# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
开源新王Llama 3.1 405B,昨夜正式上线!
在多项基准测试中,GPT-4o和Claude 3.5 Sonnet都被超越。也即是说,闭源SOTA模型,已经在被开源模型赶上。

一夜之间,Llama 3.1 405B已成世界最强大模型。
(同时上线的,还有新版70B和8B模型)

LeCun总结了Llama 3.1模型家族的几大要点:
- 405B的性能,与最好的闭源模型性能相当
- 开源/免费使用权重和代码,允许进行微调、蒸馏到其他模型中,以及在任何地方部署
- 128k的上下文,多语言,良好的代码生成能力,复杂推理能力,以及工具使用能力
- Llama Stack API可以轻松集成


Meta这次可谓是将开源的精神贯彻到底,同时大方放出的,还有一篇90多页的论文。
HuggingFace首席科学家Thomas Wolf赞赏道:如果想从0开始研究大模型,你需要的就是这篇paper!
它简直无所不包——预训练数据、过滤、退火、合成数据、缩放定律、基础设施、并行处理、训练方法、训练后适应、工具使用、基准测试、推理策略、量化、视觉、语音和视频……
AI2的研究员Nathan Lambert估计,这份90页的Llama 3.1论文,将直接把开源模型的进展往前推上3-9个月!

Meta CEO小扎则自豪地写下一篇长文:开源人工智能是前进的道路。

在纽约时报的采访中,小扎力挺开源AI
在这篇文章中,小扎感慨地回忆了Meta在LLM浪潮中的翻身之路——
去年,Llama 2只能与边缘的旧模型相提并论;今年,Llama 3在某些方面已经领先于最先进的模型;明年开始,未来的Llama模型将成为最先进的模型。
对于自己被多次问到的「是否担心开源Llama而失去技术优势」,小扎直接以Linux自比。
他表示,曾经大科技公司都大力投资于自己的Unix版本,然而最终还是开源Linux胜出了,因为它允许开发者随意修改代码,更先进、更安全、生态更广泛。
AI,也必将以类似方式发展。
为此,Meta特地放宽了自己的许可,首次允许开发者使用Llama 3.1模型的高质量输出,来改进和开发第三方AI模型。

网友:一个新时代开始
Llama 3.1正式解禁后,在全网掀起轩然大波。
AI大神Karpathy随即发表了一些自己的感想:
今天,随着405B模型的发布,GPT-4/Claude 3.5 Sonnet级别的前沿大模型首次对所有人开放供大家使用和构建。。其权重开源,商用许可、允许生成合成数据、蒸馏和微调模型。
这是Meta发布的一个真正开放的前沿LLM。除此以外,他们还放出了长达92页的技术报告,其中包含有大量模型细节:https://ai.meta.com/research/publications/the-llama-3-herd-of-models/

这次模型发布背后的理念,在小扎的一篇长文中有详细阐述,非常值得一读,因为它很好地涵盖了支持开放AI生态系统世界观的所有主要观点和论点:
开源AI是未来。
我常说,现在仍处于早期阶段,就像计算机发展的1980年代重现一样,LLM是下一个重要的计算范式,而Meta显然正定位自己为其开放生态系统的领导者。
- 人们将对这些模型进行提示和使用RAG
- 人们将对模型进行微调
- 人们将把它们蒸馏成更小的专家模型,用于特定任务和应用
- 人们对其进行研究、基准测试、优化
另外,开放生态系统还以模块化的方式自组织成产品、应用和服务,每个参与方都可以贡献自己的独特专业知识。
一个例子是,AI芯片初创Groq已经集成了Llama 3.1模型,几乎能实现8B模型瞬间推理。
Karpathy称,由于服务器压力,自己似乎无法尝试运行在Groq上的405B可能是今天能力最强、最快的大模型。

他还预计,闭源模型们很快就会追赶上来,并对此非常期待。
Meta研究员田渊栋称,一个新的时代已经开始!开源LLM现在与闭源LLM不相上下/更胜一筹!

开源模型新王者诞生了。

OpenPipe创始人在测试完经过微调的Llama 3.1 8B后感慨道:从未有过如此小且如此强大的开源模型——它在每个任务上的表现都优于GPT-4o mini!


