# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
论文一作兰宇时为南洋理工大学(NTU)博士生,导师为 Chen Change Loy。本科毕业于北京邮电大学,目前主要研究兴趣为基于神经渲染的 3D 生成模型、3D 重建与编辑。
在 ECCV 2024 中,来自南洋理工大学 S-Lab、上海 AI Lab 以及北京大学的研究者提出了一种原生 3D LDM 生成框架。具体来讲,他们针对现有原生 3D 生成模型可拓展性差、训练效率低、泛化性较差等问题,提出一种基于 3D VAE 和 3D-DiT 的两阶段通用 3D 生成框架 Latent Neural fields 3D Diffusion (LN3Diff)。该方法在 Objaverse 数据集上进行了大规模训练,并在多个基准测试中取得了优异成绩,并拥有更快的推理速度。

研究背景
近年来,以可微渲染和生成模型为核心的神经渲染技术 (Neural Rendering) 取得了很大的进展,并在新视角合成、3D 编辑和 3D 物体生成上取得了非常好的效果。然而,相较于统一图片 / 视频生成的 LDM 框架,基于 diffusion 模型的原生 3D 生成模型依然缺少通用的框架。
目前基于 SDS 蒸馏的方法受限于优化时长和饱和度较高的问题,而基于多视图生成 + Feedforward 重建的两阶段方法受限于多视图生成效果与多样性。这些限制极大地制约了 3D AIGC 的性能与自由度。
为了解决上述问题,研究者提出将基于 LDM (Latent Diffusion Model) 的原生生成框架引入 3D 生成,通过在 3D 隐空间直接进行 diffusion 采样来实现高效、高质量的 3D 资产生成。
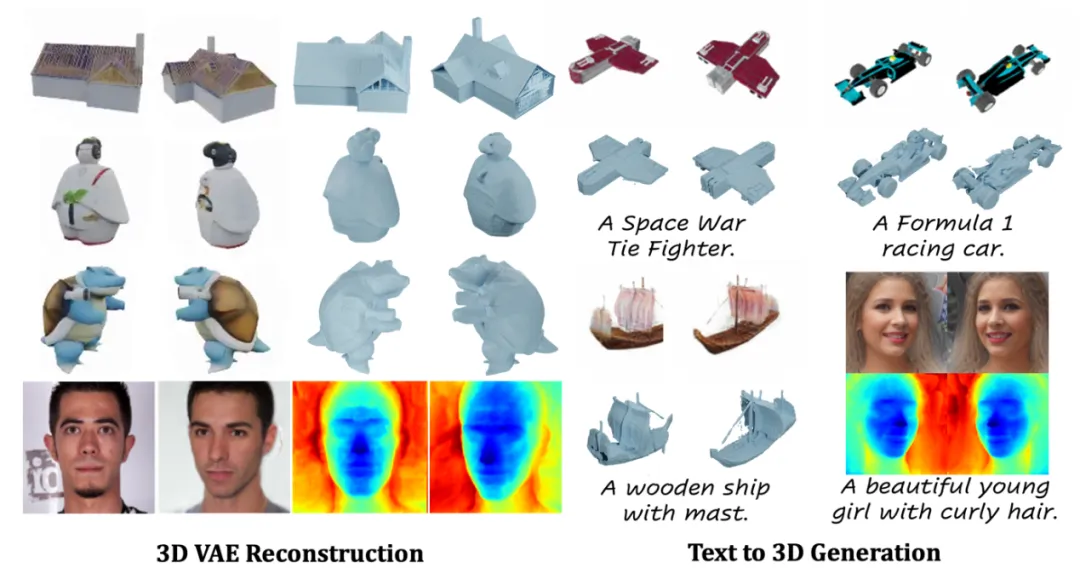
方法效果图
方法
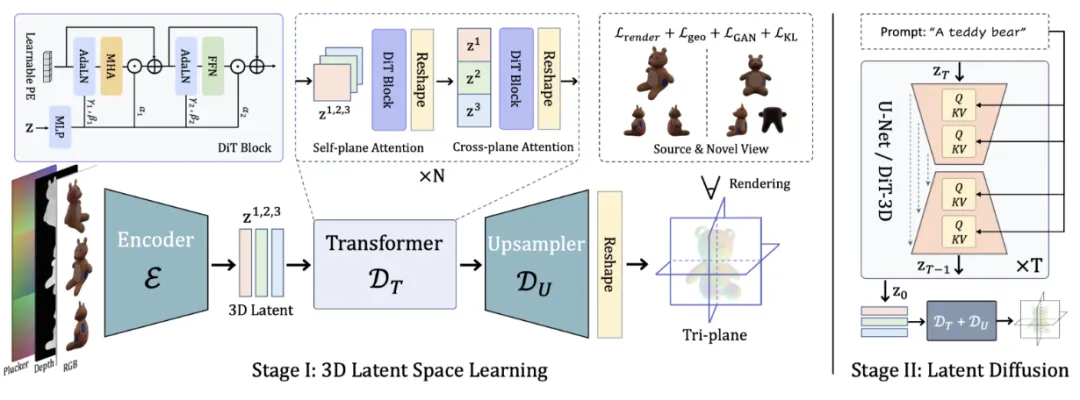
方法概览图
尽管之前的工作也尝试使用 LDM 直接进行 3D 生成,但受制于可拓展性、生成效率与在大数据上的泛化能力,并没有成为主流的 3D 生成方案。
因此,研究者提出 Latent Neural fields 3D Diffusion (LN3Diff),一种适用于任意 Neural Fields 的通用 3D 生成框架,以实现高效、高质量、可控的 3D 生成。
3D-aware VAE : 高效信息压缩
首先,和图片 / 视频生成模型类似,3D 隐空间生成模型需要与之适配的 VAE 模型来实现高效的信息压缩。为了更好地兼容 3D 模态,相较于直接使用 SD VAE 模型来进行信息编码,本文选择在大规模 3D 数据上重新训练 3D-aware VAE 模型。
在编码器端,研究者选择 3D 物体的多视图 (multi-view images) 作为 3D VAE 的输入形式,以保留纹理建模能力并更好地兼容 2D 图像编码器的结构。同时将多视图图像、对应的深度图以及 Plucker 相机信息作为模型输入,并在 token 空间进行 3D-aware attention 运算以实现更好地 3D 一致性。
在解码器端,为了实现更优的信息压缩,研究者使用基于 3D-DiT 的 VAE 解码器。为了更好地支持 3D-aware 操作,在 3D-DiT 解码器端提出 Self-plane attention 与 Cross-plane attention 来使用注意力运算在 token 空间提升 3D-aware 表达能力。随后,3D-DiT 解码器输出的 tokens 会逐步上采样为 tri-plane, 并渲染成多视图来进行目标函数计算:
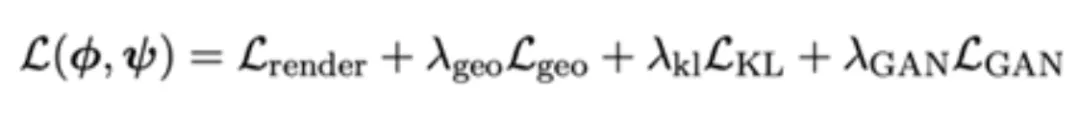
其中 为多视图重建损失,
为多视图重建损失,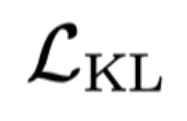 为 VAE KL 约束,
为 VAE KL 约束,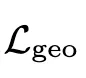 为物体表面几何平滑约束,
为物体表面几何平滑约束,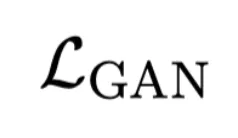 用于提升 3D 材质真实性。在实验数据上,研究者使用目前最大规模的开源 3D 数据集 Objaverse 来进行 VAE 训练,并公布了 DiT-L/2 尺寸的 VAE 预训练模型供用户使用。
用于提升 3D 材质真实性。在实验数据上,研究者使用目前最大规模的开源 3D 数据集 Objaverse 来进行 VAE 训练,并公布了 DiT-L/2 尺寸的 VAE 预训练模型供用户使用。
DiT-based 3D Latent Diffusion Model: 通用 3D 生成框架
在第二阶段,研究者在训练完成的 3D VAE space 上进行 conditional 的 diffusion 训练。得益于 3D-VAE 强大的压缩性能与隐空间的通用性,他们可以直接在压缩得到的 3D latent space 上使用成熟的 conditional latent diffusion model 框架进行训练。
在 ShapeNet 等较小规模数据集上,研究者使用 U-Net 模型结构进行 image-conditioned 训练;在较大规模的 Objaverse 数据集上,研究者使用 3D-aware DiT 模型进行 image-condition 和 text-condition 两个版本的模型训练。得益于 3D latent space 高效的表达能力,使用有限的计算资源 (4xA100 80GB) 便可以实现高质量的 3D diffusion 训练,并将模型尺寸 scale up 至 DiT-L/2。
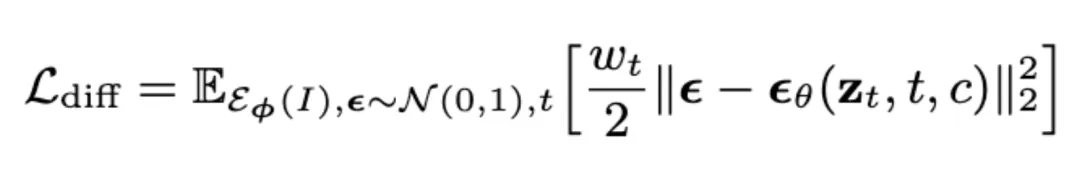
实验
数据集 ShapeNet 对比
为了与目前 3D 生成方法进行公平对比,研究者同时选择了小规模数据集 ShapeNet 与大规模通用 3D 数据集 Objaverse 进行试验。
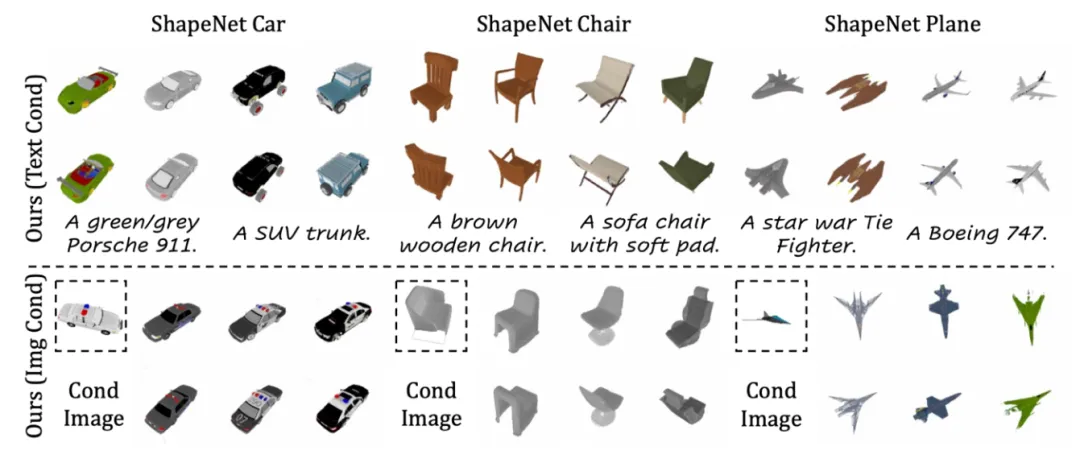
结果显示,在数据集 ShapeNet 的三个子类上,本文方法在各项指标均取得了 SoTA 的性能。相比于目前 unconditional 的生成方法,本文方法同时支持 text/image conditioned 生成。
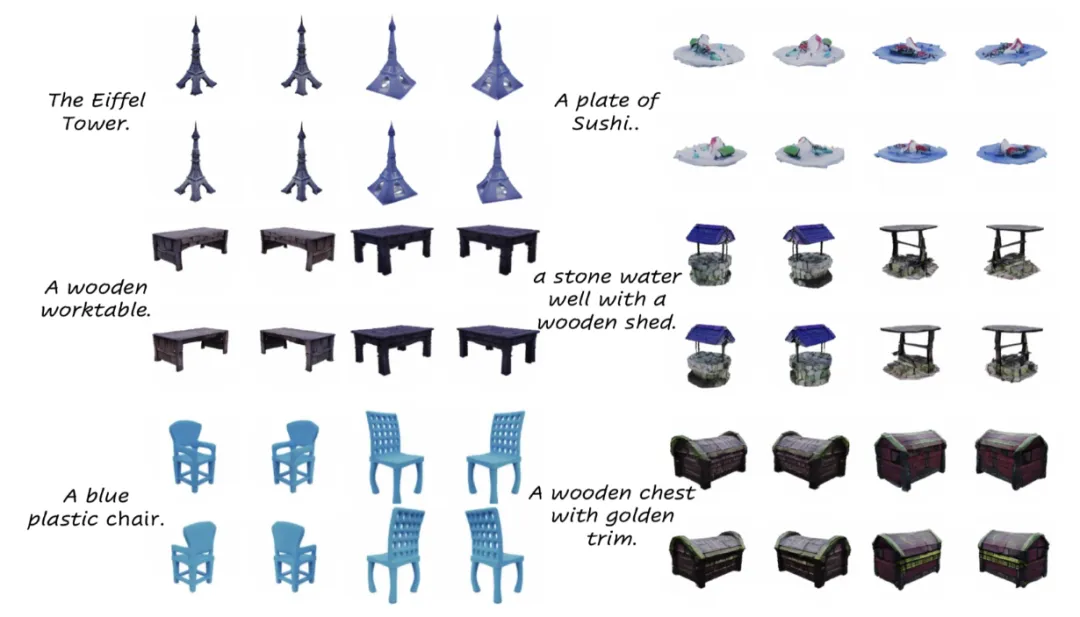
以文本为条件的 Objaverse 3D 生成
在大规模 3D 数据集 Objaverse 上,本文基于 DiT 的 3D 生成模型支持从文本描述直接生成丰富、带有细节纹理的高质量 3D 资产,并支持 textured-mesh 的导出。得益于原生 3D diffusion 框架的支持,生成过程仅需数秒即可完成。
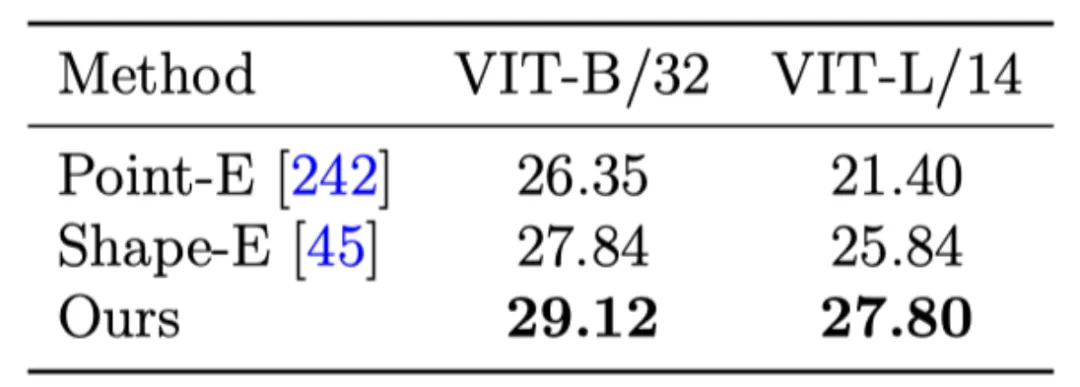
在数值指标上,LN3Diff 同样优于目前最优的原生 text-conditioned 3D 生成方法。
以图像为条件的 Objaverse 3D 生成
考虑到 3D 内容创作更多采用图片作为参考,本文方法同样支持在给定单目图片条件下实现高质量 3D 生成。相比于多视图生成 + 重建的两阶段方法,本文方法在 3D 生成效果、多样性以及 3D 一致性上有更稳定的表现:
模型输入 (single image condition):

模型输出:



模型实现 / 开源
目前项目所有模型和测试 / 训练代码均已全面开源至 Github/Huggingface, 并支持多卡、自动混合精度训练、flash-attention 以及 BF16 等加速技巧。
文章来源于“机器之心”



