# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在刚刚开幕的ICCAD 2023大会上,英伟达团队展示了用AI模型测试芯片,引发了业界关注。
众所周知,半导体设计是一项极具挑战性的工作。
在显微镜下,诸如英伟达H100这样的顶级芯片,看起来就像是一个精心规划的大都市,这其中的数百亿个晶体管则连接在比头发丝还要细一万倍的街道上。
为了建造这样一座数字巨城,需要多个工程团队长达两年时间的合作。
其中,一些小组负责确定芯片的整体架构,一些小组负责制作和放置各种超小型电路,还有一些小组负责进行测试。每项工作都需要专门的方法、软件程序和计算机语言。
最近,来自英伟达的研究团队开发了一种名为ChipNeMo的定制LLM,以公司内部数据为基础进行训练,用于生成和优化软件,并为人类设计师提供帮助。
论文地址:https://research.nvidia.com/publication/2023-10_chipnemo-domain-adapted-llms-chip-design
研究人员并没有直接部署现成的商业或开源LLM,而是采用了以下领域适应技术:自定义分词器、领域自适应持续预训练(DAPT)、具有特定领域指令的监督微调(SFT),以及适应领域的检索模型。
结果表明,与通用基础模型相比(如拥有700亿个参数的Llama 2),这些领域适应技术能够显著提高LLM的性能——
不仅在一系列设计任务中实现了类似或更好的性能,而且还使模型的规模缩小了5倍之多(定制的ChipNeMo模型只有130亿个参数)。
具体来说,研究人员在三种芯片设计应用中进行了评估:工程助理聊天机器人、EDA脚本生成,以及错误总结和分析。
其中,聊天机器人可以回答各类关于GPU架构和设计的问题,并且帮助不少工程师快速找到了技术文档。
代码生成器已经可以用芯片设计常用的两种专业语言,创建大约10-20行的代码片段了。
代码生成器
而最受欢迎分析工具,可以自动完成维护更新错误描述这一非常耗时的任务。
对此,英伟达首席科学家Bill Dally表示,即使我们只将生产力提高了5%,也是一个巨大的胜利。
而ChipNeMo,便是LLM在复杂的半导体设计领域,迈出的重要的第一步。
这也意味着,对于高度专业化的领域,完全可以利用其内部数据来训练有用的生成式AI模型。
为了构建领域自适应预训练(DAPT)所需的数据,研究人员同时结合了英伟达自己的芯片设计数据,以及其他公开可用的数据。
经过采集、清洗、过滤,内部数据训练语料库共拥有231亿个token,涵盖设计、验证、基础设施,以及相关的内部文档。
就公共数据而言,研究人员重用了Llama2中使用的预训练数据,目的是在DAPT期间保留一般知识和自然语言能力。
在代码部分,则重点关注了GitHub中与芯片设计相关的编程语言,如C++、Python和Verilog。
在监督微调 (SFT) 过程中,研究人员选取了可商用的通用聊天SFT指令数据集,并制作了的特定领域指令数据集。
为了快速、定量地评估各种模型的准确性,研究人员还构建了专门的评估标准——AutoEval,形式类似于MMLU所采用的多选题。
ChipNeMo采用了多种领域适应技术,包括用于芯片设计数据的自定义分词器、使用大量领域数据进行领域自适应预训练、使用特定领域任务进行监督微调,以及使用微调检索模型进行检索增强。
首先,预训练分词器可以提高特定领域数据的分词效率,保持通用数据集的效率和语言模型性能,并最大限度地减少重新训练/微调的工作量。
其次,研究人员采用了标准的自回归语言建模目标,并对特定领域的数据进行了更深入的预训练。
在DAPT之后,则进一步利用监督微调(SFT)来实现模型的对齐。
针对大模型的幻觉问题,研究人员选择了检索增强生成(RAG)的方法。
研究人员发现,在RAG中使用与领域相适应的语言模型可以显著提高特定领域问题的答案质量。
此外,使用适量的特定领域训练数据对现成的无监督预训练稠密检索模型进行微调,可显著提高检索准确率。
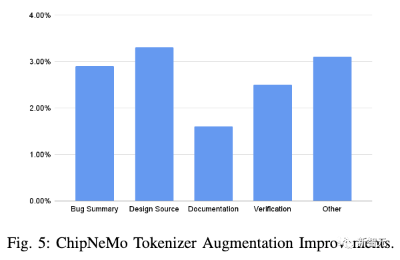
首先,自适应的分词器可以在各种芯片设计数据集中,将分词效率提高1.6%至3.3%。
其次, ChipNeMo模型在芯片设计领域基准AutoEval和开放领域学术基准上的测试结果显示:
