# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
从能力上来讲,当前AI的专业性已经在多方面超越人类。
不过咱们也依然保有一些「神圣」的特性。
比如人脑的效率很高,一碗米饭就能提供半天的算力,一个鸡腿就能输出好多好多token。
比如我们的灵魂与情感,在理性认知的同时也会产生超越常理的行为。
至于最终的超级智能到底需不需要学习人类的这些神秘特性,也许试过才知道。
——小AI你想进步吗?先来模仿我吧。
近日,来自佐治亚理工学院的研究人员,开发了首个与人类思考方式相近的神经网络——RTNet。

论文地址:https://www.nature.com/articles/s41562-024-01914-8
传统神经网络的决策行为与人类有着显著不同。
以图像分类的CNN为例,不管输入图像看上去是简单还是复杂,网络的计算量都是固定的,且相同的输入必然得到相同的输出。
人类则一般倾向于简单题做得快,但偶尔也会粗心大意犯点低级错误。
全新的RTNet能够模拟人类的感知行为,可以生成随机决策和类似人类的响应时间(RT)分布。
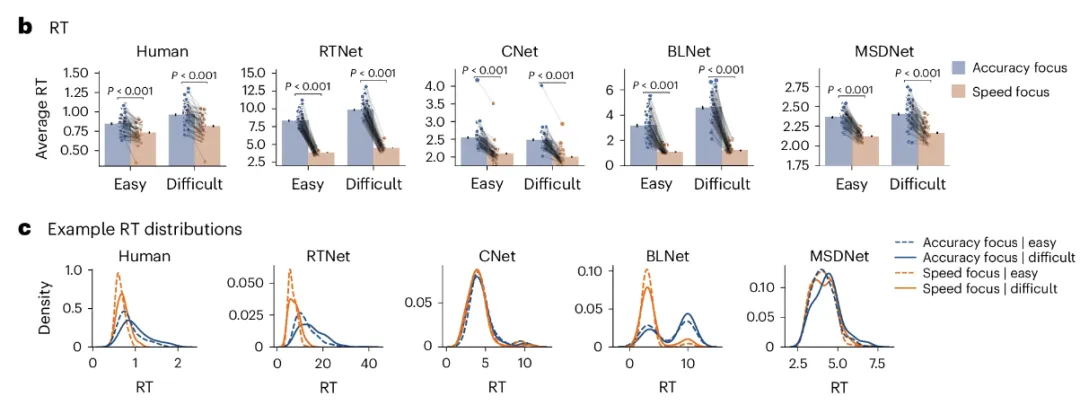
RTNet的内部机制更接近人类产生RT的真实机制,其核心假设为:RT是由顺序采样和结果积累的过程生成的。
下图是RTNet的网络结构,分为两阶段:
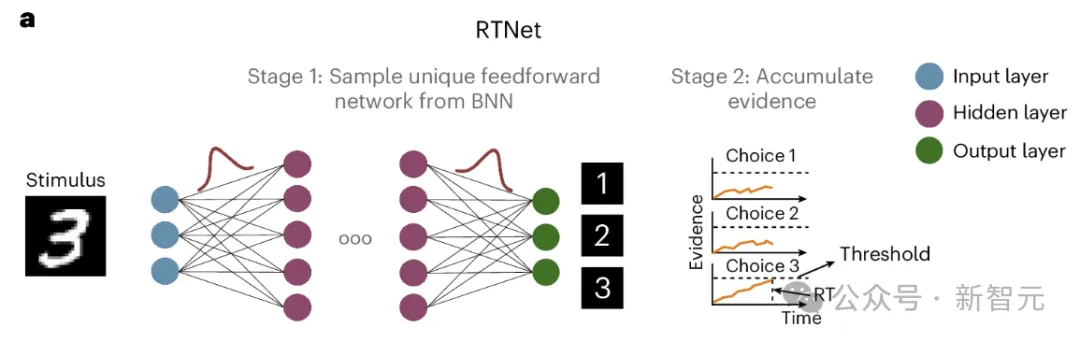
一阶段采用Alexnet架构,但权重参数为BNN的形式,与一般神经网络权重为确定值不同,BNN在训练时学习的是分布。
