# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
一口气生成2万字,大模型输出也卷起来了!
清华&智谱AI最新研究,成功让GLM-4、Llama-3.1输出长度都暴增。
相同问题下,输出结果直接从1800字增加到7800字,翻4倍。
要知道,目前大模型的生成长度普遍在2k以下。这对于内容创作、问题回答等都存在影响,可能导致模型回答问题不全面、创造性降低等。
该研究由智谱AI创始人、清华大学教授李涓子和唐杰共同领衔。

论文及代码都已放在GitHub上开源。
有网友已经抢先体验。LongWriter-llama3.1-8b可生成万字长文《罗马帝国衰落史》,在MacBook Pro 2018(32GB)上就能运行。
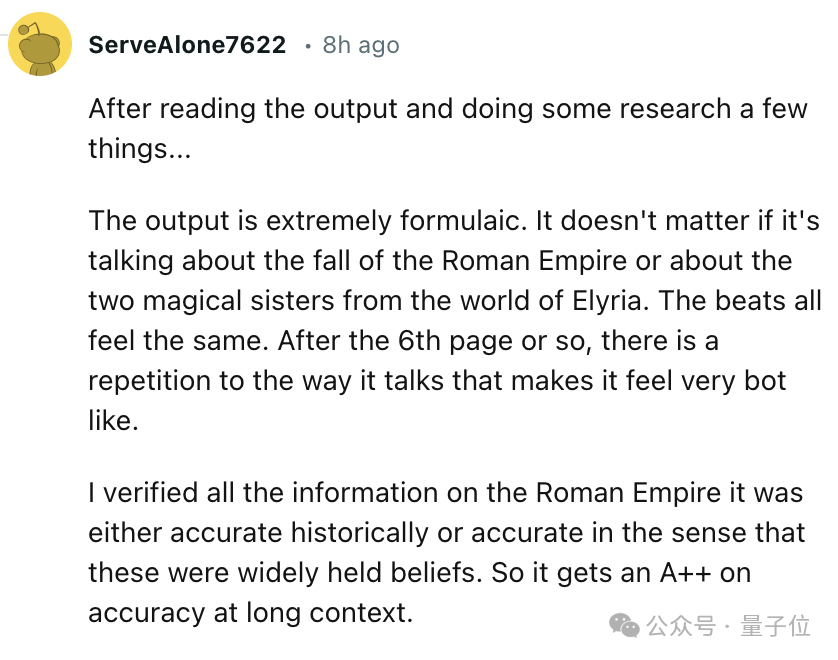
输出内容很准确,可以得A++。
本项研究主要包括3方面工作。
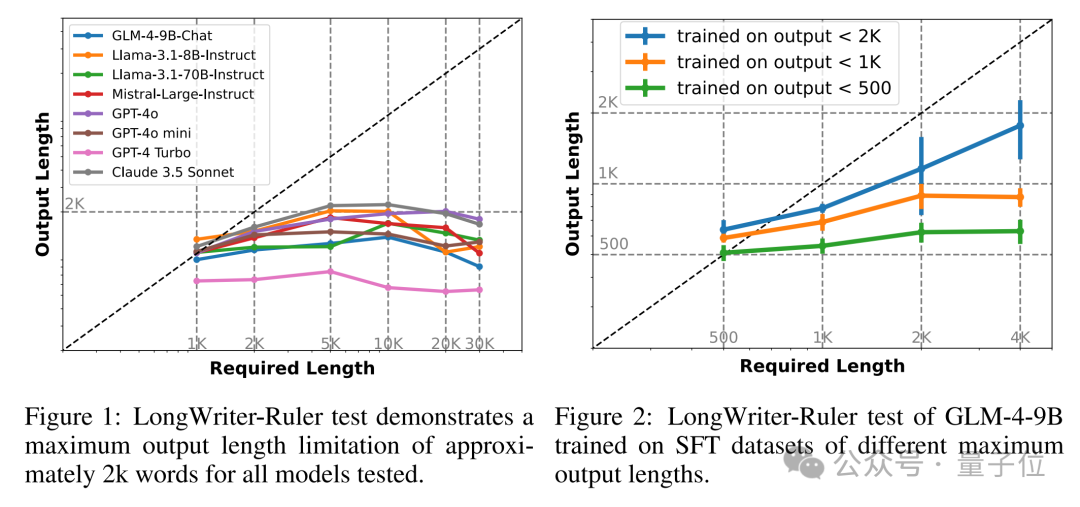
首先,研究人员构建了一个测试工具LongWrite-Ruler。通过测试多个大模型,他们发现所有模型在生成超过2000字的文本时都遇到了困难。
进一步分析用户和大模型的交互日志,研究人员发现只有超过1%的用户请求明确提到要生成超过2000字的文本。
为此,他们改变了模型在监督式微调(SFT)阶段使用的数据集的最大输出长度。
结果发现,模型的最大输出长度与SFT数据集中的最大输出长度呈显著正相关。
所以得出结论,现有模型在输出长度上受限主要是因为SFT数据集中缺少长输出样本。
即使模型在预训练阶段见过更长的序列,但是SFT阶段缺乏长文本样本,还是会影响输出长度。
为了克服这个限制,研究人员提出了AgentWrite。
这是一个基于Agent的pipline。
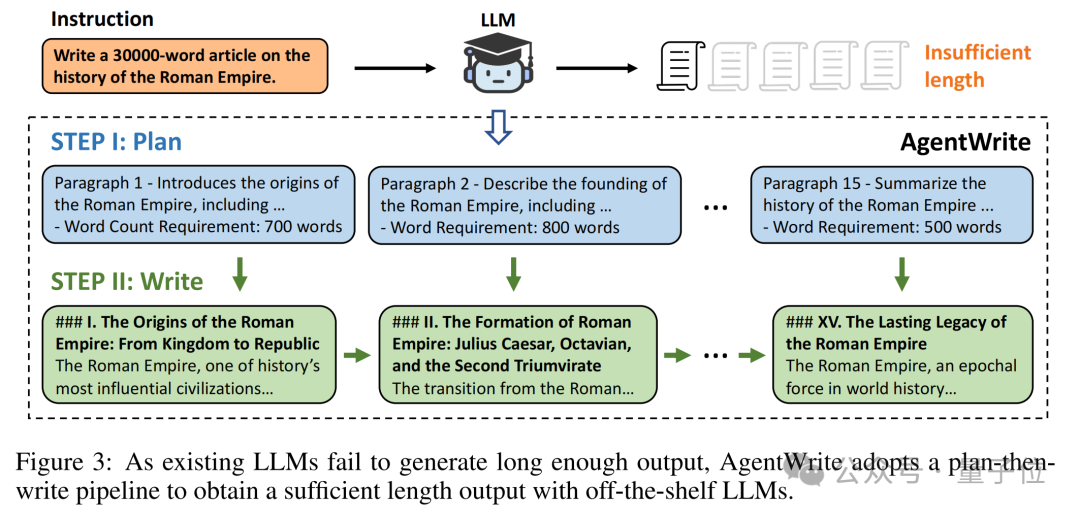
它允许将超长文本生成任务分解为多个子任务,每个子任务处理其中的一段。
具体流程是AgentWrite先根据用户指令制定出一个详细的写作计划,计划包括每个段落的主要内容点和目标词数。根据计划,AgentWrite依次提示模型生成每个段落的内容。

