# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
多模态大语言模型 (Multimodal Large Language Moodel, MLLM) 以其强大的语言理解能力和生成能力,在各个领域取得了巨大成功。
在医学领域上,视觉问答 (VQA) 是医学多模态大语言模型的一项重要任务,它可以通过回答针对医学图像的具体临床问题,有效提高医疗专业人员的效率。这一类工作可以减轻公共卫生系统的负担,对于医疗资源贫乏的国家来说尤其重要。
然而,现有的医学 VQA 数据集规模较小,仅包含相当于分类任务的简单问题,缺乏语义推理和临床知识。
如图1所示,现有的ImageCLF VQA-MED数据集仅包含「这张图像里主要异常是什么?」和「这张图片里看到了什么?」这两种完全相当于分类任务的问题。
较小的数量以及过于简单的问题使得大语言模型很难在现有数据集上训练以及微调。
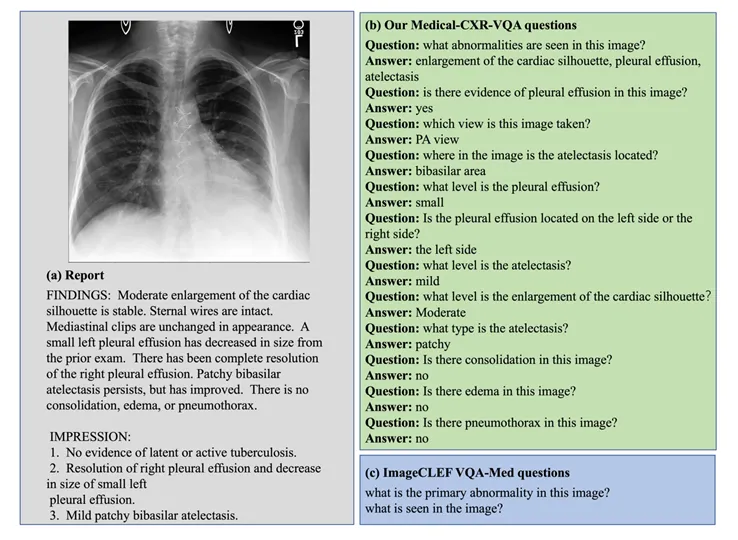
图1 新数据集与现有的数据集ImageCLF VQA-MED的问题对比
为此,得克萨斯大学阿灵顿分校、理化学研究所、国立卫生研究院、日本癌症研究中心以及东京大学的团队提出了一个大型X光胸片的问答数据库。
Medical-CXR-VQA,这个数据库覆盖了更大范围的问题类型,包含异常、存在、位置、级别、拍摄角度和类型,共7种类型的问题。

论文地址:https://authors.elsevier.com/sd/article/S1361-8415(24)00204-4
项目链接:https://github.com/Holipori/Medical-CXR-VQA
同时,作者还提出了一种新的基于LLM的方法来构建数据集。传统的数据集构建方法中主要包括两种类型:人工标注和基于规则的方法。
人工标注方法的典型示例如VQA-RAD,其依赖于大量人力资源,因而数据集的规模往往受限。
只有基于规则的方法,例如ImageCLEF和作者之前的工作Medical-Diff-VQA,才可能生成更大规模数据集。
然而,基于规则的方法对于大覆盖面的信息提取能力仍然有限,所需要提取的信息越多,意味着需要创建的规则越多。
在这里,作者使用LLM来帮助建立规则,使得相同信息覆盖面上比基于传统规则的方法准确率提高62%。
同时,作者还与2位临床专家合作对100个样本的标签进行了全面的评估,进一步帮助微调LLM。
基于该数据集,作者提出了一种新的基于图(Graph)的可解释的医学VQA方法利用图注意力来学习回答临床问题时的逻辑推理路径。
这些学习到的图推理路径可进一步用于 LLM 提示工程(Prompt engineering)和链式思维(Chain-of-thought),这对于进一步微调和训练多模态大语言模型有重要意义。
全新的Medical-CXR-VQA 数据集包括在215,547张胸部X光片上的780,014个问题答案对,问题含盖异常,存在,位置,级别,拍摄角度和类型,共7种类型的问题。各种问题类型的比例和问题类别请分别见如下图2和表1。
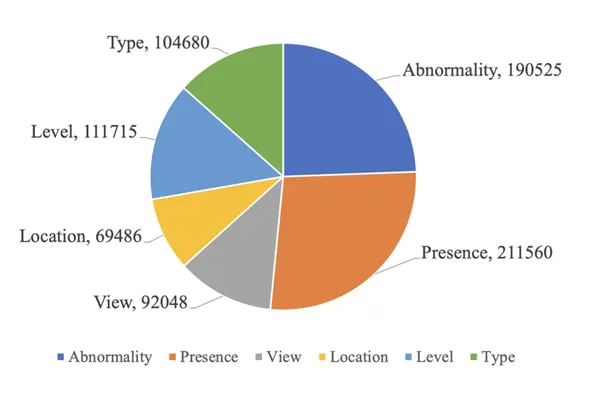
图2 Medical-CXR-VQA 问题类型的统计数据
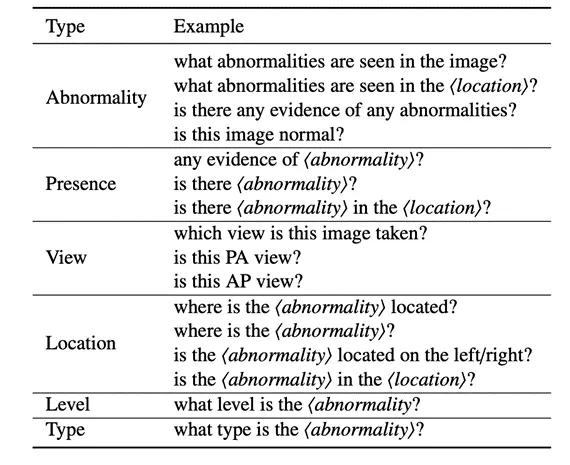
表1 Medical-CXR-VQA 问题类型示例
MIMIC-CXR是一个包括377,110张胸部X光片和277,835个放射学报告的大型数据集。作者基于MIMIC-CXR构建了Medical-CXR-VQA数据集。
传统基于规则构建的方法的一种途径是将数据集构建过程分为两步,第一步是从原始文本信息中提取出结构化的关键信息,例如疾病的位置,类型,级别,存在可能性等等;第二步是基于所提取的关键信息构建问题答案对(QA pairs)。
作者先前的工作Medical-Diff-VQA所采用的就是这种该方法,而这种方法在第一步提取结构化关键信息时非常依赖于预设关键词和规则的覆盖程度。
在千变万化的自然语言表达中,构建出一套可以覆盖所有情形和表达的规则几乎是不可能完成的任务,而借助于LLM其强大的语言理解能力和生成能力,这个问题可以迎刃而解。
这种基于LLM的方法正是针对上述第一步过程的改进。
作者采用了Llama 2 70B 作为核心LLM,以提取放射学报告中的数据。整个数据生成过程可以分为以下几个步骤:
首先,为增强LLM对特定任务的理解,作者对其进行了微调(finetune)。使用GPT-4对100份放射学报告按照精心设计的提示词进行结构化关键信息提取,并将这些信息格式化为JSON。随后,两位专业放射科医生对提取的信息进行了校验和修正,并将这100个医生标注的样本便作为黄金标准用于对Llama 2 70B的微调。
在微调完成后,利用该模型对MIMIC-CXR数据集进行全量的关键信息提取。为了确保提取质量并抑制模型可能的幻觉问题(hallucination),作者实施了一系列后处理操作。这些操作包括:统一疾病名称,从疾病名称中剥离属性词(如位置、类型、级别),并进行属性词的重新分配等。
至此,结构化的关键信息提取已经完成。
为验证基于LLM的方法与传统基于规则的方法在结构化信息上的表现差异,作者对两种方法在100个随机抽取的样本上进行了比较。基于规则的方法使用了与LLM方法相同的信息覆盖面进行关键词提取。
结果如表2所示,基于LLM的方法在高信息覆盖面的信息提取上显示出显著提升,相比基于规则的方法具有断层式的优势。
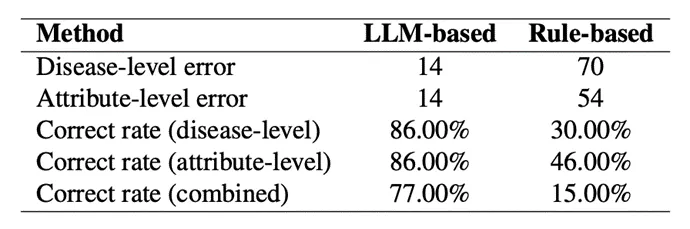
表2 基于LLM的方法与基于规则的方法在100个结构化信息提取的结果比较
最后,作者基于提取的结构化信息生成了问答对(QA pairs),并由两位人工验证者对500个问答对进行了验证。
验证结果显示,如表3所示,问答对的平均正确率达到了94.8%。
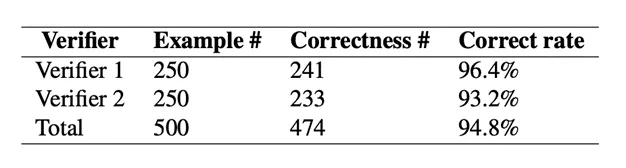
表3 数据集人工验证结果
基于构建的Medical-CXR-VQA数据集,作者提出了一种多模态图推理模型,如图3所示。
针对拍摄胸部X光片时病人姿态变化带来的挑战,作者提出了一种方法,通过定位病人的解剖结构和病灶,并提取这些定位对象的特征作为图的节点,来避免因姿态问题导致的图像不匹配。
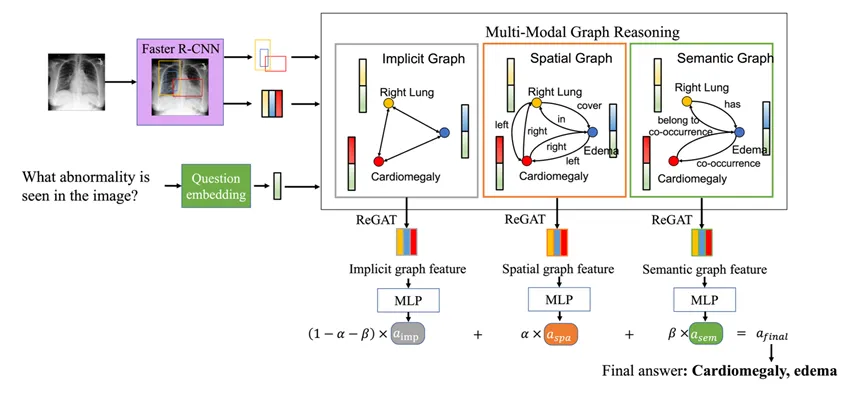
图3 模型结构
为了使图网络能够有效理解问题并从检测目标中提取相关节点信息,作者在每个节点中融入了问题的编码特征。
为深入挖掘解剖结构和病灶之间的关系,作者设计了一种包含三种关系的图网络结构:空间关系、语义关系和隐含关系。
- 在空间关系部分,作者根据检测目标的相对位置将其划分为11种类型,并将这些空间关系赋值到节点之间的边上,利用ReGAT(Relation-aware Graph Attention Network)更新节点特征。
- 在语义关系方面,作者与医学专家合作,构建了两种医疗知识图谱:共现知识图谱(Co-occurrence Knowledge Graph)和解剖学知识图谱(Anatomical Knowledge Graph)。
共现知识图谱是通过统计不同疾病的共同出现概率构建的,而解剖学知识图谱则详细分类了病灶与其可能出现的解剖结构之间的关联。
- 对于隐含关系,作者采用全连接图,让模型在所有节点之间挖掘潜在信息。
经过ReGAT计算后,每种图均生成最终的节点特征,这些特征进一步经过平均池化层处理,得到各图的最终特征。然后,将三种图的特征加权相加,生成最终答案特征并用于答案预测。
通过以上方法,作者成功解决了病人姿态变化带来的挑战,同时提升了模型在Medical-CXR-VQA(医学胸片问答)任务中的性能。
如表4所示,该方法全面超越了MMQ和VQAMix这两个先进的医学VQA模型。
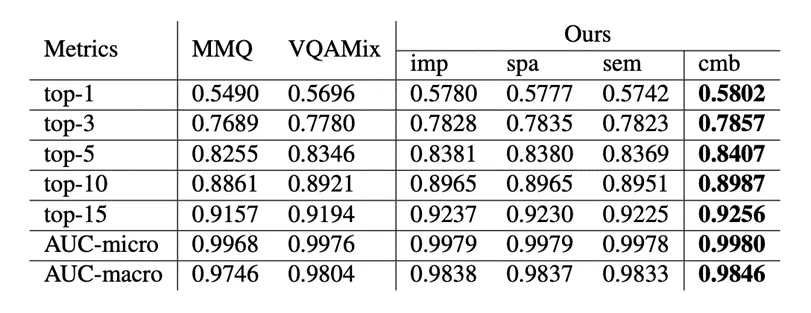
表4 与基准模型的结果对比
为了促进多模态大型语言模型在医学研究中的发展,作者对之前使用传统基于规则方法工作进行了延伸。
利用基于LLM的方法,作者创建了一个名为Medical-CXR-VQA的以临床为驱动的大规模医学VQA数据集,在给定相同的关键词提取集时将数据集构建的准确性提高了62%。
此外,作者还提出了一种用于VQA的多关系图学习方法,该方法通过包含三种不同的图关系,并引入了医学知识图谱来回答问题。
未来,作者还将通过回答问题所显示出的推理路径来构建医学LLM的思维链,并构建医学知识驱动的提示(prompt)来训练医学LLM。
参考资料:
https://github.com/Holipori/Medical-CXR-VQA
文章来自于微信公众号新智元 作者 新智元




【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
