# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
单目深度估计新成果来了!
方法名为Metric3D v2,是CVPR单目深度估计挑战赛冠军方案Metric3D的加强版。
用一套模型参数,在未知环境中,同时解决带尺度深度估计和法向估计两个问题。
可用于生成真实世界的几何估计:

在密集场景和特殊样本上也有较好效果:

无需微调和优化,可直接用于无人机感知:

无需调整尺度参数,提供单帧3D点云,其精度可以直接用于3D重建:

可部分替代物理深度估计工具,用于增强自动驾驶场景的单目SLAM:
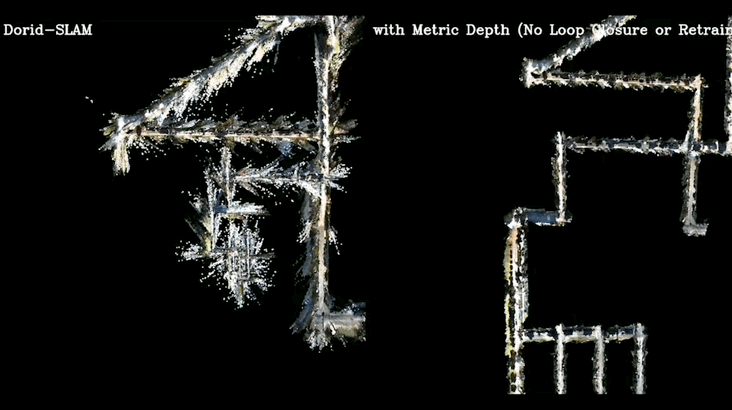
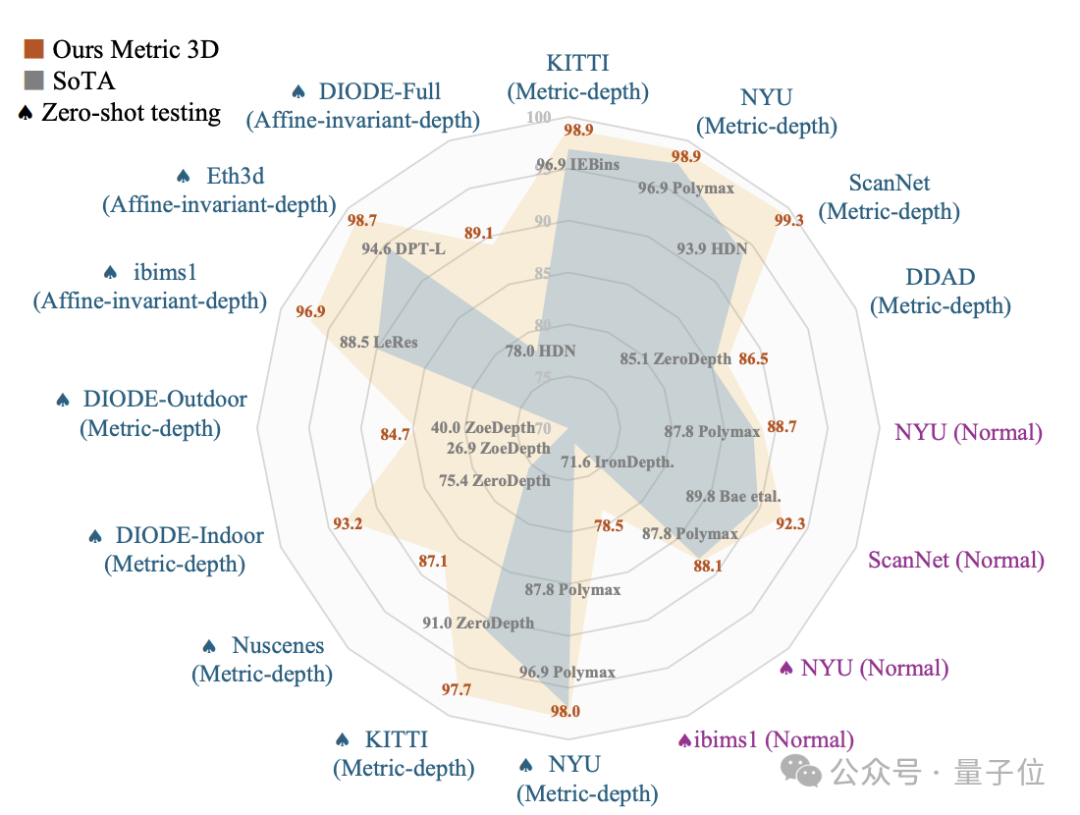
Metric3D v2在16个单目深度和法向估计基准榜单上拿下SOTA,涵盖绝对深度、相对深度和法向估计的域内和域外测试。
不做尺度对齐或微调,在KITTI上的单目深度估计相对误差可低至5%。

