# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
随着人工智能技术的不断进步和成熟,我们不难观察到,越来越多的社交媒体运营者开始倾向于采用AI技术来创作和分享内容。在韩国,AI主播的兴起甚至已成为一种现象。
Hedra AI的推出预示着我们即将迈入一个新时代,其中AI不仅能够担任主播的角色,甚至还能成为歌手。这一发展极大地降低了制作动画和塑造虚拟AI网红的门槛,使得普通大众也能够利用这些先进的AI工具,结合自己的创意,探索和开拓出更多前所未有的新机遇。
Sense 思考
我们尝试基于文章内容,提出更多发散性的推演和深思,欢迎交流。
- 降低使用门槛是未来人物角色视频生成AI的大趋势:在短视频和自媒体流行的当下,人们有创作视频的自由,但并非所有人都具备制作视频和虚拟形象的技能,这造成了一个巨大的市场需求。AI工具的出现,通过简单的图片和音频输入就能生成虚拟角色视频,大大降低了制作难度,因此吸引了大量用户。
本篇正文共4378字,仔细阅读约 13 分钟
AI Native 产品分析
59
Hedra

1. 产品:Hedra
2. 产品上线时间:2023 年
3.创始人:

Alex Bergman(左)
首席技术官,斯坦福大学博士,研究领域包括计算成像、计算机视觉、计算机图形学和机器学习。Alex Bergman发表或参与发表了数量颇丰的论文。
Michael Lingelbach(右)
首席执行官,斯坦福大学博士,从事空间智能研究
4. 产品简介:
Hedra 是由原斯坦福大学的研究团队成立的数字创作实验室推出的一个AI对口型视频生成工具,专注于将人工智能技术应用于人物角色视频的生成,旨在从简单的文本和图片中创建逼真的说话和唱歌视频。
5. 融资情况:
2024年8月,获得 Index Ventures、Abstract和A16Z Speedrun领投的1000万美元种子资金支持。
对于一家在新兴视频生成领域的公司来说,这笔投资相对较小,该领域有许多资金充裕的竞争对手,如Runway(筹集了2.37亿美元)、Pica(8000万美元)、Luma(7000万美元)、HeyGen(6000万美元)、Haiper(1920万美元),以及即Sora(来自OpenAI)和Google的Veo,来自中国的竞争者Kling也刚刚对国际用户开放。
01.
创立愿景:让生成视频工作流为创作赋能
