# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
海明威的《太阳照常升起》中,迈克·坎贝尔说出了那个简短的名言:“逐渐地,然后突然地”( Gradually,and then suddenly)。
许多事物重要变化过程都是如此,从逐步积累,突破了某个临界点时,会突然给世界一个惊喜。
在技术和企业的发展过程中,这种现象也非常常见。大模型爆发之前,AI技术经历了数十年的缓慢积累和发展。而从GPT-3到GPT-4的这个飞跃,代表了AI能力的一次显著跃升。这种快速进展是建立在长期的理论研究、算法优化、计算能力提升和大规模数据积累的基础之上的。
大模型的参数规模达到某个临界点时,其性能会有质的飞跃,这种“涌现能力”,就是一个“突然出现”的过程。当这些因素达到临界点时,我们就看到了这种“突然”爆发性的进展。
同样“突然出现”的还有大模型企业阶跃星辰,百模大战一年后登场的阶跃星辰,发布了综合性能超过GPT-3.5的千亿参数大模型Step-1。
今年3月,阶跃星辰发布了千亿参数的多模态模型Step-1V,语言大模型Step-2的预览版也一并呈现,这也是国内大模型创业公司,首次交出的万亿参数模型的答卷的里程碑时刻。
在今年的世界人工智能大会(WAIC)上,阶跃星辰再次展示了其最新成就。一次性推出了三款新模型:Step-2万亿参数语言大模型正式版、Step-1.5V多模态模型、以及Step-1X图像生成模型。
在创始人姜大昕“单模态—多模态—多模理解和生成的统—世界模型—AGI”路线图之下,阶跃星辰从千亿到万亿,从语言到多模态,从理解到生成的全面升级与布局,这一切都在100天后“突然”发生。
“万亿+多模+生成”的大模型全家桶,迈向AGI的必经之路
先来看Step-2 正式版,万亿参数,MoE架构,同时基于行业领先的系统能力大幅提升了训练效率,在数理逻辑、编程、世界知识、指令跟随等方面体感逼近GPT-4。
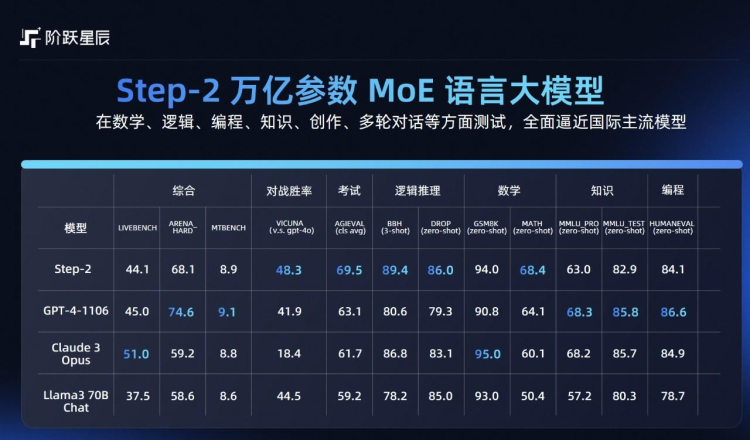
值得注意的是,得益于从头开始训练而不是基于已有模型通过向上复用训练,Step-2 中的每个“专家模型”都得到充分训练,每次训练或推理所激活的参数量也超过了市面上的大部分Dense模型。
从头开始训练MoE模型虽然挑战更大,但能带来更高的上限。这种方法允许研发团队完全自主设计模型架构,实现更高的性能上限和更强的灵活性。还能够从原始数据中学习更精细的特征,避免继承预训练模型的潜在偏见。
此外,这种方法给予团队对整个训练过程的完全控制,有利于深度优化和创新。尽管初期投入较大,但从长远来看,这种方法可能带来更大的技术突破和壁垒。
阶跃星辰多模态方面的最新进展是Step-1.5V,这是一个千亿参数的多模态大模型。Step-1.5V在图像感知和理解能力上全面提升,更具备出色的视频理解能力。它能准确地识别视频中的物体、人物和环境,并理解视频的整体氛围与人物情绪。
此外,在Step-2万亿参数语言大模型的加持下,Step-1.5V推理能力也得到了大幅增强,能根据图像内容进行解答数学题、编写代码、创作诗歌等高级推理任务。
阶跃星辰在极短的时间内,实现了从图像理解到视频理解的跨越升级。这种跨越和升级不仅是技术上的进步,也是朝着AGI发展的重要一步。AGI的目标是实现一种具备广泛认知能力的智能系统,能够在不同的任务和环境中表现出类似人类的智能。多模态大模型的成功开发,特别是具备图像和视频理解能力的模型,正是朝着这一目标迈进的必要一环。
理论上,AGI的发展需要模型在多个感知和认知领域中具备综合能力。Step-1.5V通过整合语言、图像和视频的理解与推理能力,不仅能处理单一模态的信息,还能在多模态信息的交互中展现出更复杂的推理和理解能力。这种能力的提升,不仅推动了模型在特定任务中的表现,也为未来更广泛的应用场景奠定了基础。
Step-1X是阶跃星辰的首个图像生成大模型,模型采用了全链路自研DiT架构(Diffusion Models with transformer),支持 600M、2B、8B多参数量灵活适配,通过强化的语义对齐能力和增强的指令跟随性能,确保了生成图像与文本描述的高度一致性,提升了交互式创作的效率与质量。同时还针对中国元素和文化进行深度优化,使得模型在处理具有中国特色的内容时,能展现出更加细腻和准确的表现力,符合本土审美偏好。

