# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
AI时代,数据就是新的石油。全球人类数据逐渐枯竭的时代,合成数据是我们的未来吗?
最近Nature封面一篇论文引起的风波,让我们明白:重要的并不是「合成数据」,而是「正确使用合成数据」。
本周四,牛津、剑桥、帝国理工、多伦多大学等机构的一篇论文登上了Nature封面。

不过,让人没想到的是,论文一经刊出便引发了AI社区的大量讨论。


一些人认为,问题的核心不在「合成数据」上,而是在「数据质量」上。
即使全部用的是人工数据,如果质量太差,那结果一样也是「垃圾进垃圾出」。


甚至,有人觉得研究者故意采用了与实际操作不匹配的方法,实际上是在「哗众取宠」。

对此,马毅教授表示,如今我们已经走进了缺少科学思想和方法的时代——
许多研究,不过都是重新发现一些科学常识。

如何避免模型崩溃?
那么问题来了,在使用AI合成数据时,如何才能避免发生模型崩溃呢?
对于这篇Nature封面的文章,Scale AI的CEO Alexandr Wang深表赞同。
他表示,利用纯合成数据来训练模型,是不会带来信息增益的。
通常,当评估指标因「自蒸馏」(self-distillation)而上升时,大概率是因为一些更隐蔽的权衡:

具体而言,在连续几代的合成训练中,错误主要来自三个方面:
也就是,每次你用上一个模型生成的数据来训练新模型时,都会丢失一些信息和精度,导致模型变得越来越空洞,最终无法正常工作。
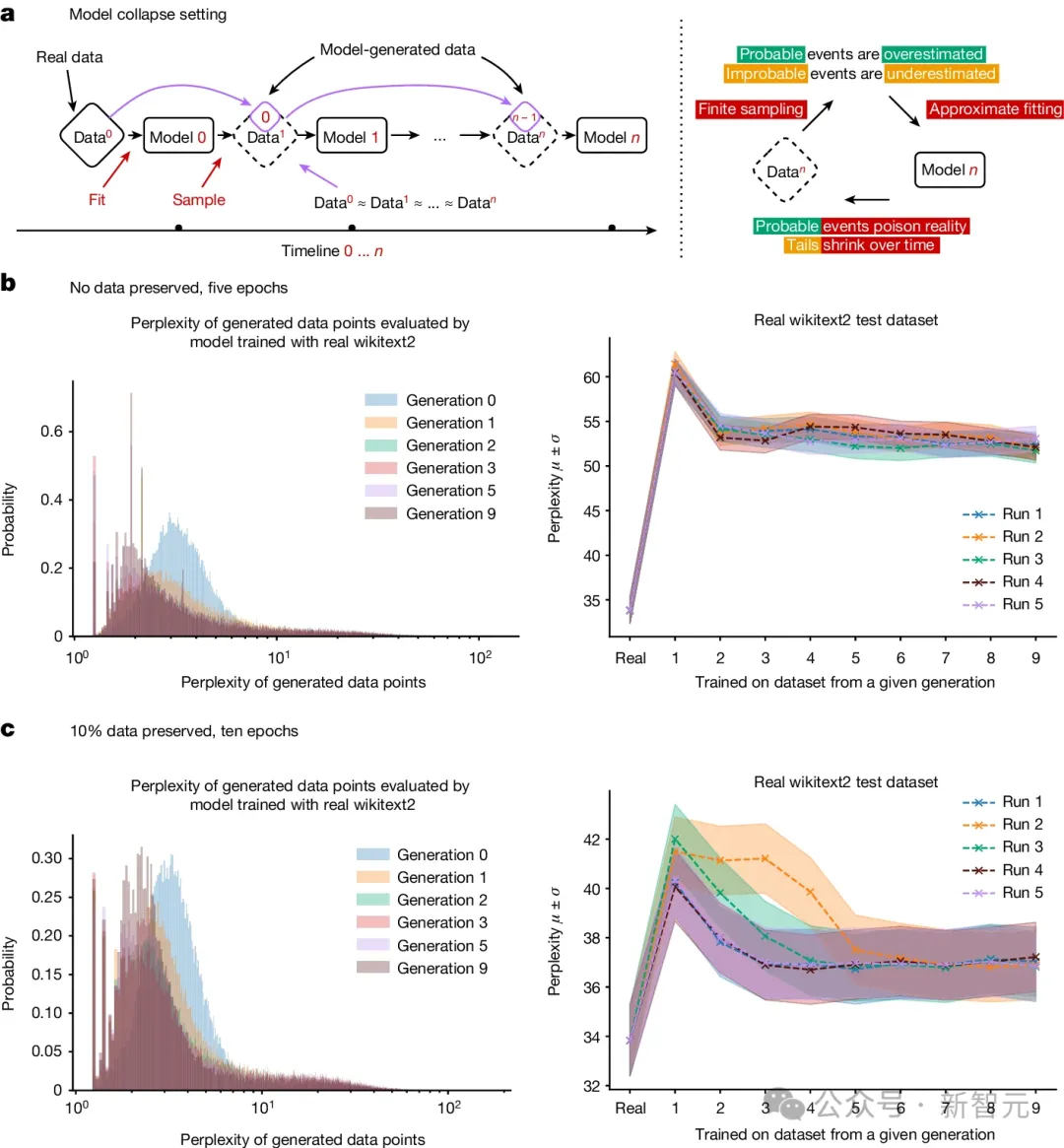
