# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
LLaMA3-405B的模型效果已经赶上目前最好的闭源模型GPT-4o和Claude-3.5,这可能是未来大模型开源与闭源的拐点,这里就LLaMA3的模型结构、训练过程与未来影响等方面说说我的看法。
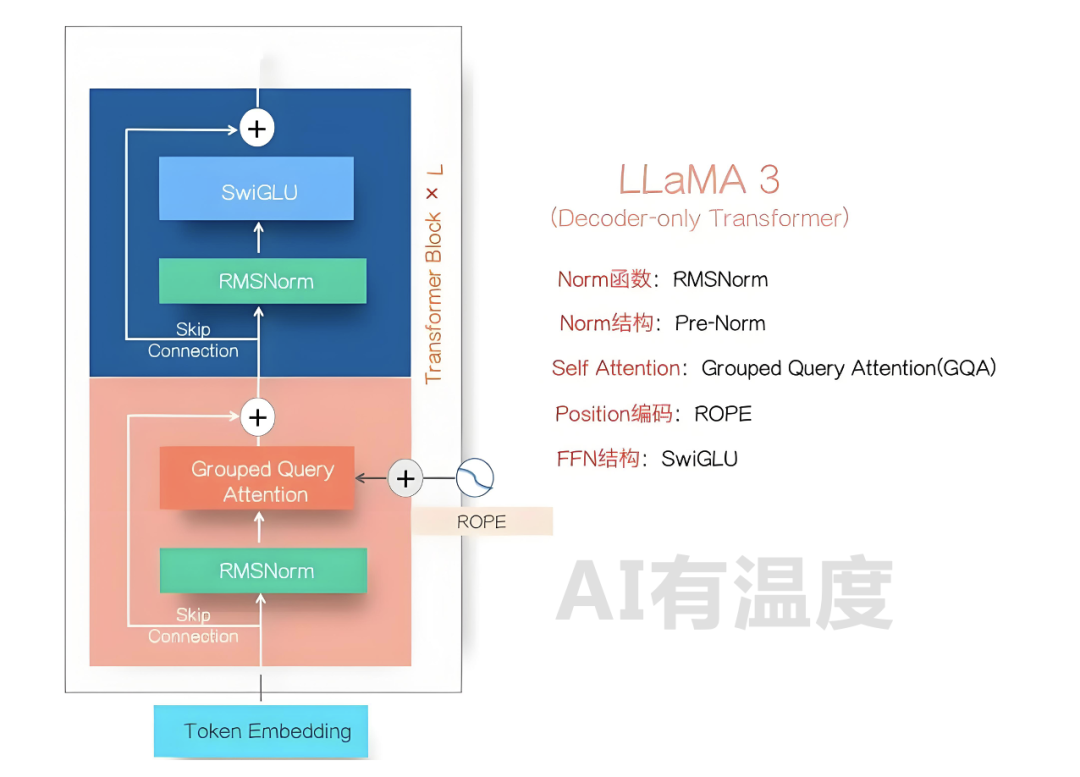
LLaMA3的模型结构如上图所示,这基本已经成为目前Dense LLM模型的标准结构了,很多采取MOE结构的LLM模型,其变化无非是把上图的FFN模块里的单个SwiGLU模块拓展成K个并联的SwiGLU模块,形成多个专家,再加上一个门控网络来选择目前Token走这么多专家里的哪几个。目前很少有结构能逃脱Transformer架构的影响,对比Transformer的部件升级主要有以下三点:
第一:FFN层激活函数由GELU(ReLU的平滑版本)变为了SwiGLU,引入了更多的权重矩阵。FFN层包括两个线性变换,中间插入一个非线性激活函数,最初的Transformer架构采用了ReLU激活函数:

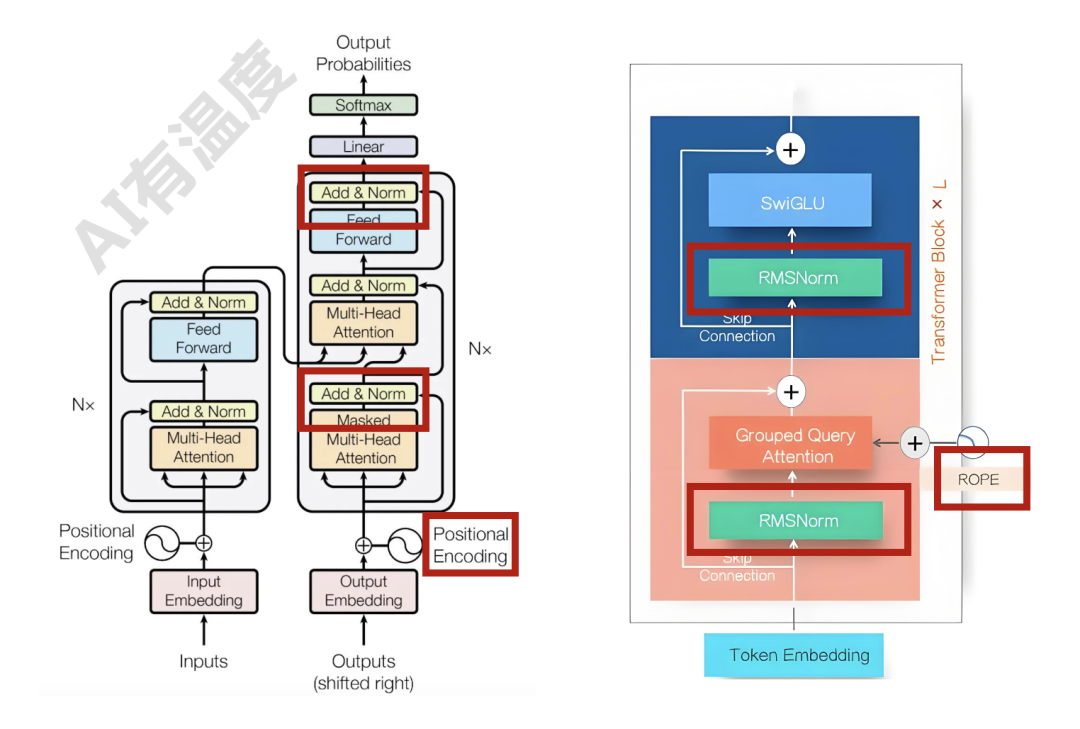
第二:归一化由post Layer Normalization变为pre RMSNorm,由后变前的同时计算公式也不同。
第三:由三角函数计算的绝对位置编码改为了RoPE相对旋转位置编码,解决了长文本预测外推性问题。推荐阅读:手把手带你从零推导旋转位置编码RoPE
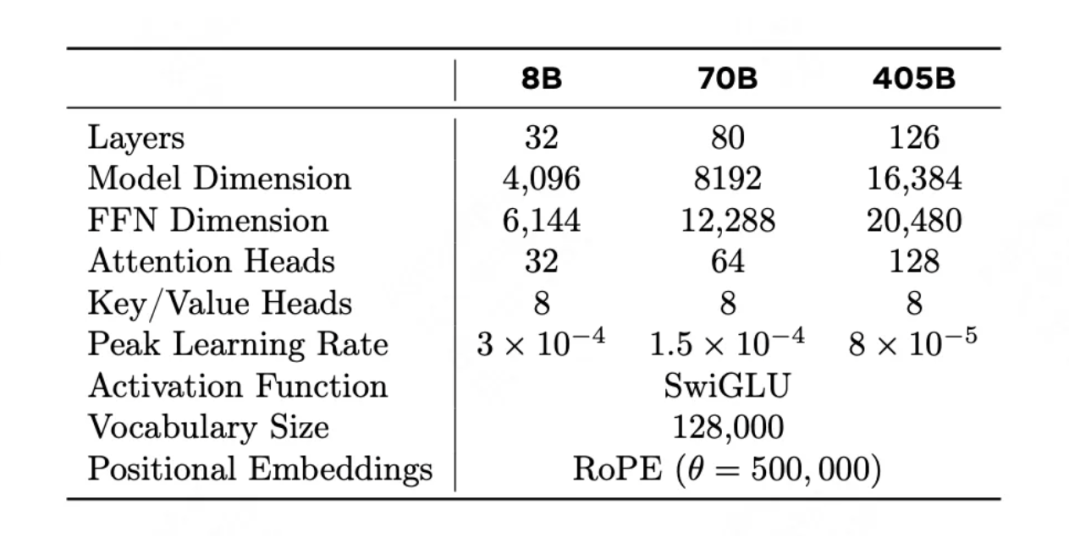
其余的变化就是模型层数横向及纵向的叠加(见上图),比如405B模型采用了126层的网络结构,RoPE theta 调到了50万等等。