英伟达高级科学家Jim Fan表示,GPT-4的力量就在我们手中。这是一个具有历史性意义的时刻。

鲜有人关注AI模型训练背后的基础设施,Pytorch之父Soumith Chintala站出来表示,在16000块GPU搭建的设施中,也会遇到失败的时候。
这些细节都藏在了Llama 3.1的论文中,包括如何并行化、保持系统可靠性。值得一提的是,Meta团队在模型训练中实现了90%的有效训练时间。
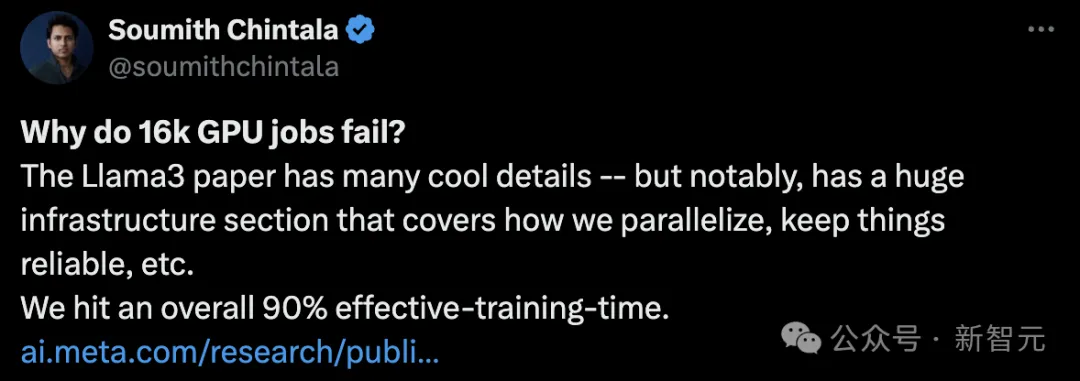

有网友细数了Llama模型迭代过程中,GPU的用量也在不断增长。
Llama 1:2048块GPU
Llama 2:4096块GPU
Llama 3.1:16384块GPU(其实,Llama 3是在两个拥有24,000块GPU集群完成训练)
Llama 4:......

最强开源模型家族
其实,关于Llama 3.1系列模型一些要点,在昨天基本上被剧透得体无完肤了。
正如泄露信息所述,Llama 3.1可以支持8种语言(英语,德语、法语、意大利语、葡萄牙语、印地语、西班牙语和泰语),多语言对话智能体、翻译用例等。
在上下文长度上,比起Llama 2、Llama 3,Llama 3.1系列模型中所有上下文增加了16倍,为128K。

Meta强调,Llama 3.1还在工具使用方面得到了改进,支持零样本工具使用,包括网络搜索、数学运算和代码执行。
基于长上下文,模型不仅知道何时使用工具,还能理解如何使用以及如何解释结果。
此外, 通过微调,Llama 3.1在调用自定义工具方面提供了强大的灵活性。

首先,Llama 3.1可以作为一个能够执行「智能体」任务的系统来运行:
- 分解任务并进行多步骤推理
- 使用工具
- 内置工具:模型自带对搜索或代码解释器等工具的知识
- 零样本学习:模型可以通过以前未见过的上下文工具定义来学会调用工具
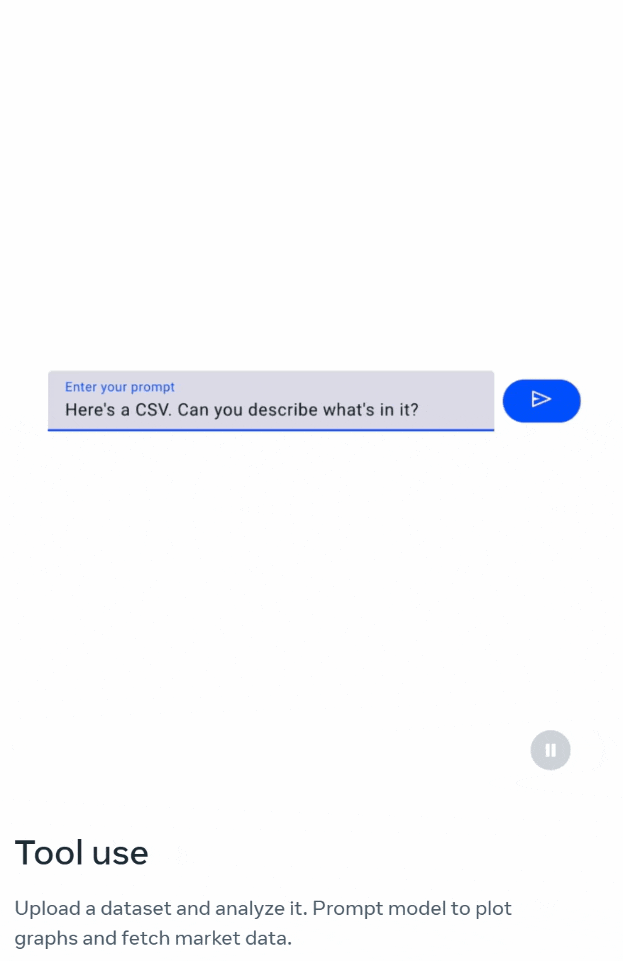
比如问模型:「这是一个CSV文件,你可以描述它里面有什么吗?」
它会识别出:这份CSV文件包含了多年的每月通货膨胀率,年份一栏表示了每组每月通货膨胀率的年份。