这项工作由来自香港科技大学、阿德莱德大学、西湖大学、英特尔、香港大学、浙江大学的研究人员共同打造,目前已被AI顶刊TPAMI接收。

单目深度估计技术在计算机视觉领域具有重要意义。这项技术能从单幅2D图像中推断出场景的3D结构,为众多应用提供了关键支持。
在传统领域,单目深度估计广泛应用于自动驾驶、机器人导航、增强现实等场景,帮助智能系统更好地理解和交互环境。
随着AIGC的兴起,单目深度估计在这一新兴领域也发挥着重要作用。它为3D场景生成、虚拟现实内容制作、图像编辑等任务提供了深度信息,大大提升了生成内容的真实感和沉浸感。
通过赋予AI系统对3D世界的理解能力,单目深度估计正在推动AIGC应用向更高维度发展。
但单目深度估计一直是一个“病态”问题,根本原因在于其受到尺度二义性的影响。
对单张图像而言,尺度二义性来自于两个方面:
其一是物体大小未知产生的二义性:
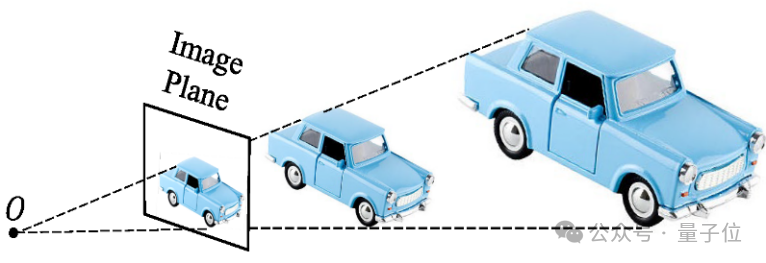
为解决这类问题,早期可泛化的深度估计模型如midas、leras等使用混合数据集训练深度估计网络,希望模型从大量数据集中学到各个物体在场景中的大小。
然而,不同数据集相机内参有很大差异,这种差异会引起第二种尺度二义性(有时又可视作透视畸变):
同一个物体,使用不同相机在不同距离拍摄出的图像也大致可能相同(下图雕塑完全一致,但背景产生了畸变),因而对该物体的深度估计会受到影响.