虽然这些实验是在小规模模型(100M参数)上进行的,但观察到的基本效应也会随着时间的推移在更大规模的模型上出现。
例如,今天的大多数模型无法生成像Slate Star Codex风格的博客文章,这也是由于模型崩溃的原因。随着我们连续训练模型,它们逐渐失去了在广泛分布上进行预测的能力。

在Wang看来,混合数据(Hybrid Data)才是未来的发展方向,它能够避免所有与模型崩溃相关的棘手问题。
也就是说,在合成数据的过程中,必须通过某种新的信息来源来生成:
(1)使用真实世界数据作为种子
(2)人类专家参与
(3)形式逻辑引擎
相比之下,那些不慎使用了无信息增益的合成数据来训练模型的开发者,终将会发现他们的模型随着时间的推移变得越来越奇怪和愚蠢。
来自Meta、纽约大学和北京大学的研究人员,提出了一种通过人类或较弱模型的「排序-修剪反馈」方法,可以恢复甚至超越模型原来的性能。
对于这项研究,LeCun也进行了转发,表示支持。
众所周知,不管是对于人类还是机器来说,区分一个示例的好坏,要远比从头生成一个高质量的样本容易得多。
基于此,作者提出了一种全新的方法——通过合成数据反馈来防止模型崩溃。

论文地址:https://arxiv.org/abs/2406.07515
为了研究这个问题,作者首先在理论环境中提供了分析结果。
在这里,作者提出了高维极限下的高斯混合模型和线性模型作为分类器,并让一个验证者(例如人类或oracle)来选择或修剪生成的数据。
结果显示,当合成数据点的数量趋于无限时,基于选定数据训练的模型可以达到与原始数据训练相媲美的最佳结果。
在合成数据上的模拟显示,与使用原始标注相比,oracle监督始终能产生接近最佳的结果。