接下来,我们可以要求它按时间序列绘制图表。
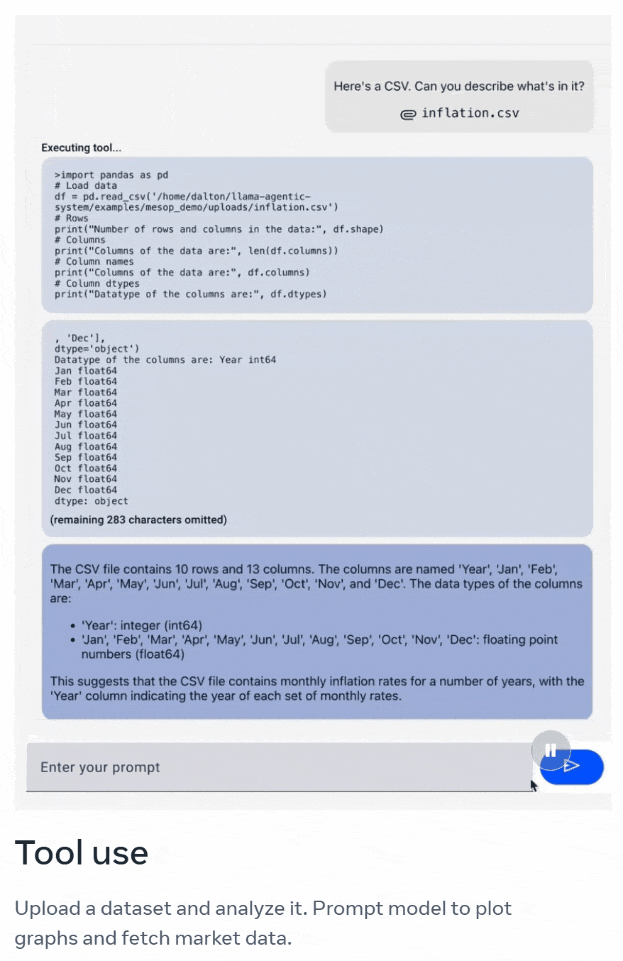
接下来,它还能完成一系列刁钻的任务,比如在同一图表中绘制S&P500的走势图。

