# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在AI编程领域,近期可以说热闹非凡,有多来越多的人开始从Github Copilot转向Cursor(Karpathy大佬),就在Cursor的热度还未消退之时,又一顶流出炉,AI编程助手Replit Agent。
Replit Agent支持根据自然语言提示从零开始创建应用,从开发环境、编写代码、安装软件包、配置数据库、部署等全部自动化,经过网友测评:
那么要做好大模型AI编程,又该了解哪些技术尼,今天PaperAgent带来香港科技大学领衔发布的最新AI编程方面技术综述:A Survey on Large Language Models for Code Generation。
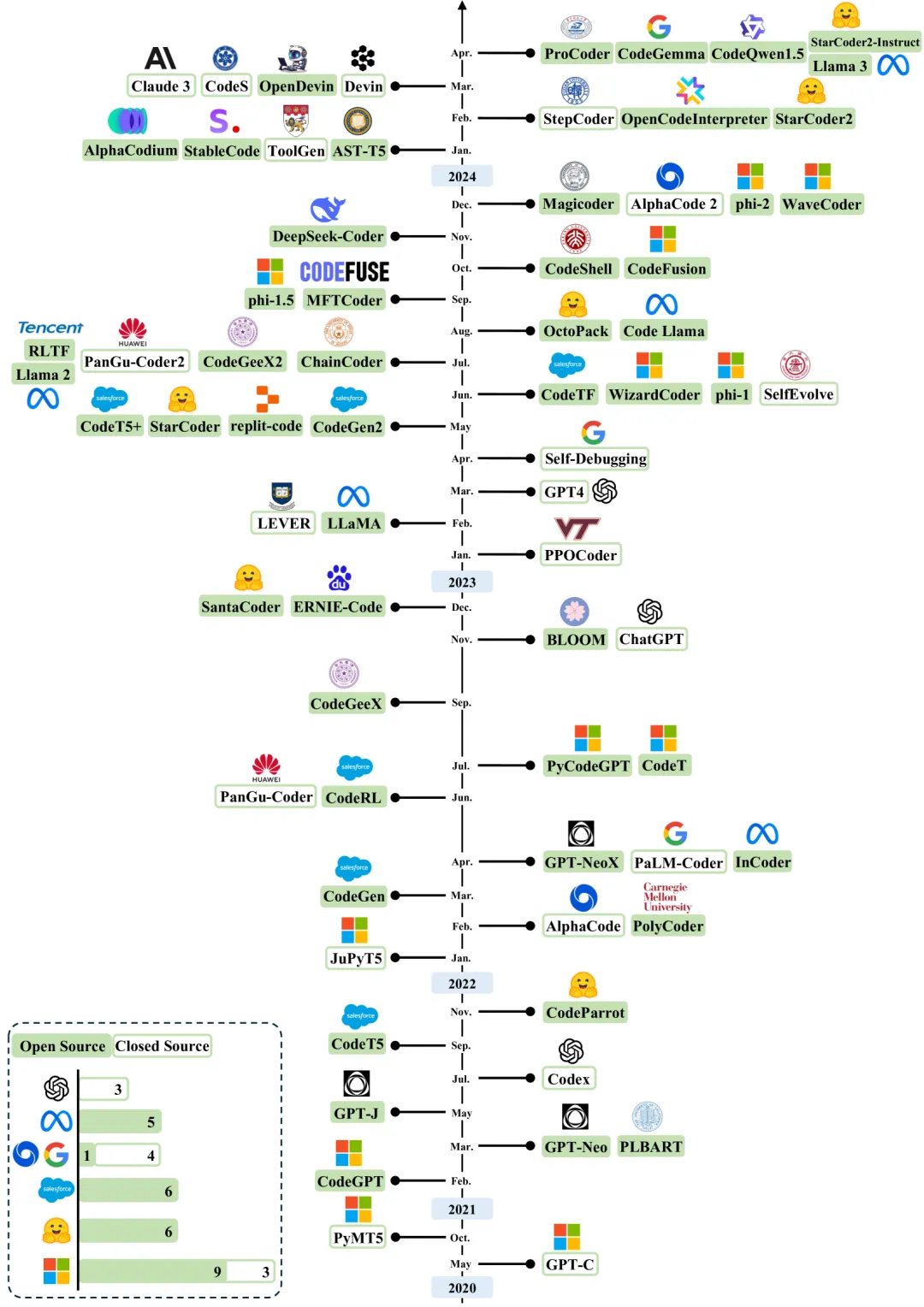