BNN在每次推理时,从学到的分布中随机采样出本次使用的权重,从而引入了随机性。
二阶段是一个累加的过程,以分类任务为例,事先设置一个阈值,每次推理的结果累加到各自的分类上,直到某一类到达了阈值,则推理停止。
由此可知,RTNet在原理上至少模拟了人类决策的两种特性:首先是BNN引入的随机性,其次是对于不同难度任务有不同的完成时间(RT),因为更简单的图像可以用更少的推理次数累积到阈值。
作者还通过全面的测试,表明RTNet复刻了人类准确度、RT和置信度的所有基本特征,并且比所有当前替代方案都做得更好。
模仿人类感知决策
人类感知决策有六个基本特征:
1)人类的决策是随机的,这意味着相同的刺激可以在不同的试验中引发不同的反应
2)增加速度压力会缩短RT但降低准确性(SAT)
3)更困难的决策会导致准确性降低和RT延长
4)RT分布右偏,并且这种偏斜会随着任务难度的增加而增加
5)正确试验的RT低于错误试验
6)正确试验的信心高于错误试验
目前,对于现有的图像可计算模型,能够在多大程度上再现人类的全部行为特征,我们所做的工作还相对较少。
本文中,作者选择了在这方面表现最先进的几个神经网络:CNet、BLNet和MSDNet,作为RTNet的对比对象。
人类对照组
选取60名参与者执行数字辨别任务,分别报告感知到的数字,以及评估自己的决策信心。
每次试验开始时,参与者注视一个小的白色十字架500-1,000毫秒,随后展示需要辨别的图像300毫秒。
数字图像来源于MNIST数据集,使用1到8之间的数字,并叠加不同程度的噪声。

