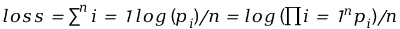# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
开源最彻底的大模型来了——130亿参数,无需申请即可商用。
不仅如此,它还附带着把全球最大之一的中文数据集也一并开源了出来:600G、1500亿tokens!
这就是来自昆仑万维的Skywork-13B系列,包含两大版本:
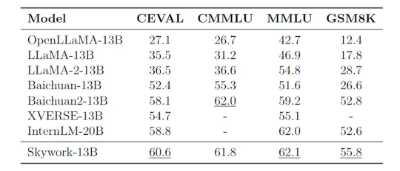
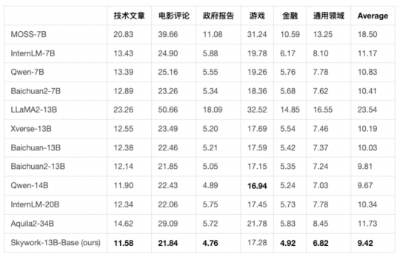
在各大权威评测benchmark上,如C-Eval、MMLU、CMMLU、GSM8K,可以看到Skywork-13B在中文开源模型中处于前列,在同等参数规模下为最优水平。
而Skywork-13B系列之所以能取得如此亮眼的成绩,部分原因离不开刚才我们提到的数据集。
毕竟清洗好的中文数据对于大模型来说可谓是至关重要,几乎从某种程度上决定了其性能。
但昆仑万维能将如此“至宝”无偿地给奉献出来,不难看出它对于构建开源社区、服务开发者的满满诚意。
除此之外,昆仑万维Skywork-13B此次还配套了“轻量版”大模型,是在消费级显卡中就能部署和推理的那种!
Skywork-13B下载地址(Model Scope):
https://modelscope.cn/organization/skywork
Skywork-13B下载地址(Github):
https://github.com/SkyworkAI/Skywork
接下来,我们进一步来看下Skywork-13B系列更多的能力。
Skywork-13B系列大模型拥有130亿参数、3.2万亿高质量多语言训练数据。
由此,模型在生成、创作、数学推理等任务上提升明显。
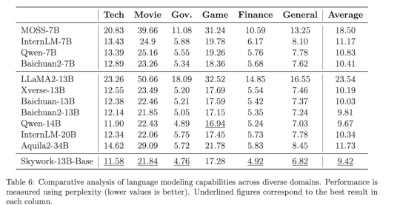
首先在中文语言建模困惑度评测中,Skywork-13B系列大模型超越了目前所有中文开源模型。
在科技、金融、政务、企业服务、文创、游戏等领域均表现出色。
另外,Skywork-13B-Math专长数学任务,进行过数学能力强化训练,在GSM8K等数据集中取得了同等规模模型最佳效果。
与此同时,昆仑万维还开源了数据集Skypile/Chinese-Web-Text-150B。其数据是通过精心过滤的数据处理流程从中文网页中筛选而来。
由此,开发者可以最大程度借鉴技术报告中大模型预训练的过程和经验,深度定制模型参数,进行针对性训练与优化 。
除此之外,Skywork-13B还公开了模型使用的评估方法、数据配比研究和训练基础设施调优方案等。
而Skywork-13B的一系列开源,无需申请即可商用!
用户在下载模型并同意遵守《Skywork模型社区许可协议》后,不用再次申请商业授权。
授权流程也取消了对行业、公司规模、用户数量等方面限制。
昆仑万维会如此彻底开源其实也并不意外。
昆仑万维董事长兼CEO方汉是最早参与到开源生态建设的老兵了,也是中文Linux开源最早的推动者之一。
在今年ChatGPT趋势刚刚兴起时,他就多次公开发声、强调开源的重要性:
代码开源可助力中国版ChatGPT弯道超车。
所以也就不难理解Skywork-13B系列大模型的推出了。
所以,Skywork-13B系列开源工作,具体是如何实现的呢?