此外,由于通过人类监督来分辨高质量数据比直接人类标注更简单且成本更低,这为人类参与监督的有效性提供了有力的证据。
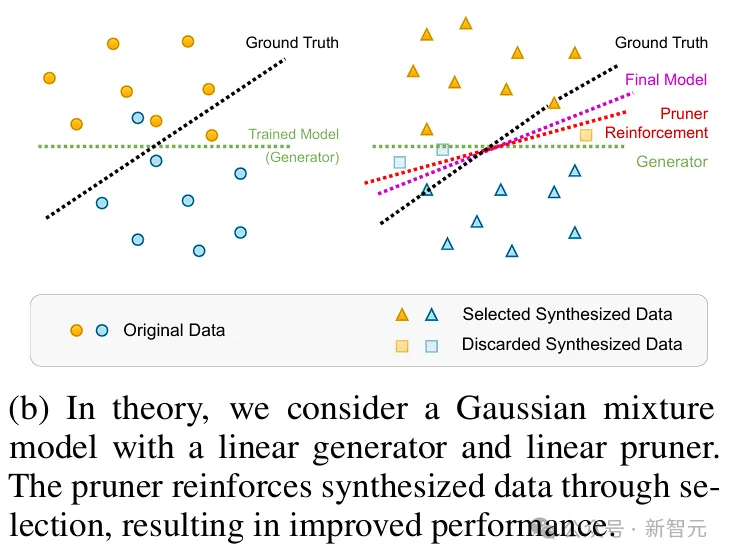
一个具有线性生成器和线性剪枝器的高斯混合模型:其中的剪枝器通过选择强化合成数据来提高性能
接下来,作者进行了两个大规模的实验:
1. 在算术任务(矩阵特征值预测)上训练Transformer,并使用与真实值的距离来修剪大量合成数据
2. 使用大语言模型(Llama 2)和有限的合成数据进行新闻摘要
结果显示,在这两种情况下,仅依赖生成数据会导致性能下降,即使数据量增加,也会出现模型崩溃。
并且,仅根据困惑度从生成池中选择最佳解决方案并不会提升性能,即模型本身缺乏基于困惑度选择最佳预测的能力。
相反,在oracle监督下,可以获得一个基于反馈增强的合成数据集,其性能随着数据量的增加而超过了原始数据集。
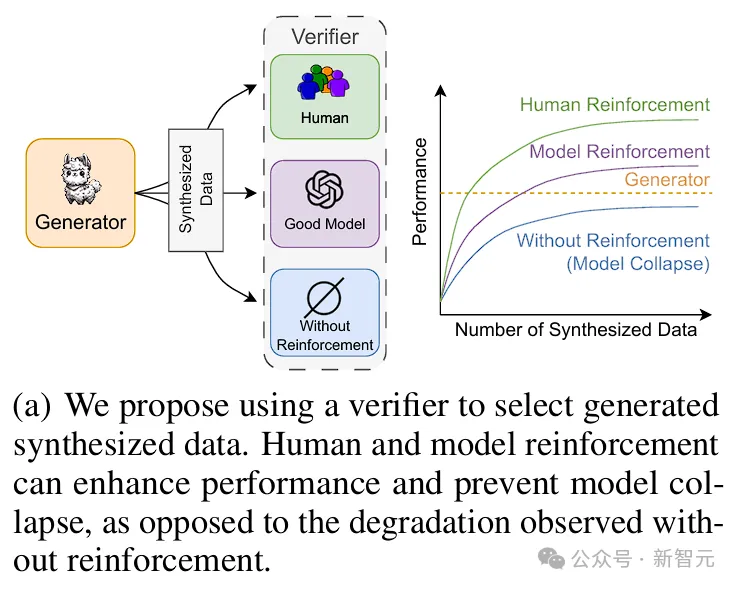
通过人类和模型的强化,可以提升性能并防止模型崩溃;而在没有强化的情况下则会出现性能下降
因此,在用合成数据训练新模型时,不仅要关注生成器的质量,还需要一个高质量的验证者来选择数据。
一句话总结就是:reinforcement is all you need!
对于读者们对于这篇Nature封面论文的吐槽,斯坦福大学的博士生Rylan Schaeffer表示理解。
他指出,模型崩溃通常出现在研究人员故意采用与实际操作不匹配的方法时。
数据积累可以崩溃,也可以不崩溃,这完全取决于具体的操作细节。
你们故意把它弄崩溃,它当然就会崩溃了。????

