# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

Github:https://github.com/denser-org/denser-retriever/tree/main
当前流行的基于嵌入检索的RAG(Retrieval-Augmented Generation)技术由Meta在2020年首次提出,最初应用于开放领域的抽取式问答。
RAG通过结合信息检索与生成模型,利用嵌入向量显著提升了文本生成任务的准确性和质量。这一方法为自然语言处理领域带来了新的可能性,尤其在开放域问答和对话系统中表现出了卓越的性能。具体而言,RAG主要包括两个关键步骤:检索和生成。
检索阶段(Retrieval Stage):在检索阶段,系统首先从大型知识库中检索与输入查询最相关的文档或段落。常用的技术包括关键词检索,如基于TF-IDF、BM25的传统方法,或稠密向量检索,亦或结合这两种方法的混合检索技术。
生成阶段(Generation Stage):在生成阶段,模型将输入查询与检索到的文档或段落作为上下文,生成最终的回答或文本。该过程通常依赖于预训练的大型语言模型,如GPT系列、GLM系列等,以发挥其强大的生成能力。
在 RAG 应用中,我们之前已经详细介绍了 prompt 的设计、向量数据库的使用、问答的分割策略以及各种检索策略的选择。今天,我们将重点探讨另一个至关重要的组件——检索器,并深入阐述它在 RAG 系统中的核心作用。
检索器是 RAG 模型的引擎,通过它,系统能够高效地从庞大的数据集或知识库中找到最相关的信息。检索器的性能直接影响到模型生成的回答的准确性和相关性,因此选择合适的检索器至关重要。
提升信息获取效率:在海量数据中找到与用户查询高度匹配的内容是 RAG 模型能够生成高质量输出的前提。一个强大的检索器能够迅速锁定最有价值的文档或段落,确保生成模型拥有足够的上下文信息。
Denser Retriever 是一款企业级的 RAG 检索器,整合了多种先进的搜索技术,提供强大的向量搜索(VS)能力。在 MTEB 数据集上的实验表明,Denser Retriever 能显著提升向量搜索的基线性能(使用 snowflake-arctic-embed-m 模型),在 MTEB/BEIR 排行榜上达到了最先进的水平。
这款检索器由 Denser.ai 公司开发,其创始人黄志恒曾担任 AWS 首席科学家,领导过 Amazon Kendra 和 Amazon Business Q 项目。截至 2024 年 7 月,黄志恒的谷歌学术引用次数已超过 13,700 次。
Denser Retriever 完全开源,允许用户轻松构建自己的 RAG 应用和聊天机器人。DenserAI 团队推出的 Denser Retriever 在快速原型设计方面表现卓越。它将关键词搜索、向量搜索和机器学习重排序结合在一个平台中,并通过梯度提升(xgboost)技术优化搜索结果。
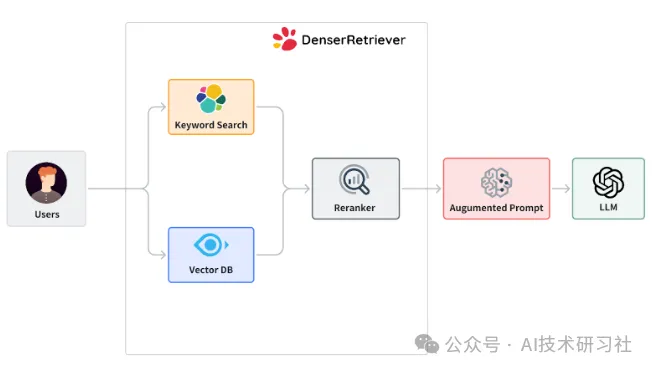
上图说明了 Denser Retriever,它由三个组件组成:
关键字搜索:依赖于传统的精确关键字匹配技术,我们在Denser Retriever中使用Elasticsearch来实现这一功能。
向量搜索:通过神经网络模型将查询和文档编码为高维空间中的密集向量表示,我们使用Milvus和Snowflake-arctic-embed-m模型,该模型在MTEB/BEIR排行榜的各个尺寸变体中均实现了最先进的性能。
ML交叉编码器重新排序器:可以进一步提升上述两种检索方法的准确性,我们采用cross-encoder/ms-marco-MiniLM-L-6-v2模型,该模型在准确性和推理延迟之间达到了良好的平衡。
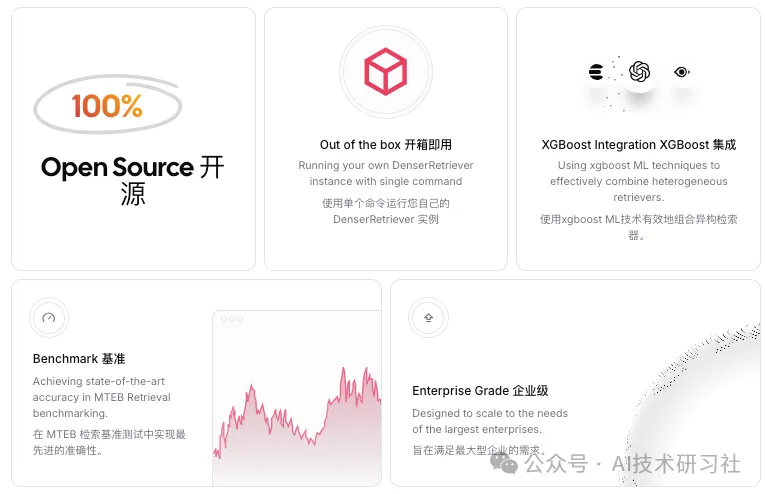
Denser Retriever 的初始版本提供了以下功能:
支持异构检索器:包括关键词搜索、向量搜索以及机器学习模型重排序,确保在各种检索场景下均能实现高效准确的结果。
利用 xgboost 技术:通过 xgboost 机器学习技术,将异构检索器的结果进行有效结合,提高整体检索性能。
先进的精确度:在 MTEB 检索基准测试中,Denser Retriever 达到了最先进的精确度水平,展现出其卓越的性能。
驱动端到端应用:提供了如何使用 Denser Retriever 来驱动聊天机器人和语义搜索等端到端应用的示范。
详细的开发文档和安装指南:为开发者提供了全面的文档支持,帮助快速上手并进行部署。
接下来,我们将结合实例,展示如何选择并实现合适的检索器,帮助您在 10 分钟内构建出一个强大的聊天机器人应用。无论是初学者还是有经验的开发者,都可以从中找到实用的技巧和方法,进一步提升 RAG 模型的应用效果。
使用之前,需要先进行安装。
pip install git+https://github.com/denser-org/denser-retriever.git#main
或者poetry安装。
poetry add git+https://github.com/denser-org/denser-retriever.git#main
下面描述如何从给定的文本文件构建检索器:state_of_the_union.txt 。以下代码演示如何读取文本文件、将文件拆分为文本块并将它们保存到 jsonl 文件passages.jsonl 。
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from denser_retriever.utils import save_HF_docs_as_denser_passages
from denser_retriever.retriever_general import RetrieverGeneral