Lingelbach 和 Bergman 在斯坦福大学攻读博士学位期间相识,后来一起在 NVIDIA、Google 和 Meta 工作,他们看到了人工智能崛起中的一个巨大机会。
这两位创始人表示,他们设想了一个利用生成视频工作流程来赋能创作者和企业的平台。多亏了投资者的支持和他们敬业团队的辛勤工作,这一愿景现在更接近现实。
他们的数据充分显示了 Hedra 技术在早期阶段引起的广泛兴趣。自 6 月发布以来,已有超过 35 万用户在该平台上生成了超过 160 万部视频。Hedra 表示,他们见证了从戏剧性独白到 AI 流行歌星,甚至是教师创作的教育内容等各种形式的视频。
Hedra 表示,他们非常重视负责任的部署,并内置了审核过滤器,以筛查暴力、仇恨言论和未经授权使用名人图片的内容。这是一种针对AI生成内容的伦理问题的积极应对方式。
这家初创公司计划创建一个多模态工作室,将故事、声音和视频生成整合到一个统一的工作流程中。这将允许用户创建具有独特外貌、声音和个性的可定制数字化身。Hedra 目前已经获得了一些知名投资者的支持,包括 Index Ventures、Abstract 和 Andreessen Horowitz 的 Speedrun 计划。
02.
旗舰产品Character-1
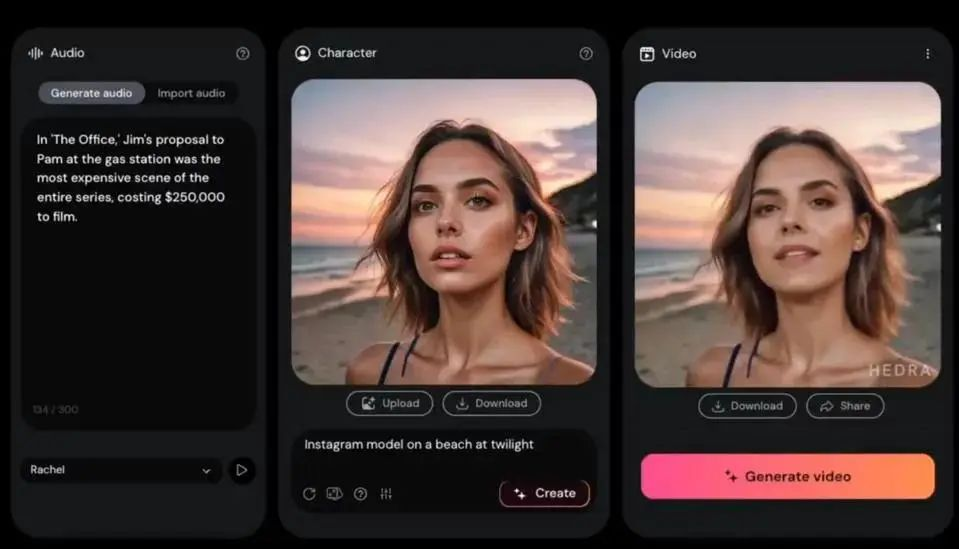
(Hedra 界面)
Hedra的旗舰产品是一个视频基础模型,它的核心功能之一是能够将用户的文本和图片输入转化为动态视频。
Character-1 擅长创造高度富有表现力的角色。用户上传一张人物正脸的照片和相应的语音文件,模型会分析语音的节奏、音调和强度,然后相应地调整视频中人物的嘴型和表情,确保与输入的语音内容精确同步,包括基本的发音同步,以及更细微的表情变化,如微笑、皱眉、眨眼或惊讶,还有讲话、呼吸时颈部的变化,从而传达更丰富的情感和语境。这使得Hedra生成的视频看起来非常自然,使其能够成为各种多媒体项目的多功能工具。
另外值得注意的是, 它可以用于多种语言的内容制作,提高内容的传播效果,不过内置的声线预设用来说中文台词会出现很奇怪的口音,可选择的声线较少,还是比较推荐自己上传音频。
从一些官方在社交平台上给网友的回复中得知,模型主要测试了中文和英文输入,且中文表现还不错。
而经小编测试,上传的音频内的法语、德语的对口型表现也都相当不错:

(法语)

(英语)
Character-1不仅限于人脸,只要它们有清晰的嘴巴、鼻子和眼睛,它还可以动画化富有表现力的无生命物体(人类、动漫、动物、石像等),每个角色都可以具有独特的表情、动作和语音。
不过在五官不明确的情况下还是会出现一些奇怪的画面。鉴于网上可以找到很多真实人物的尝试案例,那么接下来就玩儿点“抽象”的:

(石头唱歌)
(文物唱歌)

(文物唱歌)
在效率上,Character-1的算法优化了视频生成的流程,使其因为视频生成速度和画面控制性而在众多同类型产品中脱颖而出,提高了制作效率:该模型每60秒实时处理生成90秒的视频,取决于Hedra的H100供应情况。这种效率提升对于有快速制作大量视频内容需求的用户来说非常有用。
另外,Character-1支持生成内容的无限时长,它使创作者能够制作以角色为中心的,更长、更复杂的视频内容。尽管在当前的免费试用版本中限制为30秒,当上传的音频超过30秒时会被系统裁剪,但这已经足够用于制作许多类型的短视频内容。
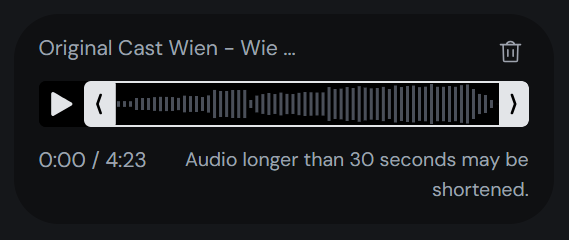
(时长限制)
03.
Hedra 实操:“黑手党与背叛”
Hedra的使用非常简单,主要分为两个部分:定义音频和定义角色,两个部分都提供了两种方式供用户选择。
定义音频:
定义你的角色:
外国博主Erik Knobl在Medium上发表了他测试Hedra的实操记录。他构思了一个黑手党对话的场景,其中一名参与者被指控为叛徒。先让ChatGPT生成一个对话大纲,然后加入自己的创意以保持每个角色的不同。然后,在Midjourney生成肖像,使用相同的sref(样式参考编号)3211368754生成了三张肖像,以保持相同的风格。



(相同的sref生成的三张肖像)
那么接下来看看用这三个人物形象生成的视频剪辑出来的成果:
可以看到,生成角色一致性的特点在这个案例中表现的尤为明显。在生成相同人物的不同视频片段时,该模型都能确保动画人物在整个视频中保持其身份和表情特征,无论是微妙的眼部动作,还是唇角的轻微变化。Hedra的这种能力,让视频内容的叙事更加引人入胜,为观众提供了一种全新的沉浸式体验。
此外,Hedra在对视频整体风格的把控上,无论是色彩的运用,光影的效果,还是场景的转换,都能够保持一种连贯性。这种对一致性的追求,不仅提升了视频的艺术价值,也极大地增强了其传播效果,使得视频内容能够在观众心中留下深刻的印象。
04.
欢迎进入数字人时代

当下还有不少和Hedra类似的AI视频生成工具,能够通过各种不同的输入方式,最终能够生成一段人物的嘴型、动作、表情与人物台词契合的视频,从广义上来看,可以把这些生成的人物叫做“数字人”。不同的AI工具可以用不同的方式生成不同类型的数字人:
(HeyGen)
(曦灵)
(MetaHuman)
这些AI工具使视频制作更容易更高效,允许编辑技能有限的人轻松创作视频。它们对快速内容创建十分有帮助,减轻了用户掌握复杂软件或聘请专业动画师的负担,节省时间和资源,使个人能够专注于培养创造力。目前已经可以看到这类工具在多个领域的应用潜力:


在社交媒体上:这类AI将照片转化为对话视频的能力, 使各个博主、up主还有其它内容创作者能够快速轻松地制作引人入胜的视频内容,对用户互动和内容创作有深远的影响;
电影和娱乐行业:通过使用这类AI可以生成动画和栩栩如生的角色,电影制作者可以提高制作效率和创造力,无论是用于特效还是沉浸式游戏体验,这类AI工具都为故事叙述和观众参与引入了新维度。
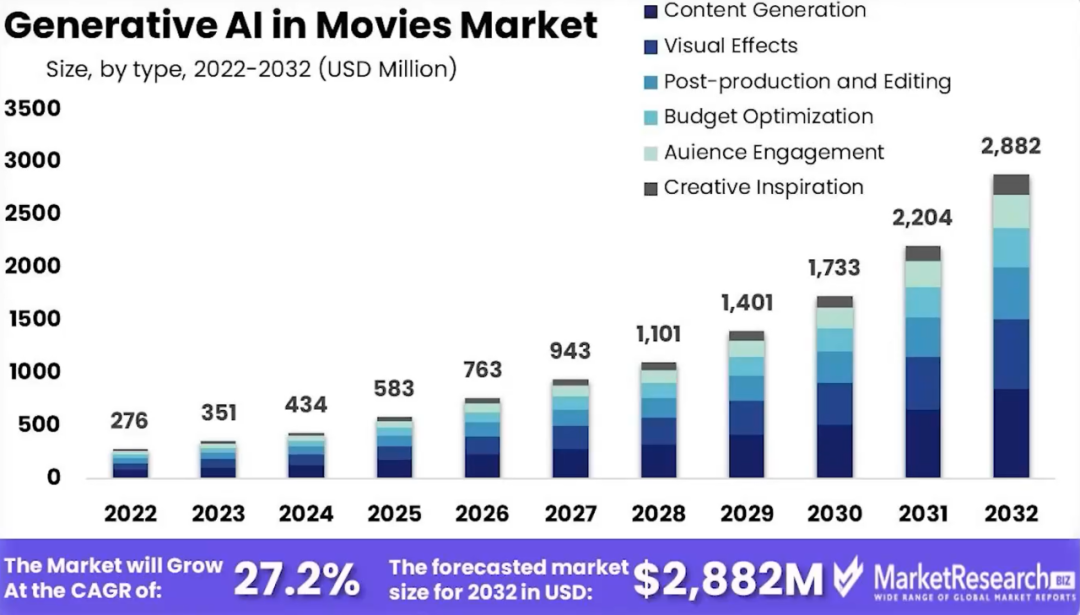
(影视行业的AI应用)
在广泛运用这类AI工具的同时,也要对这些工具带来的风险和挑战有所警惕:


(Deep Fake)
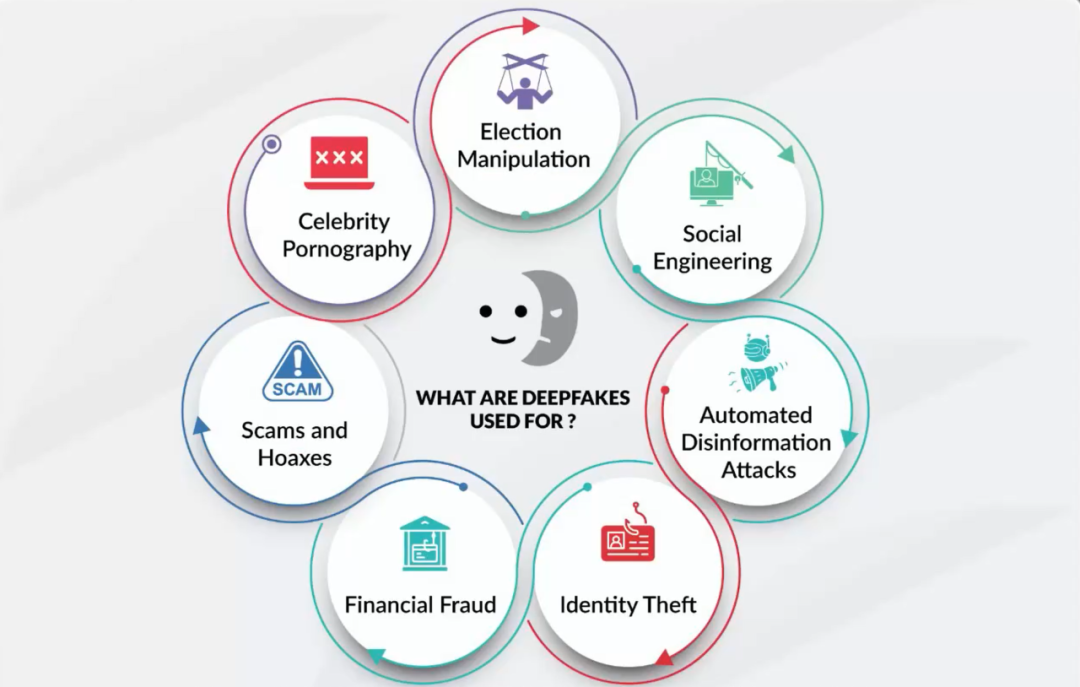
(Deep Fake常见情况)
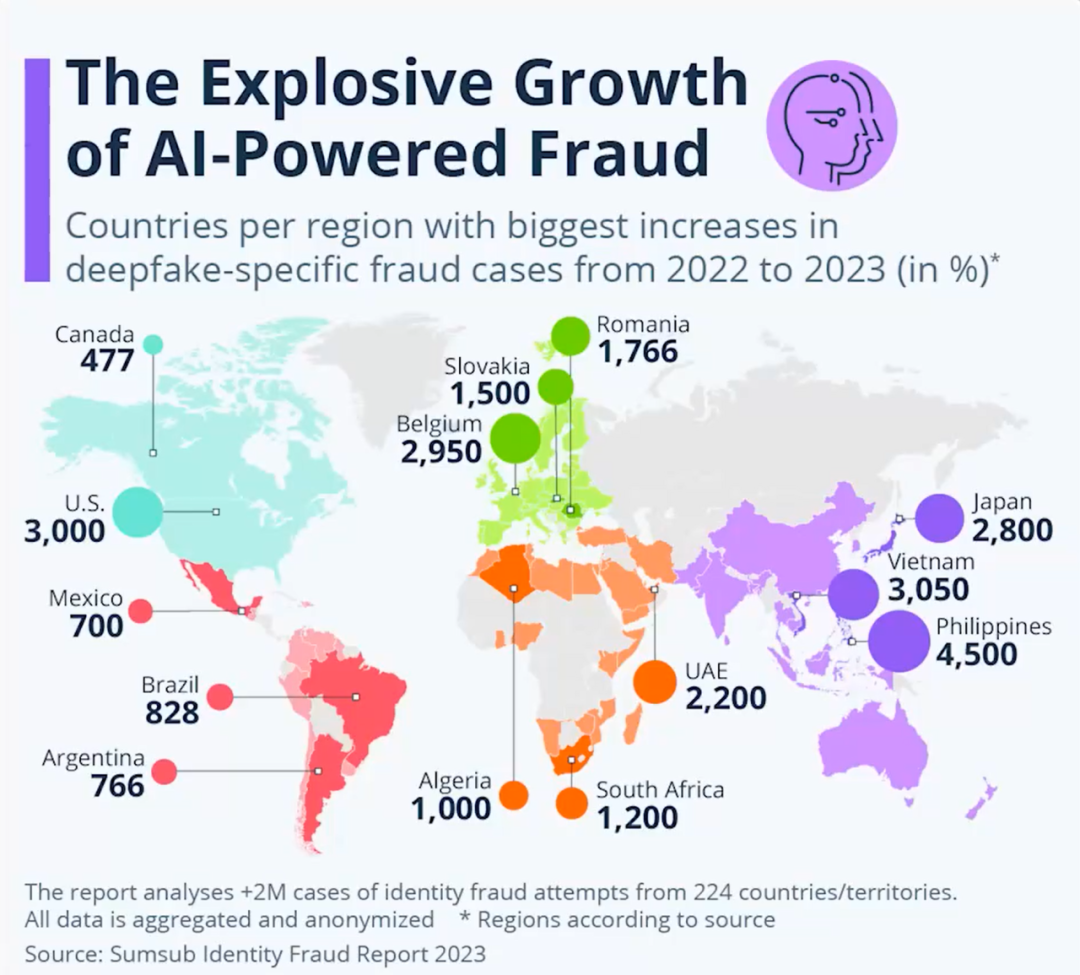
(AI诈骗发生数量)
所幸,针对AI生成内容的识别技术也正在紧锣密鼓地研究推进中,相信在不久的将来,我们就可以更安全、更有保障的去使用这些便利的AI工具了。
文章来源于“深思 SenseAI”,作者“ SenseAI”




【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】Fay开源数字人框架是一个AI数字人项目,该项目可以帮你实现“线上线下的数字人销售员”,
“一个人机交互的数字人助理”或者是一个一个可以自主决策、主动联系管理员的智能体数字人。
项目地址:https://github.com/xszyou/Fay
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