在这篇斯坦福、马里兰和MIT等机构合著的论文中,Schaeffer研究了积累数据对模型崩溃有何影响。
经过实验后他们确认,用每一代的合成数据替换原始的真实数据,确实会导致模型崩溃。
但是,如果将连续几代的合成数据与原始的真实数据一起积累,可以避免模型崩溃。

论文地址:https://arxiv.org/abs/2404.01413
在实践中,后代LLM会随着时间推移,在不断增加的数据中进行训练,比如Llama 1需要1.4万亿个token,Llama 2需要2万亿个token,Llama 3需要15万亿个token。
从某种意义上说,这种数据积累设定是极其悲观的——
在这个假设的未来中,合成数据被不受控制地倾倒在互联网上,用于训练模型的下一次迭代。
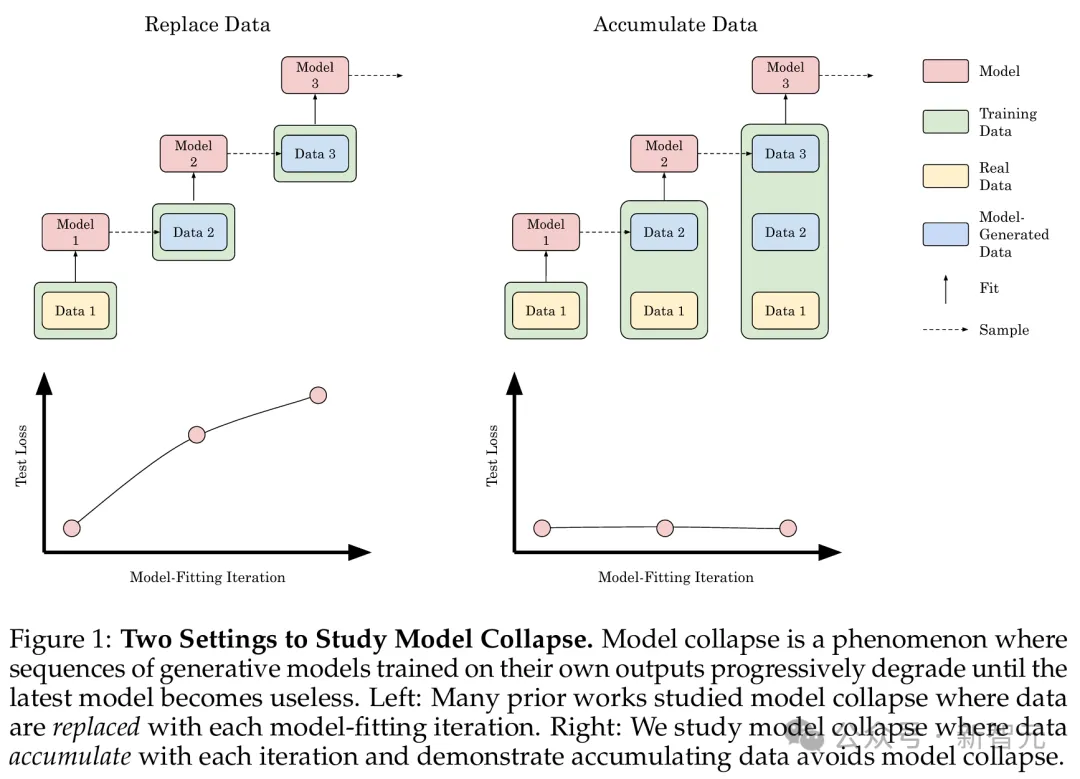
如图右侧所示,积累数据可以避免模型崩溃
研究者使用了因果Transformer、扩散模型和自变分编码器三种不同的实验设置,分别在真实文本、分子构象和图像数据集上进行了训练。
他们发现,替换数据会导致所有模型和所有数据集的模型崩溃,而积累数据可以避免模型崩溃。
基于Tranformer的因果语言建模
首先,他们在文本数据上训练了因果Transformer。