# Generate text chunks
documents = TextLoader("tests/test_data/state_of_the_union.txt").load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
texts = text_splitter.split_documents(documents)
passage_file = "passages.jsonl"
save_HF_docs_as_denser_passages(texts, passage_file, 0)
# Build denser index
retriever_denser = RetrieverGeneral("state_of_the_union", "experiments/config_local.yaml")
retriever_denser.ingest(passage_file)
# Query
query = "What did the president say about Ketanji Brown Jackson"
passages, docs = retriever_denser.retrieve(query, {})
print(passages)
基于 Streamlit 的简单搜索应用
这段代码实现了一个基于 Streamlit 的简单搜索应用,利用 Denser Retriever 检索器从预定义的索引中检索数据并展示结果。以下是代码的主要功能总结:
导入必要模块:导入了 logging、time、date、streamlit 和 Denser Retriever 相关模块。
配置检索器:定义了索引名称 index_name 为 "unit_test_titanic"。使用配置文件 config-titanic.yaml 初始化了一个 RetrieverGeneral 对象。将测试数据集 "titanic_top10.jsonl" 导入到检索器中进行索引。
创建 Streamlit 界面:设置了应用标题和初始说明(如起始 URL 和可选字符串提示)。从检索器中获取索引字段及其数据类型,并动态生成侧边栏输入框,用于筛选和过滤元数据。允许用户输入查询,并使用检索器根据查询和元数据进行检索。
检索与展示:用户输入查询后,代码记录检索时间并展示检索结果。检索结果以卡片的形式展示,每张卡片显示文档的标题、评分、文本片段以及相关元数据。
主程序执行:if __name__ == "__main__": 条件确保在脚本直接运行时,调用 denser_search() 函数启动应用。
import logging
import time
from datetime import date
import streamlit as st
from denser_retriever.retriever_general import RetrieverGeneral
logger = logging.getLogger(__name__)
index_name = "unit_test_titanic"
retriever = RetrieverGeneral(index_name, "tests/config-titanic.yaml")
retriever.ingest("tests/test_data/titanic_top10.jsonl")
starting_url = "https://github.com/datasciencedojo/datasets/blob/master/titanic.csv"
optional_str = 'Try questions such as "cumings"'
def denser_search():
st.title("Denser Search Demo")
st.caption(f"Starting URL: {starting_url}")
if optional_str:
st.caption(f"{optional_str}")
st.divider()
fields_and_types = retriever.retrieverElasticSearch.get_index_mappings()
meta_data = {}
for field, type in fields_and_types.items():
if field in ["content", "title", "source", "pid"]:
continue
if type == "date":
option = st.sidebar.date_input(
field,
(date(1858, 1, 1), date(1910, 12, 31)),
date(1858, 1, 1),
date(1910, 12, 31),
format="MM.DD.YYYY",
)
else:
categories = retriever.get_field_categories(field, 10)
option = st.sidebar.selectbox(
field,
tuple(categories),
index=None,
placeholder="Select ...",
)
meta_data[field] = option
if query := st.text_input("Input your query here", value=""):
st.write(f"Query: {query}")
st.write(f"Metadata: {meta_data}")
start_time = time.time()
passages, docs = retriever.retrieve(query, meta_data)
retrieve_time_sec = time.time() - start_time
st.write(f"Retrieve time: {retrieve_time_sec:.3f} sec.")
