# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
KV Cache 是大模型推理性能优化的一个常用技术,该技术可以在不影响任何计算精度的前提下,通过空间换时间的思想,提高推理性能。
我们先推理一下基于Decoder架构的大模型的生成过程。用户输入“中国的首都”,模型续写得到的输出为“是北京”,模型的生成过程如下:
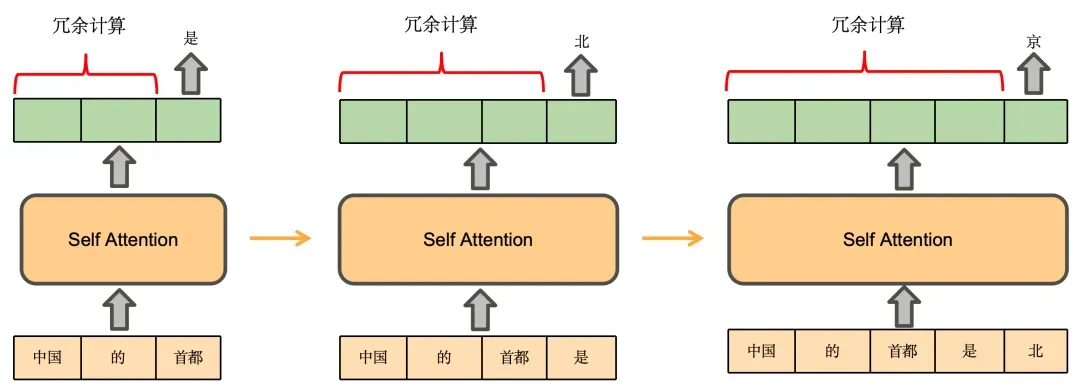
即在预测“是”时,实际发生的计算是这样的:
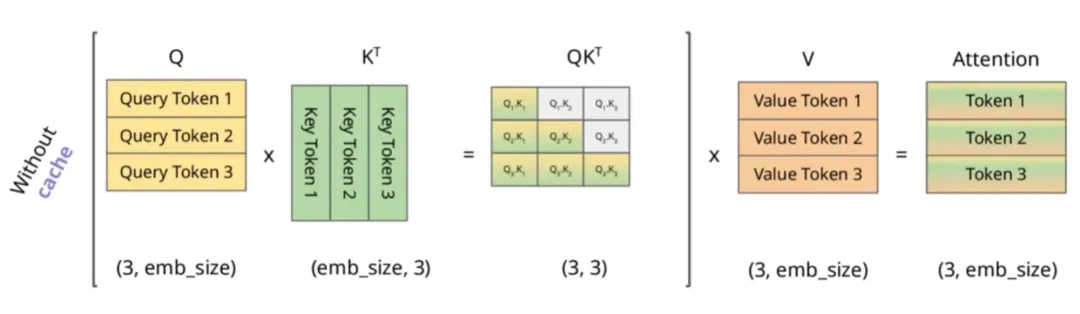
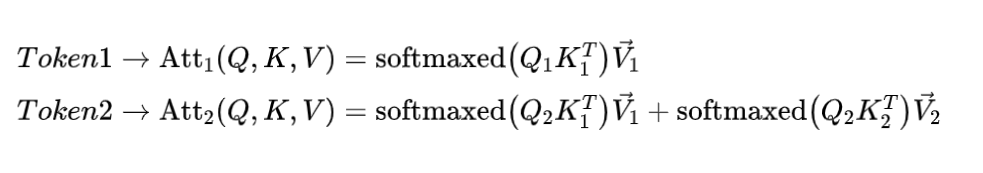
根据上述图解与公式可发现:

