# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
世界上第一个完全由神经模型驱动的游戏引擎,刚刚诞生了!
「黑神话:悟空」的热度正旺,AI又在游戏中创造了全新的里程碑。
史上首次,AI能在没有游戏引擎的情况下,为玩家生成实时游戏了。
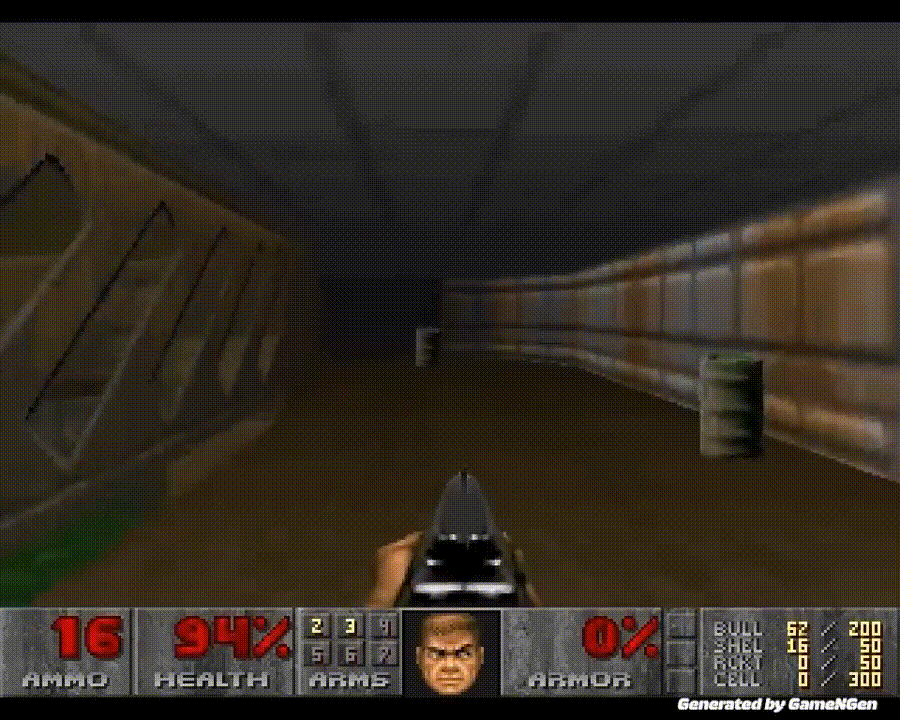
从此,我们开始进入一个炸裂的新时代:游戏不仅能被AI玩,还能由AI来创造和驱动。
谷歌的GameNGen,可以在单个TPU上,让AI以每秒20帧的速度,生成实时可玩的游戏。每一帧,都是由扩散模型预测的。

几年后,AI实时生成3A游戏大作的愿望还会远吗?
从此,开发者不必再手动编程游戏逻辑,开发时间和成本都会显著降低。
价值2000亿美元的全球游戏产业,可能会被彻底颠覆!
谷歌研究者表示,GameNGen是第一个完全由神经模型驱动的游戏引擎,能够在复杂环境中,实现高质量的长轨迹实时交互。

论文地址:https://arxiv.org/abs/2408.14837
不仅速度是实时的,它的优秀画质,也是让开发者颤抖的地步。
模拟「毁灭战士」时,它下一帧预测的峰值信噪比(PSNR)达到了29.4,已经可以和有损JPEG压缩相媲美。
在神经网络上实时运行时,视觉质量已经达到了与原始游戏相当。
模拟片段和游戏片段如此相似,让不少人类被试都分不清,眼前的究竟是游戏还是模拟?

网友感慨:这不是游戏,这是人生模拟器。
小岛秀夫的另一个预言,成真了。
3A电视剧是不是也来了?想象下,按照自己的喜好生成一版《权游》。
想象下,1000年后或一百万年后,这项技术是什么样?我们是模拟的概率,已经无限接近于1了。

从此,游戏开发不再需要游戏引擎?
AI首次完全模拟具有高质量图形和复杂交互的复杂视频游戏,就做到了这个地步,实在是太令人惊叹了。
作为最受欢迎、最具传奇色彩的第一人称射击游戏,自1993年发布以来,「毁灭战士」一直是个技术标杆。
它被移植到一系列超乎想象的平台上,包括微波炉、数码相机、洗衣机、保时捷等等。

