# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
刚刚发布的开源「巨无霸」Llama 3.1虽然自带论文,但依旧激起了广大网友强烈的好奇心和求知欲。
Llama 3.1都使用了哪些数据?其中有多少合成数据?为什么不使用MoE架构?
后训练与RLHF流程是如何进行的?模型评估是如何进行的?
我们什么时候可以见到Llama 4?Meta是否会发展agent?
恰逢Llama 3.1刚刚发布,Meta科学家就现身播客节目Latent Space,秉持着开源分享的精神,对以上问题都作出了清晰的回答。

受访者Thomas Scialom现任Meta的人工智能研究科学家,领导了Llama 2和Llama 3的后训练,并参加了CodeLlama、Toolformer、Bloom、GAIA等多个项目。

以下是采访内容的节选。
Llama 3.1研发思路
其实LLM的参数规模的选择需要考虑多种因素,包括scaling law、训练时间、GPU和硬件的约束等等。
而且,不能只考虑Meta所用的硬件,还有整个AI社区,并不是每个人都在使用H100,还有很多不同的GPU型号和显存大小。
再加上,目前广泛应用于推理阶段的量化技术,比如可以用FP16或FP8精度,这会改变推理和训练/微调成本的比重。
以上这些限制因素,都让模型规模的选择成为一个非常具有挑战性的问题。
总体而言,着重考虑的是目前已有的算力,在Scaling Law和训练token总量的限制内,我们进行了一些权衡,找到了一个有合适推理效率的平衡点。
之所以做到405B这么大规模,其实原因很简单——我们想做出最好的模型,一个真正与GPT-4比肩的开源模型。(现在是GPT-4o了)虽然目前还没有完全达到目标,但差距正在逐渐缩小。
正如小扎之前宣布的,Meta囤积了越来越多的GPU,因此下一代模型将继续扩展。
对于网友们所说的,无法在家里运行Llama 3.1,这很有可能是事实。但如果进行FP8量化,依旧可以用128k的上下文窗口在单节点上运行。
从另一个角度来看,我们还是要寄希望于开源社区的力量。Llama 1和Llama 2刚刚发布时,大家同样认为模型太大了,但两周后它就能在树莓派上运行了。
虽然不能确定Llama 3.1也会和以前一样,但通过将模型开源,我们希望可以看到类似的趋势。

我们所熟知的Scaling Law主要关注两个维度,即模型权重和训练量,包括训练时的step、epoch和token总量等等。
基本上,论文的发现就是,模型规模是重要因素。因此,GPT-3犯了一个错误——模型参数量远远超出了token总量的要求。

论文地址:https://arxiv.org/pdf/2001.08361
这也正是之后的Chinchilla所发现和强调的,相比最初的Scaling Law,他们更强调了训练数据token总量的重要性。