完成之后,还能重新调整图表,把信息加到不同的坐标轴上。

如上所示,Llama 3.1支持8种语言,因此可以胜任多语言的翻译。
我们可以让它将童话故事《汉泽尔与格莱特》(糖果屋)翻译成西班牙语。

即使面对比较复杂的推理题,Llama 3.1也能轻松拿下。
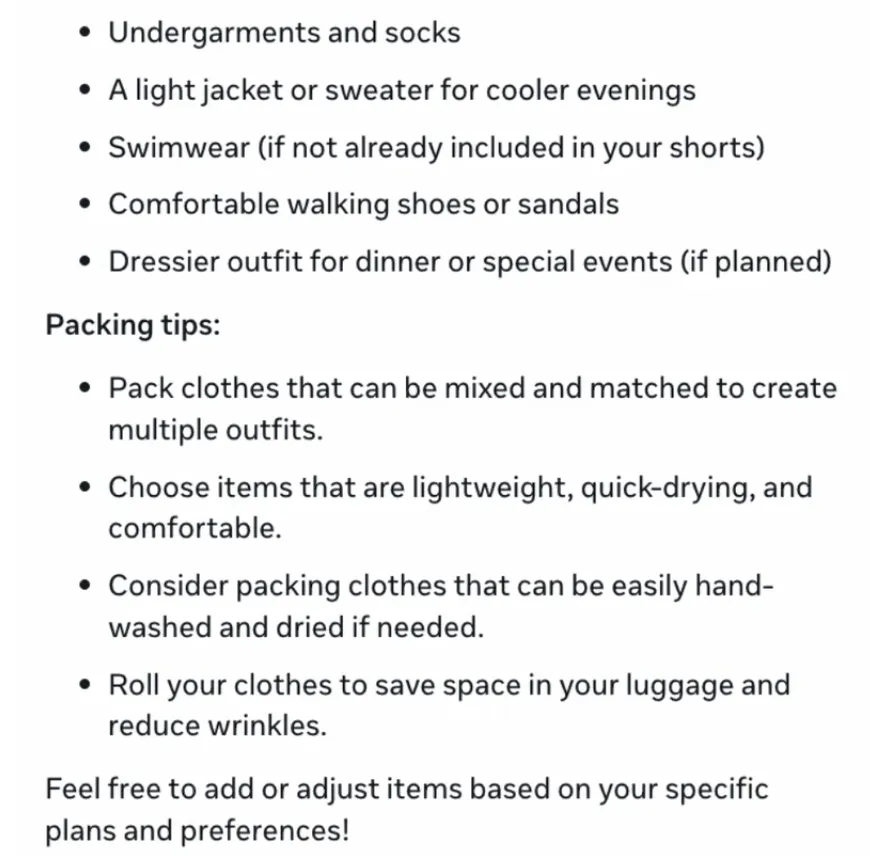
「我有3件衬衫、5条短裤和1条连衣裙。我要出行10天,这些衣服够我度假用吗」?
AI将已知的条件,进行分解,对上衣、短裤、裙子设想了一个合理的搭配方案,并建议最好多带几件上衣。

在推理完成后,它还贴心地为我们提供了更详细的出行穿衣指南、行李清单。
我们还可以让AI手写代码。
比如让它创建一个程序,使用递归回溯算法或深度优先搜索算法生成一个完美迷宫,并且可以自定义大小和复杂度。
只见AI一上手,直出迷宫程序的Python代码。

代码完成后,AI还给出了详细的解释。

再接下来,若想自定义程序,AI代码助手为我们提供了相应的代码建议——调整宽度和高度。

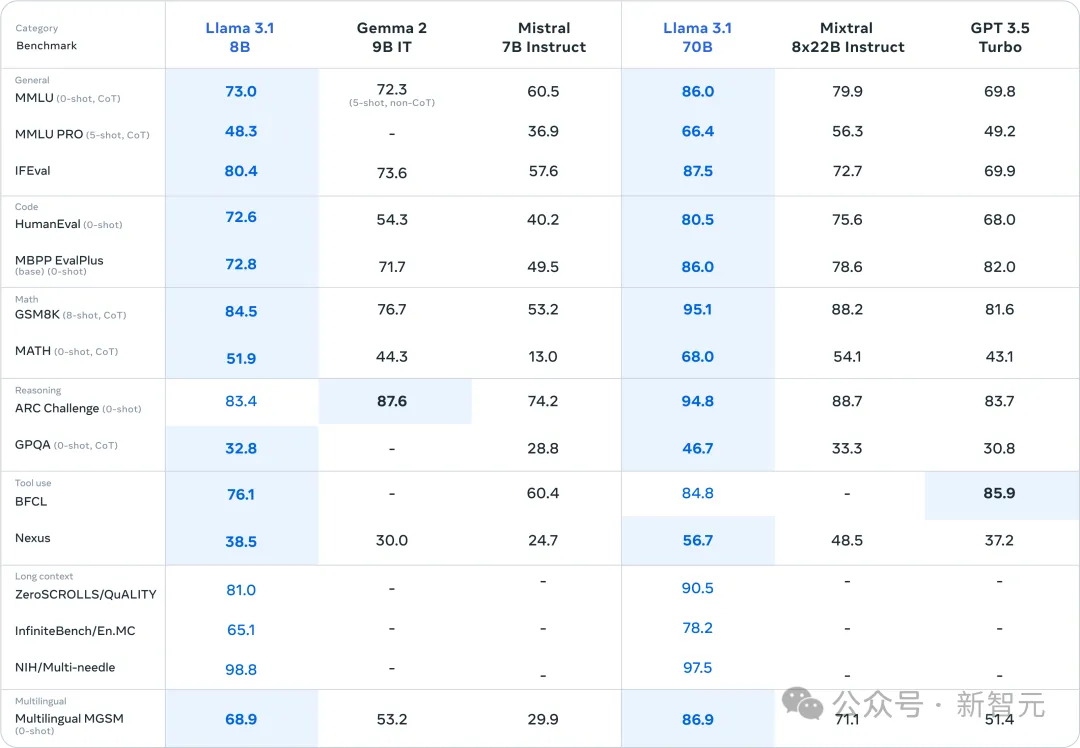
为了评估Llama3.1的表现,Meta不仅在测试中囊括了150个涵盖多语种的基准数据集,并且还在真实场景中进行了比较。
在多种任务中,405B都可以和GPT-4、GPT-4o、Claude 3.5 Sonnet等闭源领先模型掰手腕。