而这次,GameNGen把这些早期改编一举超越了。
从前,传统的游戏引擎依赖的是精心编码的软件,来管理游戏状态和渲染视觉效果。
而GameNGen,只用AI驱动的生成扩散模型,就能自动模拟整个游戏环境了。
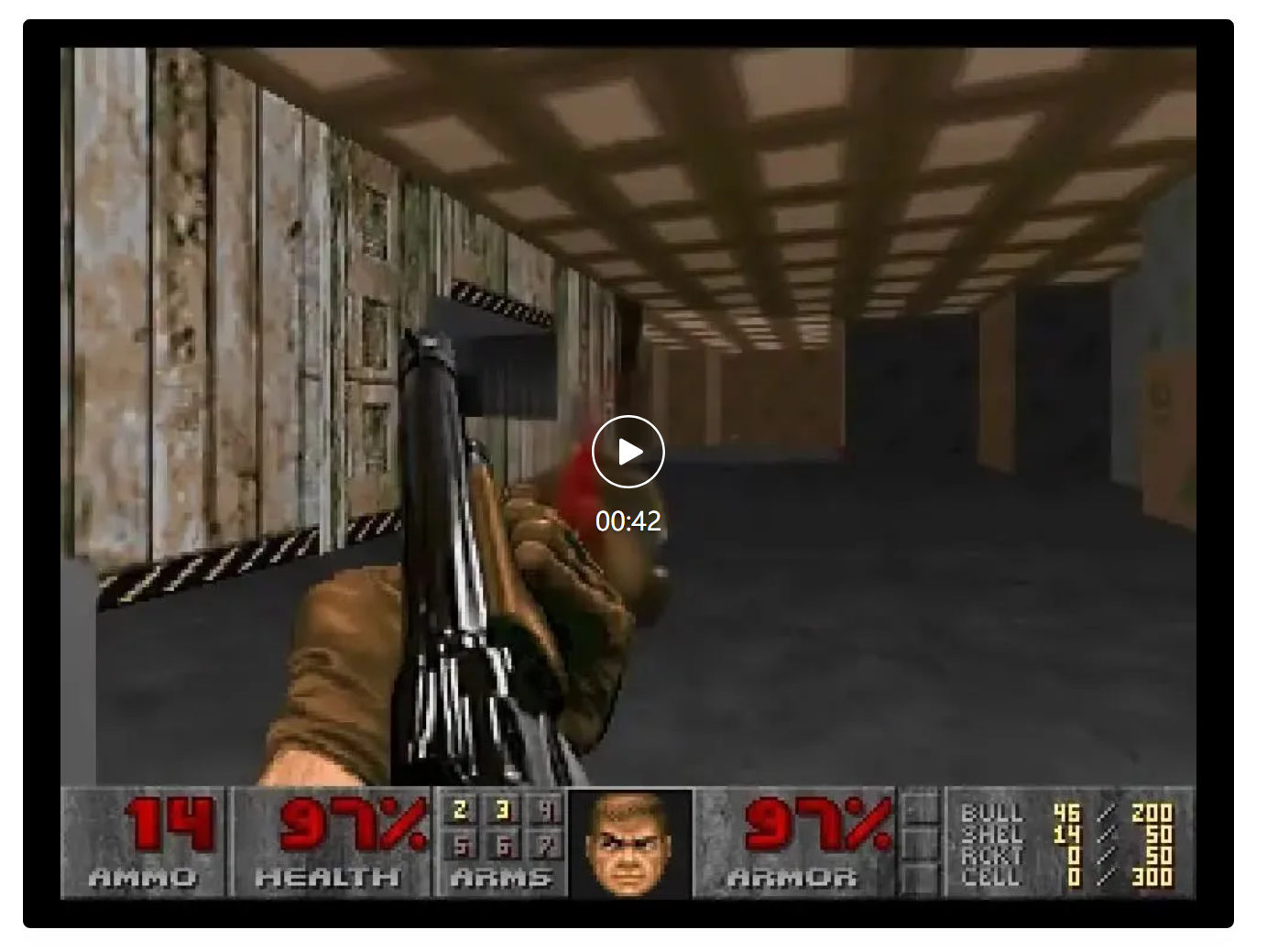
从视频中可以看出,神经网络复现游戏标志性视觉效果的能力简直是一绝,AI实时生成复杂交互环境的潜力非常惊人
「毁灭战士」一直以复杂的3D环境和快节奏的动作闻名,现在,所有这些都不需要游戏引擎的常用组件了!
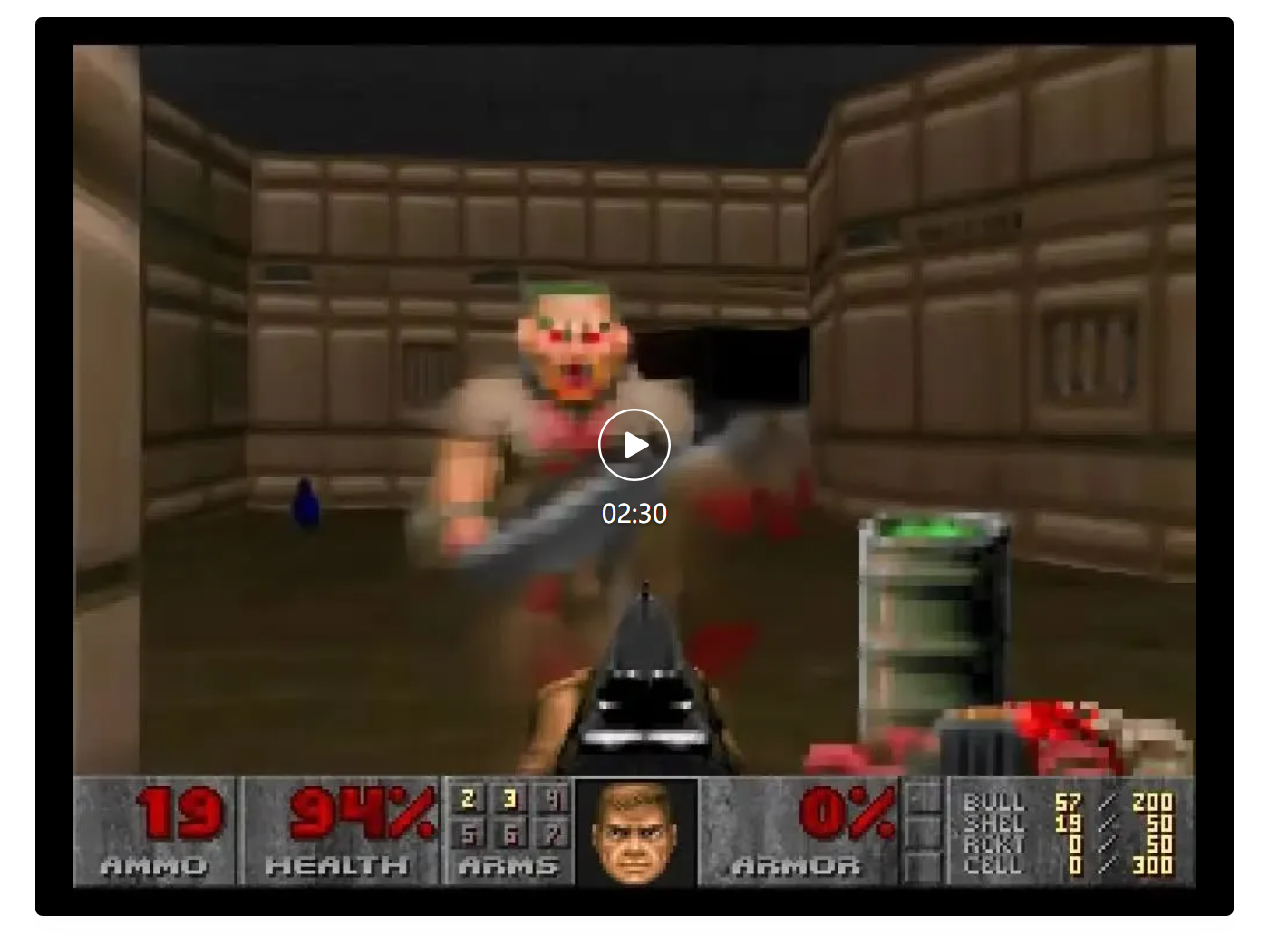
AI引擎的意义,不仅仅是减少游戏的开发时间和成本。
这种技术,可以使游戏创作彻底民主化,无论是小型工作室,还是个人创作者,都能创造出从前难以想象的复杂互动体验。
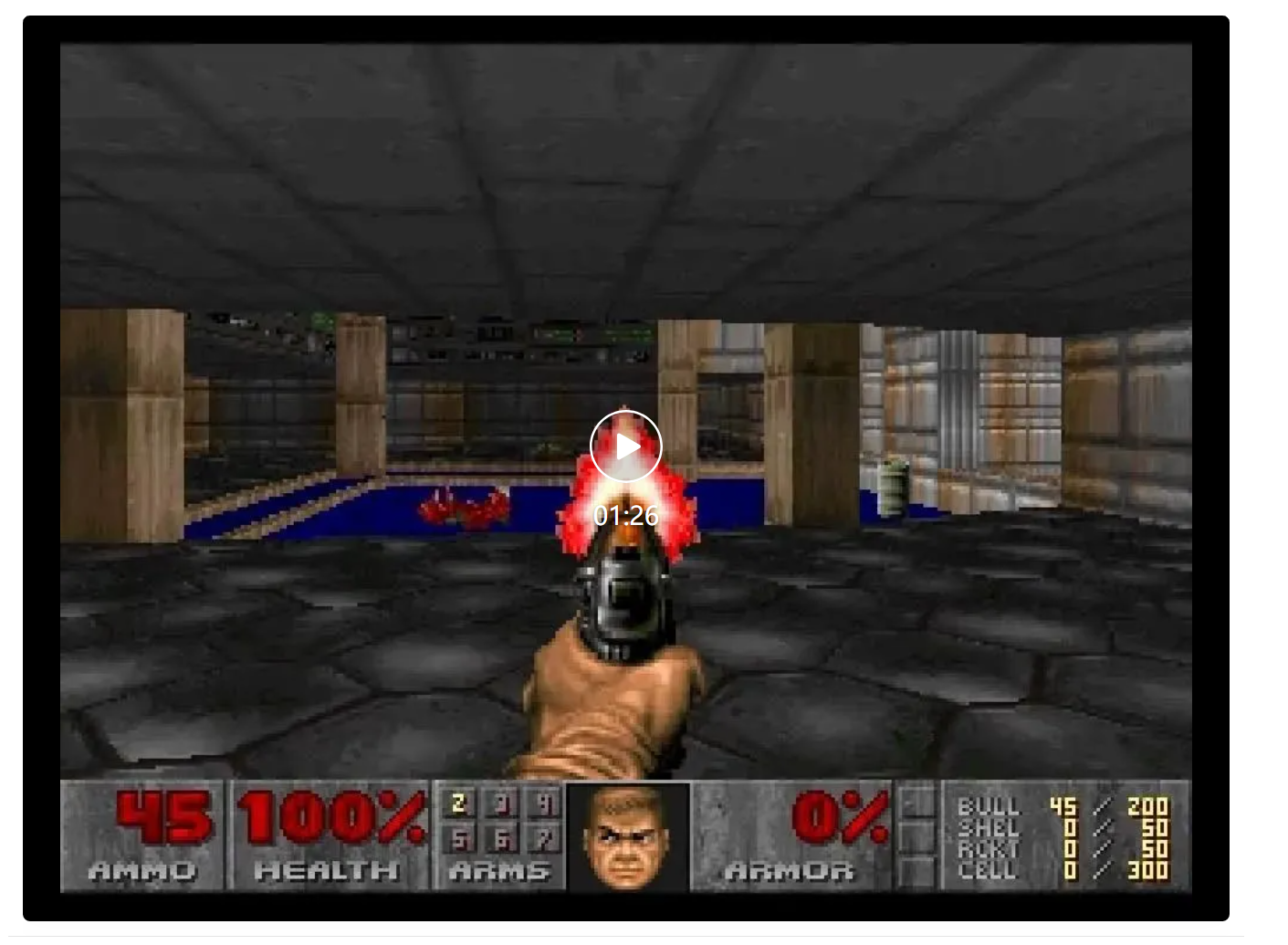