早期的midas、leras等工作,提出估计相对深度来规避相机差异带来的尺度二义性。
近期基于stable-diffusion的工作如Marigold/Geowizard或基于数据标注的工作DepthAnything v1/v2能够恢复更高精细度的相对深度,却无法恢复尺度信息。
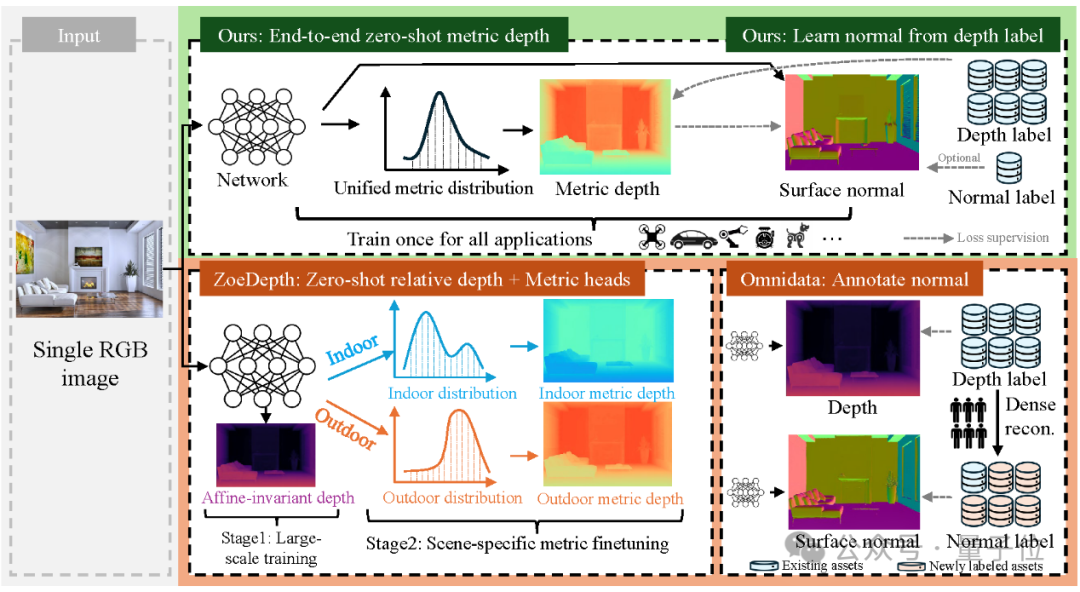
为恢复尺度信息,前人提出将预训练好的相对深度模型,在特定数据集上过拟合以学习尺度信息,如ZoeDepth。然而,该方法使得网络学到的深度分布受限于所finetune的数据集,因而尺度误差较大。
为缓解相机内参变化引起的尺度二义性,Metric3D提出在公共相机空间中学习绝对深度。该空间被定义为一个焦距固定的针孔相机模型空间。
由于网络不再受相机尺度二义性的影响,学习难度被大大降低了。
在符合透视投影几何的前提下,论文提出两种将数据从真实焦距转换到公共焦距的方法。
凭借公共相机空间的设计,Metric3D仅仅依靠卷积模型就在CVPR单目深度估计挑战赛上获得冠军。
深度图可以直接由RGB-D相机,激光雷达等测距传感器获得。
然而,法向图真值需要稠密重建点云的渲染,稠密重建本身需要大量工程和人工成本(如Omnidata)。同时,室外场景的法向数据尤其难以获得。
在Metric3D v2这项研究中,引入了一种联合深度-法线优化框架,利用大规模深度标注的知识,克服户外法线数据标签稀缺的问题。
在联合优化中,法向的知识来源有三:真实法向标注、迭代优化中深度和法向特征的前向交互 、稠密深度预测提供的伪法向标注
具体来说算法流程为:
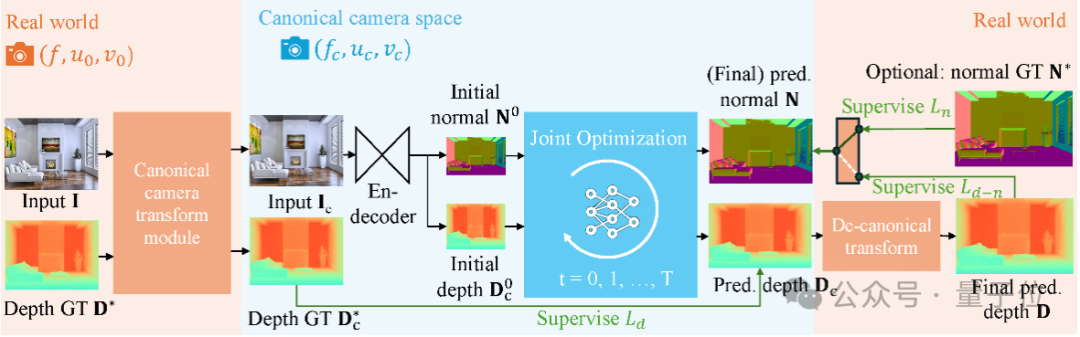
为增强模型鲁棒性,Metric3D v2在16个公开数据集共计16M张图像上进行训练。这些数据集由超过10000种相机内参采集,涵盖室内、室外、自动驾驶等多种场景。
然而,其所需的数据量仍远远小于训练DepthAnything v1/v2所需的62M。

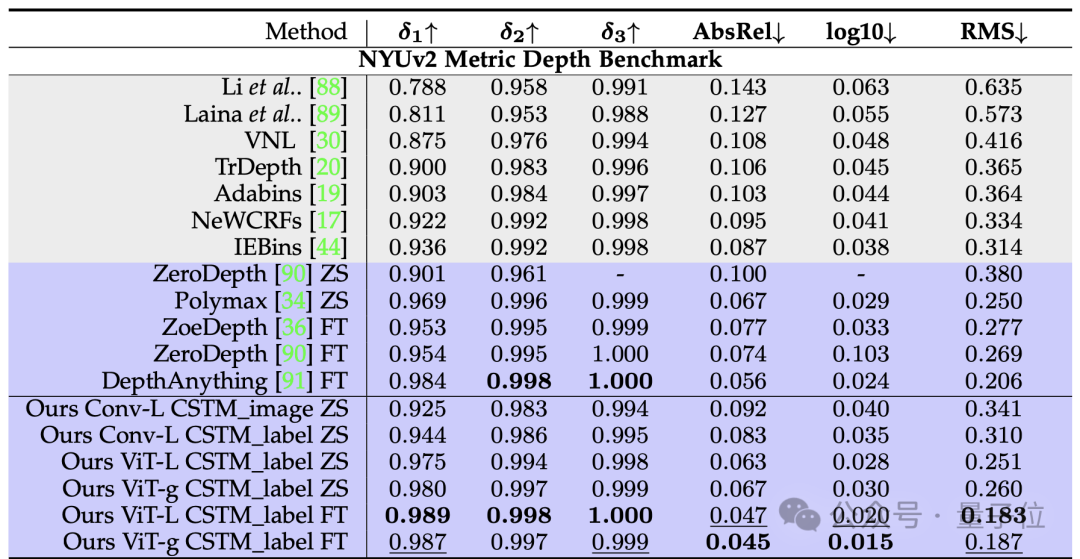
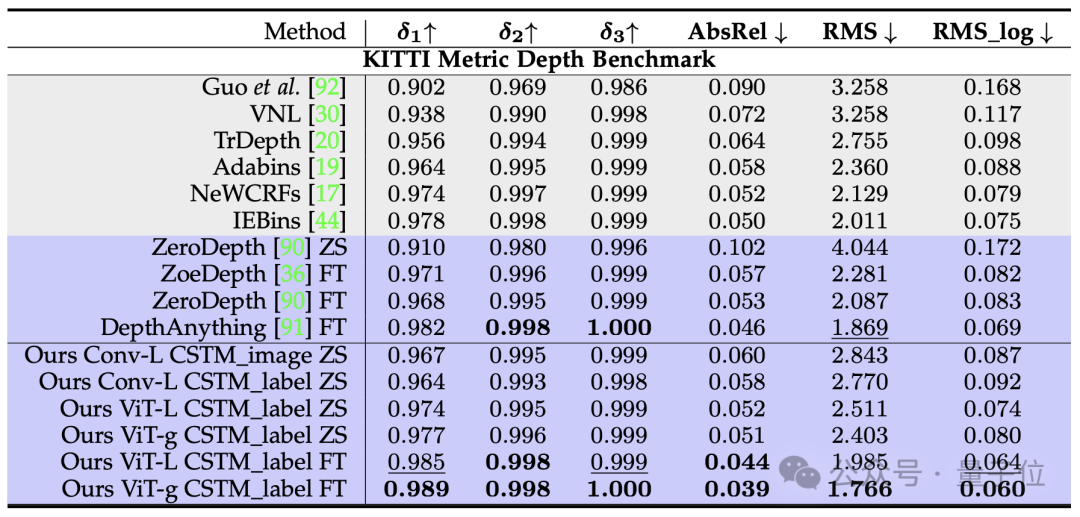
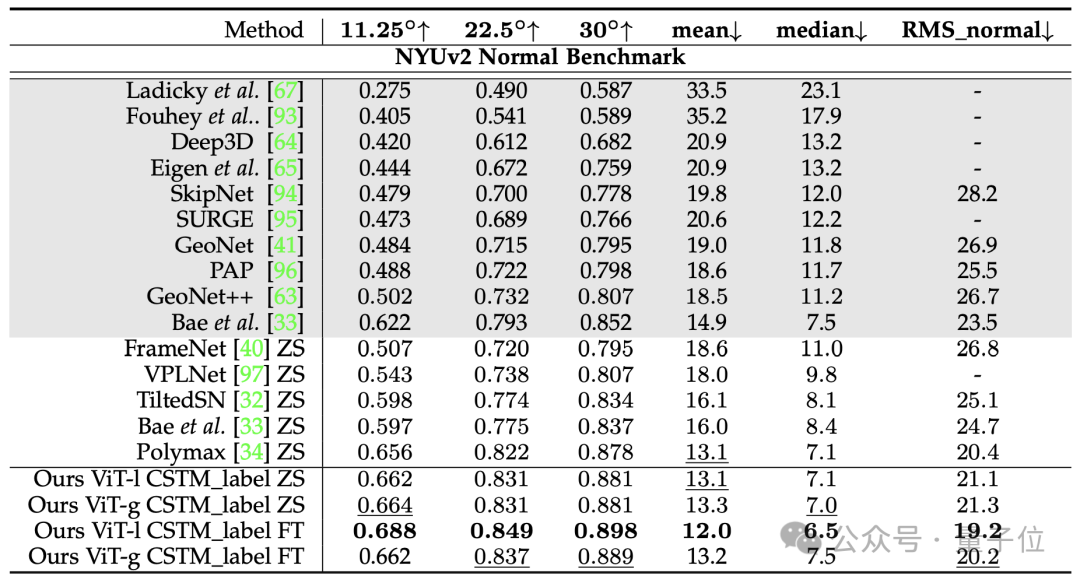
常规有尺度深度和法相估计的基准测试,Metric3D v2超越DepthAnything和OmniData(v2):
相对深度估计基准测试,量化指标优于最近在CVPR2024大放异彩的Marigold:
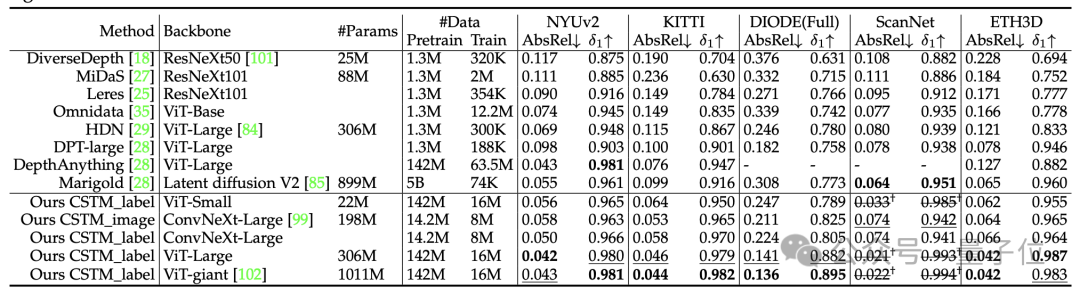
再来看定量比较。
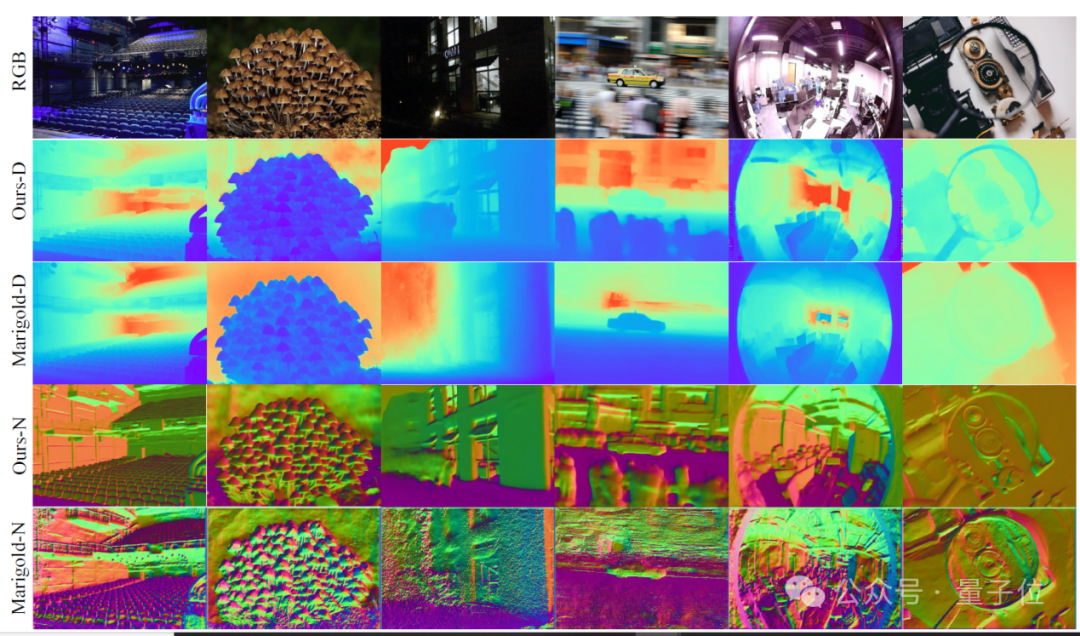
1、多场景深度与法向估计
尽管Metric3D v2是判别式模型,但在一些场景下,其细粒度也可以和基于生成模型的Marigold平分秋色。
同时,由网络预测出的法向图比深度直接转换所得的更加平滑。
对比其它基线方法ZoeDepth和OmniData(v2),Metric3D v2能给出更高细粒度的带尺度深度和法向。

2、单目场景三维重建
即使像Marigold、DepthAnything v2这样的高精度相对深度模型,也需要在特定数据上拟合、或手动挑选出一组合适的仿射参数后,才能得到三维点云。



3、单帧直接测距
Metric3Dv2模型具有更高精度的测距功能:

总的来说,Metric3D v2是一种用于零样本单目有尺度深度和表面法线估计的几何基础模型。
论文针对真实尺度下几何估计中的各种挑战,分别提出了解决方案。Metric3Dv2框架整合超过10000台相机捕捉的上千万数据样本,训练一个统一的有尺度深度和表面法向模型。
零样本评估实验展示了方法的有效性和鲁棒性。对于下游应用,Metric3Dv2能够从单一视角重建有尺度的三维结构,实现对随机采集的互联网图像的测距和单帧稠密建图。
凭借其精度、泛化能力和多功能性,Metric3D v2 模型可作为单目几何感知的基础模型。
在线试用:
https://huggingface.co/spaces/JUGGHM/Metric3D
论文链接:https://arxiv.org/abs/2404.15506.pdf
项目主页:https://jugghm.github.io/Metric3Dv2
代码仓库:https://github.com/YvanYin/Metric3D



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