而8B和70B的小模型,在参数量相似的闭源和开源模型中,同样表现出色。
除了长上下文任务,8B和70B模型在通用任务、代码、数学、推理、工具使用、多语言上,取得了SOTA。
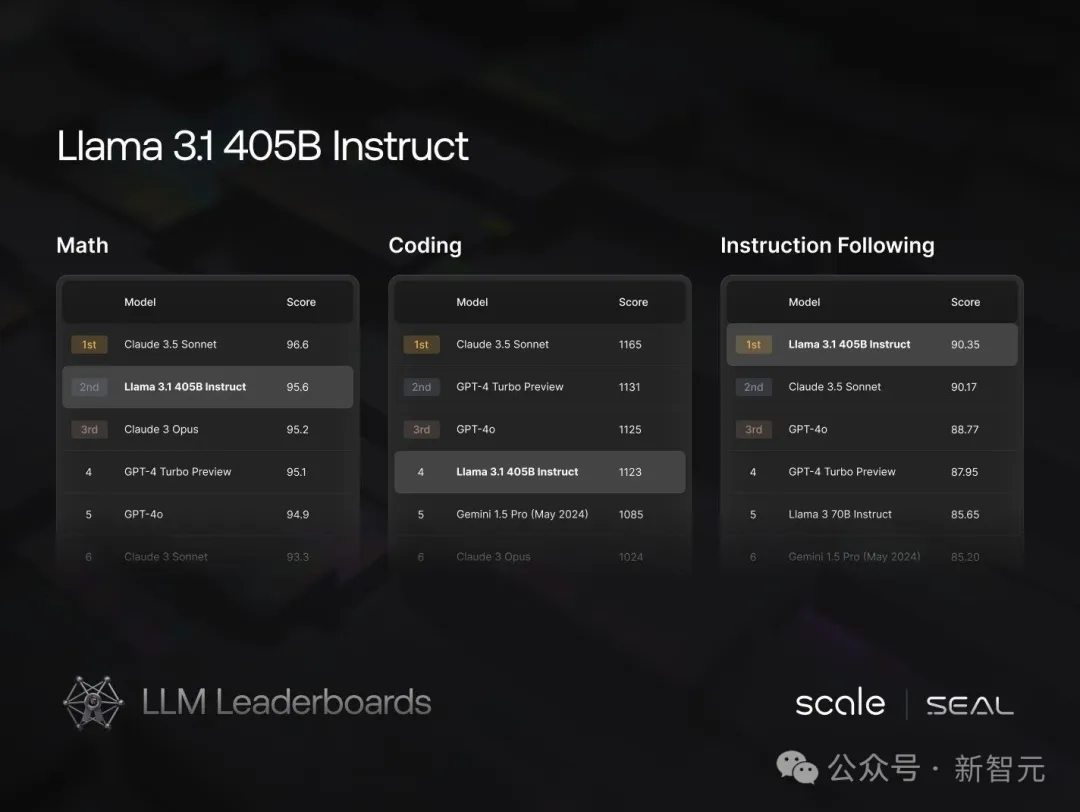
人类评估中,Llama 3.1 405B模型与GPT-4不相上下,但略逊于GPT-4o。
不过,在与Claude 3.5 Sonnet相较下,405B大模型更有优势,胜率为24.9%。

此外,在Scale的排行榜中,Llama 3.1 405B微调版本在指令跟随评估中,碾压Claude 3.5 Sonnet、GPT-4o。
在数学任务中,405B仅次于Claude 3.5 Sonnet,位列第二。不过,Llama 3.1在代码任务上,得分相对较低。
92页超详技术报告
没有谁能够像Meta一样开源彻底,92页超长技术报告,也在今天一并放出。