此外,AI游戏引擎,还给全新的游戏类型打开了大门。
无论是环境、叙事,还是游戏机制,都可以根据玩家的行为动态来发展。
从此,游戏格局可能会被整个重塑,行业会从热门游戏为中心的模式,转向更多样化的生态系统。
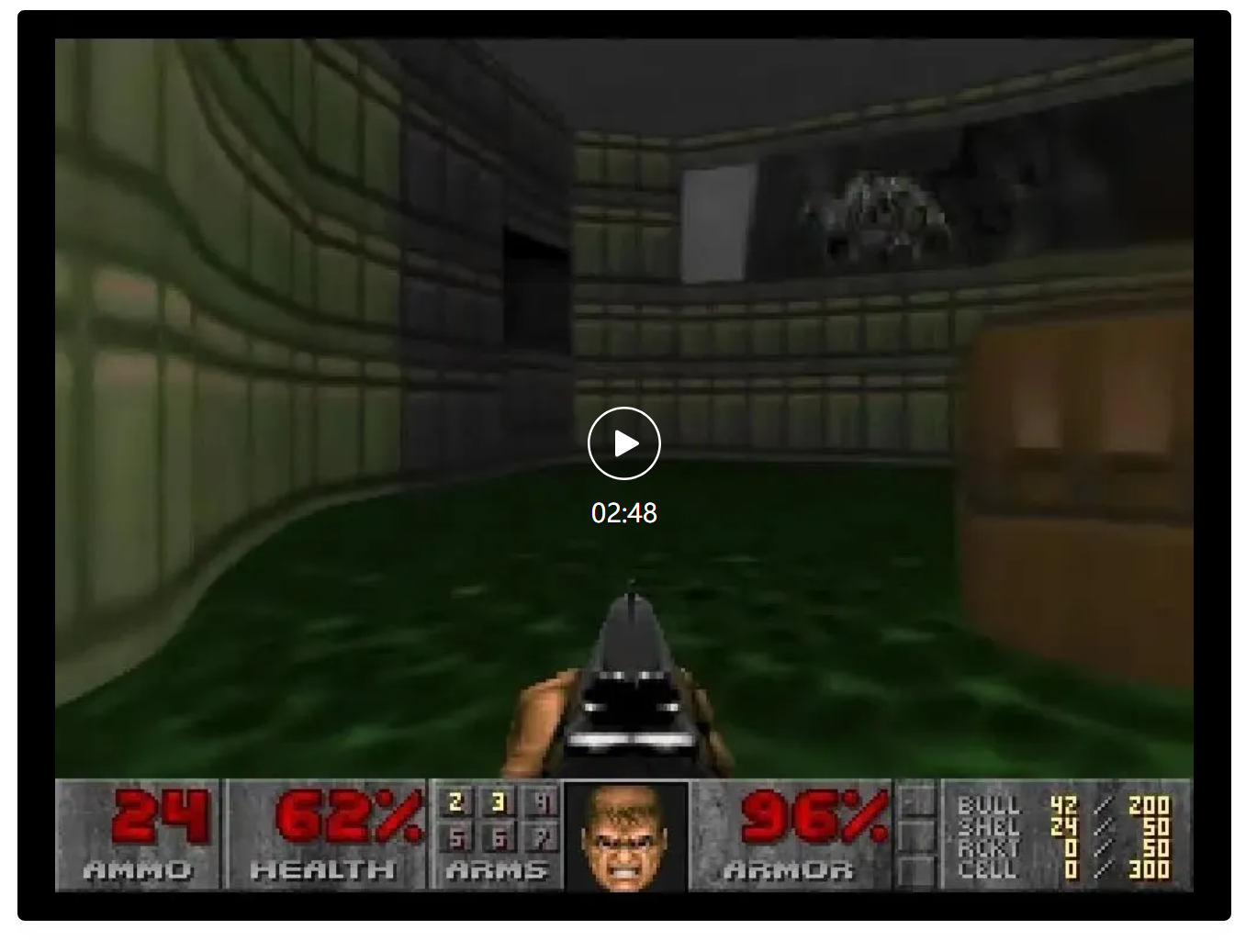
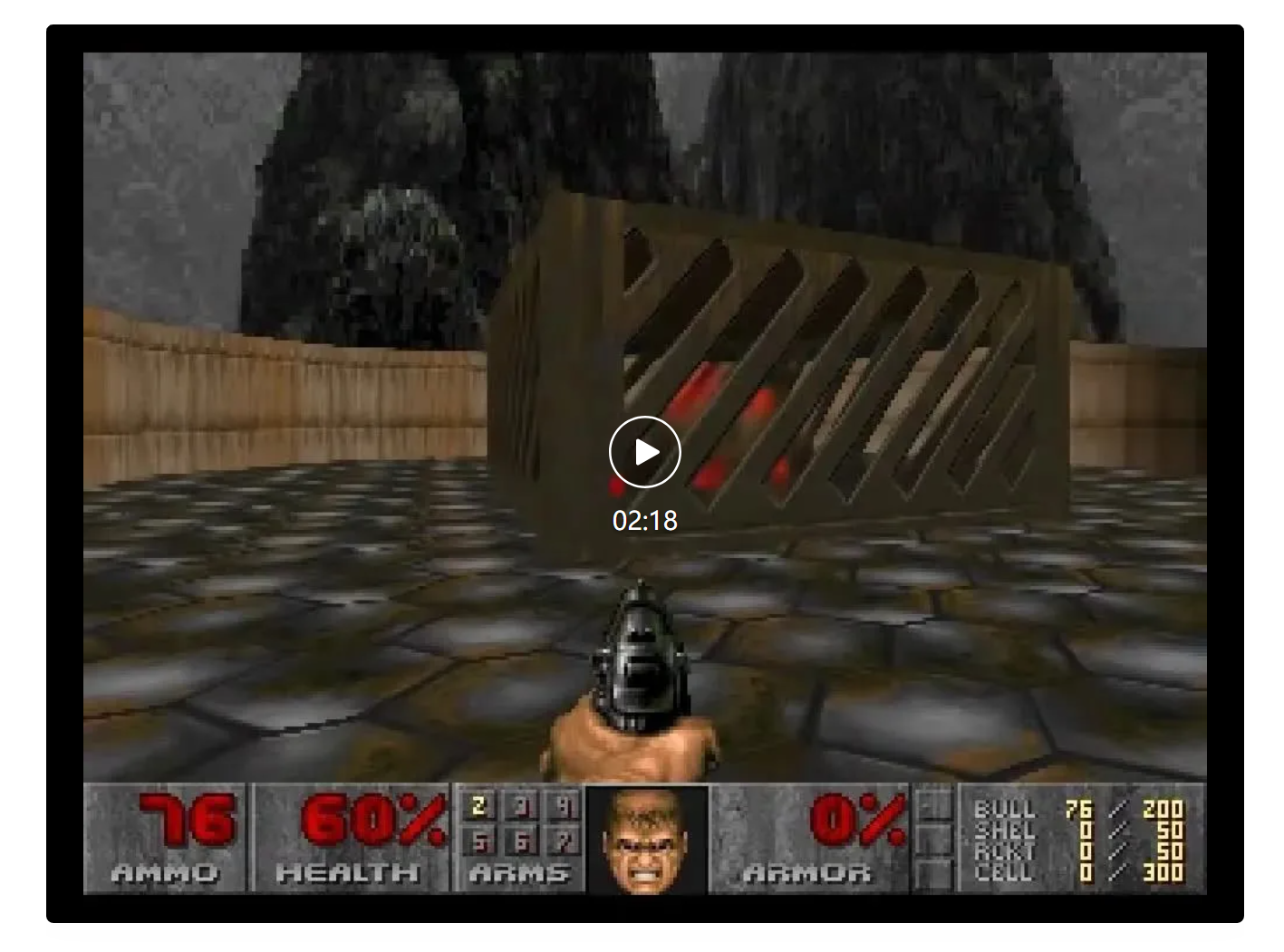
顺便一提,「DOOM」的大小只有12MB。

大佬们「疯了」
AI初创HyperWrite的CEO Matt Schumer表示,这简直太疯狂了!用户玩游戏时,一个模型正在实时生成游戏。
如果将大多数AI模型的进展/轨迹映射到这上面,那么在几年内,我们将会得到3A级生成游戏。

英伟达高级科学家Jim Fan感慨道,被黑客们在各种地方疯狂运行的DOOM,竟然在纯粹的扩散模型中实现了,每个像素都是生成的。
连Sora跟它比起来,都黯然失色。我们只能设定初始条件(一个文本或初始帧),然后只能被动观看模拟过程。
因为Sora无法进行交互,因此还不算是一个「数据驱动的物理引擎」。
而GameNGen是一个真正的神经世界模型。它将过去的帧(状态)和用户的一个动作(键盘/鼠标)作为输入,并输出下一帧。这种质量,是他见过的最令人印象深刻的DOOM。
随后,他深度探讨了一些GameNGen中存在的限制。
比如在单个游戏上过拟合到了极致;无法想象新的场景,无法合成新的游戏或交互机制;数据集的瓶颈,导致了方法无法推广;无法实现用提示词创造可玩世界,或用世界模型训练更好的具身AI,等等。

一个真正有用的神经世界模型,应该是什么样子?
马斯克的回答是:「特斯拉可以用真实世界的视频做类似的事情」。
的确,数据是难点。
Autopilot团队可能拥有数万亿的数据对(摄像头视频,方向盘动作)。
有了如此丰富的真实世界数据,完全有可能训练一个涵盖各种极端情况的通用驾驶模拟器,并使用它来部署和验证新的完全自动驾驶(FSD)版本,而不需要实体车辆。

最后Jim Fan总结道:不管怎么说,GameNGen仍是一个非常出色的概念验证——至少我们现在知道,9亿帧是将高分辨率DOOM压缩到神经网络中的上限。
网友们感慨:扩散网络学习物理引擎和游戏规则的方式,太疯狂了。
核心作者:个人里程碑
谷歌DeepMind核心贡献者,项目负责人Shlomi Fruchter,在社交媒体上,介绍了自己开发GameNGen的过程。

他表示,「GameNGen是自己开发路上的里程碑」。
从最初手写GPU渲染代码(显式),到现在训练能在GPU上运行的神经网络(隐式),甚至包含了游戏逻辑,让我有一种实现了完整「闭环」的感觉。
Fruchter进行的第一个大型编码项目之一是3D引擎(如下图所示)。早在2002年,GPU仍只能用于渲染图形。
还记得,第一款图形处理器GeForce 256是在1999年发行。
渲染3D图形恰好需要大量的矩阵运算,这恰恰是GPU所擅长的。
然后谷歌研究人员编写高级着色器语言代码,计算自定义渲染逻辑并构建新的视觉效果,同时还能保持高帧率。

GameNGen的诞生,是源于一个好奇心:
「我们能否在当前的处理器上,运行一个隐式神经网络,来进行实时互动游戏」。
对于Fruchter以及团队成员来说,最终答案是一个令人兴奋的发现。
AI大牛Karpathy曾说过,100%纯软件2.0计算机,只有一个神经网络,完全没有传统软件。
设备输入(音频、视频、触摸等)直接到神经网络中,其输出直接作为音频/视频在扬声器/屏幕上显示,就是这样。
有网友便问道,那就是它不能运行DOOM了?
对此,Karpathy表示,如果能够很好提出请求,它可能可以非常接近地模拟DOOM。
而现在,Fruchter更加肯定,它可以运行DOOM了。

另一位谷歌作者Dani Valevski也转发了此帖,对此愿景表示极度认可。

GameNGen或许标志着游戏引擎全新范式的开启,想象一下,和自动生成的图像或视频一样,游戏也是自动生成的。
虽然关键问题依旧存在,比如如何训练、如何最大程度利用人类输入,以及怎样利用神经游戏引擎创建全新的游戏。但作者表示,这种全新范式的可能性让人兴奋。
而且,GameNGen的名字也暗藏彩蛋,可以读出来试一试——和Game Engine有相似的发音。
Agent采集轨迹,SD预测生成
在手动制作计算机游戏的时代,工作流程包括(1)收集用户输入(2)更新游戏状态,以及(3)将更新后的状态渲染为屏幕像素,计算量取决于帧率。
尽管极客工程师们手中的Doom可以在ipod、相机,甚至微波炉、跑步机等各种硬件上运行,但其原理依旧是原样模拟模拟手动编写的游戏软件。
看起来截然不同的游戏引擎,也遵循着相同的底层逻辑——工程师们手动编程,指定游戏状态的更新规则和渲染逻辑。
如果和扩散模型的实时视频生成放在一起,乍一看好像没什么区别。然而,正如Jim Fan指出的交互式世界模拟不仅仅是非常快速的视频生成。
其一,生成过程需要以用户的输入动作流为条件,这打破了现有扩散模型架构的一些假设。
其二,模型需要自回归生成帧,这往往会导致采样发散、模型不稳定等问题。

由于无法直接对游戏数据进行大规模采样,因此首先教会一个agent玩游戏,在各种场景中生成类似于人类且足够多样化的训练数据。
agent模型使用深度强化学习方法进行PPO训练,以简单的CNN作为特征网络,共生成900M帧的????_agent数据集,包括agent的动作以及对环境的观察,用于后续的训练 、推理和微调。