论文地址:https://arxiv.org/pdf/2203.15556
Chinchilla论文想要找到「算力最优化」的训练方式,认为在有限算力的前提下,存在一个模型参数量和训练token数的最佳比率。
如果你希望在论文的基准测试中得到最优模型,那么Chinchilla本身没有问题;但Meta要发布的旗舰模型还需要更高的推理效率。
因此,我们选择增加训练的token数,并增加训练时长,让模型达到「过度训练」的状态。
这不符合Chinchilla定律,也会付出额外的算力,但我们希望让模型有更好的推理表现,从而更多地应用于开源社区,因此需要做出一些超越Chinchilla定律的选择。
事实上,这也是Llama 1的研发人员所做的事情。我所说的「不要陷入Chinchilla陷阱」就是这个意思。
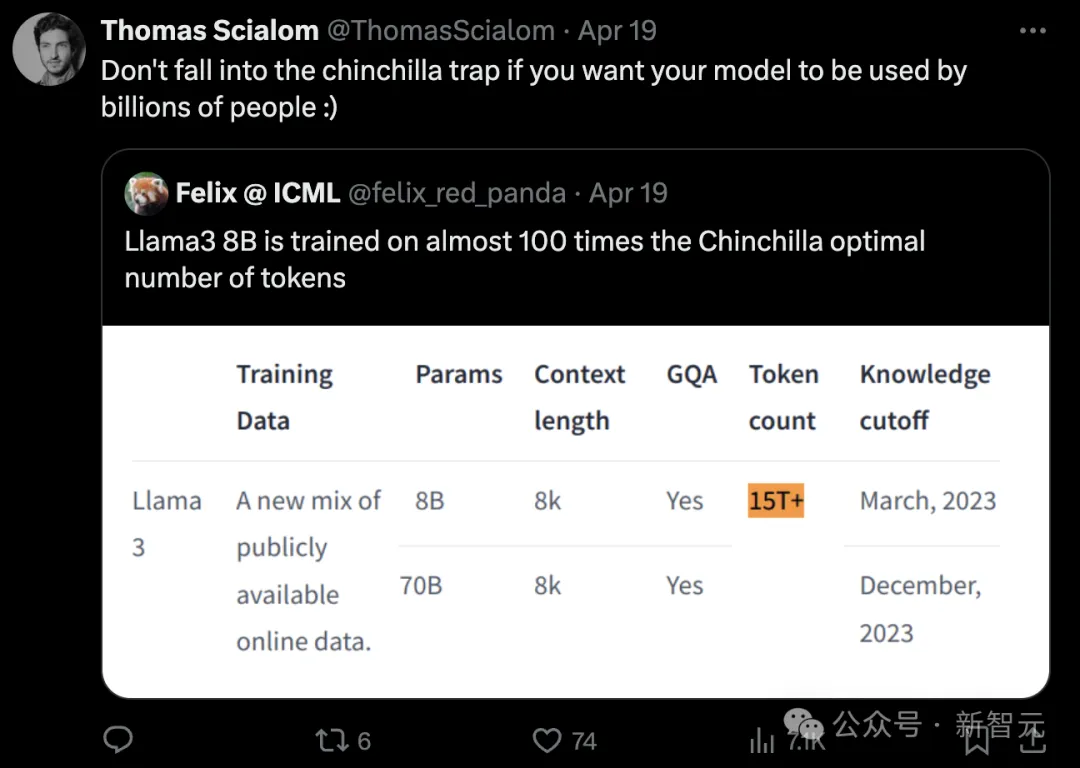
相比Llama 2, Llama 3的架构没有太多变化,但是在扩展数据的规模和质量方面,我们作出了很多努力,数据集从2T token增加到15T token。
架构方面,我认为将来会有更多改进,甚至不仅仅局限于Transformer。
目前的Tranformer架构仍然缺少灵活性,比如,我认为对每个token使用等量的算力是没有意义的,因此还有很多研究的空间。
关于「为什么不使用MoE架构」,这个是我经常听到的质疑,其中的原因有多个方面。
我认为,稠密模型只是MoE的一个特定变体,你可以把它看作只有一个专家的MoE,因此这只是一个还没有优化的超参数而已。
但我们目前正在进行一些工作,未来可能会在这个超参数上继续探索。
关于数据,我的直觉是,公开互联网上充斥着过多文本垃圾,用这些token训练模型是对算力的浪费。
在为Llama 2抓取数据时,我们就使用Llama作为分类器,用于过滤出高质量的token,并打上主题标签,比如这段文本是和数学、法律还是政治有关,这样可以实现主题的均衡和多样性。
Llama 3的后训练过程完全没有使用人工书写的答案,仅依靠从Llama 2获得的合成数据。
我非常看好合成数据,而且随着模型性能提升,情况也会变得更好。
目前的模型研发有一个趋势,就是针对基准分数进行模型的后训练改进。
模型评估是一个开放的研究问题,目前还没有很好的答案,尤其是面对同一个模型有如此多的功能。
当你试图提升模型在某个基准上的分数时,这就不再是一个好的基准了,因为可能会存在过拟合,分数提升未必可以迁移成为相似的能力。
因此,语言模型的评估,尤其是训练后评估,是一个非常困难的问题。我们尝试过很多方法,包括用奖励模型,model-as-a-judge、使用多样化的提示、多样化的基准测试……
我感觉为Llama 2进行评估要比今天容易多了,当时的模型性能比现在相差很多。现在的模型变得如此好,以至于很难找到能击溃模型的合适prompt,进行性能比较并查看边界情况。
比较模型的其中一个好办法就是进行多轮RLHF。每次上传新模型时,只需在所有带标注的prompt上进行采样,让新旧模型分别回答,再自动计算胜率。
Llama 4与Agent
Meta已经在6月开始训练Llama 4模型,而且重点可能围绕agent技术,并且已经在Toolformer等agent工具上进行了一些工作。

论文地址:https://arxiv.org/pdf/2302.04761
但同时也要意识到,如果没有一个优秀的指令模型,Toolformer扩展和未来能力也会大大受限,因此我们研发了Llama 2和Llama 3。
此外,Meta也曾在一年前发布GAIA基准,用于评估模型解决现实世界问题的能力。
在这个基准的排行榜上,基于GPT-3的agent系统得分几乎接近于零,但GPT-4驱动的系统就有很好的成绩,比如30%~40%,这其中就体现出模型的智力差距。
在我看来,agent的各种能力,比如函数调用、遵循复杂指令、预先规划、多步骤推理等等,和模型的这种智力差距是类似的。

论文地址:https://arxiv.org/pdf/2311.12983
现在有了足够强大的Llama 3,我将重新专注于agent的构建。如果能实现良好的模型互联,形成一个复杂的agnent系统,将获得几个数量级的扩展,从而实现规划、回溯、网页导航、代码执行等多种功能。
文章来源于“新智元”,作者“新智元”



【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