具体来说,就是在TinyS-tories上预训练了单个epoch的9M参数GPT-2和 12M、42M和125M参数的Llama 2语言模型。
前者是一个470M token的,GPT-3.5/4生成的幼儿园阅读水平的短篇故事数据集。
对于每次模型拟合迭代n≥2,研究者会从上一次迭代的语言型中采样一个与TinvStories大小相同的新数据集,然后用新生成的数据集替换或连接以前的数据集。
在每次模型拟合迭代中,他们会来自上一次迭代的替换或串联数据集来预训练一个新的初始化模型。
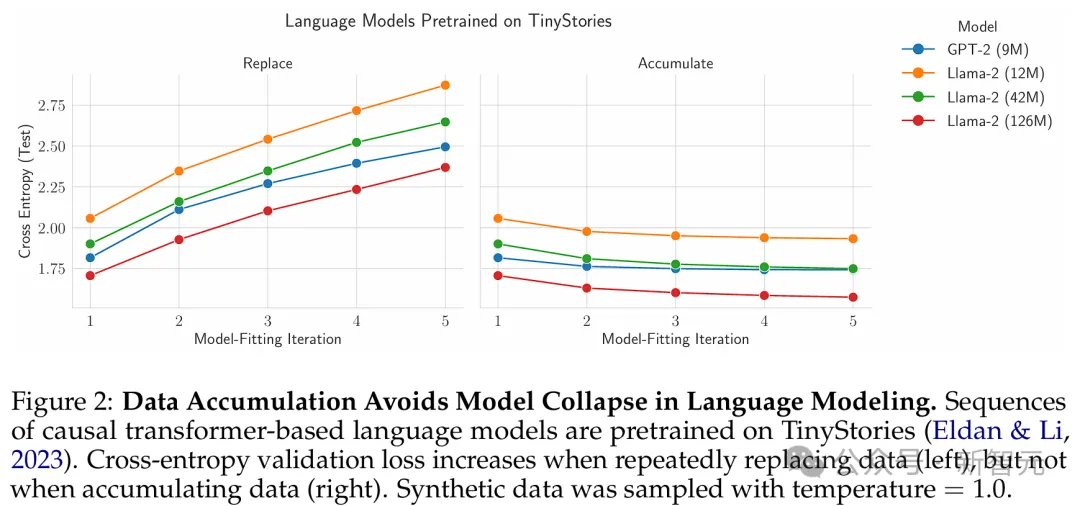
结果显示,对于所有架构、参数计数和采样温度,随着模型拟合迭代次数的增加,替换数据会导致测试交叉熵的增加(图2左)。
同时他们还发现,对于所有架构、参数计数和采样温度,随着模型拟合迭代次数的增加,积累的数据会导致测试交叉熵等于或更低(图2右)。
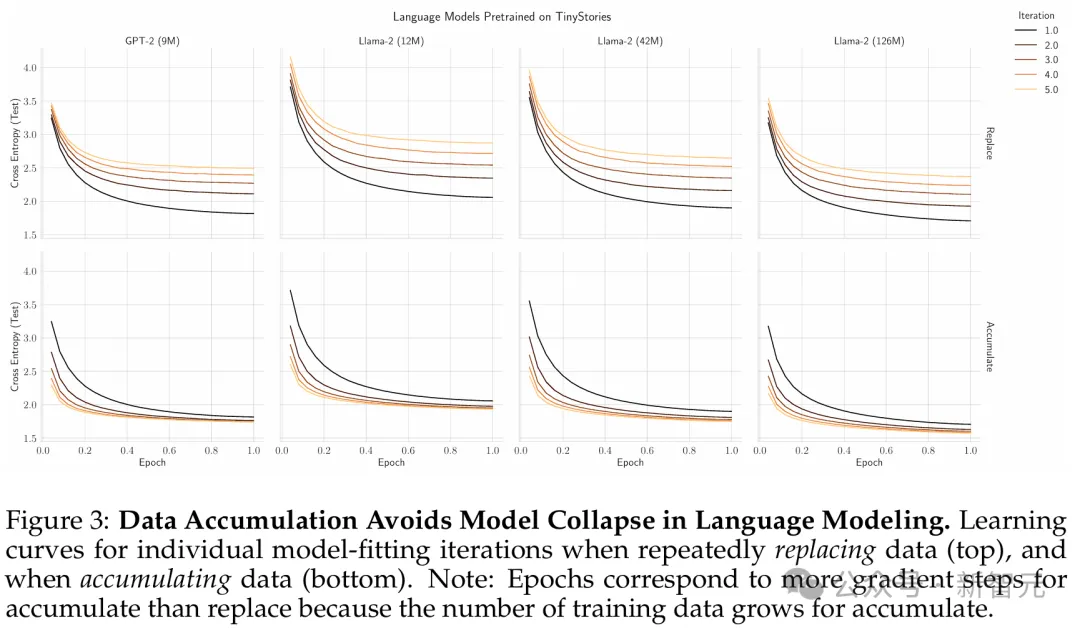
图3是重复替换数据(顶部)和积累数据(底部)时各个模型拟合迭代的学习曲线。
结果显示,数据积累避免了语言建模中的模型崩溃。
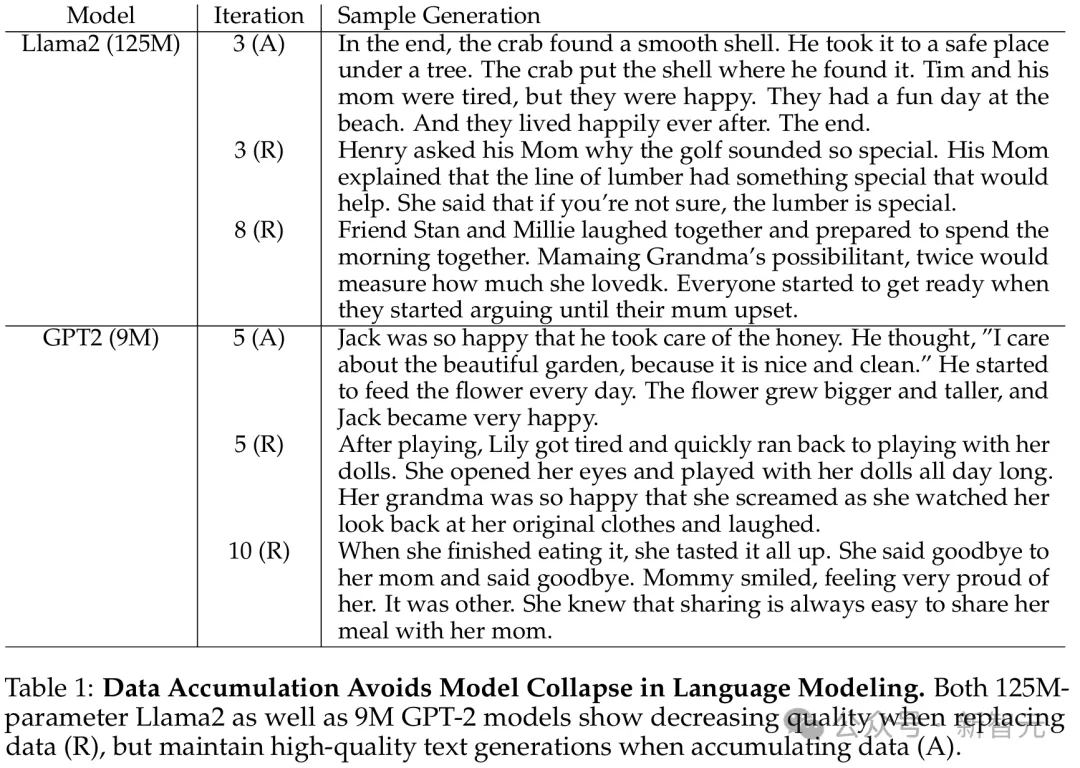