Skywork-13B的技术细节可以从四方面看起:
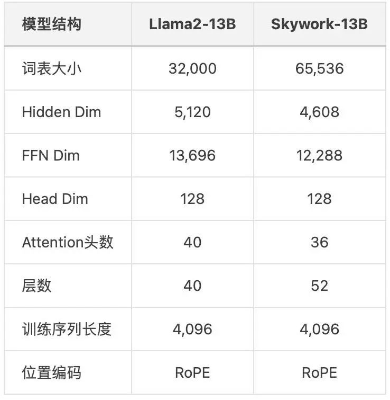
首先在结构上,Skywork-13B相比Llama2-13B,更加“瘦长”,模型层数为52。
这样做的好处是能在大Batch Size训练下取得更好泛化效果。
同时将FFN Dim缩小到12288和4608,可以保证模型参数量和原始Llama2-13B模型相当。
具体Skywork-13B和Llama2-13B对比如下:
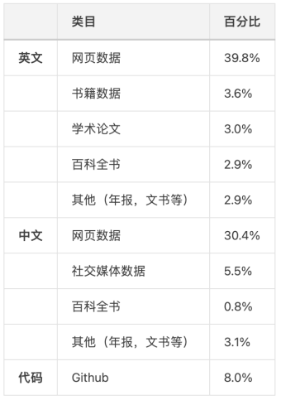
其次在数据方面,昆仑万维也公开了英文、中文、代码数据的比例。
可以看到中英文部分吸收了大量网页数据和社交媒体数据,同时兼顾了相对专业的方面,比如学术论文、年报、文书等。
代码方面则主要从GitHub上吸收数据。
在训练方法方面,Skywork-13B也是完全开源。
训练共有两个阶段:
第一阶段使用通用语料进行通用能力学习,第二部分加入STEM(科学,技术,工程,数学)相关数据进一步增强模型的推理能力、数学能力、问题解决能力。
这样做的好处是能更加精细化利用数据。
最后在模型评估方面,昆仑万维给出了领域数据困惑度评估方法。
大语言模型训练的本质是让预测的下一个词(个体)更加准确。
昆仑万维认为评估基础大模型的一个重要方式,就是评估在各个领域中,大语言模型生成文章(整体)的概率。
一般模型预测下一个词的概率会使用Cross Entropy损失函数,整体的损失函数为每个位置预测真实词损失的平均:
n表示文档长度(token数量),pi是位置i上真实词的概率。
将文档中每个位置上真实词的概率连乘,则为生成文档整体的概率。
这样一来,就能将loss和生成文章的概率联系在一起了。
而由于不同模型使用的分词器不同,token数量不同,因此对损失函数乘以token数目n,这样就能仅考虑生成文章的概率部分,不同模型也可以进行比较。
将标准化后loss取指数转换成perplexity(困惑),可以使模型的差异更加可读。
基于如上分析,昆仑万维在多个领域筛选出了这个月发表的成百上千篇高质量文章(2023年10月),并进行人工核对。
选择最新的数据,为的是保证测试数据不在所有评估大模型的训练集范围内。
如下是最后评估结果,可以看到Skywork-13B表现突出。
对于昆仑万维此次的开源发布,可以说它主打的就是个“敢”。
毕竟能将大模型背后的利器——高质量数据集,能够如此毫不避讳地放出来共享,放眼全球范围都是寥寥无几的存在。
而若是将时间线拉开来看,我们就不难理解昆仑万维是怎么这么“敢”的了。
早在今年年初、全球各大厂商大模型“争奇斗艳”白热化阶段,昆仑万维就以黑马的姿态直接杀入百模大战。
首发就敢以现场直播、实时演示的方式,让天工参加自家程序员面试,并且很流畅地通过了第一关:
而且除了面试题之外,昆仑万维还敢直面弹幕中网友们现场提出的各种刁钻问题:
在接下来的时间里,昆仑万维还保持着数月一迭代的优化,让语义理解、推理等任务变得更加丝滑。
并且在8月底,昆仑万维率先在国内推出了第一款融入大模型能力的AI搜索。
是当时刨除插件形式之外,第一个敢将大模型能力投入应用的独立AI搜索产品。
而在短短2个月后,昆仑万维又将最新的大模型、最新的数据集,一并发布且开源,可以说它的一切动作不仅在于快,更是在于敢。
那么接下来的问题是——为什么要这么做?
其实,对于AIGC这一板块,昆仑万维早在2020年便已经开始涉足,早早的准备和技术积累就是它能够在大热潮来临之际快速跟进的原因之一。
据了解,昆仑万维目前已形成AI大模型、AI搜索、AI游戏、AI音乐、AI动漫、AI社交六大AI业务矩阵。
至于不遗余力的将开源这事做好做大,一方面是源于企业的基因。
昆仑万维董事长兼CEO方汉是最早参与到开源生态建设的开源老兵,也是中文Linux开源最早的推动者之一,开源的精神和AIGC技术的发展早已在昆仑万维战略中完美融合。
正如方汉此前所言:
昆仑天工之所以选择开源,因为我们坚信开源是推动AIGC生态发展的土壤和重要力量。昆仑万维致力于在AIGC模型算法方面的技术创新和开拓,致力于推进开源AIGC算法和模型社区的发展壮大,致力于降低AIGC技术在各行各业的使用和学习门槛。
没错,降低门槛,便是其坚持开源的另一大原因。
从昆仑万维入局百模大战以来的种种动作中,也很容易看到它正在践行着让天工用起来更简单、更丝滑。
总而言之,昆仑万维目前已然是处于国产大模型的第一梯队,甚至说是立于金字塔尖都不足为过。
那么在更大力度的开源加持之下,天工大模型还将有怎样惊艳的表现,是值得期待一波了。
文章来自微信公众号 “量子位”,作者 金磊 明敏


【开源免费】suno-api是一个使用监听技术实现了调用suno功能,并封装好API的AI音乐项目。
项目地址:https://github.com/gcui-art/suno-api
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales