# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在 2024 年全球开发者大会上,苹果重磅推出了 Apple Intelligence,这是一个全新的个性化智能系统, 可以提供实用的智能服务,覆盖 iPhone、iPad 和 Mac,并深度集成在 iOS 18、iPadOS 18 和 macOS Sequoia 中。
库克曾经表示,Apple Intelligence 是苹果创新的新篇章,将改变用户使用产品的方式。他强调,苹果独特的方法结合了生成式人工智能和用户的个人信息,能提供真正有用的智能服务。此外,Apple Intelligence 能够以完全私密和安全的方式访问信息,帮助用户完成对他们最重要的事情。这是苹果独有的 AI 体验。
如今,距离 Apple Intelligence 官宣一个多月过去了,这项技术终于落地智能设备,相关技术文档也终于放出。
在刚刚过去的一天,拥有 iPhone 15 Pro 或 iPhone 15 Pro Max 的用户可以下载 iOS 18.1 开发测试版,并可以体验 Apple Intelligence 的功能了。
随着这篇长达 47 页技术报告的出炉,我们可以更加深入的了解 Apple Intelligence 背后的秘密武器。

报告详细介绍了其中两款模型 ——AFM-on-device,AFM 代表 Apple Foundation Model,是一个约 30 亿参数的语言模型,以及一个更大的基于服务器的语言模型 AFM-server,可以高效、准确和负责地执行专门的任务(图 1)。
这两个基础模型作为苹果更大的生成模型系列的一部分存在。

架构及训练
AFM 基础模型是基于 Transformer 架构构建的密集解码器模型,采用如下设计:

AFM 预训练过程在开发高性能语言模型,以支持一系列 Apple Intelligence 功能方面发挥着关键作用。研究团队注重效率和数据质量,以获得高质量的端到端用户体验。
在后训练方面,研究团队发现改进通用后训练可以提升 Apple Intelligence 所有功能的性能,因为模型在遵循指令、推理和写作方面会具有更强的能力。
为了确保这些模型功能符合苹果对保护用户隐私的承诺,以及苹果的 Responsible AI 原则,后训练工作包括一系列数据收集和生成、指令调整和对齐创新。后训练过程包含两个阶段:监督微调(SFT)和来自人类反馈的强化学习(RLHF)。研究团队提出了两种新的后训练算法:(1)带有 teacher committee(iTeC)的拒绝采样微调算法,以及(2)一种用于强化学习迭代的 RLHF 算法,带有镜像下降策略优化(mirror descent policy optimization)和留一法优势估计器(leave-one-out advantage estimator)(MDLOO),使得模型质量显著提高。
Apple Intelligence特性
基础模型是为 Apple Intelligence 专门设计的,这是一个支持 iPhone、iPad 和 Mac 的个人智能系统。
苹果发现,针对特定任务的微调,他们可以将小模型的性能提升到一流水平,除此以外,他们还开发了一种基于运行时可交换适配器(runtime-swappable adapters)的架构,使单一基础模型能够专门用于数十个此类任务。图 2 显示了高级概述。
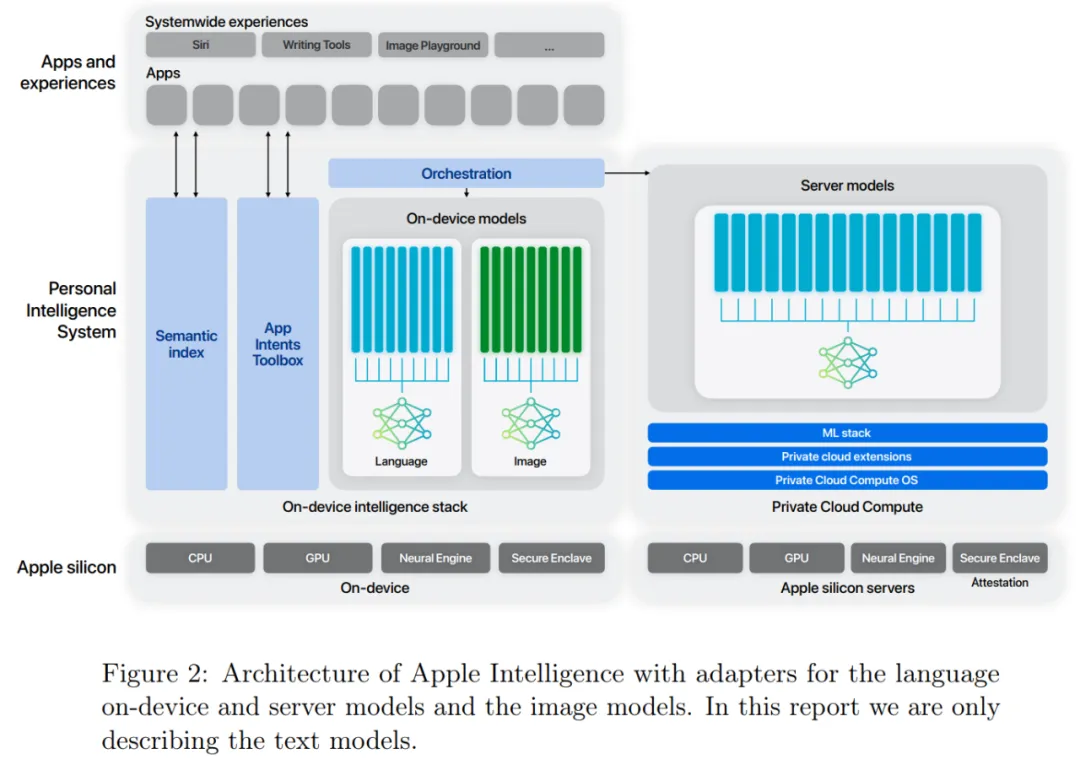
适配器架构
苹果使用 LoRA 适配器来针对特定任务进行模型微调。对于每项任务,研究者会调整 AFM 自注意力层中的所有线性投影矩阵以及逐点前馈网络中的全连接层。仅通过微调适配器,基础预训练模型的原始参数保持不变,可以保留模型的一般知识,同时定制适配器以支持特定任务。
量化
为了将 AFM 纳入内存预算有限的边缘设备并降低推理成本,需要考虑量化技术。先前的研究发现,与原始的 32/16 位浮点相比,经过 4 位量化的模型损失会很小。
为了在模型容量和推理性能之间实现最佳平衡,苹果开发了最先进的量化方法和利用准确率 - 恢复适配器(accuracy-recovery adapters)的框架。使得模型在每个权重平均小于 4 位的情况下,还能实现近乎无损的量化,并提供灵活的量化方案选择。
方法
经过后训练,模型被压缩和量化,得到平均低于 4 位的权重。量化模型通常表现出中等程度的质量损失。因此,苹果不会将量化后的模型直接用于功能开发,而是附加一组参数高效的 LoRA 适配器以进行质量恢复。
值得注意的是,训练准确率 - 恢复适配器具有样本效率,可以看作是训练基础模型的迷你版本。在适配器的预训练阶段,只需要大约 100 亿个 token(约占基础模型训练的 0.15%)即可完全恢复量化模型的能力。
由于应用程序适配器将从这些准确率 - 恢复适配器微调而来,因此它们不会产生任何额外的内存使用或推理成本。关于适配器大小,苹果发现适配器秩为 16 时提供了模型容量和推理性能之间的最佳权衡。
但是,为了灵活性,苹果提供了一套具有不同秩 {8、16、32} 的准确率 - 恢复适配器供应用程序团队选择。
混合精度量化
AFM 中的每个 transformer 块和每个层都存在残差连接。因此,所有层都具有同等重要性的可能性不大。根据这一直觉,苹果通过推动某些层使用 2 位量化(默认为 4 位)来进一步减少内存使用量。平均而言,AFM-on-device 可以压缩到每个权重仅约 3.5 位 (bpw),而不会造成显著的质量损失。
评估
研究团队使用常见的开源评估工具和基准来评估 AFM 预训练模型。表 2 展示了在 HELM MMLU v1.5.0 上 AFM-on-device 和 AFM-server 的结果。

这些基准测试表明,AFM 预训练模型具有强大的语言和推理能力,为后训练和特征微调提供了坚实的基础。

AFM 与开源模型(Phi-3、Gemma-1.1、Llama-3、Mistral、DBRX-Instruct)和商业模型(GPT3.5 和 GPT-4)的比较结果如下图3所示。与其他模型相比,AFM 模型更受人类评估人员的青睐。特别是,AFM-on-device 与 Phi-3-mini 相比,尽管模型规模小了 25%,但仍获得了 47.7% 的胜率,甚至优于开源强基线 Gemma-7B 和 Mistral-7B。

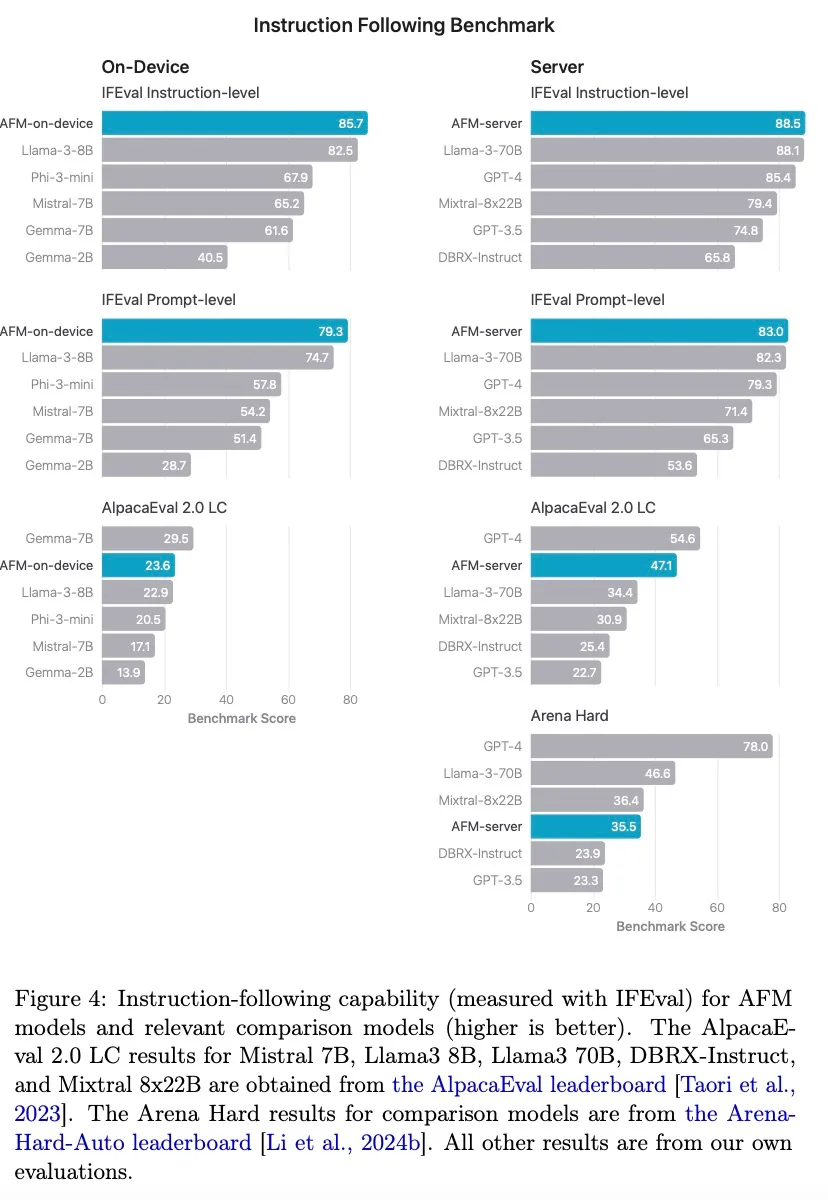
为了衡量模型生成响应遵循提示中指令的能力,研究团队在 IFEval 基准上评估了 AFM-on-device 和 AFM-server,结果如下图 4 所示:
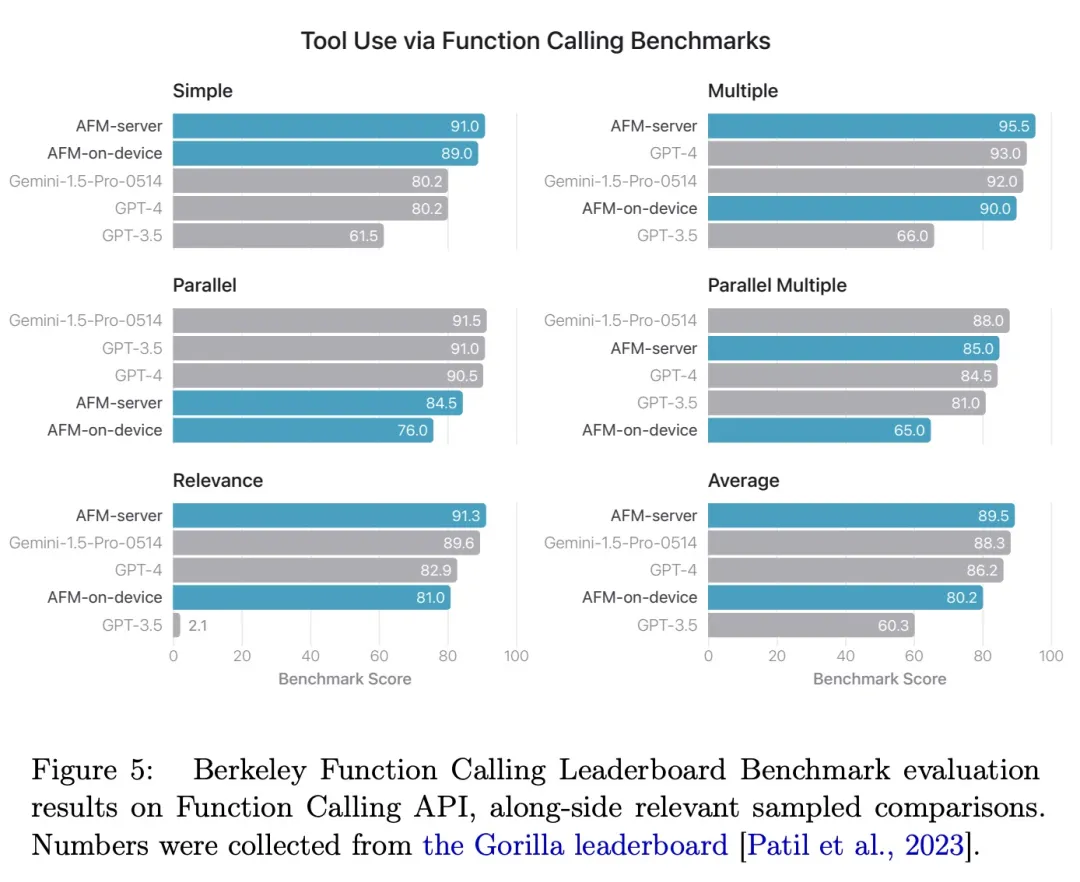
如图 5 所示,AFM-server 实现了最佳的整体准确率,优于 Gemini-1.5-Pro-Preview-0514 和 GPT-4。
苹果将 AFM 与一些最出色的模型以及规模较小的开源模型进行了比较。如图 6 所示,与 Gemma-7B 和 Mistral-7B 相比,AFM-on-device 可以实现相当或更好的性能。AFM-server 的性能明显优于 DBRX-Instruct 和 GPT3.5,并且与 GPT4 相当。

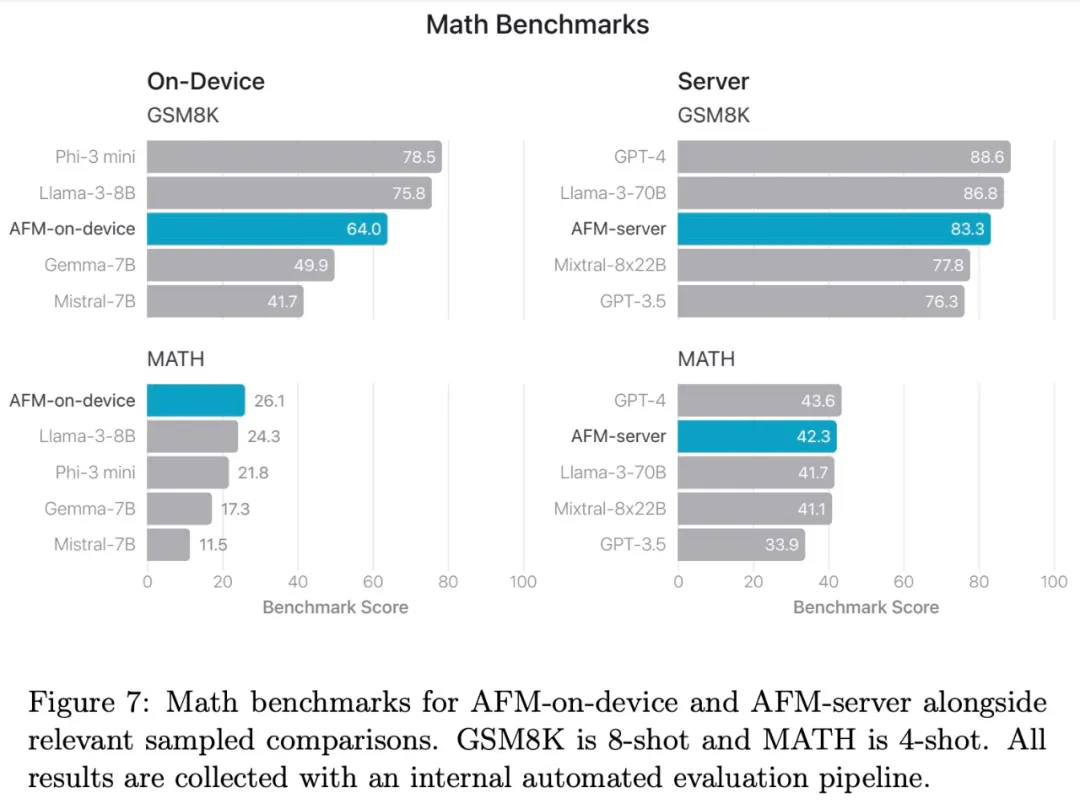