论文地址:https://ai.meta.com/research/publications/the-llama-3-herd-of-models/
论文提出,Llama 3.1这种高质量的基座模型有3个关键杠杆:数据、规模以及复杂度管理。
数据方面,相比前代,Llama 3.1的数据总量和质量都有所提高,比如对预训练数据更仔细的预处理和管理管道,以及对训练后数据更严格的质量保证和过滤方法。
Llama 2仅在1.8T token的数据上进行预训练,而Llama 3.1的多语言预训练语料则达到了15.6T token,有超过8倍的增长。
规模方面,Llama 3.1的训练使用了超过1.6万个英伟达H100 GPU,计算总量达到3.8e25 FLOPS,几乎是Llama 2的50×。
为了更好地实现「scale up」,论文特别提出了「复杂度管理」这个方面。在选择模型架构和算法时,需要更关注其稳定性和可扩展性。
值得关注的是,Llama 3.1并没有使用最受关注的MoE架构,而是decoder-only架构的稠密Transformer,仅将原始的Transformer架构进行过一些修改和调整,以最大化训练稳定性。
类似的做法还有,使用SFT、RS、DPO等简洁的训练后流程,而不是更复杂的强化学习算法。
和许多大模型类似,Llama 3的开发也主要包括两个阶段:预训练和后训练。
预训练时同样使用「预测下一个token」作为训练目标,首先将上下文窗口设定为8K,之后在继续预训练阶段扩展到128K。
后训练阶段通过多个轮次迭代的人类反馈来改进模型,显著提升了编码和推理性能,并整合了工具使用的能力。
此外,论文还尝试使用3个额外阶段为Llama 3.1添加图像、视频、语音等多模态功能:
- 多模态编码器预训练:图像和语音的编码器分开训练,前者的预训练数据是图像-文本对,后者则采用自监督方法,尝试通过离散化的token重建语音中被掩码的部分。
- 视觉适配器:由一系列跨注意力层组成,将图像编码器的表示注入到经过预训练的语言模型中。以图像为基础,论文还尝试在视频-文本对上训练了视频适配器。
- 语音适配器:连接语音编码器和语言模型,此外还集成了「文本到语音」系统。

遗憾的是,上述的多模态功能依旧在开发阶段,因此没有包含在新发布的Llama 3.1中。
Llama 3.1依旧使用标准的稠密Transformer,与Llama和Llama 2在架构方面并没有显著差异,性能的改进主要来自训练数据质量、多样性的提升,以及规模扩展。

与Llama 3相比,Llama 3.1的架构有以下改进:
- 分组查询注意力(GQA):带有8个键-值头,提升推理速度并减少解码时的KV缓存
- 注意力掩码:防止同一序列中不同文档之间出现自注意力。这个技巧在标准预训练中效果有限,但对很长的序列进行继续预训练时非常重要
- 128K token词表:包括tiktoken中的100K以及额外的28K,以更好支持非英语语言。与Llama 2相比,同时提高了英语和非英语的压缩比率
- 将RoPE的超参数θ设置为500,000:更好支持长上下文
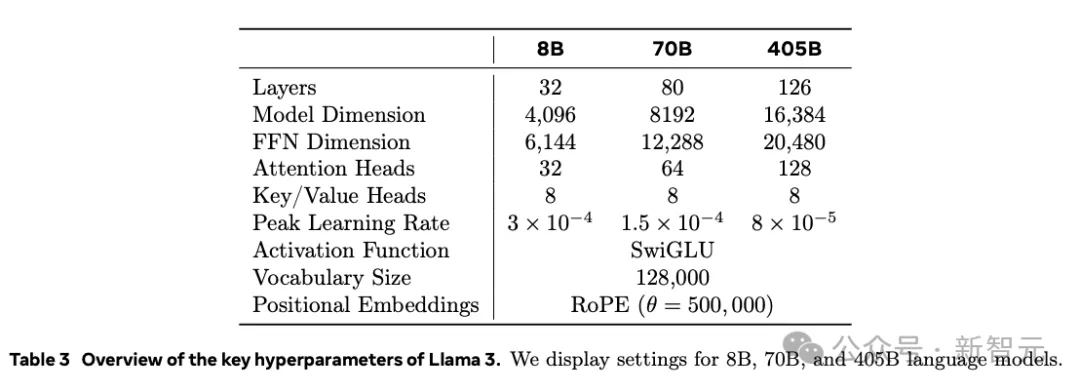
模型的关键超参数如表3所示,基于数据量和训练算力,模型的大小达到了Scaling Law所揭示的算力最优化。
要在1.6万张GPU上训练405B的模型,仅仅是考虑并行和故障处理,就已经是一个大工程了。
除了模型本身,论文对训练过程使用的并行化方案,以及存储、网络等基础设施都进行了阐述。
Llama 3.1的训练采用4D并行(张量+流水线+上下文+数据),在BF16精度下,GPU利用率(MFU)约为38%~41%。