GameNGen使用的Stable Diffusion 1.4是文生图扩散模型,其中最重要的架构修改就是,让以文本为条件的模型适应数据集中的动作数据a_{<n}和对先前帧的观察结果o_{<n}。
具体来说,首先训练一个嵌入模块A_emb,将agent的每个动作(例如特定的按键)转换为单个token,并将交叉注意力中的文本替换为编码后的动作序列。
为了能接受o_{<n}作为条件,同样使用自动编码器ϕ将其编码到潜在空间中(即x_t),同时在潜在的通道维度上与噪声隐变量ε_α拼接在一起。
实验中也尝试过用交叉注意力处理o_{<n}输入,但并没有明显改进。
相比原来的Stable Diffusion,GameNGen对优化方法也做了改进,使用velocity parameterization方法最小化扩散损失。
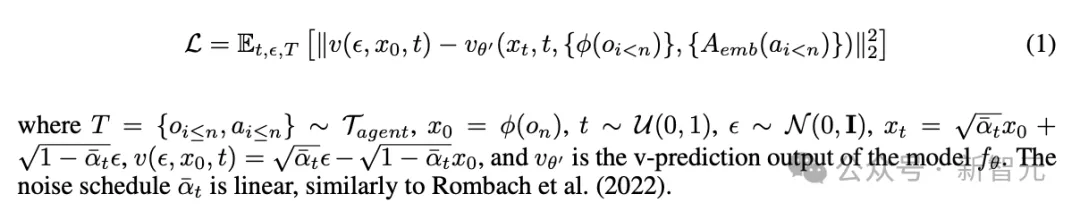
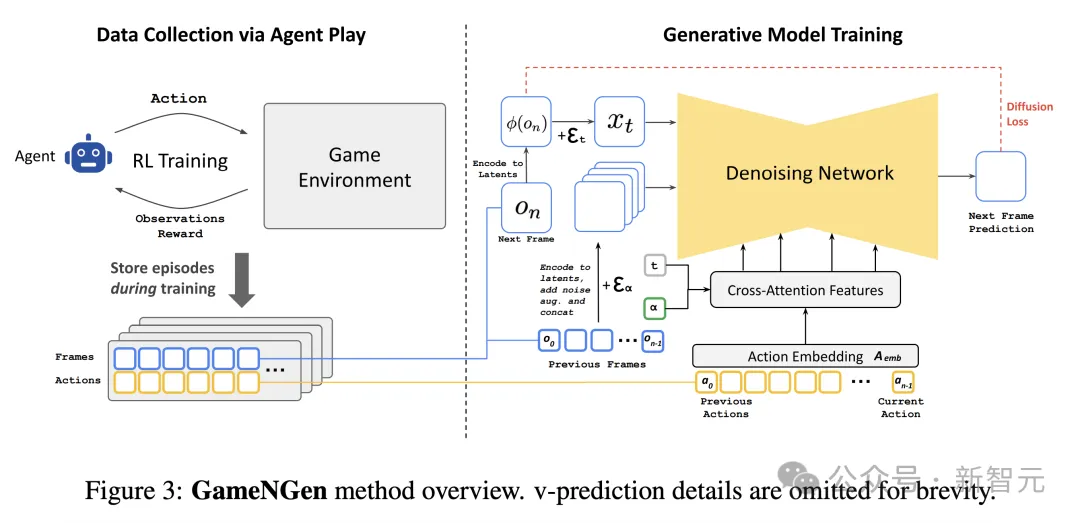
GameNGen方法概述(省略v-prediction细节)
从原Stable Diffusion的教师强制训练转换为游戏引擎中的自回归采样,会不可避免地导致错误累积和样本质量快速下降。
为了避免这个问题,训练生成模型时会在编码过的上下文帧中添加不同数量的高斯噪声,同时将噪声水平作为模型的输入,从而让降噪网络可以纠正先前帧中采样的信息。
这些操作对于随着时间推移时保证帧质量至关重要。在推理过程中,也可以控制添加的噪声水平以最大限度地提高生成质量。

自回归漂移:上图中, 20-30个步骤后,生成质量会快速下降;而下图中,具有噪声增强的相同轨迹不会出现质量下降
模型在推理时使用DDIM采样方法。之所以能达到20FPS的实时生成效率,与GameNGen推理期极高的采样效率直接相关。
通常,生成扩散模型(例如Stable Diffusion)无法只用单个去噪步骤产生高质量结果,而是需要数十个采样步骤。
但令人惊讶的是,GameNGen只需4个DDIM采样步骤就能稳健地模拟 DOOM,而且相比使用20个或更多采样步骤时,质量并没有明显下降。
作者推测,这可能源于多个因素的共同作用,包括可采样的图像空间受限,以及通过先前帧信息施加了较强的条件限制。
仅使用4个降噪步骤让U-Net的推理成本降低至40ms,加上自动编码器,总推理成本为50ms,相当于每秒生成20帧图像。
实验还发现,模型蒸馏后进行单步采样能够进一步提高帧率,达到50FPS,但会以牺牲模拟质量为代价,因此最后还是选用了20FPS的采样方案。
AI游戏生成太逼真,60%片段玩家没认出
总的来说,就图像质量而言,GameNGen在长时间轨迹上预测,达到了与原始游戏相当的模拟质量。
对于短时间轨迹,人评估者在模拟片段和真实游戏画面中,进行区分时,比随机猜测略强一些。
这意味着什么?
AI生成的游戏画面,太过逼真沉浸,让人类玩家有时根本无法辨别。
图像质量
这里,评估中采用了LPIPS和PSNR作为评估指标。这是在强制教学设置下进行测量,即基于真实过去观察预测单个帧。
对5个不同关卡中,随机抽取的2048个轨迹进行评估时,GameNGen达到了29.43的PSNR和0.249的LPIPS。
下图5展示了,模型预测和相应的真实样本示例。

视频质量
针对视频质量,研究人员使用了自回归设置,即模型基于自己的过去预测来生成后续帧。
不过,预测和真实轨迹在几步后会发生偏离,主要是由于帧间移动速度的微小差异累积。
如下图6所示,随着时间推移,每帧的PSNR值下降,LPIPS值上升。
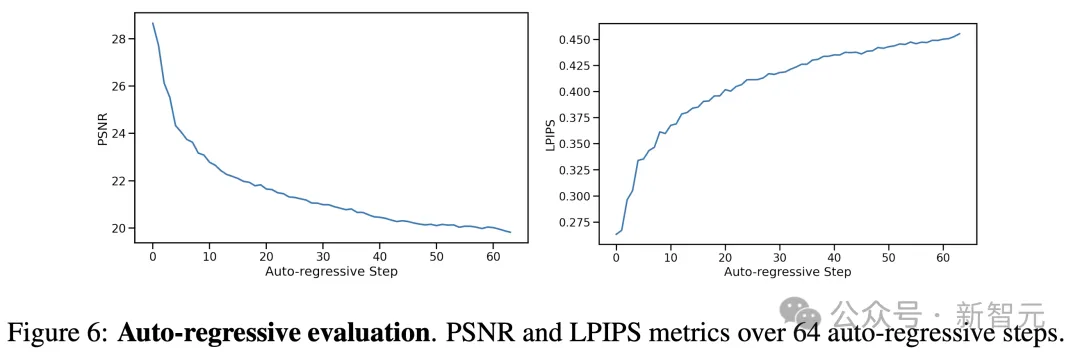
预测轨迹在内容和图像质量方面,仍与实际游戏相似,但逐帧指标在捕捉这一点上,能力有限。
因此,研究团队测量了在512个随机保留轨迹上,计算的FVD(用于测量预测和真实轨迹分布之间的距离)。
这里,分别对16帧(0.8秒)和32帧(1.6秒)两种模拟长度,进行了测试。
最终,得到的FVD分别是114.02,以及186.23。
人工评估
为了得到更真实的评估,研究者向10名人类评分者,提供了130个随机短片段(长度为1.6秒和3.2秒)。
并且,将GameNGen模拟的游戏和真实游戏并排对比,如下所示。

评估者的任务,便是识别其中,哪一个是真实游戏。
结果发现,针对1.6秒生成游戏的片段,在58%情况下,他们认为GameNGen生成游戏是真实的。
而对于3.2秒片段,这一比率更高,达到了60%。
接下来,研究者评估了架构中,不同组件的重要性,从评估数据集中采样轨迹,并计算地面真值与预测帧之间的LPIPS和PSNR指标。
上下文
通过训练N∈{1, 2, 4, 8, 16, 32, 64}模型,测试上下文中过去观察数量N的影响。(标准模型使用了N=64)。
这影响了历史帧和动作的数量。
保持解码器冻结情况下,训练模型200,000步,并在5个关卡的测试集轨迹上进行评估。
结果如下表1所示,如预期一样,研究者观察到GameNGen生成质量,随着上下文增加,而提升。
更有趣的是,在1帧和2帧之间,这一改进非常大,但往后开始很快接近了阈值线,改进质量逐渐放缓。
即便用上了最大上下文(64帧),GameNGen模型也仅能访问,略超过3秒的历史信息。
另一个发现是,大部分游戏状态可能会持续更长时间。
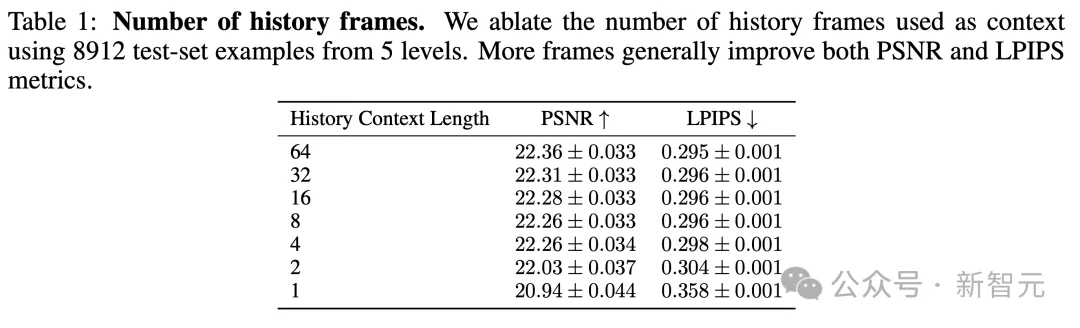
表1结果很好地说明了,未来可能需要改变模型架构,来支持更长的上下文。同时,探索更好的方法,采用过去帧作为条件。
噪声增强
为了消除噪声增强的影响,研究人员还训练了一个没有添加噪声的模型。
通过对比评估,经过噪声增强的标准模型和没有添加噪声的模型(在200k训练步骤后),以自回归方式计算预测帧与真实帧之间的PSNR和LPIPS指标。
如下图7所示,呈现了每个自回归步骤的平均指标值,总共达64帧。
这些评估是在随机保留的512条轨迹上进行的。
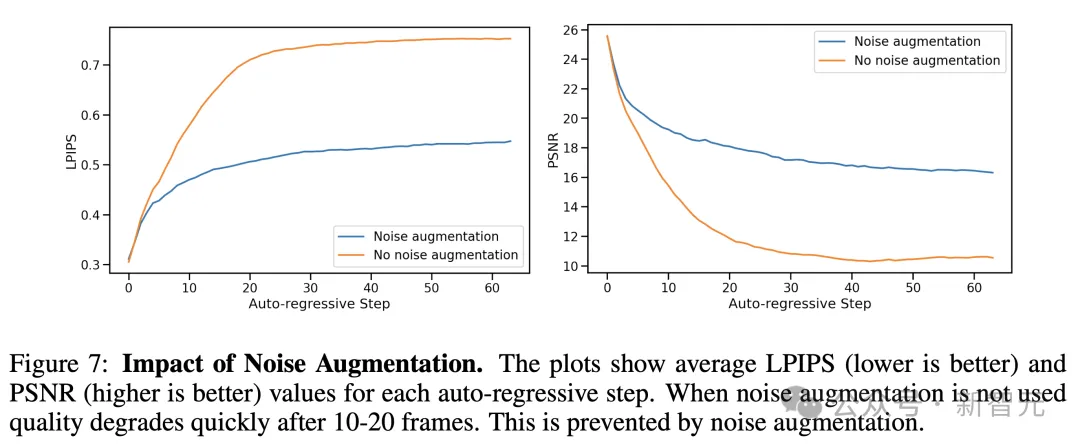
结果显示,没有噪声增强时,与真实值的LPIPS距离,比起研究标准噪声增强模型增加得更快,而PSNR下降,表明模拟与真实值的偏离。
智能体
最后,研究人员将智能体生成的数据训练,与使用随机策略生成的数据训练,进行了比较。
这里,通过训练两个模型,以及解码器,每个模型训练700k步。
它们在一个由5个关卡组成的2048条人类游戏轨迹的数据集上,进行评估。
而且,研究人员比较了在64帧真实历史上下文条件下,生成的第一帧,以及经过3秒自回归生成后的帧。
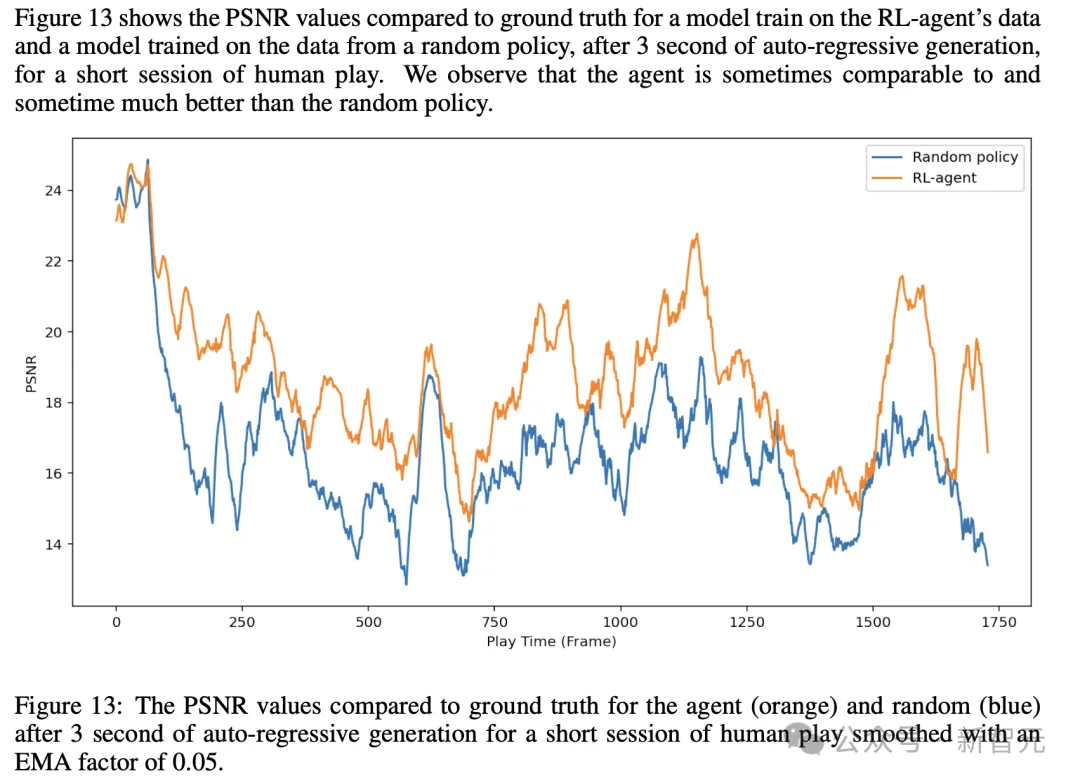
总得来说,研究观察到,在随机轨迹上训练模型效果出乎意料地好,但受限于随机策略的探索能力。
而在比较单帧生成时,智能体仅略胜一筹,达到25.06 PNSR,而随机策略为24.42。
而在比较3秒情况下,差异增加到19.02 Vs 16.84。
在手动操作模型时,他们还观察到,某些区域对两者都非常容易,某些区域对两者都非常困难,而在某些区域智能体表现更好。
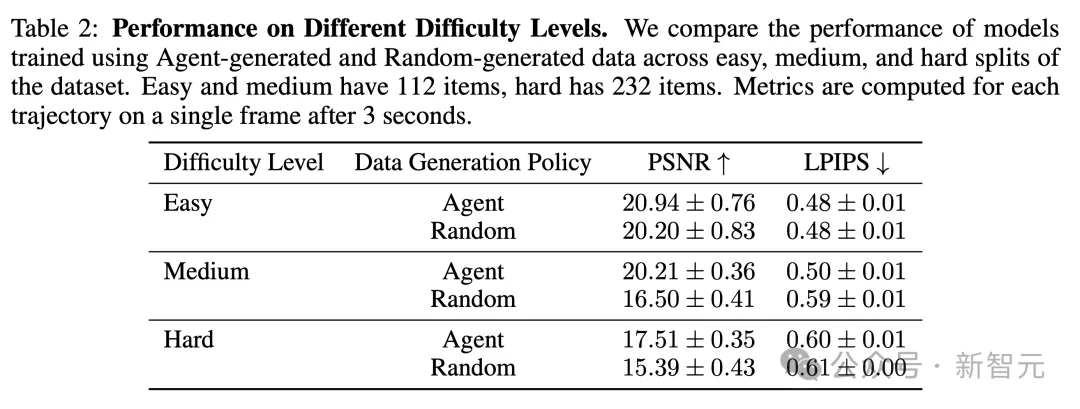
因此,作者根据其在游戏中与起始位置的距离,将456个示例手动分为三个级别:简单、中等和困难。
如下表2所示,结果观察到,在简单和困难集合中,智能体仅略优于随机,而在中等集合中,智能体的优势如预期般更大。
0代码生成游戏,老黄预言成真
今天,视频游戏,是由人类编程的。
GameNGen的诞生,开启了实时互动视频游戏的全新范式。
在这一范式中,游戏是神经模型的「权重」,而非代码行。
如今看来,老黄的预言近在眼前。

每个像素很快都将会是生成的,并非是渲染的。
在今年GTC大会的记者会上,Bilawal Sidhu就老黄的话,提出了一个后续问题:「我们距每个像素都是以实时帧速率生成的世界还有多远」?
老黄表示,我们还需要5-8年的时间,并且现已看到了跨越创新S曲线的迹象。

它表明,当前存在一种架构和模型权重,可以让神经网络能够在现有GPU上,有效交互运行复杂游戏DOOM。
不过,GameNGen仍有许多重要的问题存在,这也是谷歌开发者接下来继续攻克的问题。
Shlomi Fruchter带领团队开辟了游戏制作的另一片天地,并希望这个范式能为前路指明方向。
在这种新范式下,能够直接拉低视频游戏的开发成本,并让更多人得到访问。
仅需一句话,或者是一个示例图像,未来可任何一个开发者,皆可以对游戏进行开发和编辑。
另外,为现有游戏创建/修改行为,可能在短期就能实现了。
比如,我们可以将一组帧,转化为一个全新可玩的关卡,或者仅基于示例图像创建一个新角色,无需编写代码。
新范式的好处,或许还能保持足够优秀的帧率,和极少的内存占用。
正如论文作者所述,他们希望这小小一步的尝试,能够对人们游戏体验,甚至更广泛地对日常交互软件系统的互动,带来有极大价值的改善。
从游戏到自动驾驶汽车,令人兴奋的可能性
更令人兴奋的是,GameNGen的潜在应用,远远超出了游戏领域!
无论是虚拟现实、自动驾驶汽车还是智能城市行业,都可能因此而变革。
因为在这些行业中,实时模拟对于培训、测试和运营管理都至关重要。
比如在自动驾驶汽车中,需要能够模拟无数的驾驶场景,以安全地在复杂的环境中行驶。

而GameNGen这类AI驱动引擎,恰恰可以通过高保真度和实时处理来执行这项任务。
在VR和AR领域,AI引擎可以创建完全沉浸式的交互式世界,还能实时适应用户输入。
这种交互式模拟产生的巨大吸引力,可能会彻底改变教育、医疗保健和远程工作等行业!
当然,GameNGen也存在一些挑战。
虽然它可以以交互速度运行《毁灭战士》,但图形密集程度更高的游戏,可能会需要更大的算力。

另外,它是针对特定游戏量身定制的,因此要开发能运行多个游戏的通用AI游戏引擎,挑战仍然艰巨。
但现在,我们俨然已至未来的风口浪尖,从此,我们最喜欢的游戏不是从代码行中诞生,而是从机器的无限创造力中诞生。
从此,人类创造力和机器智能之间的界限会越来越模糊。
通过GameNGen,谷歌研究人员让我们对未来有了令人兴奋的一瞥——
在这个世界中,阻碍我们虚拟体验的唯一限制,就是AI的想象力。
文章来源于“新智元”,作者“新智元”




【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