1. DAPT模型在开放领域学术基准上的准确性略有下降。
2. DAPT对领域本身的任务产生了积极的影响。其中,模型对于内部设计和电路设计的知识水平显著提高。
3. 使用规模更大、性能更强的基础模型,可以在特定领域任务中获得更好的结果。
4. DAPT对域内任务的改进与模型大小呈正相关,较大的模型在DAPT后对特定领域任务性能的提升更为明显。
所有模型均使用128个A100 GPU进行训练。研究人员估算了与ChipNeMo领域自适应预训练相关的成本,如下表所示。
值得注意的是,DAPT占从头开始预训练基础模型总成本的不到1.5%。
研究人员对使用和不使用RAG的多个ChipNeMo模型和Llama 2模型进行了评估,结果如图8所示:
- RAG可以大幅提升模型的得分,即便RAG未命中,分数通常也会更高。
- ChipNeMo-13B-Chat获得的分数比类似规模的Llama2-13B-Chat更高。
- 使用RAG的ChipNeMo-13B-Chat与使用RAG的Llama2-70B-Chat获得了相同的分数(7.4)。当RAG命中时,Llama2-70B-Chat得分更高;但RAG未命中时,具有领域适应的ChipNeMo表现更好。
- 领域SFT使ChipNeMo-13B-Chat的性能提高了0.28(有 RAG)和0.33(无 RAG)。
从图9中可以看出,DAPT补足了模型对底层API的知识,而领域域SFT进一步改善了结果。
一个有趣的结果是,LLaMA2-70B似乎可以借助卓越的通用Python编码能力,来解决尚未接受过训练的新问题。但由于它几乎没有接触过Tcl代码,因此在该工具上的表现较差。
而这也凸显了DAPT在小众或专有编程语言方面的优势。
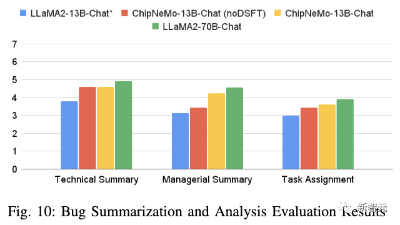
结果如图10所示,ChipNeMo-13B-Chat模型在所有三项任务上均优于基本LLaMA2-13B-Chat模型,分别将技术总结、管理总结和任务推荐的分数提高了0.82、1.09和0.61。
此外,领域SFT也显著提高了模型在管理总结和任务分配方面的性能。
不过,Llama2-70B-Chat模型在所有任务上表现都要比ChipNeMo-13B更加出色。
虽然较大的Llama2 70B有时也可以达到与ChipNeMo相似的精度,如图8、9和10所示。但考虑较小规模的模型所带来的成本效益,也同样重要。
比如,与Llama2 70B不同,英伟达的ChipNeMo 13B可以直接加载到单个A100 GPU的显存中,且无需任何量化。这使得模型的推理速度可以得到大幅提升。与此同时,相关研究也表明,8B模型的推理成本就要比62B模型低8-12倍。
因此,在生产环境中决定使用较大的通用模型还是较小的专用模型时,必须考虑以下标准:
- 训练和推理权衡:
较小的领域适应模型可以媲美更大的通用模型。虽然领域适应会产生额外的前期成本,但使用较小的模型可以显著降低运营成本。
- 用例独特性:
从图6、9和10中可以看出,领域适应模型模型在很少出现在公共领域的任务中表现极佳,如用专有语言或库编写代码。而对于通用大模型来说,即使提供了精心挑选的上下文,也很难在这种情况下与领域适应模型的准确性相媲美。
- 领域数据可用性:
当存在大量训练数据(数十亿训练token)时,领域适应效果最好。对于积累了大量内部文档和代码的公司和项目来说,情况通常如此,但对于较小的企业或项目则不一定。
- 用例多样性:
虽然可以针对特定任务微调通用模型,但领域适应模型可以适用于领域中的各种任务。
总的来说,领域自适应预训练模型(如ChipNeMo-13B-Chat)通常可以取得比其基础模型更好的结果,并且可以缩小与规模更大的模型(如Llama2 70B)之间的差距。
参考资料:
https://blogs.nvidia.com/blog/2023/10/30/llm-semiconductors-chip-nemo/
https://spectrum.ieee.org/ai-for-engineering
文章来自微信公众号 “ 新智元 ”



【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner