# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
训练一个扩散模型要多少钱?
之前最便宜的方法(Wuerstchen)用了28400美元,而像Stable Diffusion这样的模型还要再贵一个数量级。
大模型时代,一般人根本玩不起。想要各种文生小姐姐,还得靠厂商们负重前行
为了降低这庞大的开销,研究者们尝试了各种方案。
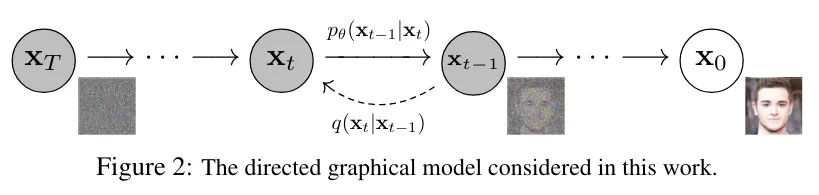
比如,原始的扩散模型从噪声到图像大约需要1000步,目前已经被减少到20步左右,甚至更少。
当扩散模型中的基础模块逐渐由Unet(CNN)替换为DiT(Transformer)之后,一些根据Transformer特性来做的优化也跟了上来。
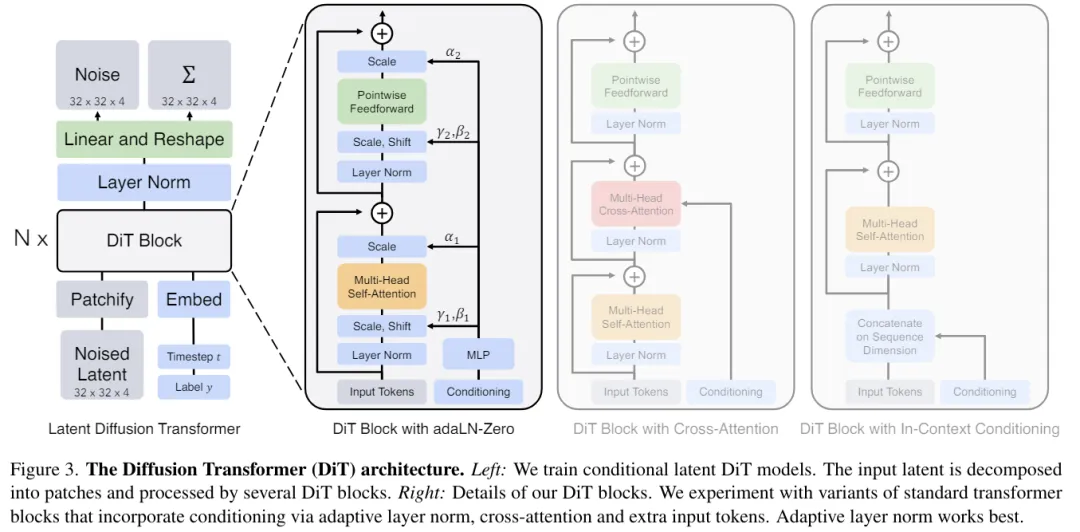
比如量化,比如跳过Attention中的一些冗余计算,比如pipeline。
而近日,来自加州大学尔湾分校等机构的研究人员,把「省钱」这个目标直接向前推进了一大步:

论文地址:https://arxiv.org/abs/2407.15811
——从头开始训练一个11.6亿参数的扩散模型,只需要1890美元!
对比SOTA有了一个数量级的提升,让普通人也看到了能摸一摸预训练的希望。
更重要的是,降低成本的技术并没有影响模型的性能,11.6亿个参数给出了下面这样非常不错的效果。


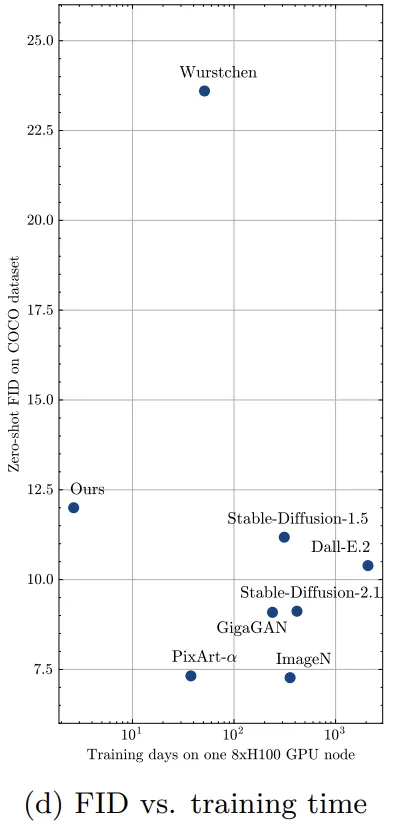
除了观感,模型的数据指标也很优秀,比如下表给出的FID分数,非常接近Stable Diffusion 1.5和DALL·E 2。
相比之下,Wuerstchen的降成本方案则导致自己的考试分数不甚理想。
抱着「Stretching Each Dollar」的目标,研究人员从扩散模型的基础模块DiT入手。
首先,序列长度是Transformer计算成本的大敌,需要除掉。
对于图像来说,就需要在不影响性能的情况下,尽量减少参加计算的patch数量(同时也减少了内存开销)。
减少图像切块数可以有两种方式,一是增大每块的尺寸,二是干掉一部分patch(mask)。
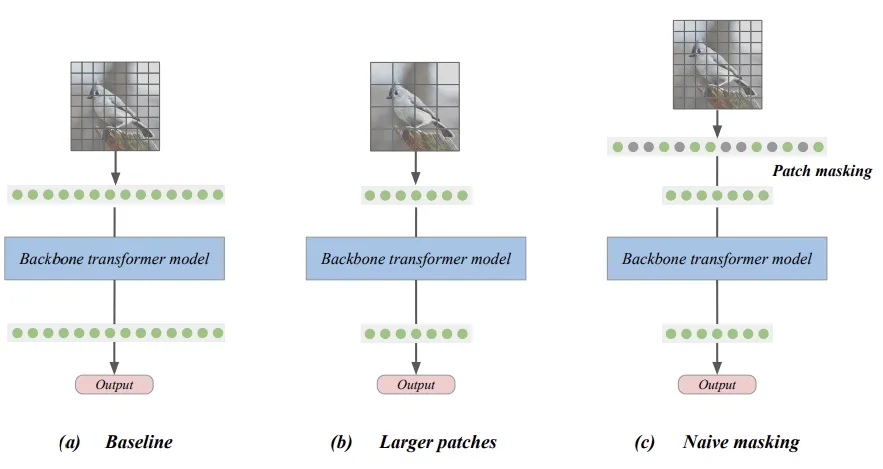
因为前者会显著降低模型性能,所以我们考虑进行mask的方式。
最朴素的mask(Naive token masking)类似于卷积UNet中随机裁剪的训练,但允许对图像的非连续区域进行训练。
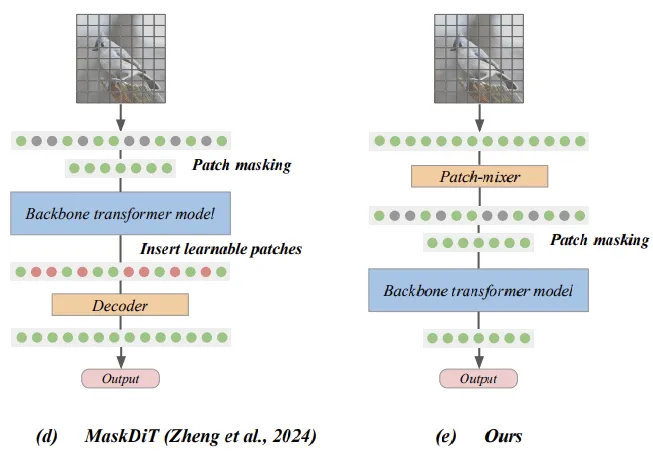
而之前最先进的方法(MaskDiT),在输出之前增加了一个恢复重建的结构,通过额外的损失函数来训练,希望通过学习弥补丢掉的信息。
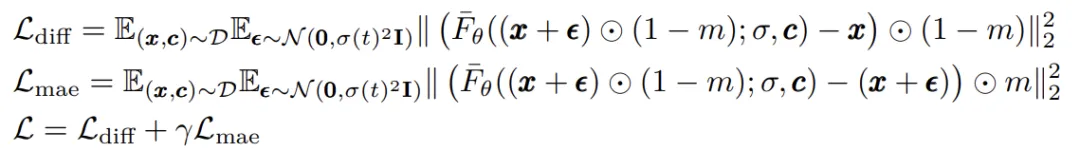
这两种mask都为了降低计算成本,在一开始就丢弃了大部分patch,信息的损失显著降低了Transformer的整体性能,即使MaskDiT试图弥补,也只是获得了不太多的改进。
——丢掉信息不可取,那么怎样才能减小输入又不丢信息呢?