Llama 3.1训练集群的故障处理也十分出色,达到了超过90%的有效训练时间,但这依旧意味着,总共54天的预训练过程中,每天都至少有一次中断。
论文将全部419次意外中断的故障原因都详细列出(表5),对未来的GPU集群搭建有非常重要的借鉴意义。其中确认或怀疑与硬件相关的问题占比达到了78%。

由于集群的自动化运维比较完善,尽管故障次数多,但大部分都可以被自动处理。整个过程中,只有3次故障需要手动干预。
代码
为了提高模型的编码能力,Meta采用了训练代码专家、生成SFT合成数据、通过系统提示引导改进格式,以及创建质量过滤器(从训练数据中删除不良样本)等方法。

使用Llama 3将Python代码(左)转换为PHP代码(右),以使用更广泛的编程语言来扩充SFT数据集

通过系统提升,让代码质量提高。左:无系统提示 右:有系统提示
多语种
为了提高Llama 3的多语种能力,Meta专门训练了一个能够处理更多多语言数据的专家,从而获取和生成高质量的多语言指令微调数据(如德语、法语、意大利语、葡萄牙语、印地语、西班牙语和泰语),并解决多语言引导中的特定挑战。

数学推理
训练擅长数学推理的模型,面临着几大挑战,比如缺乏提示、缺乏真实的CoT、不正确的中间步骤、需要教模型使用外部工具、训练和推理之间的差异等。
为此,Meta采用了以下方法:解决提示不足问题、增强训练数据中的逐步推理过程、过滤错误的推理过程、结合代码和文本推理、从反馈和错误中学习。

长上下文
在最后的预训练阶段,Meta将Llama 3的上下文长度从8K token扩展到128K。
在实践中团队发现,如果仅使用短上下文数据进行SFT,会导致模型长上下文能力显著退化;而阅读冗长的上下文非常乏味、耗时,所以让人类标注此类示例也是不切实际的。
因此,Meta选择了合成数据来填补这一空白。
他们使用Llama 3的早期版本,生成了基于关键长上下文用例的合成数据:(多轮)问答、长文档摘要、代码库推理。
工具使用
Meta训练了Llama 3与搜索引擎、Python解释器、数学计算引擎交互。
在开发过程中,随着Llama 3的逐步改进,Meta也逐渐复杂化了人工标注协议。从单轮工具使用标注开始,转向对话中的工具使用,最后进行多步工具使用和数据分析的标注。

Llama 3执行多步骤规划、推理和工具调用来解决任务
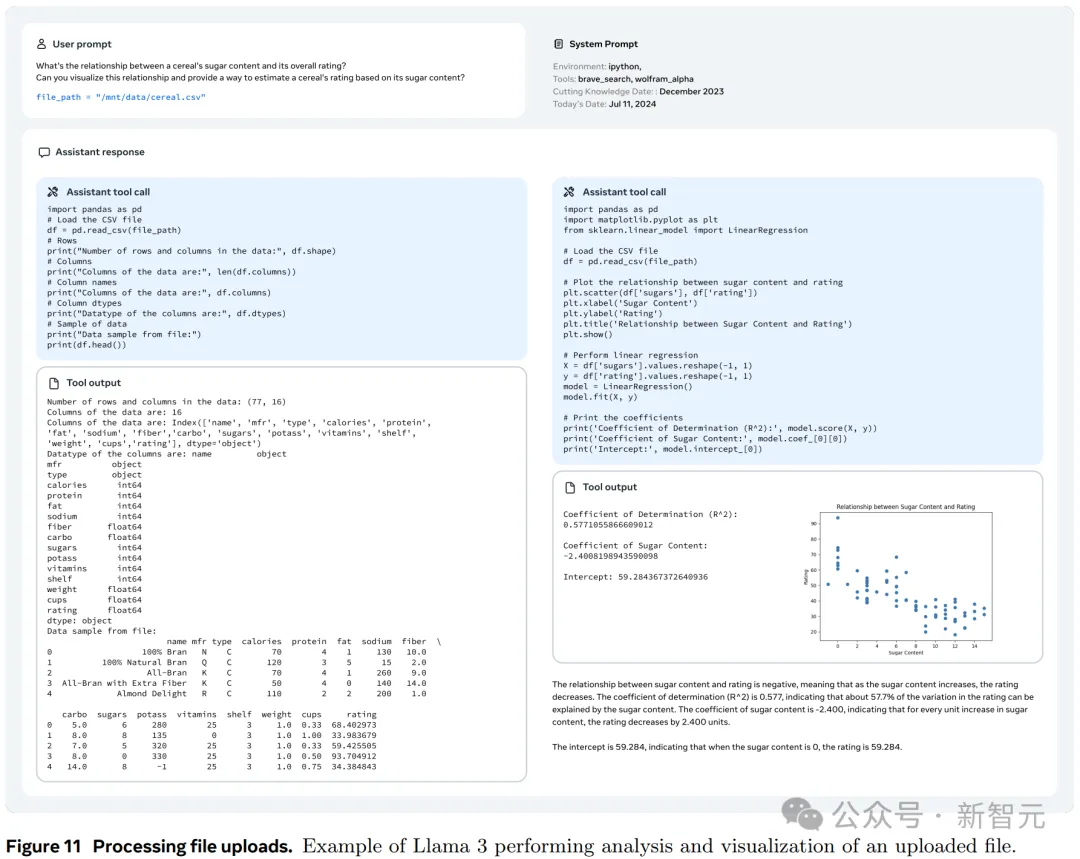
基于提供文件,要求模型总结文件内容、查找并修复错误、优化代码、执行数据分析或可视化等
事实性
对于LLM的公认挑战幻觉问题,Meta采取了幻觉优先的方法。
他们遵循的原则是,训练后应该使模型「知道它知道什么」,而不是添加知识。
可操纵性
对于Llama 3,Meta通过带有自然语言指令的系统提示,来增强其可操纵性,特别是在响应长度、格式、语气和角色/人格方面。