参与者使用计算机键盘报告感知到的数字,将左手的四个手指放在数字1-4上,右手的四个手指放在5-8上。这样参与者可以在不看键盘的情况下做出反应,从而减少额外的干扰。
实验包括对SAT和不同任务难度的测试。
SAT测试要求参与者注重其反应速度或准确性,并在实验中交替进行速度和准确性的测试。
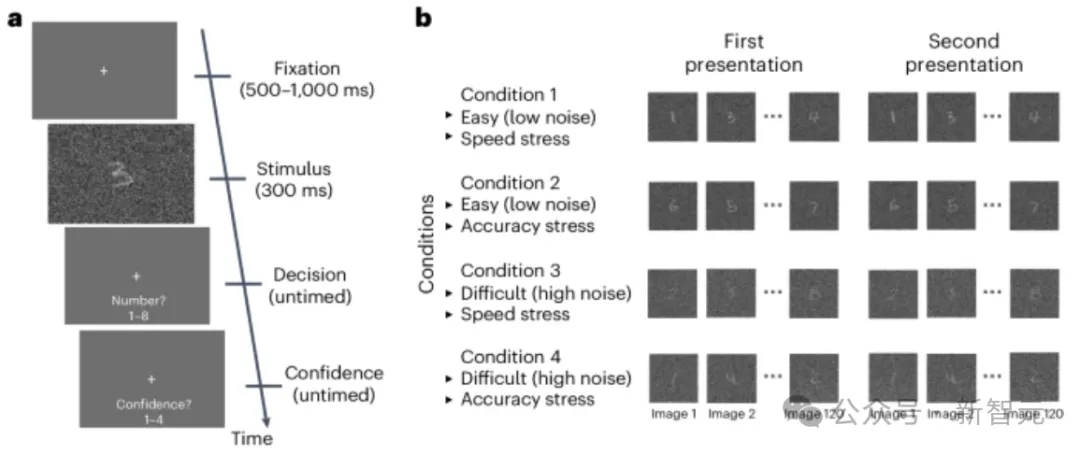
通过向图像中添加不同程度的均匀噪声来改变任务难度。简单任务包含0.25的平均均匀噪声(范围为0-0.5),而困难任务包含0.4的均匀噪声(范围为0-0.8)。(ps:相对的图像像素值为0到1之间)
另外,为了适应测试,人类组也参与了训练阶段,分为无噪声、关注准确性和关注速度三部分,每个部分进行50次训练。
测试阶段由960次实验组成,分为四轮,整合了SAT条件以及不同的难度等级。
RTNet
RTNet采用Alexnet架构有两个原因:一是为了匹配实验中的其他网络,太小了吃亏。
另一方面RTNet的BNN很难训练,又限制了模型不能太大。综合考虑就Alexnet比较合适。
在BNN中,权重被建模为概率分布,而不是点估计。按照贝叶斯推理规则,可以使用以下公式推断权重w的后验分布:
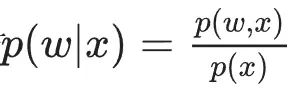
但是,对于大型网络来说,这种计算是难以完成的,因此,计算这个后验分布通常使用变分推断来近似。
指定一个替代分布q (w) 来近似后验,并调整其参数以最大化两个分布之间的相似性,分布之间的相似性通过KL散度来量化:
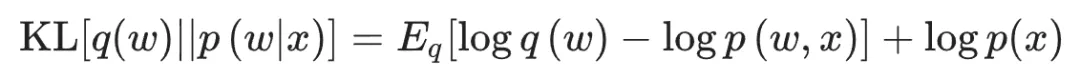
但由于p (x) 难以计算,这时可以通过定义一个证据下限 (ELBO) 函数代理目标函数来绕过此计算:
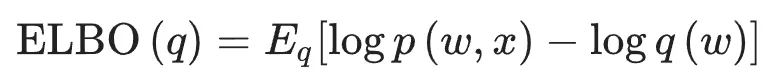
研究人员对RTNet的BNN模块进行了总共15个epoch的训练,批次大小为500,在MNIST测试集上实现了高于97%的分类准确率。
作者使用60种均值方差的组合作为初始化,训练了60个RTNet实例,来对标60个人类受试者,同样,下面介绍的其他网络也用类似的方法(随机种子)分别生成60个实例。
CNet
CNet 建立在残差网络 (ResNet) 的架构之上,利用跳过连接在输入处理期间引入传播延迟。
在每个处理步骤中,所有层中的所有单元都会并行更新。但是,由于每个残差块引入的传播延迟,更简单的感知特征会在块之间更快地传输。
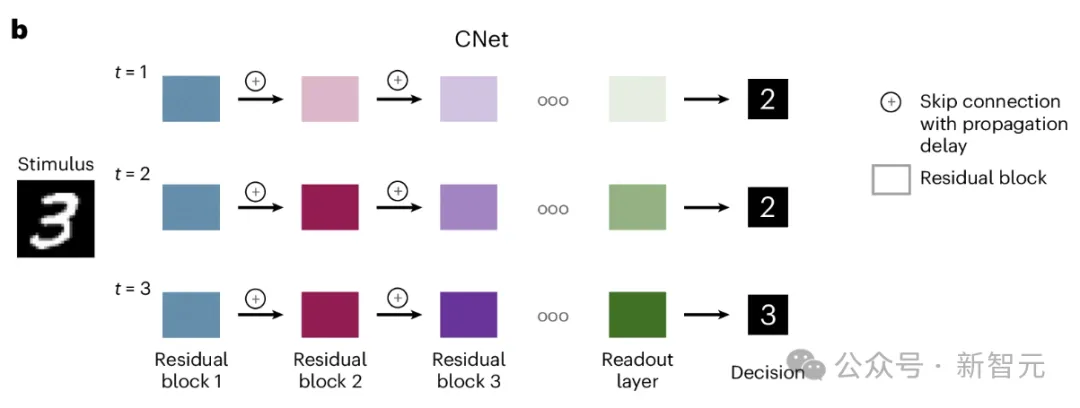
通常,残差块t需要t−1个时间步才能接收完整且稳定的输入。在处理过程中的任何时间点,网络都可以生成预测。
但是,如果时间步长t小于残差块的数量,则响应将基于较高块中的不稳定表示。
BLNet
BLNet是一个RCNN,由标准前馈CNN和循环连接组成,这些循环连接将每一层都连接到自身,最后的读出层通过softmax函数计算每个时间步的网络输出。
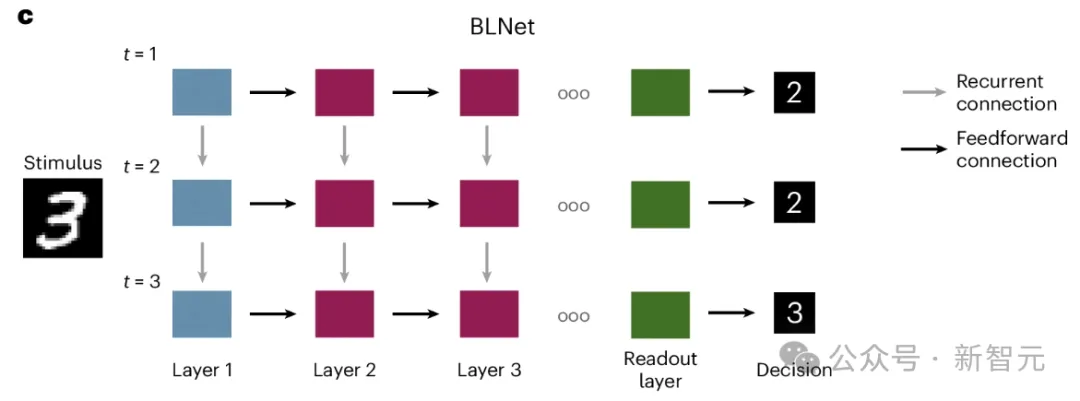
在每个时间步长,给定层从两个来源接收输入:来自前一个卷积层的前馈输入和来自自身的循环输入。
如果当前的计算结果超过预定义的阈值,网络就会生成响应。
MSDNet
MSDNet 的架构类似于标准前馈神经网络,但其每一层后都有提前退出分类器。
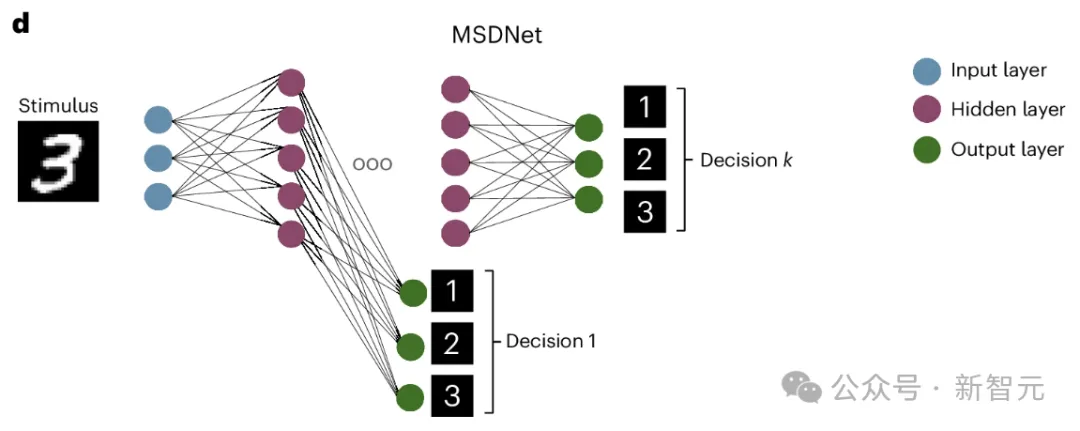
在每个输出层,使用softmax函数计算每个选择的结果,如果任何一个方案的结果超过预定义值,网络将停止处理并立即产生响应。
下图a – e ,分别表示人类、RTNet、CNet、BLNet和MSDNet所做决策的随机性。暖色表示两次呈现图像时给出的反应相同,而冷色表示两次呈现图像时给出的反应不同。
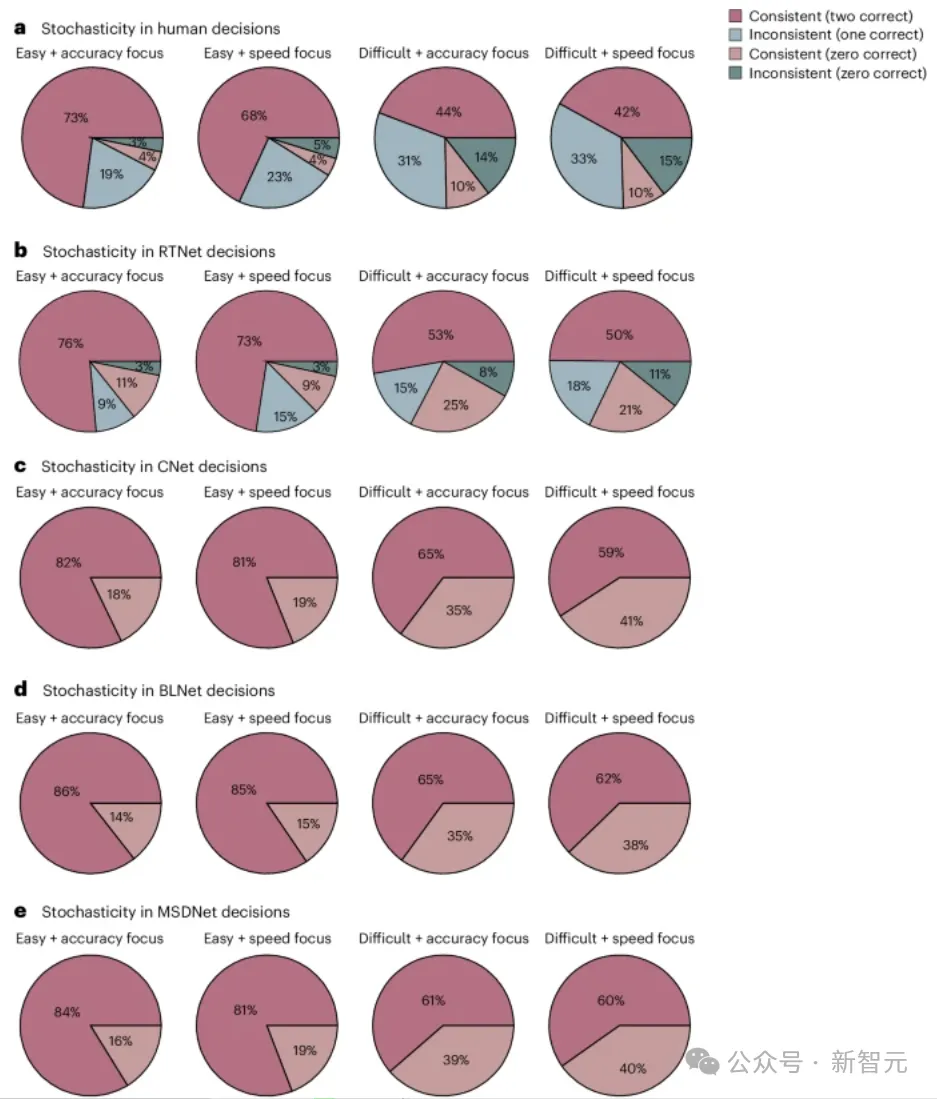
人类和RTNet表现出随机决策,随机性随着任务难度和速度压力的增加而增加。但是,CNet、BLNet和MSDNet的决策是完全确定性的。
下图展现了人类参与者和模型表现出的行为效果:
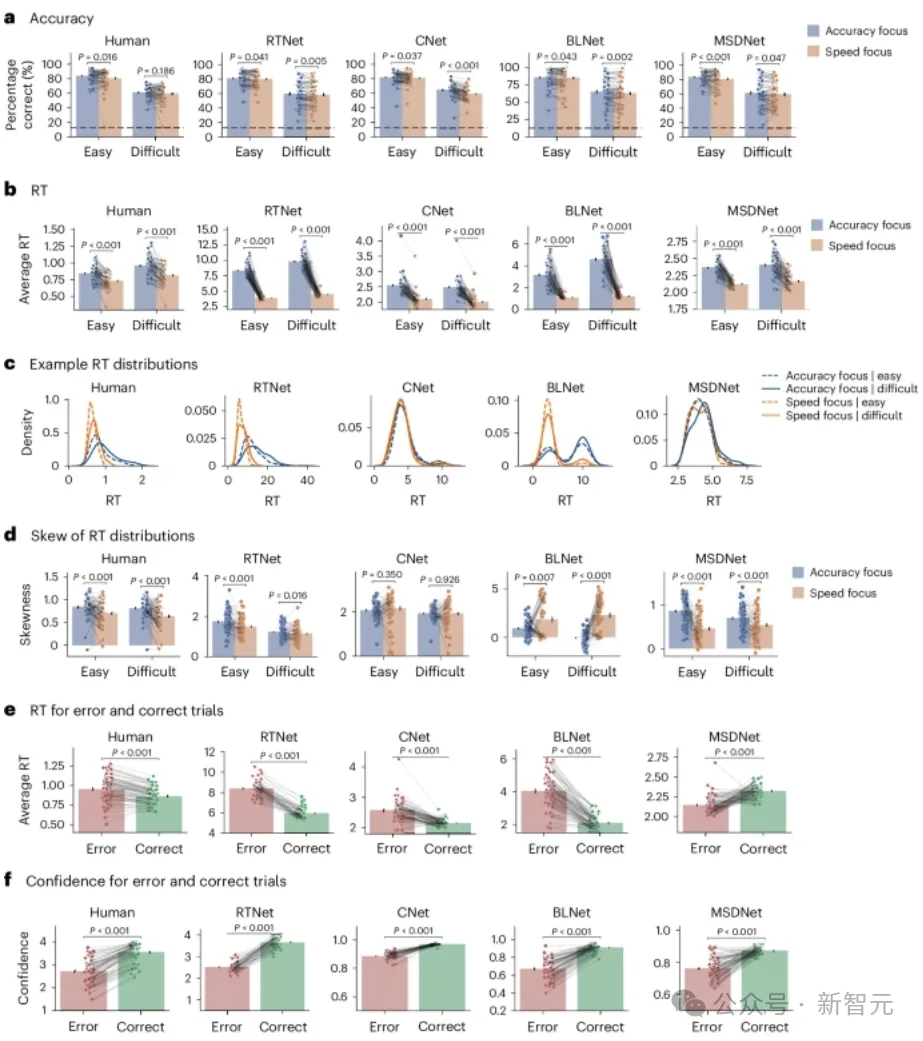
其中,人类的RT以秒为单位,神经网络的RT以所消耗的推理次数(RTNet)、传播步骤数(CNet)、前馈扫描数(BLNet)和层数(MSDNet)来衡量。
所有模型均能够复制在人类身上观察到的SAT。但SAT对人类、RTNet和BLNet的影响比其他模型要强得多,且各个RT分布显示出,速度和准确度焦点条件之间存在明显分离。
总体而言,RTNet产生的RT分布比所有其他网络都更好地反映了人类数据中观察到的模式。
需要注意的是,CNet、BLNet和MSDNet只能产生小于或等于其层数或残差块的不同 RT,相比之下,RTNet可以处理任意数量的样本,而不管其架构中的层数是多少。
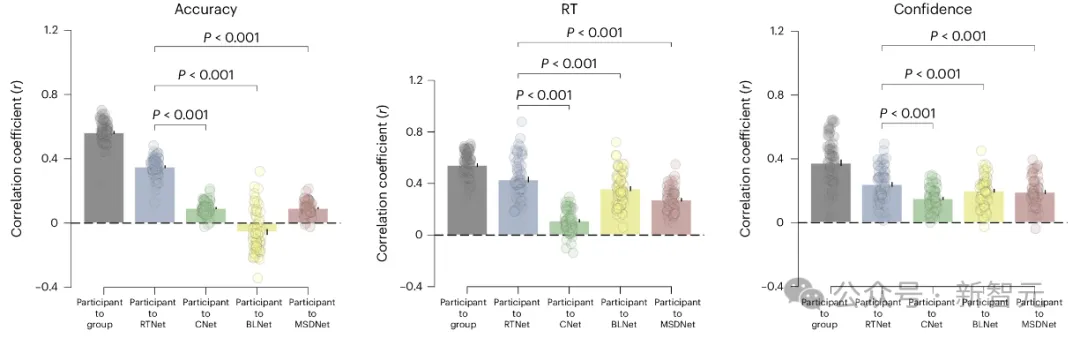
上图展示了在所有实验条件下,针对各个参与者的人体数据和每个模型之间的逐图相关性,在所有条件下分别计算准确度、RT和置信度的相关性。
对于每个测量,RTNet 的相关性都比CNet、BLNet或MSDNet更强。而在所有情况下,RTNet的预测都相当接近噪声上限。
讨论
传统的决策认知模型通常被称为顺序抽样模型。
RTNet在概念上更类似于顺序抽样模型的一个子组,称为种族模型:每个选择都有自己的积累系统,并且每个选择的证据都是并行积累的。
RTNet与传统认知模型相比具有两个重要优势。首先,RTNet是图像可计算的,可以应用于实际图像,而传统模型则不能。
其次,传统认知模型无法自然地捕捉不同选择之间的关系,而RTNet在训练其核心的BNN期间学习了选择之间的所有关系。
生理记录揭示了人类视觉系统处理的几个特点:
首先,从视觉皮层的一个区域到另一个区域的传导大约需要10毫秒,来自光感受器的信号在70-100毫秒内到达颞下皮层的视觉层次顶端。因此,纯前馈网络中从输入到输出的一次扫描应该在几百毫秒以内。
其次,视觉皮层每一层的神经元在刺激开始后的几百毫秒内继续激发动作电位,并从后面的处理层接收强烈的循环输入。
最后,神经元处理是有噪声的,即相同的图像输入会在不同的试验中产生非常不同的神经元激活。
由上面的介绍可知,RTNet基本符合了人类视觉的生物学特性。
文章来源于“新智元”,作者“新智元”