本文提出了一种延迟掩蔽策略(deferred masking strategy),在mask之前使用混合器(patch-mixer)进行预处理,把被丢弃patch的信息嵌入到幸存的patch中,从而显著减少高mask带来的性能下降。
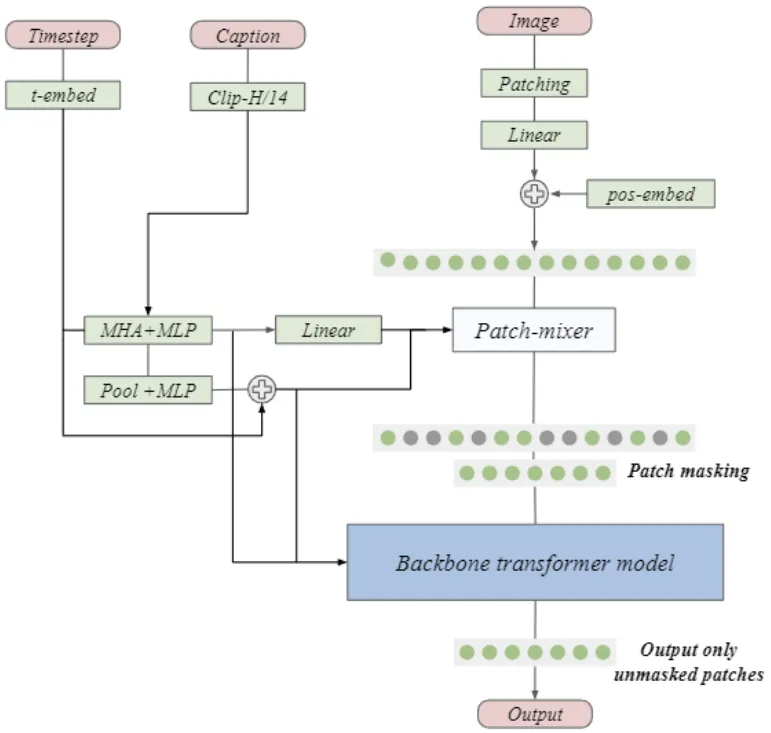
在本架构中,patch-mixer是通过注意力层和前馈层的组合来实现的,使用二进制掩码进行mask,整个模型的损失函数为:
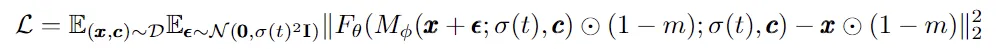
与MaskDiT相比,这里不需要额外的损失函数,整体设计和训练更加简单。
而混合器本身是个非常轻量的结构,符合省钱的标准。
微调
由于非常高的掩蔽比(masking ratio)会显著降低扩散模型学习图像中全局结构的能力,并引入训练到测试的分布偏移,所以作者在预训练(mask)后进行了小幅度的微调(unmask)。
另外,微调还可以减轻由于使用mask而产生的任何不良生成伪影。
MoE能够增加模型的参数和表达能力,而不会显著增加训练成本。
作者使用基于专家选择路由的简化MoE层,每个专家确定路由到它的token,而不需要任何额外的辅助损失函数来平衡专家之间的负载。
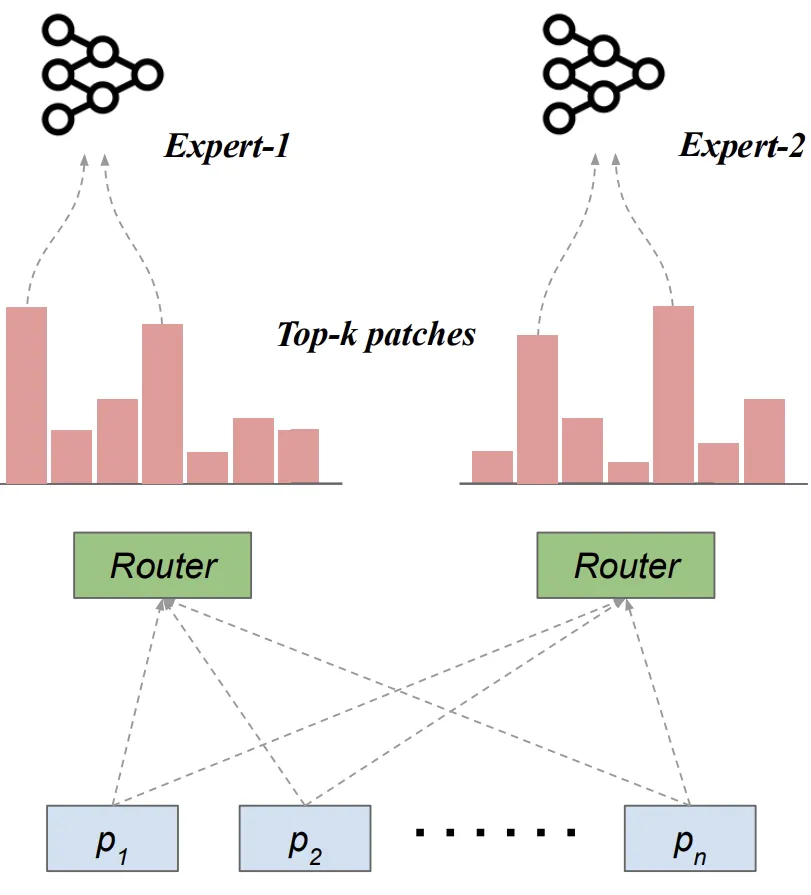
此外,作者还考虑了分层缩放方法,线性增加Transformer块的宽度(即注意力层和前馈层中的隐藏层尺寸)。
由于视觉模型中的更深层倾向于学习更复杂的特征,因此在更深层中使用更多的参数将带来更好的性能。
作者使用两种DiT的变体:DiT-Tiny/2和DiT-Xl/2,patch大小为2。
使用具有余弦学习率衰减和高权重衰减的AdamW优化器训练所有模型。
模型前端使用Stable-Diffusion-XL模型中的四通道变分自动编码器(VAE)来提取图像特征,另外还测试了最新的16通道VAE在大规模训练(省钱版)中的性能。