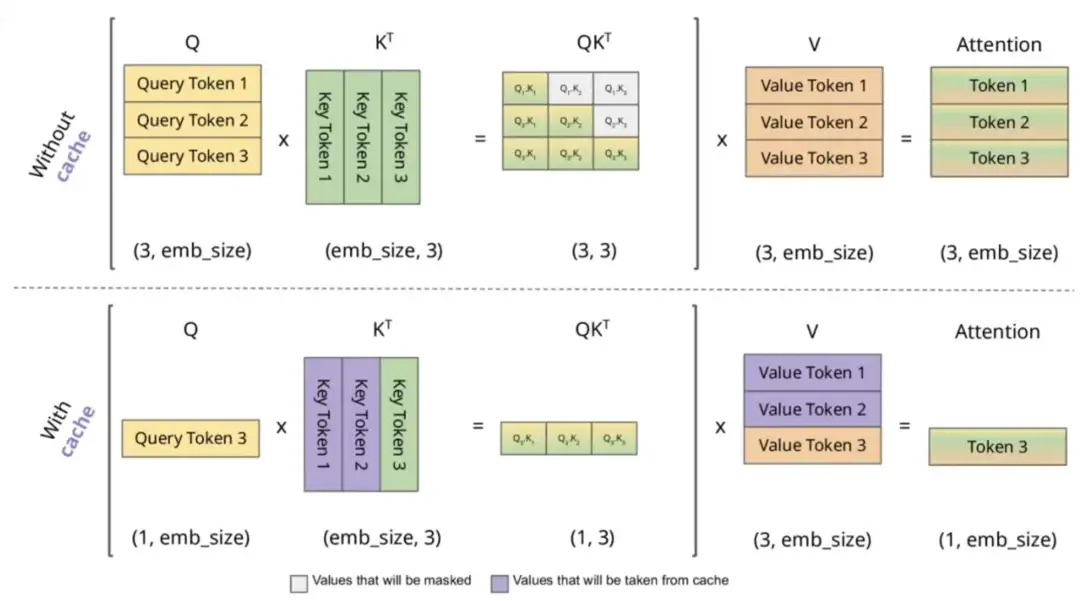
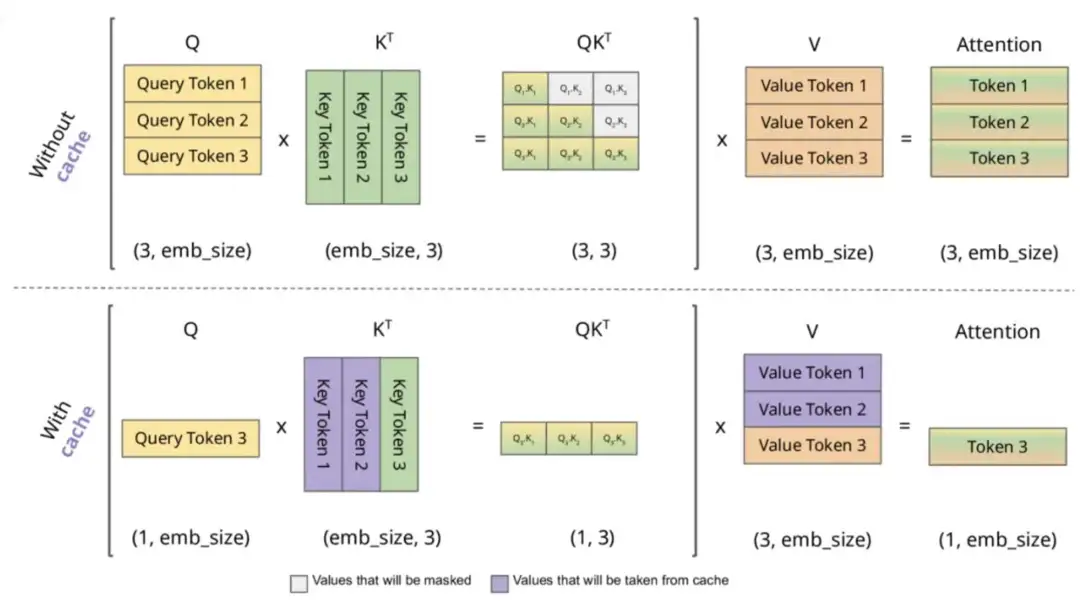
KV Cache的本质是以空间换时间,它将历史输入token的KV缓存下来,避免每步生成都重新计算历史的KV值。一个典型的带有 KV cache 优化的生成大模型的推理过程包含了两个阶段:
当将大模型应用输入过长时,使用原始的 Dense Attention 会出现两个主要挑战:
因此,目前提出了使用滑动窗口的注意力机制,主要有如下几种方式:
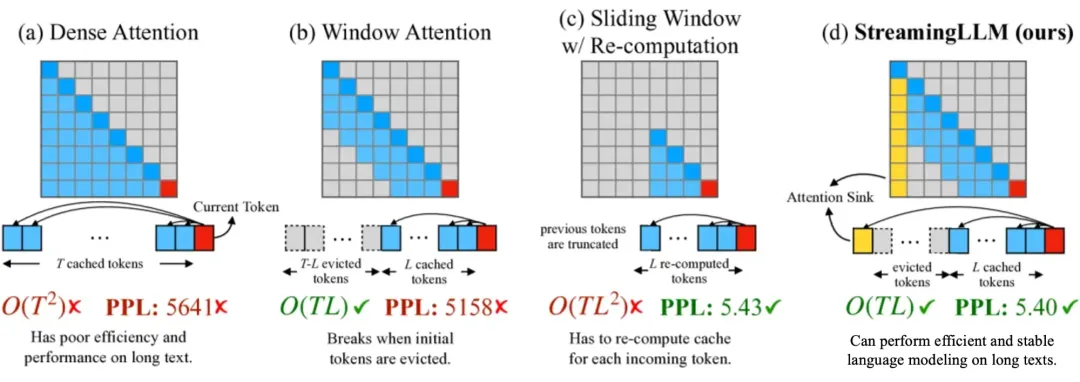
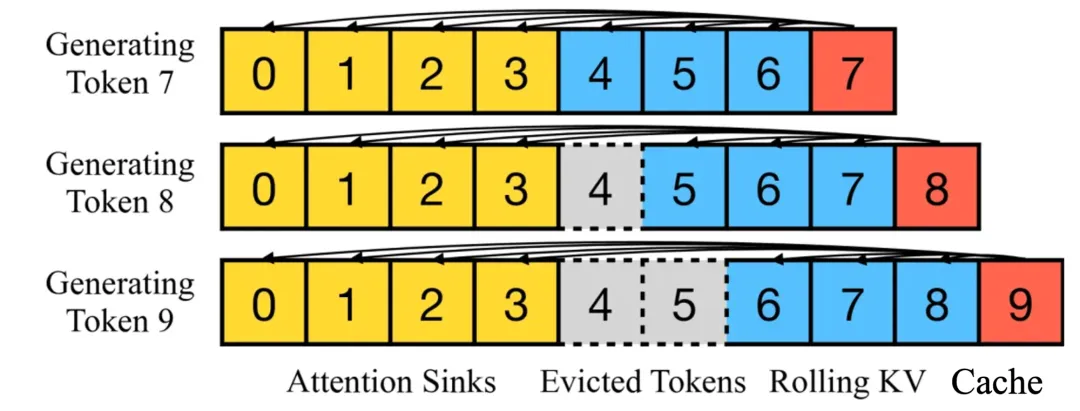
同时,还有一些权重共享的思路来对空间缓存进行优化,以达到减少 Key 和 Value 矩阵的参数量的目的,比如GQA与MQA。

KV Cache 是一种典型的通过空间换时间的技术,在以Transformer-decoder架构为主的生成式大语言模型中能取得巨大的收益。
文章来源“ 安泰Rolling”,作者“琳玉”




【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
