# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Viggle AI 这家以其同名视频生成服务而闻名的初创公司,近日宣布完成 1900 万美元的早期投资,其中 Andreessen Horowitz 领投。
Viggle 公司的创始人兼 CEO Chu Hang 是一位华人,在 Google、英伟达、Facebook 和 Autodesk 都工作过。
你可能不了解 Viggle AI,但你可能见过它做的表情包。
这些是在网上疯传的表情包:说唱歌手 Lil Yachty 在夏季音乐节上蹦跳,但他被换成了电影《小丑》里的 Joaquin Phoenix。

耶稣似乎在为人群加油鼓劲:

Viggle 最初从 Discord 社区开始起步,目前用户已经超过了 430 万,3 月份上线了独立的 App 产品。团队使用了自己开发的 JST-1 模型,支持人们创建更逼真的人物动作和表情。
今天的文章里,我们将了解 Viggle 这个华人创立的小团队,是如何取得「病毒式」用户增长,以及创始人在 a16z 的访谈。资料来自 TechCrunch 以及 Z potential,Founder Park 略有调整。
2024 年 3 月,Viggle 推出内测,目前吸引了超过 400 万名 Discord 社区用户。用户们聚集在一起玩二创。
目前,Viggle 主要有两类用户群:
第一类:社交媒体乐子人。他们想做出娱乐性的 meme,追求的是好玩,想要社交传播效果好。Viggle 非常有吸引力的特效激发了这类人的尝试欲,然后通过社交渠道传播裂变。这也是提升产品知名度最好的方法之一。
第二类用户:专业创作者。这类用户用 Viggle 来设计游戏、做视觉特效。比如,动画工程师可以快速把概念变成粗略的动画,让想法和感觉变得视觉化,大大减少设计草稿的时间,减少繁琐的工作流,提升效率。
Viggle 的团队成员充满激情,而且技术精湛。创始人 Chu Hang 曾在 Autodesk、Facebook、Nvidia 和 Google 等全球领先的科技公司担任 AI 研究员。在上海交通大学获得信息工程学士学位后,他在康奈尔大学攻读电气与计算机工程硕士学位,并在高级多媒体处理实验室进行研究。2016 年,Chu Hang 进入多伦多大学,在计算机科学领域攻读博士学位,专注于机器学习领域的研究。
过去 8 个月,担任 Viggle 产品增长负责人的是 Nan Ha。她是一名资深的 SEO、内容营销和联盟营销合作的专家,毕业于 USC 与 LSE 的联合研究生项目环球沟通与传媒专业。在她的领导下,Viggle 的 Discord 社区从 500 名成员,迅速扩展到超过 400 万成员,成为全球第二大社区。
依托于 Discord 平台运营,Viggle 迅速扩大用户基础,并借助 Discord 的内容审核和社区管理工具来管理庞大的用户群体。相比国内的平台,像是小红书和抖音,Discord 的即时性和互动性更好地支持了 Viggle 的病毒式传播和用户增长。
对于像 Viggle 和 Midjourney 这样的初创企业来说,在 Discord 上运营意味着他们不需要为用户建立独立的平台。相反,他们可以利用 Discord 上技术娴熟的用户群体和内置的内容审核工具。对于仅有 15 名员工的 Viggle 来说,这种支持至关重要。
Discord 的产品副总裁 Ben Shanken 评论道:「没有人能为这样的增长做好准备,我们在他们广泛传播的阶段,选择与他们合作,是因为他们还是一个初创公司,实际上 Discord 上有很多生成式 AI 创作的内容。」
当然,Viggle 在 TikTok 上也取得了广泛的传播。
#Viggle 词条下有超过 4 万条视频,#viggleai 词条下也有超过 3.3 万条视频,显示了其强大的用户参与度。
例如,博主 Geirill 在 TikTok 上以 6030 粉丝获得 41.6 万赞,其中 Viggle AI 视频独占 31.4 万赞。KOL 和博主的推广为 Viggle 带来了巨大的流量支持,用户也乐于使用 Viggle 制作视频,进一步促进了产品传播和裂变效应。
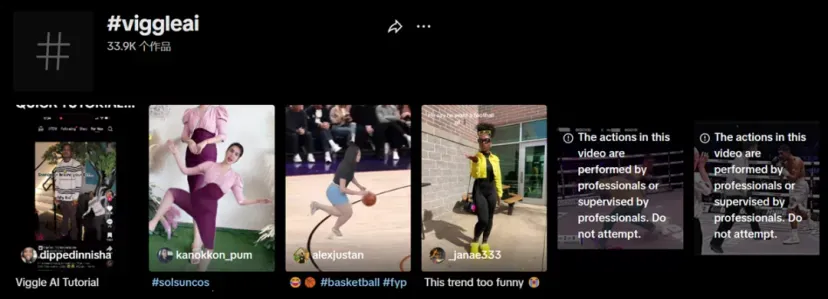
图片来源:tiktok
Viggle 的低使用门槛使得普通人和普通创作者也能够轻松上手。这种广泛的用户基础和便捷的创作体验,是 Viggle 能够迅速在 Discord 社区、TikTok 内爆发式增长的原因之一。
这些不同版本的表情包都是用户做的,但原始素材是 Viggle AI 提供的。
「我们的模型跟传统的视频生成器有本质上的区别。现有的视频生成器主要基于像素,不了解物理结构。我们让模型理解这些,所以产品在可控性和生成效率方面好得多。」CEO Chu Hang 说。
比如,要制作一个类似小丑唱跳的替身视频,只需要上传一份包含唱跳动作的视频,以及替身的图像就好了。

或者,用户可以上传角色图像,直接加上文字 ptompt。
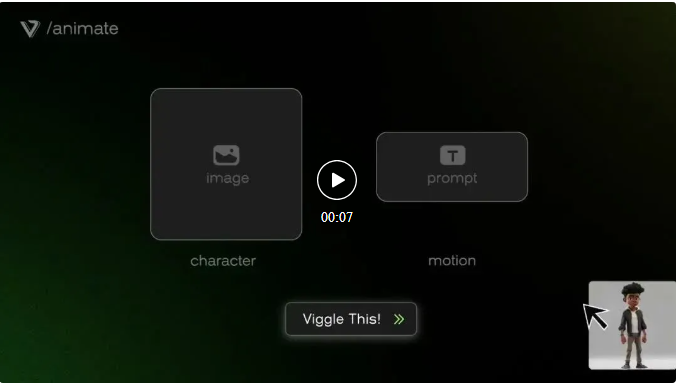
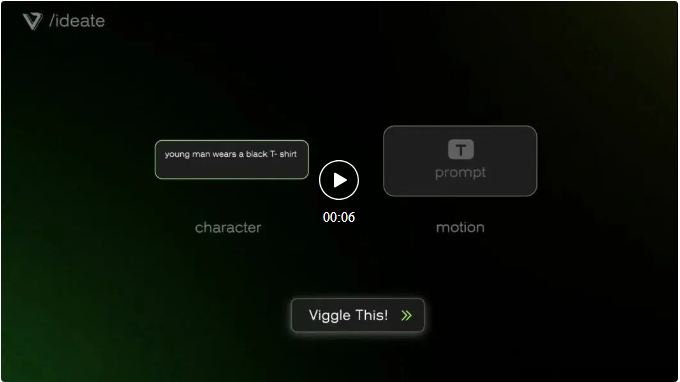
全部用文字 prompt 创建动画角色也行。
此外,还能风格化真人照片,再加动效。
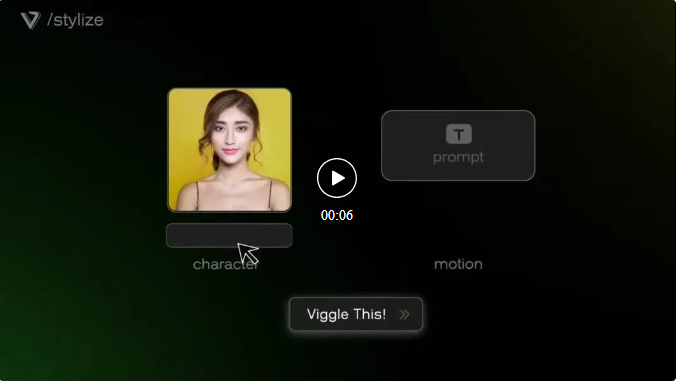
制作表情包,只占 Viggle 用户需求的一小部分。现在它生成的视频离完美还很远:角色们抖个不停,脸上毫无表情,但 Viggle 也已经是创意工作者们爱用的可视化工具了。对电影制作人、动画师和视频游戏设计师来说,用 Viggle 可以把他们的想法直接转化为视觉效果。
Viggle AI 模型的训练素材的其中一个来源是 YouTube 视频。CEO 在媒体采访中透露,他们到目前为止依赖的一直是公开的数据,包括 YouTube 视频。这话跟 OpenAI CTO Mira Murati 聊 Sora 的训练数据时说的话差不多。
这可能成为一个问题。今年 4 月,YouTube CEO 说,用 YouTube 视频训练文生视频 AI「明显违反」他们的服务条款,对 Sora 来说是这样,对 Viggle 来说可能也是。
后来,Viggle 的一位发言人向媒体补充说明道:Viggle 利用各种公共资源(包括 YouTube)来生成 AI 内容。我们的训练数据经过精心策划和完善,确保整个过程符合所有服务条款。我们优先与 YouTube 等平台保持良好的关系,并致力于遵守其条款,避免大量下载和任何其他涉及未经授权的视频下载的行为。
这看起来好像仍然跟 YouTube 4 月的评论矛盾。据报道,包括 OpenAI、Nvidia、Apple 和 Anthropic 在内的许多 AI 模型开发商都用 YouTube 视频转录或剪辑来训练模型。
这或许是硅谷的一个不太算是秘密的秘密:每个人都可能这样做,只是很少有人大声说出来。
传统上,视频和 3D 生成被视为两个独立的挑战。Viggle 通过采用一种创新的联合解决方案,成功应对了生成式视频技术中的两个关键挑战:高延迟和低可控性。
可控性
Viggle 与其他纯生成类AI产品(如 Runway、Sora 等)相比,提供了更高的可控性和预见性。
使用 Runway 时,用户通过输入一段提示语生成视频,但无法预测最终的生成结果,需要多次尝试才能得到理想效果,缺乏对生成过程的控制。
Viggle 允许用户上传已有的视频和图像,表明他们对最终生成的视频明确的预期。Viggle 通过模版与上传的视频动作来学习,快速并精确地生成用户预想中的视频内容,解决了其他AI视频生成工具中常见的可控性差的问题。这使得 Viggle 成为视频从业者和 AI 创作者的更优选择,尤其是那些质量要求高、物理效果要合理的视频场景中。
低延迟
Viggle 独创的 JST-1 技术,将视频和 3D 生成统一在一个基础模型中处理。Viggle 的技术方案显著降低了视频生成的延迟问题。这种统一模型能够有效利用 3D 空间信息和时间动态,减少传统方法中分开处理所带来的冗余和延迟,使得用户不必等待几分钟或几小时才能获得几秒钟的视频。
JST-1 作为驱动力,使得视频-3D 基础模型能够从现有的 2D 视频资料中分析视频中的动作和姿势并构建出 3D 模型。这个过程不仅涉及到形状和外观的转换,还包括对角色动作和环境交互的物理理解。
探索跨领域应用与提升动画制作效率
Viggle 还计划继续提升技术并扩展其功能。Chu 表示:「我们将重点放在构建后台服务的模型,同时借助 Discord 的前端基础设施。这种方法使我们能够更快地进行迭代,专注于开发最先进的 AI 系统。」
此外,公司还在探索娱乐以外的多个应用场景,如游戏设计和视觉特效领域。通过 Viggle,动画团队可以从概念设计中快速生成初步的动画资产,从而节省时间和精力,这有可能彻底改变动画制作的方式,使其更加高效且易于操作。
图片来源:viggle

Chu Hang:目前我正在负责一个名为 Viggle 的项目,我们称之为「可控视频生成」。这与市面上现有的文本到视频的转换工具不同,我们希望能提供更精确的控制能力。我们的目标是让用户能够精确指定动作和角色。
我们团队之前也是图像和视频生成工具的重度用户,但我们面临的最大挑战是,学起来太难了,学习曲线很陡。所以,我们希望 Viggle 能简单易用,让每个人都能轻松上手,不需要复杂的学习过程。
Viggle 的基本功能很简单。你只需要上传两个东西:一个是图像,用来确定角色;另一个是文本或者视频,告诉 Viggle 你想要的动作。然后 Viggle 就能把这些合在一起,生成角色做特定动作的画面。一开始,我们是想给电影和游戏制作人用,让他们能快速预览动画效果。这个工具确实挺实用的,我们也看到,一些早期用户已经开始这么用了。
但我们没料到的是,这玩意儿竟然成了表情包的热门工具。比如有个模板是小丑上台的场景,用户可以把视频里的小丑换成自己。我们发现几百万个角色在模仿和复现这个瞬间。
用起来也方便,你上传一张图片,几秒钟后就能出现在那个场景里。这种多样性挺有意思的。我们也希望 Viggle 能适应这种多样化的使用场景。
一些内容创作者也主动找我们,问能不能在 Viggle 上展示他们的舞蹈或者歌曲,还希望能和我们合作推广。这也很有意思。
现在,我们不仅限于上传视频来制作内容,还可以使用各种模板。你可以看到,我们这里有很多模板,包括一些有趣的舞蹈动作和体育赛事场景。
比如说,如果你想用某个模板,而且我们已经有了角色,你就可以用这个角色和模板来生成新的内容。即便你提供的只是正面视角的图像,我们的模型也会尽力生成一个 360 度全方位的人体视图。我们的创作者社区提供了许多优秀的模板,而真正的多样性来自于那些充满创意的想法。
对我们来说,最重要的是要支持这些创意社区,确保他们能够得到他们需要的工具,而且是最好用的工具。我们希望他们能够尽早体验到新功能,几乎是通过一种专属的渠道。我们基本上是在为创作者社区提供最有力的支持。
我们真的希望将这个角色模型应用到更多的生活场景、物体和场景中去。
在我看来,实现真实世界建模主要有两条路,一种是像素级的处理方法,Transformer 模型(Diffusion Models)在这方面做得相当好,但它有个问题,就是控制像素比较难。毕竟现实世界是三维的、物理的,像素并不是一个高效的表达方式,但它的优势是可以用任何视频来训练,生成各种内容。我们希望,当扩展到一定程度时,可控性会自然显现出来。但我们选择了另一条路径。
我们首先把生成的可控性做到像图形引擎那样精确,然后再从这个基础上进行扩展。所以我认为这两种路径的发展,以及它们最终如何融合成一种沉浸式体验,真的非常令人期待。
现在,Viggle 带来了一种全新的内容消费体验。对 AI 来说,通常就是如果你喜欢某个瞬间,你就会分享它。但在 Viggle,你可以和那个瞬间进行更深层次的互动。比如说,如果我特别喜欢某个时刻,我甚至可以把自己的虚拟形象放进去,体验一下那个场景。这就像是进入了一个平行宇宙,可以亲眼看到自己如何重新体验那个瞬间。这种全新的内容消费方式,不仅增加了娱乐性,还带来了更加个性化、定制化的体验。
如果你想让这些创作内容有真正的娱乐价值,那这个技术必须得表现得很好。所以对待这种搞笑的东西我们是认真的,会进行相当严格的研究。
参考资料:
https://techcrunch.com/2024/08/26/viggle-makes-controllable-ai-characters-for-memes-and-visualizing-ideas/
https://mp.weixin.qq.com/s/kHNmPYHNhhw5WngvzRcpgg
https://www.youtube.com/watch?v=IebslwhPzFo&t=2s
https://mp.weixin.qq.com/s/VGEcjWQ6pNPB1qO8eANtaA
文章来源“Founder Park”,作者“Founder Park”




【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