下图展示了开源和闭源模型随着时间能力差异曲线,可以看出两者差距随着时间是逐步减小的,而LLaMA 3-405B让两线出现了交点。

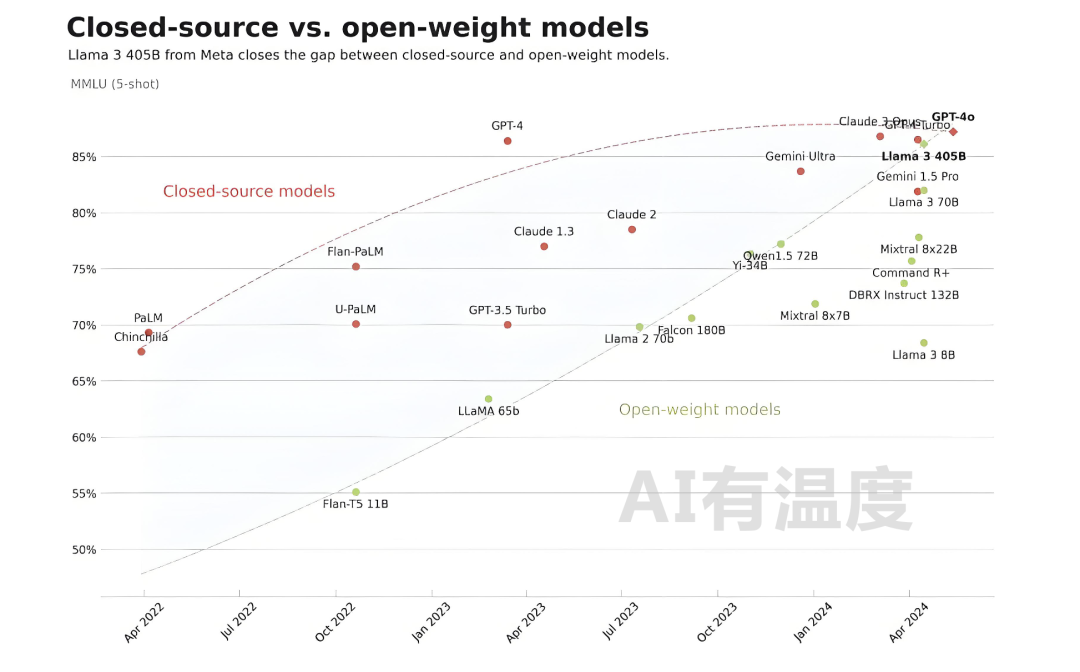
LLaMA 3-405B的开源,对于其它无论闭源还是开源模型,都有重大影响:
我认为最后大模型的结果会是一家独大,因为它最重要的能力就是知识的全面性与对话推理能力,而如果做某一领域的模型,只要有那方面的数据,用以前的技术手段也能达到相同的效果。以目前情况来看,大模型的应用以调用为主,根据这个“大脑”开发配套的Agent即可,那我肯定会选一个最强的大脑进行开发......但是一家独大的发展可能并不利于以后这项技术以后的发展。
文章来源于“Al有温度”,作者“安泰Roling”



【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