「你是一个乐于助人、开朗的AI聊天机器人,为忙碌的家庭充当膳食计划助手」
团队成员
Llama 3的团队可以说非常庞大,单核心成员而言就达到了差不多220人,其他贡献者也有312人之多。


小扎:开源AI是未来
众所周知,小扎一直是开源AI的忠诚拥趸者。
这次不仅是发布一个新的最强模型那么简单,而是誓要让开源AI走上神坛。

在博客中,小扎直接以史为鉴,曾经,各大科技公司都投入巨资埋头开发封闭源Unix版本。
Unix战场打得火热,没想到笑到最后的却是开源的Linux。

Linux最初是因为它允许开发者随意修改代码,并且价格更实惠,广受开发者青睐。
但随着时间的推移,它变得更加先进、更安全,并且拥有比任何封闭的Unix更广泛的生态系统支持更多的功能。
今天,Linux已成为云计算和大多数移动设备操作系统的行业标准,而所有人都因此受益。
小扎相信,AI的发展轨迹也将如此,并且将矛头直指「几家科技公司」的闭源模型。

「今天,几家科技公司正在开发领先的封闭模型,但开源正在迅速缩小差距。」
小扎敢直接点名自然有他的实力作为底气,去年,Llama 2还落后于前沿的旧一代模型。
而今年,Llama 3在性能方面已经能与其他巨头大模型分庭抗礼了。
Llama 3.1 405B作为第一个前沿级别的开源AI模型,除了相对于封闭模型显著更好的成本/性能比之外,405B模型的开放性使其成为微调和蒸馏小型模型的最佳选择。
对于开发者来说,坚持开源模型有五大好处:
第一,开源模型允许开发者自由地训练、微调和蒸馏自己的模型。
每个开发者的需求不同,设备上的任务和分类任务需要小模型,而更复杂的任务则需要大模型。
利用最先进的开源模型,开发者可以用自己的数据继续训练,并蒸馏成理想大小。
第二,可以避免被单一供应商限制。
开发者不希望依赖于自己无法运行和控制的模型,也不希望供应商改变模型、修改使用条款,甚至完全停止服务。
而开源使得模型可以轻松切换和部署,从而打造一个广泛的生态系统。
第三,保护数据安全。
开发者在处理敏感数据时,需要确保数据的安全,这就要求他们不能通过API发送给闭源模型。
众所周知,由于开发过程更透明,因此开源软件通常更安全。
第四,运行高效且成本更低。
开发者运行Llama 3.1 405B的推理成本只有GPT-4o的一半,无论是用户端还是离线推理任务。
第五,长远眼光来看,开源将成为全行业标准。
实际上,开源的发展速度比闭源模型更快,而开发者也希望能够在长期具有优势的架构上构建自己的系统。
在小扎看来,Llama 3.1的发布将成为行业转折点,让开源变得愈发势不可挡。
文章来源于“新智元”,作者“新智元”




【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
