# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
《思考快与慢》中人类的两种思考方式,属实是被Meta给玩明白了。
研究人员通过把AI的“慢思考”结果蒸馏进“快思考”,让Llama2表现提升了257%,变得比GPT4还能打,同时还能降低推理成本。
这里的快慢两种思考方式,指的就是2002年诺贝尔经济学奖得主丹尼尔·卡尼曼推广的系统1和系统2——
简单说,系统1是简单无意识的直觉,速度更快;系统2则是复杂有意识的推理,准确性更强。
Meta所做的“蒸馏”,就是用系统2生成数据,然后对用系统1推理的模型进行微调。
有网友看了后表示,这种模式和人类很像,一旦解决了一个难题,再解决(相似的问题)就变得简单了。

对于大模型而言,模仿人类的“系统2”的方式有很多种,在模型中所处的环节也不尽相同,这里作者一共研究了四种:
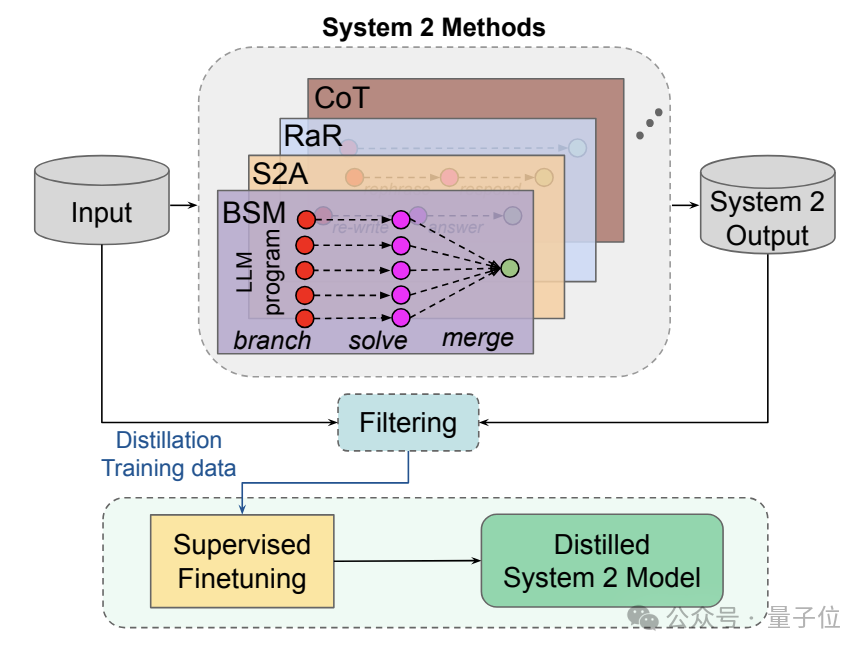
但从整体流程上看则是殊途同归,各种“系统2方法”都会在未标注数据集上生成推理结果。
在这过程当中,模型会在给出结果的同时生成详细的中间推理步骤,但研究人员只保留最终的输出结果。
然后就得到了输入-系统2输出的数据对,可以视为一种无监督的“伪标签”,将这些数据对收集起来,就形成初步的蒸馏数据集。
当然了,这步得到的数据还不能直接拿来微调系统1模型,需要进行过滤以确保其拥有足够高的质量。
过滤的具体依据,是一致性和鲁棒性。
一致性筛选当中,对每个输入样本,都会用系统2模型采样生成多个输出,然后通过多数投票等方法进行比较,如果大多数都一致,则认为该输出是可靠的;
鲁棒性筛选是对一个输入样本进行适当的扰动,如改变无关细节、调整词序等,然后观察系统2模型在扰动前后的输出是否一致。
筛选后的高质量蒸馏数据,就可以对系统1模型进行无监督微调了。

微调过程可以看作是一种知识蒸馏,但又与与传统的知识蒸馏不同,这里两种系统使用的是同一个基础模型。
系统1模型的目标是直接学到系统2模型的输出行为,而不是中间的复杂推理过程,在后续推理时也不需要执行系统2的推理步骤,而是直接生成输出。
但从输出质量上来看,表现却能接近系统2模型,也就是实现了系统2能力向系统1的转移。
那么,为什么要专门收集数据去微调系统1模型,而不直接用系统2模型推理呢,作者也给出了解释。
道理其实很简单,从系统2的另一个名字“慢系统”当中,很容易就能看出答案:
因为系统2的速度慢,在实时交互、移动设备部署等场景下,模型的延迟可能是无法接受的。
另外,由于需要输出完整的推理过程,系统2输出的token长度也是系统1的数百倍。
就像开头那位网友说的,系统2把复杂的推理解决了,再将数据喂给系统1,问题对其而言也会变得容易。
从表现上看,这样的模式也确实让系统1模型的表现大幅进步,甚至超过了真·系统2模型。
针对前面四种不同的系统2方法,研究人员分别使用不同的数据集,在不同的任务上进行了测试。
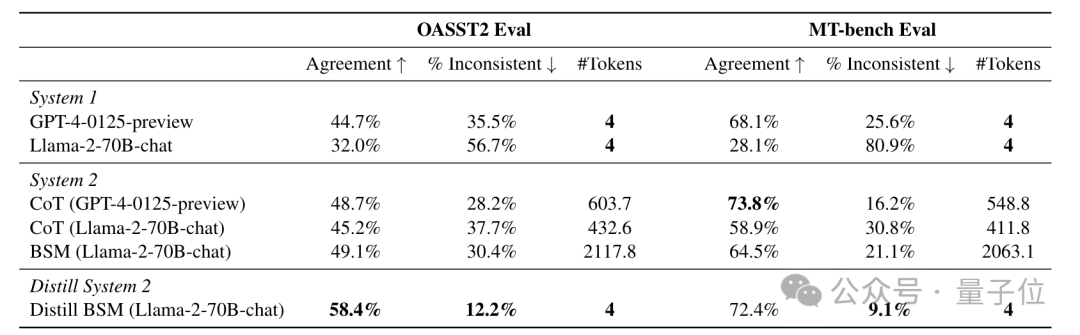
针对BSM方法,作者采用的数据集是Open Assistant 2和MT-bench,评估了模型作为“评判者”时的表现。
可以看到,在两个数据集中,Llama-2的表现(人类一致性)分别从32.0%和28.1%,提高到了58.4%和72.4%,最高增幅达到了257%,比CoT方法更加有效。
而且,微调后的模型均超过了系统1版的GPT-4,甚至达到了GPT-4配合CoT的水准。
同时(改变选项位置后的)不一致性也大幅降低,而且和系统2相比,Token数量少到几乎可以忽略不计。
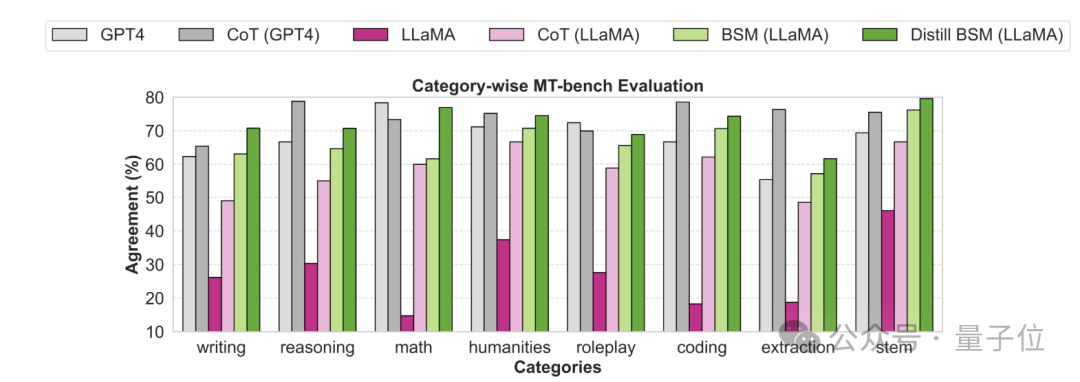
同时针对MT-Bench不同的子类任务,作者也分别分析了各种方法的人类一致性。
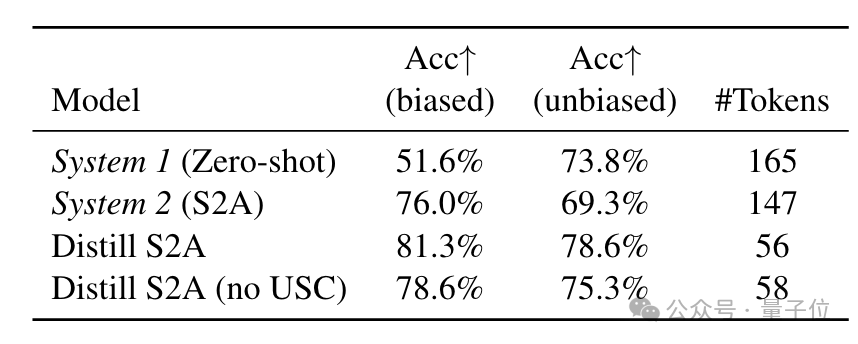
接下来是S2A方法,它主要解决的是模型偏见问题,因此评估时采用了带偏见的TriviaQA任务。
结果蒸馏后的准确率达到81.3%,超过了原始S2A的76%,生成的token数量也从147个减少到了56个。
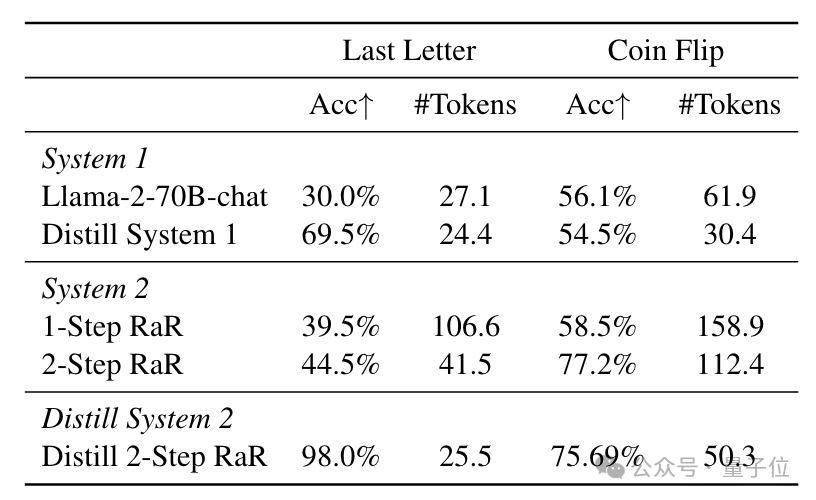
RaR的测试目标则是完成一些推理任务,这里作者测试了Last letter concatenation和Coin flip。
在Letter任务中,蒸馏后的系统模型准确率从30%飞升到了98%,也超过了系统1自蒸馏的69.5%,同时也优于原始的RaR方式。
而在Coin flip任务里,蒸馏后的准确率达到 75.69%,也与接近2-步原始RaR的77.2%接近,但生成的token数量大幅减少。
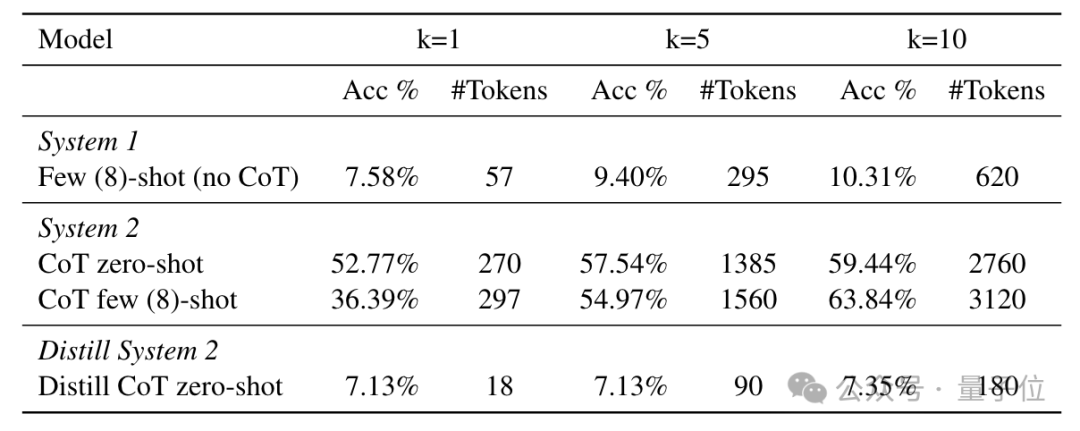
不足的一点是,CoT的蒸馏效果与另外三种大相径庭,作者发现,在数学推理任务上,CoT的推理能力很难迁移到系统1当中。
在GSM8K数据集上,蒸馏后的模型在k=1时准确率仅为7.13%,k=10时也只有7.35%,甚至不如没蒸馏之前的版本。
所以,作者认为,接下来的研究目标是进一步明确这种蒸馏的应用场合,找到更类似于人类学习的方式。
文章来源于“量子位”,作者“关注前沿科技”



【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