图 7 比较了经过后训练的 AFM 在数学基准上的表现。结果发现,AFM-on-device 的性能明显优于 Mistral-7B 和 Gemma-7B,即使规模不到它们的一半。
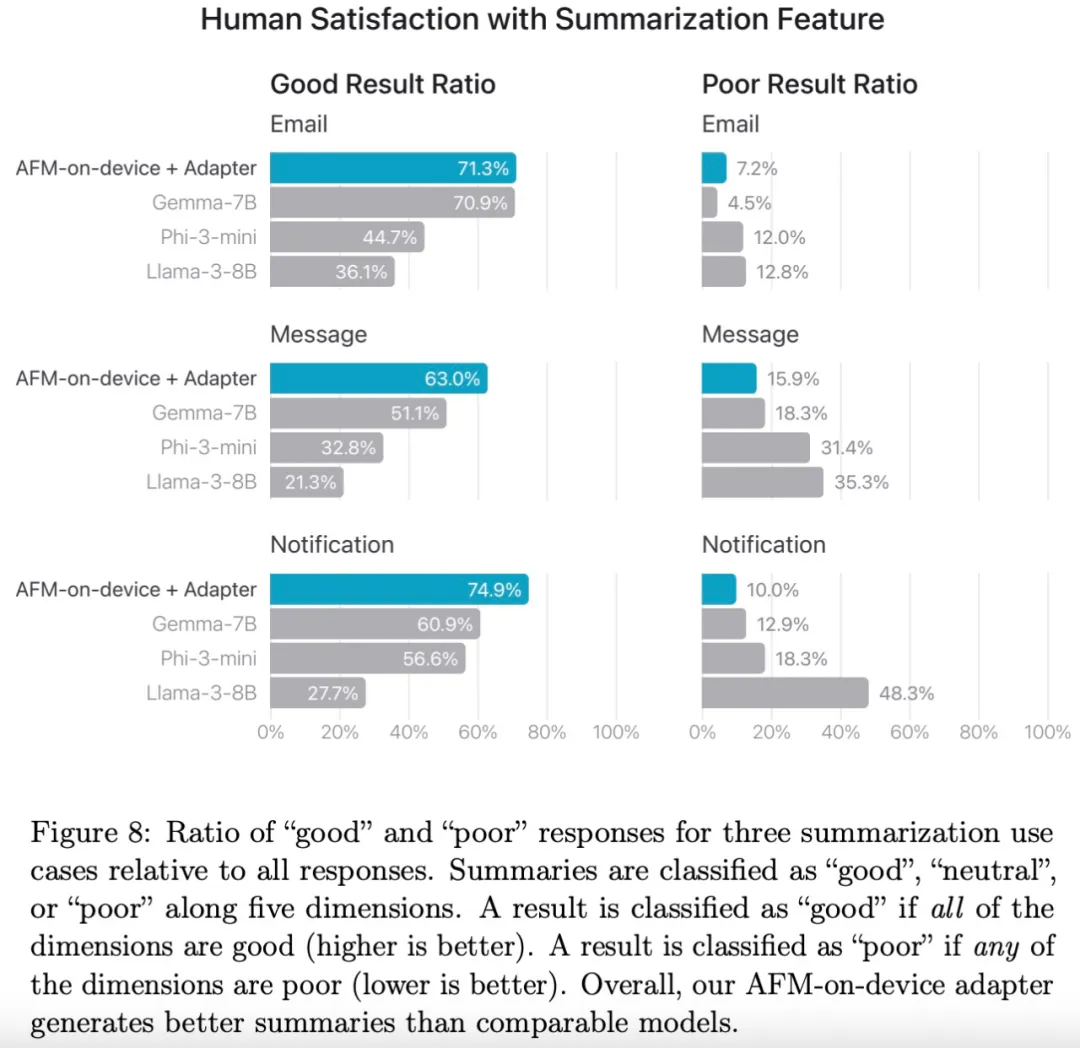
下图为人类评分员评估 AFM-on-device 适配器、Phi-3-mini、Llama-3-8B 和 Gemma-7B 在摘要任务上的质量。图 8 显示 AFM-on-device-adapter 总体上优于其他模型。
负责任的AI
Apple Intelligence 的开发和设计都注重保护用户隐私。
图 9 总结了人类评分员在不同模型上给出的违规率,越低越好。AFM-on-device 和 AFM-server 都对对抗性提示具有鲁棒性,其违规率明显低于开源和商业模型。
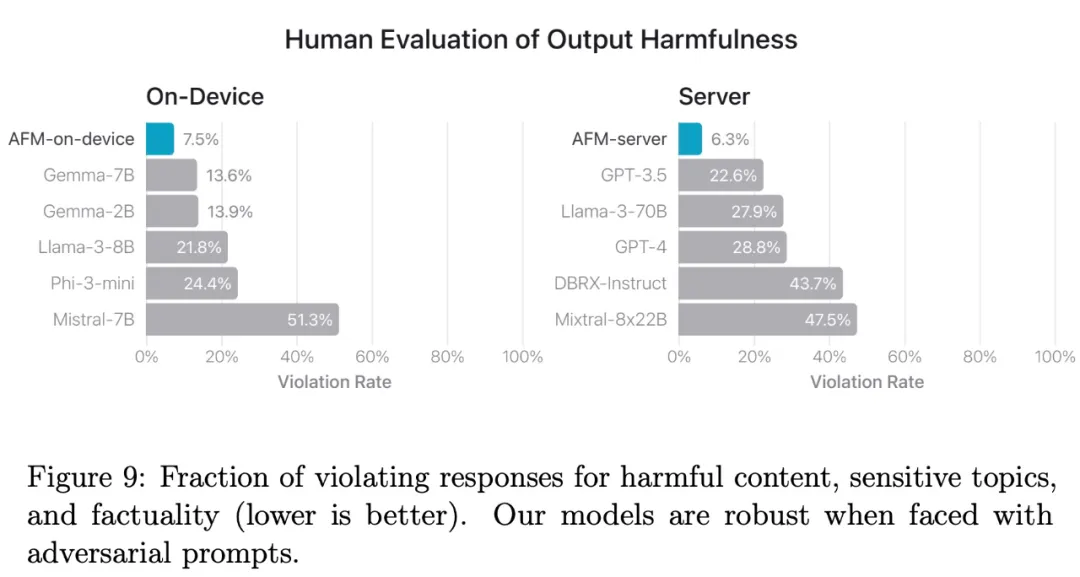
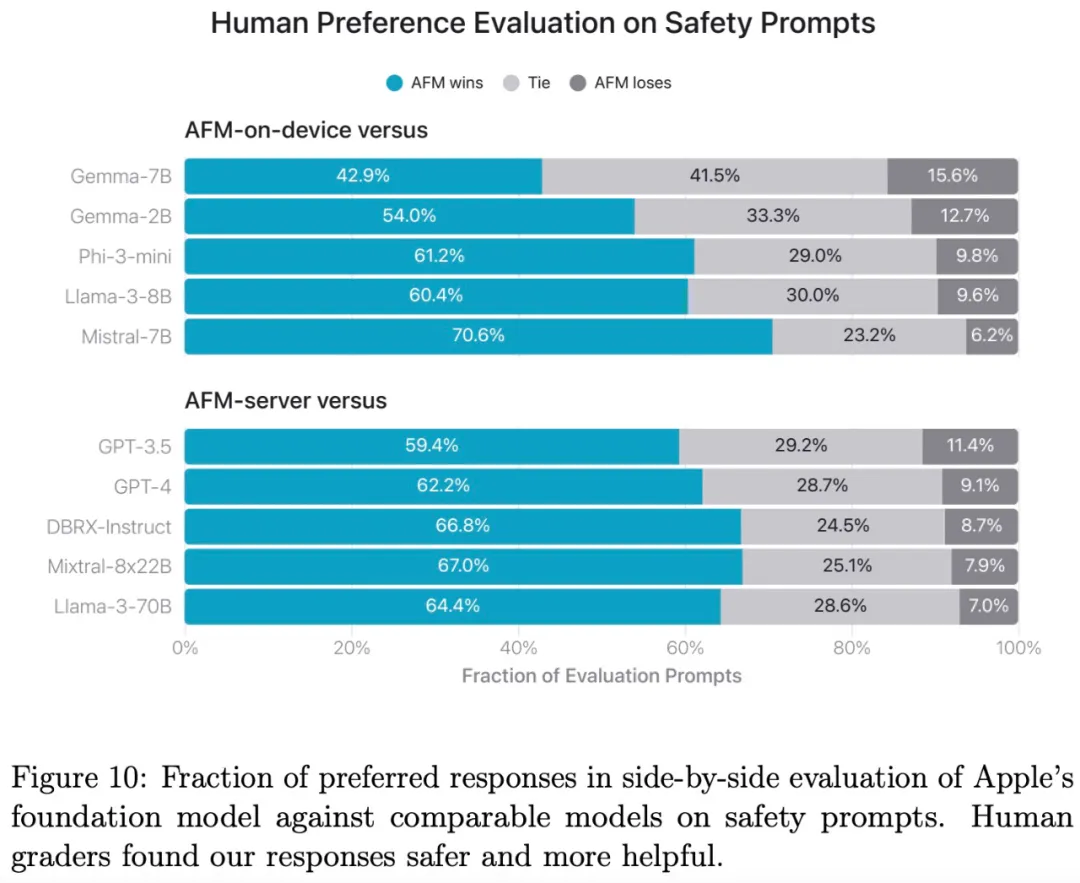
图 10 表明,与其他模型相比,AFM 模型更受人类评分员的青睐。
文章来源于“机器之心”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