模型即产品,自研C端应用
正如姜大昕所言,模型和应用的关系犹如灵魂与皮囊,两者的深度绑定是实现技术极致的关键。模型作为AI的核心,决定了系统的能力上限,而应用则是模型与现实世界交互的重要界面。这种关系不仅是相互依存的,更是一种协同进化的过程。
模型的每一次突破都能推动应用的创新,同时,应用中遇到的实际需求也反过来指导着模型的优化方向。这种良性循环促进了整个大模型领域的快速发展。
以GPT系列为例,其强大的语言模型与ChatGPT应用的深度结合,不仅展示了自然语言处理的巨大潜力,也开创了人机交互的新范式。同样,DALL-E图像生成模型与语言模型的融合,拓展了AI在创作领域的应用边界。
因此,阶跃星辰也选择了模型和应用两条腿走路,基于自身的大模型推出了自研的个人效率助手“跃问”以及类似AI开放世界平台 “冒泡鸭”。
跃问基于Step系列大模型开发,整合了图像识别、文本处理和数据分析等功能,提供一站式智能助手解决方案,在文档处理、内容创作和数据分析方面表现突出,能快速处理各种格式的长文本,制作复杂表格,并进行数据提取分析。对需要提高生活和工作效率的用户来说,跃问是一个值得尝试的工具。
尤其是跃问多模态内容理解能力的功能,不仅能将复杂的文本信息转化为直观的长图,智能提取文档中的关键信息,以图文并茂的形式呈现,还能直接理解现实世界,并给出实用的建议和帮助,比如出差住酒店不知道怎么用咖啡机,就可以直接找跃问来解决。

丰富的产业应用生态圈,重点行业已有落地
除了自研产品,阶跃星辰构建了基于Step系列大模型的产业应用生态圈,并在重点行业实施落地策略,通过与合作伙伴达成了深度合作,共同探索面向C端用户的创新应用。
在本次WAIC现场,阶跃星辰与上海电影联合推出的AI互动体验《大闹天宫》,还结合《葫芦兄弟》的IP进行了视频生成能力的展示,引来许多观众的打卡围观。
在互动体验中,用户通过上传真人照片就能获得天庭风格的证件照,并测试出对应的《大闹天宫》版MBTI性格类型,还能获得虚拟官职。

据游戏开发负责人介绍,在Step系列大模型的支持下,所有互动问题、用户形象和分析结果都是模型实时学习后生成的,实现了千人千面和无限剧情的可能。
面向金融财经领域,阶跃星辰与上海报业旗下界面财联社达成深度合作,双方围绕 AIGC 财经资讯、智能投研、智能投顾等领域推进大模型的应用落地。同时,阶跃星辰还联合国泰君安、界面财联社推出业内首个千亿级参数多模态证券垂直类大模型——君弘灵犀大模型,在行业内首个实现了将大模型能力全面融入客户智能化服务体系之中,为客户在智能投顾问答、投研内容生产和交互模式上带来全新体验。
除了与行业头部企业,许多独立开发者也选择了基于Step系列大模型进行大模型应用开发。比如《胃之书》,这是一款结合AI技术的智能饮食记录应用,旨在帮助用户轻松记录饮食、了解营养状况、发现美食乐趣。它通过智能识别和营养分析功能,结合趣味探索的特色,为用户提供一个全方位的饮食记录和管理工具,上线三天就靠自然增长进入AppStore分类榜Top20。
开发者赵纯想在构建应用的过程中,采用了一种A/B测试策略,通过为不同用户分配不同模型,通过比较不同模型在实际应用中的表现,特别是用户的付费行为,最终选择了阶跃星辰模型。
结语
在当今的AI领域,许多公司都在借鉴OpenAI的经验,逐步探索前行。而从大模型的发展来看,每隔三个月,训练成本就会减半;每延迟几个月,便能直接训练出更强的模型。
阶跃星辰的名字源自“阶跃函数”,完美地捕捉了技术飞跃的本质,这与Scaling Law的核心本质不谋而合——随着模型规模的扩大,性能会显著提升,发生跃迁。阶跃星辰在短短100天内实现了令人瞩目的进步,这也正是“阶跃”所象征的跨越式发展。
文章来源于“硅星人Pro”,作者“周一笑”