125M的Llama2和9M的GPT-2,在替换数据(R)时都表现出了质量下降,但在积累数据(A)时,却保持了高质量的文本生成。
分子构象数据的扩散模型
接下来,他们在分子构象数据上训练扩散模型序列。
具体来说,研究者在GEOMDrugs数据集上训练了GeoDiff,这是一种用于分子构象生成的几何扩散模型。
他们将GEOM-Drugs数据集的训练部分下采样到40,000个分子构象,将其用作初始训练集,并为每个预测执行50个扩散步骤。
结果经过8次模型拟合迭代,研究者发现:替换数据时测试损失增加,这与我们的语言模型实验相匹配,并且累积数据时测试损失保持相对恒定(图4)。
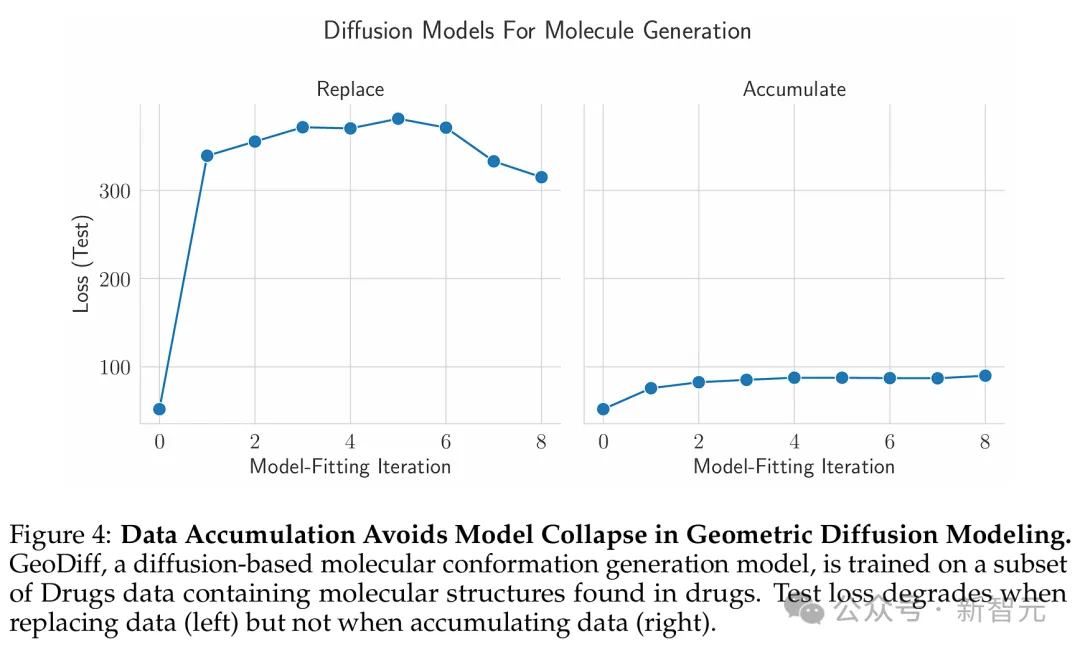
与语言模型不同,他们发现,当替换数据时,在合成数据训练的第一次模型拟合迭代中,性能会显著恶化,并且在后续迭代中不会进一步大幅下降。
图像数据的自变分编码器
实验最后,研究者在CelebA上训练了自变分编码器(VAE)序列,该数据集包含了20万张人脸图像,分为训练集和测试集。
这种选择,在具有许多样本、彩色图像和分辨率的现实数据集,和在累积数据上训练模型多次迭代的计算可行性之间,达到了平衡。
结果他们发现,在每次迭代中替换数据再次表现出模型崩溃——
测试误差会随着每次额外的迭代而迅速上升,并且每次迭代产生的质量较低且生成的面孔多样性较少,直到所有模型生成都代表单一模式。

相比之下,在每次迭代中,积累数据会显著减缓模型崩溃——
随着每次额外的迭代,测试误差的增加速度显著减慢。
虽然与图6的中图和右图相比,世代的多样性确实下降了,它仍然代表数据集中变化的主要轴,例如性别,但模型似乎不再沿着数据流形的更短轴生成其他细节,例如眼镜和配件。
还有一个有趣的现象是,与语言建模不同,积累数据的测试误差确实会随着迭代次数的增加而增加(尽管比替换数据慢得多)。
为什么会存在这种差异?这个研究方向就留给未来了。
参考资料:
https://x.com/alexandr_wang/status/1816491442069782925 https://x.com/RylanSchaeffer/status/1816535790534701304
https://arxiv.org/abs/2404.01413
https://arxiv.org/abs/2406.07515
文章来源于:微信公众号新智元




【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