作者使用EDM框架作为所有扩散模型的统一训练设置,使用FID以及CLIP分数来衡量图像生成模型的性能。
文本编码器选择了最常用的CLIP模型,尽管T5-xxl这种较大的模型在文本合成等具有挑战性的任务上表现更好,但为了省钱的目标,这里没有采用。
训练数据集
使用三个真实图像数据集(Conceptual Captions、Segment Anything、TextCaps),包含2200万个图像文本对。
由于SA1B不提供真实的字幕,这里使用LLaVA模型生成的合成字幕。作者还在大规模训练中添加了两个包含1500万个图像文本对的合成图像数据集:JourneyDB和DiffusionDB。
对于小规模消融,研究人员通过从较大的COYO-700M数据集中对10个CIFAR-10类的图像进行二次采样,构建了一个名为cifar-captions的文本到图像数据集。
使用DiT-Tiny/2模型和cifar-captions数据集(256×256分辨率)进行所有评估实验。
对每个模型进行60K优化步骤的训练,并使用AdamW优化器和指数移动平均值(最后10K步平滑系数为0.995)。
延迟掩蔽
实验的基线选择我们上面提到的Naive masking,而本文的延迟掩蔽则加入一个轻量的patch-mixer,参数量小于主干网络的10%。
一般来说,丢掉的patch越多(高masking ratio),模型的性能会越差,比如MaskDiT在超过50%后表现大幅下降。
这里的对比实验采用默认的超参数(学习率1.6×10e-4、0.01的权重衰减和余弦学习率)来训练两个模型。
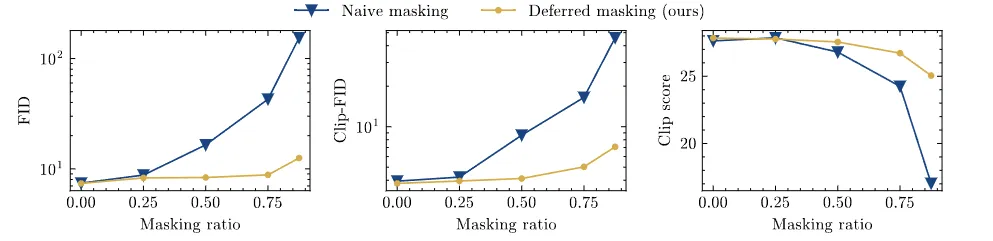
上图的结果显示了延迟屏蔽方法在FID、Clip-FID和Clip score三个指标上都获得了提升。
并且,与基线的性能差距随着掩蔽率的增加而扩大。在掩蔽率为75%的情况下,朴素掩蔽会将FID分数降低至 16.5,而本文的方法则达到5.03,更接近于无掩蔽时的FID分数(3.79)。