在AgentWrite基础上,团队利用GPT-4o生成了6000个长输出SFT数据,输出长度在2k到32k词之间,构成了数据集LongWriter-6k。并将这些数据添加到训练过程中。
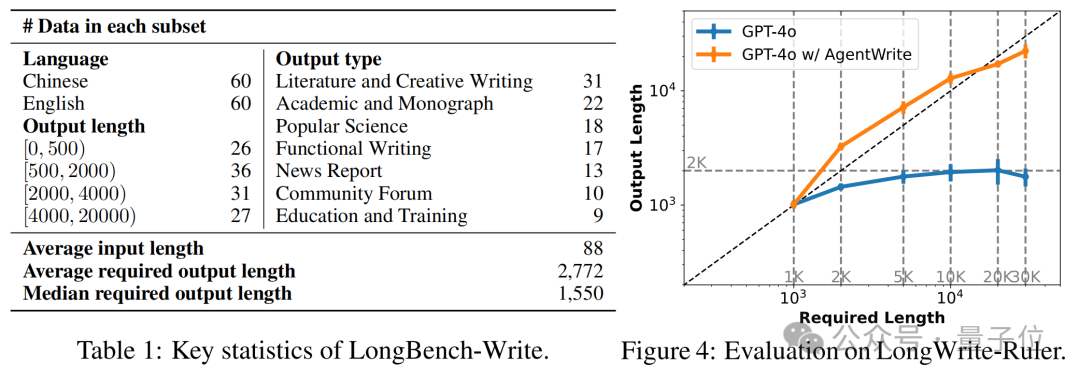
为了验证方法的有效性,团队还提出了一个LongBench-Write。其中包含了多样化的用户写作指令,输出长度规格分别为0-500词、500-2000词、2000-4000词以及4000词以上。
评估结果显示,使用AgentWrite后模型输出长度明显增加。
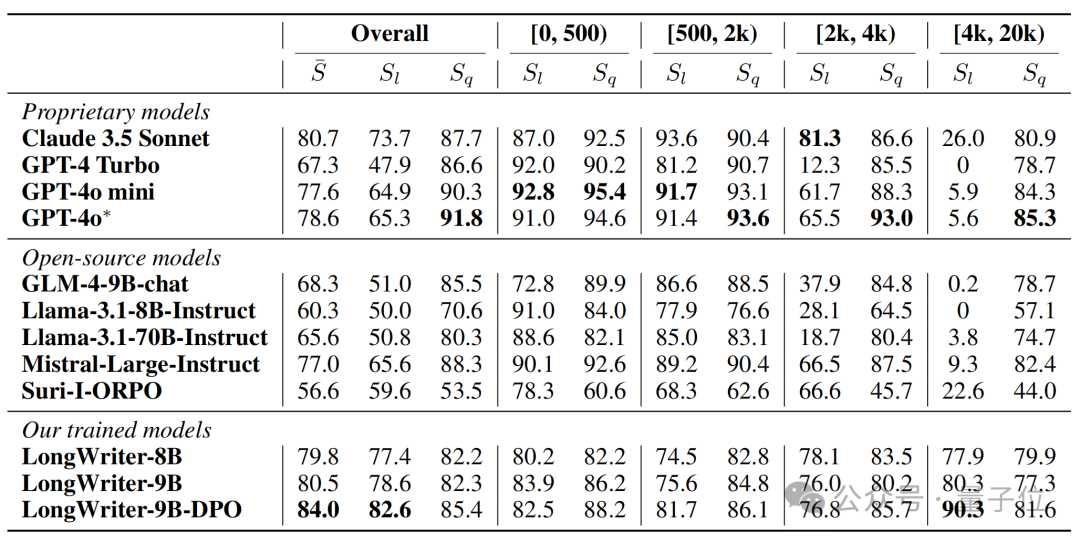
通过直接偏好优化(DPO),GLM-4-9B在一众模型中实现了最佳性能。
手速快的网友已经抢先实测。
Reddit上一位网友让LongWriter-llama3.1-8b生成罗马帝国衰败史,整体需要22分钟(与硬件有关),平均每秒生成3.34个token。

生成内容比较公式化,回答不同问题的结构、节奏相似。
无论如何这是个好的开始,带来的提升很明显。

研究团队也表示未来将进一步扩展模型的输出长度和输出质量,同时也会开始研究如何在不牺牲生成质量的情况下提高效率。
文章来源于“量子位”,作者“明敏”



【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
