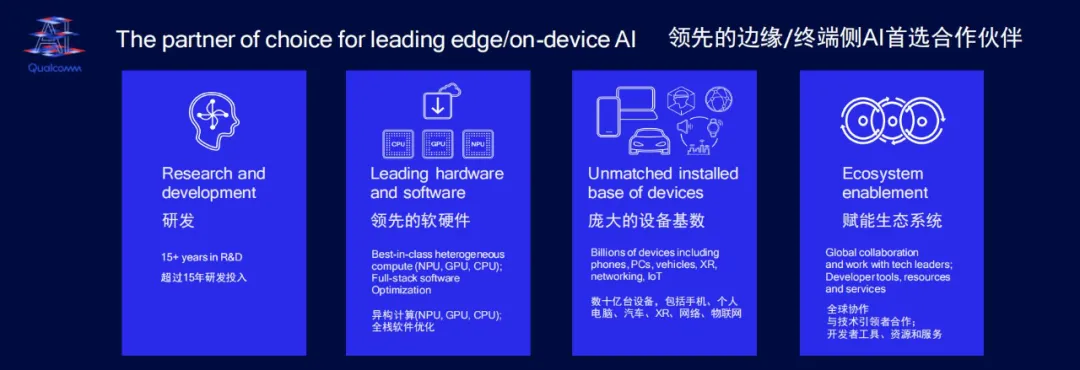
现在,高通的生成式 AI 能力已经覆盖了开发的全流程:高通提供面向生成式 AI 设计的全新计算架构,可以实现 CPU、NPU、GPU 结合的异构计算;高通 AI 引擎能够横跨不同设备类型,帮助人们把业界领先的 AI 模型快速落地;最后,使用这套软件和硬件,大模型应用对接的还是用户面积最大、品类最为繁多的生态。
高通的终端侧生成式 AI 布局,已经在收获成果:
有高通这样提供完整技术栈的存在,生成式 AI 的大规模落地已经按下了加速键。由此带动,变革正逐渐显现,这不由得让人想起 NPU 刚刚诞生时,上一波 AI 技术爆发的前夜。
很快,终端侧生成式 AI 带来的智能化将会无处不在。
文章来源于“机器之心”,作者“关注大模型的”



【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
