# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
一觉醒来,OpenAI又上新功能了:
GPT-4o正式上线微调功能。
并且官方还附赠一波福利:每个组织每天都能免费获得100万个训练token,用到9月23日。

也就是说,开发人员现在可以使用自定义数据集微调GPT-4o,从而低成本构建自己的应用程序。
要知道,OpenAI在公告中透露了:
GPT-4o微调训练成本为每100万token 25 美元(意味着每天都能节省25美元)
收到邮件的开发者们激动地奔走相告,这么大的羊毛一定要赶快薅。

使用方法也很简单,直接访问微调仪表盘,点击”create”,然后从基本模型下拉列表中选择gpt-4o-2024-08-06。
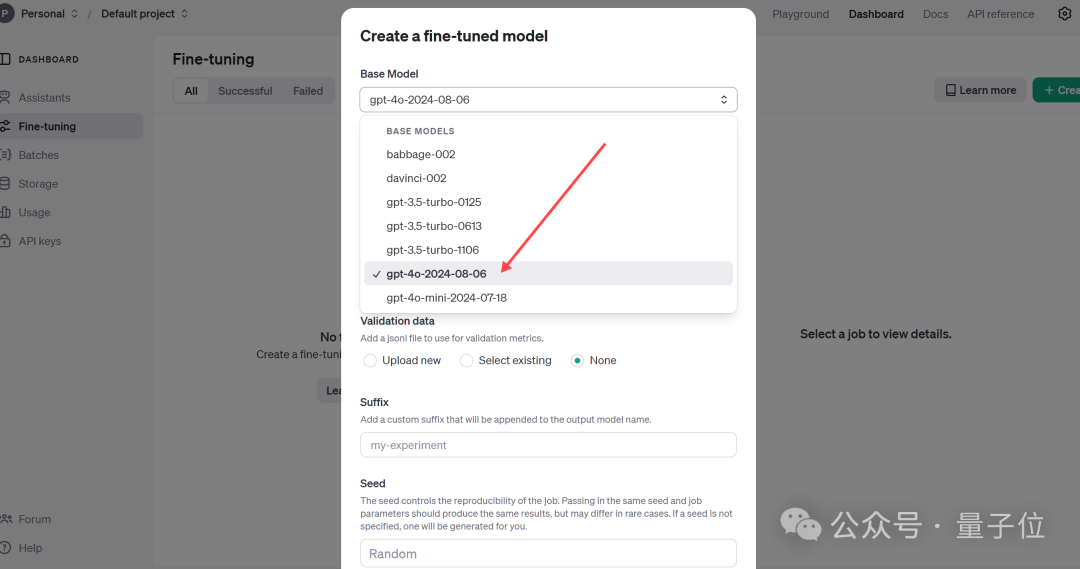
对了,OpenAI还提到,只需训练数据集中的几十个示例就可以产生良好效果。

消息公布后,一众网友跃跃欲试,表示很想知道模型微调后的实际效果。
OpenAI官方早有准备,随公告一同发布了合作伙伴微调GPT-4o的实际案例。
首先是一款代码助手Genie,来自AI初创公司Cosine,专为协助软件开发人员而设计。
据Cosine官方介绍,Genie的开发过程采用了一种专有流程,使用数十亿个高质量数据对非公开的GPT-4o变体进行了训练和微调。
这些数据包括21%的JavaScript和Python、14%的TypeScript和TSX,以及3%的其他语言(包括Java、C++和Ruby)。
经过微调,Genie在上周二OpenAI全新发布的代码能力基准测试SWE-Bench Verified上,取得了43.8%的SOTA分数。
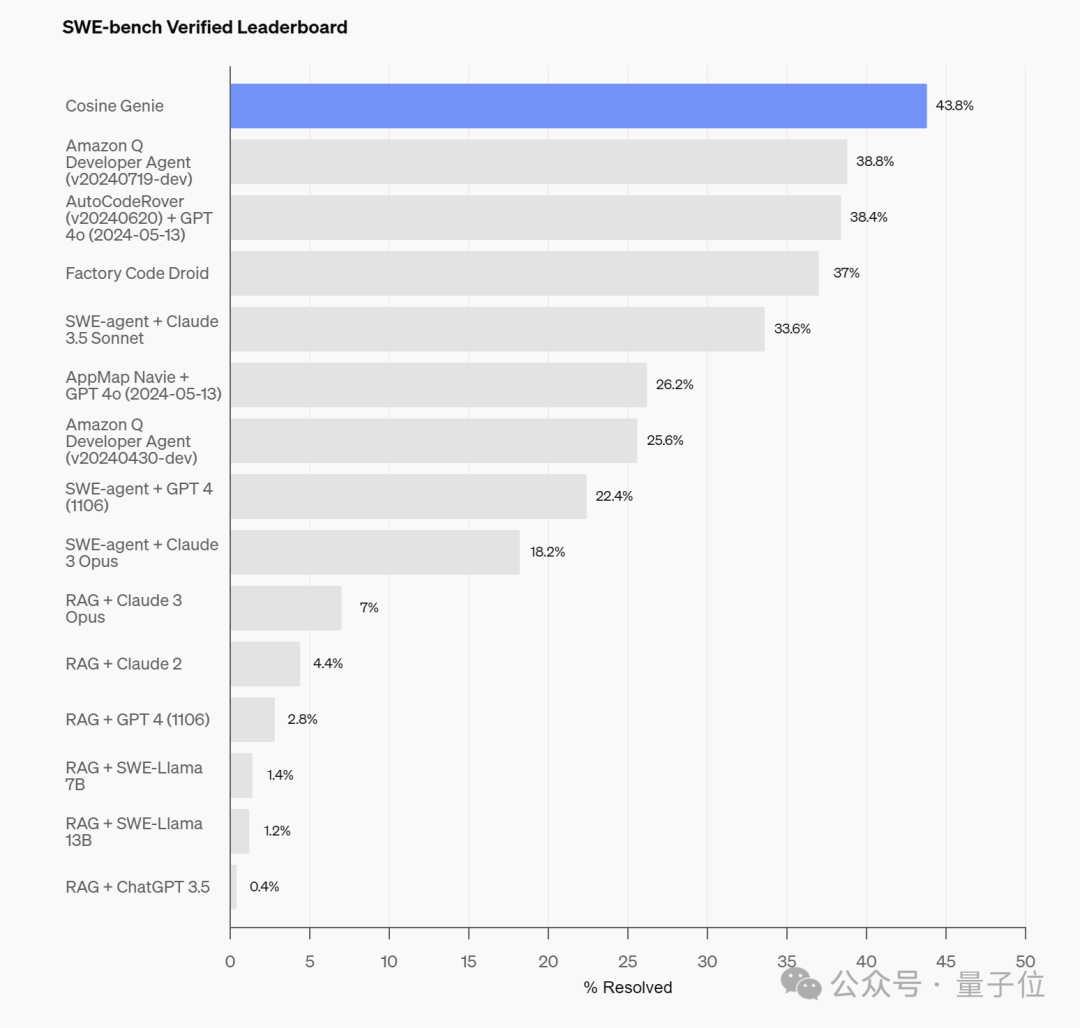
与此同时,Genie还在SWE-Bench Full上的SOTA分数达到了30.08%,破了之前19.27%的SOTA纪录。
相较之下,Cognition的Devin在SWE-Bench的部分测试中为13.8%。
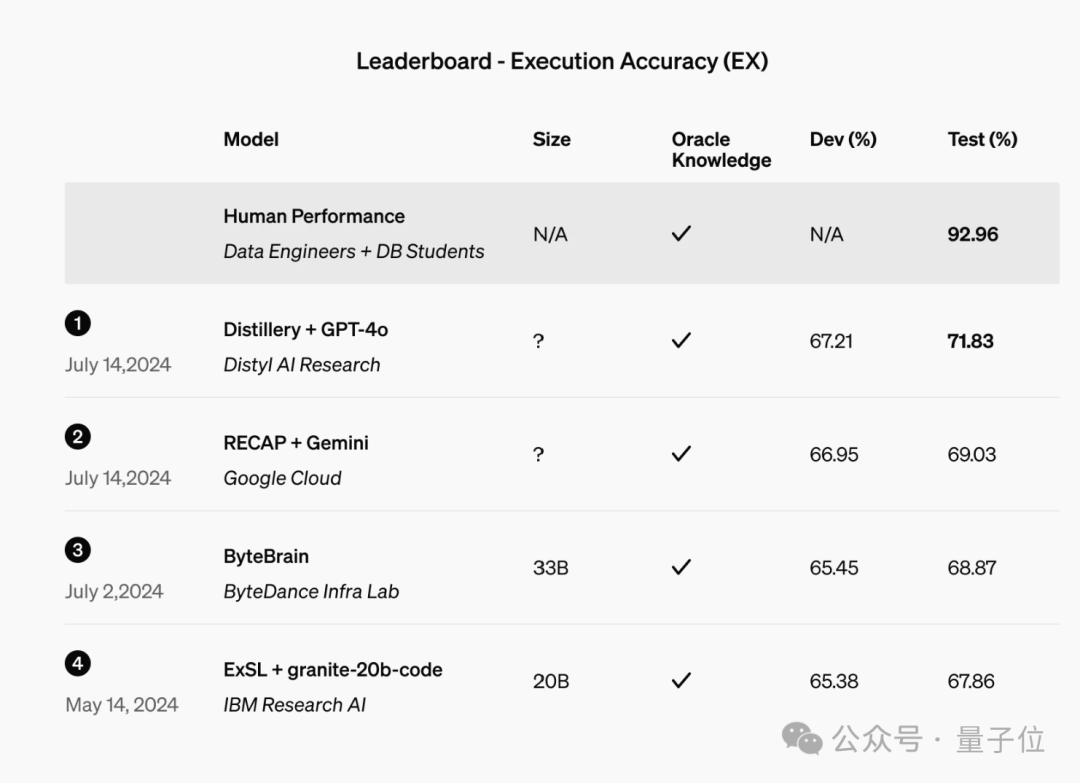
另一个案例来自Distyl,这是一家为财富500强企业提供AI解决方案的公司,最近在领先的文本到SQL基准测试BIRD-SQL中排名第一。
经过微调,其模型在排行榜上实现了71.83%的执行准确率,并在查询重构、意图分类、思维链和自我纠正等任务中表现出色,尤其是在SQL生成方面表现尤为突出。
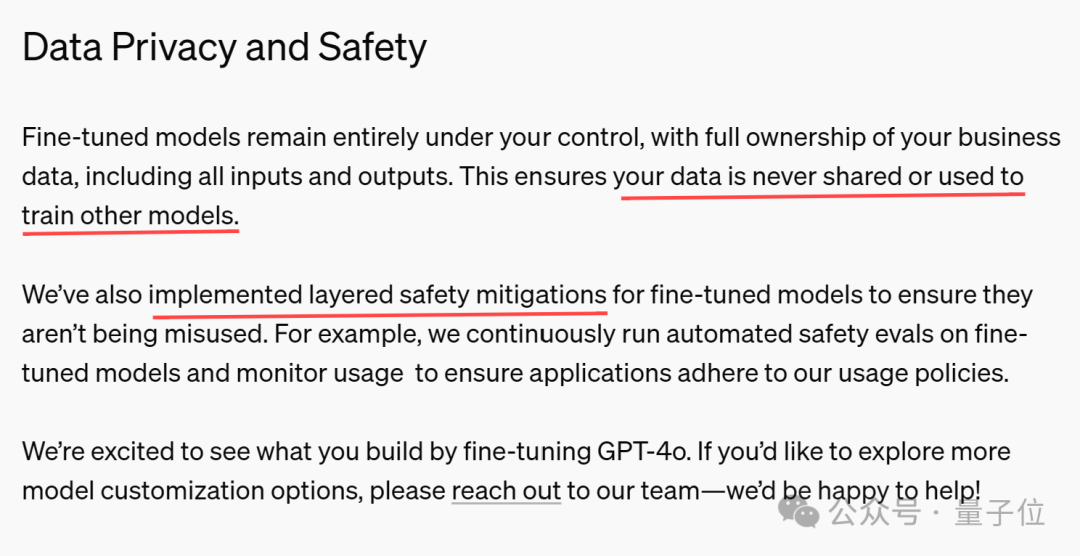
除了提供案例,OpenAI还在公告中特意强调了数据隐私和安全问题,总结下来就是:
开发者的业务数据(包括输入和输出)不会被共享或用于训练其他模型。
针对微调模型实施了分层安全缓解措施,例如不断对微调模型运行自动安全评估并监控使用情况。
一片热闹之际,有网友认为微调仍然比不上提示词缓存。
微调很酷,但它仍然不如提示词缓存……
之前量子位也介绍过,提示词缓存的作用,就是一次给模型发送大量prompt,然后让它记住这些内容,并在后续请求中直接复用,避免反复输入。
今年5月,谷歌的Gemini就已经支持了提示词缓存,Claude也在上周上新了这项功能。
由于不需要反复输入重复的脚本,提示词缓存具有速度更快、成本更低这两大优势。
有网友认为,提示词缓存功能对开发者更友好(无需异步微调),且几乎可以获得与微调相同的好处。
提示词缓存可以让您付出1%的努力获得99%的好处。

不过也有人给微调打call,认为微调在塑造响应方面更有效。例如确保JSON格式正确、响应更简洁或使用表情符号等。

眼见OpenAI的竞争对手们相继用上了提示词缓存,还有人好奇了:
想知道OpenAI是否会坚持微调或转向提示词缓存(或两者兼而有之)。
对于这个问题,有其他网友也嗅出了一些蛛丝马迹。
OpenAI在其延迟优化指南中提到了缓存技术。
我们也第一时间找了下指南原文,其中在谈到如何减少输入token时提到:
通过在提示中稍后放置动态部分(例如RAG结果、历史记录等),最大化共享提示前缀。这使得您的请求对KV缓存更加友好,意味着每个请求处理的输入token更少。

不过有网友认为,仅根据这一段内容,无法直接推出OpenAI采用了提示词缓存技术。
BTY,抛开争议不谈,OpenAI的羊毛还是得薅起来~
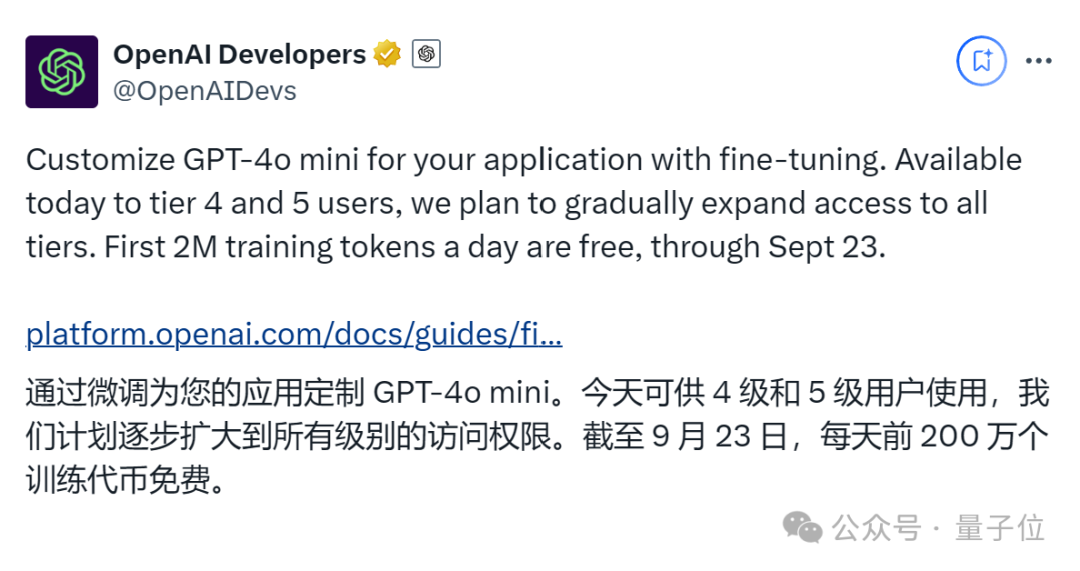
除了GPT-4o,还可以免费微调GPT-4o mini,9月23日之前OpenAI免费提供每天200万个训练token。
文章来源于“量子位”,作者“一水”




【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