超参数
沿着训练LLM的一般思路,这里比较两个任务的超参数选择。
首先,在前馈层中,SwiGLU激活函数优于GELU。其次,较高的权重衰减会带来更好的图像生成性能。
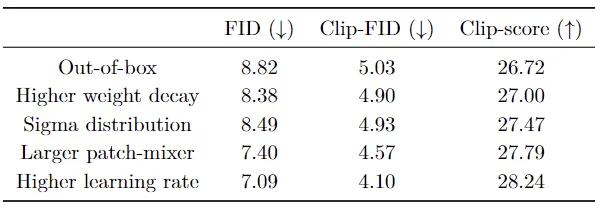
另外,与LLM训练不同的是,当对AdamW二阶矩 (β) 使用更高的运行平均系数时,本文的扩散模型可以达到更好的性能。
最后,作者发现使用少量的训练步骤,而将学习率增加到最大可能值(直到训练不稳定)也显著提高了图像生成性能。
混合器的设计
大力出奇迹一般都是对的,作者也观察到使用更大的patch-mixer后,模型性能得到持续改善。
然而,本着省钱的目的,这里还是选择使用小型的混合器。
作者将噪声分布修改为 (−0.6, 1.2),这改善了字幕和生成图像之间的对齐。
如下图所示,在75% masking ratio下,作者还研究了采用不同patch大小所带来的影响。
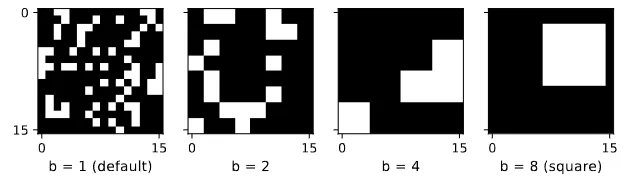
当连续区域变多(patch变大)时,模型的性能会下降,因此保留随机屏蔽每个patch的原始策略。
分层缩放
这个实验训练了DiT-Tiny架构的两种变体,一种具有恒定宽度,另一种采用分层缩放的结构。
两种方法都使用Naive masking,并调整Transformer的尺寸,保证两种情况下的模型算力相同,同时执行相同的训练步骤和训练时间。

由上表结果可知发现,在所有三个性能指标上,分层缩放方法都优于基线的恒定宽度方法,这表明分层缩放方法更适合DiT的掩蔽训练。
参考资料:
https://arxiv.org/abs/2407.15811
文章来自于微信公众号新智元 作者新智元



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