N_cards_per_row = 3
chars_to_show = 80
if passages:
for n_row, row in enumerate(docs):
i = n_row % N_cards_per_row
if i == 0:
st.write("---")
cols = st.columns(N_cards_per_row, gap="large")
# draw the card
with cols[n_row % N_cards_per_row]:
st.caption(f"{row['title'].strip()}")
st.markdown(f"**{row['score']}**")
st.markdown(f"*{row['text'][:chars_to_show].strip()}*")
for field in meta_data:
st.markdown(f"*{field}: {row.get(field)}*")
st.markdown(f"**{row['source']}**")
if __name__ == "__main__":
denser_search()
Denser Retriever的评估
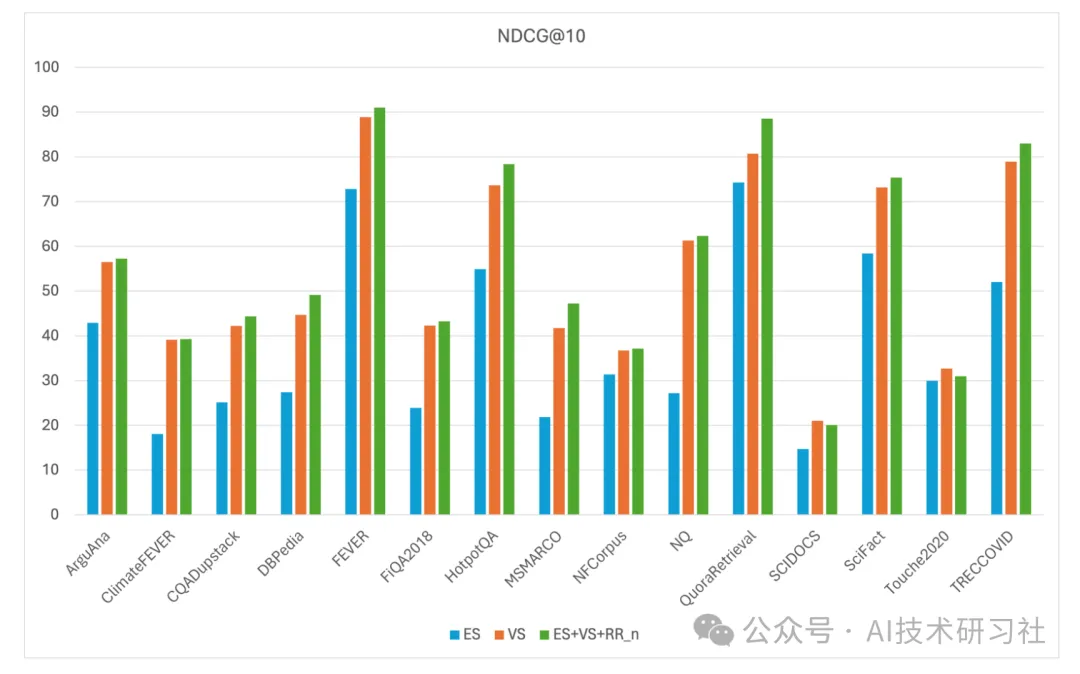
对 Denser Retriever 在 MTEB 数据集上的评估显示,通过使用 xgboost 模型(简称 ES+VS+RR_n),将关键词搜索、向量搜索和重排序器结合,能够显著提升向量搜索(VS)的基准性能。以 snowflake-arctic-embed-m 模型为例,该组合在 MTEB/BEIR 排行榜上达到了最先进的性能。
具体而言,ES+VS+RR_n 模型在 15 个 MTEB 数据集上的 NDCG@10 得分达到了 56.47,较 snowflake 模型(NDCG@10 得分为 54.24)有绝对提升 2.23, 相对提升 4.11%。在广泛认可的 MSMARCO 基准数据集上,ES+VS+RR_n 模型将 snowflake 模型的 NDCG@10 得分从 41.77 提升至 47.23,带来了 13.07% 的相对提升。
用户可以通过一个简单的 Docker Compose 命令快速安装 Denser Retriever 及其所需工具,用于构建自己专属的RAG应用。同时Denser Retriever还提供了自托管解决方案,支持企业级别生产环境的部署。
总的来说,在 RAG 的构建中,选择合适的检索器至关重要。检索器的质量直接影响到系统从外部知识库中提取信息的准确性和相关性,进而决定生成内容的质量。一个强大的检索器不仅能够提升查询结果的精度,还能确保生成模型在各种任务中表现出色,从而实现高质量的输出。
Denser Retriever 是一个非常出色的工具。它集成了多种搜索技术,结合关键词搜索、向量搜索和机器学习重排序,为构建高效的 RAG 应用提供了强大的支持。Denser Retriever 不仅具备企业级的应用潜力,还通过其开源特性为开发者提供了灵活的定制和扩展能力,是构建高性能检索系统的理想选择。
文章来自于“AI技术研习社”,作者“Soyoger”。




【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