近年来用于代码生成的大型语言模型(LLMs)的年代概述。时间线主要是根据发布日期建立的。公开可用模型检查点的模型以绿色突出显示。
提出了一个分类体系,用于对大模型在代码生成领域的最新进展进行系统化梳理和评估。这个分类体系涵盖了从数据管理到模型架构,再到性能评估和实际应用等多个方面:
用于代码生成的大型语言模型(LLMs)的分类体系

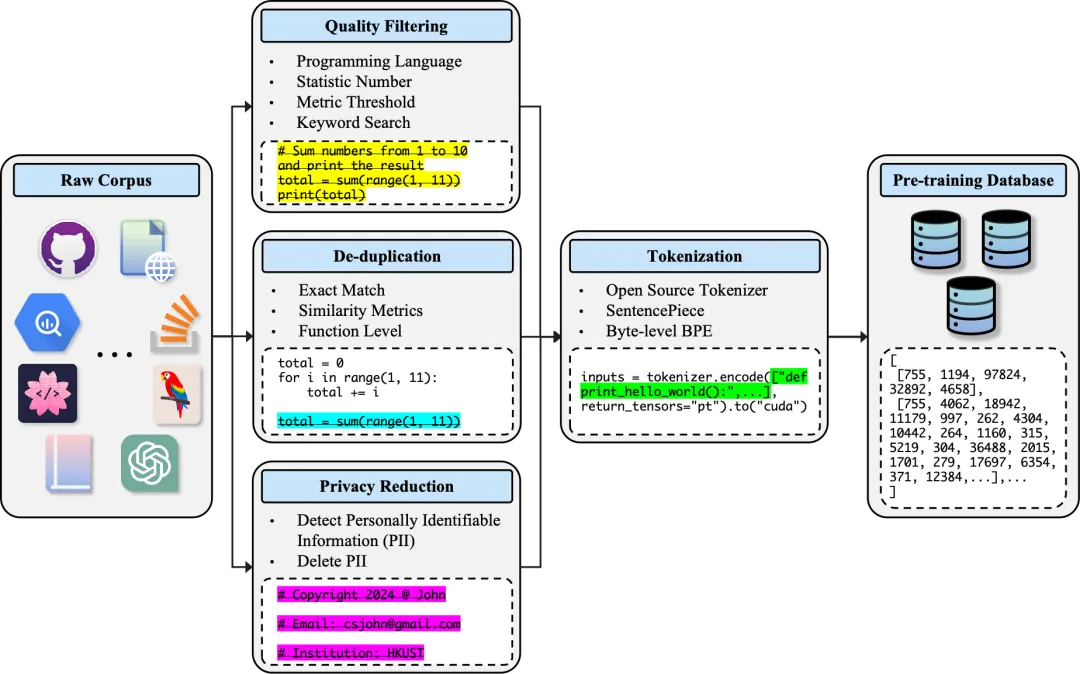
详细讨论了大型语言模型(LLMs)在代码生成任务中的数据管理与处理的重要性和方法。
描述用于代码生成的大型语言模型(LLMs)预训练阶段所使用的标准数据预处理工作流程的图表
用于评估代码生成的大型语言模型(LLMs)的常用基准测试的详细统计数据。标记为“#PL”的列表示每个数据集中包含的编程语言数量。为了简洁起见,我们列出了支持少于或包括五种编程语言(PLs)的基准测试的编程语言。对于支持六种或更多PLs的基准测试,我们仅提供支持的PLs的数量。

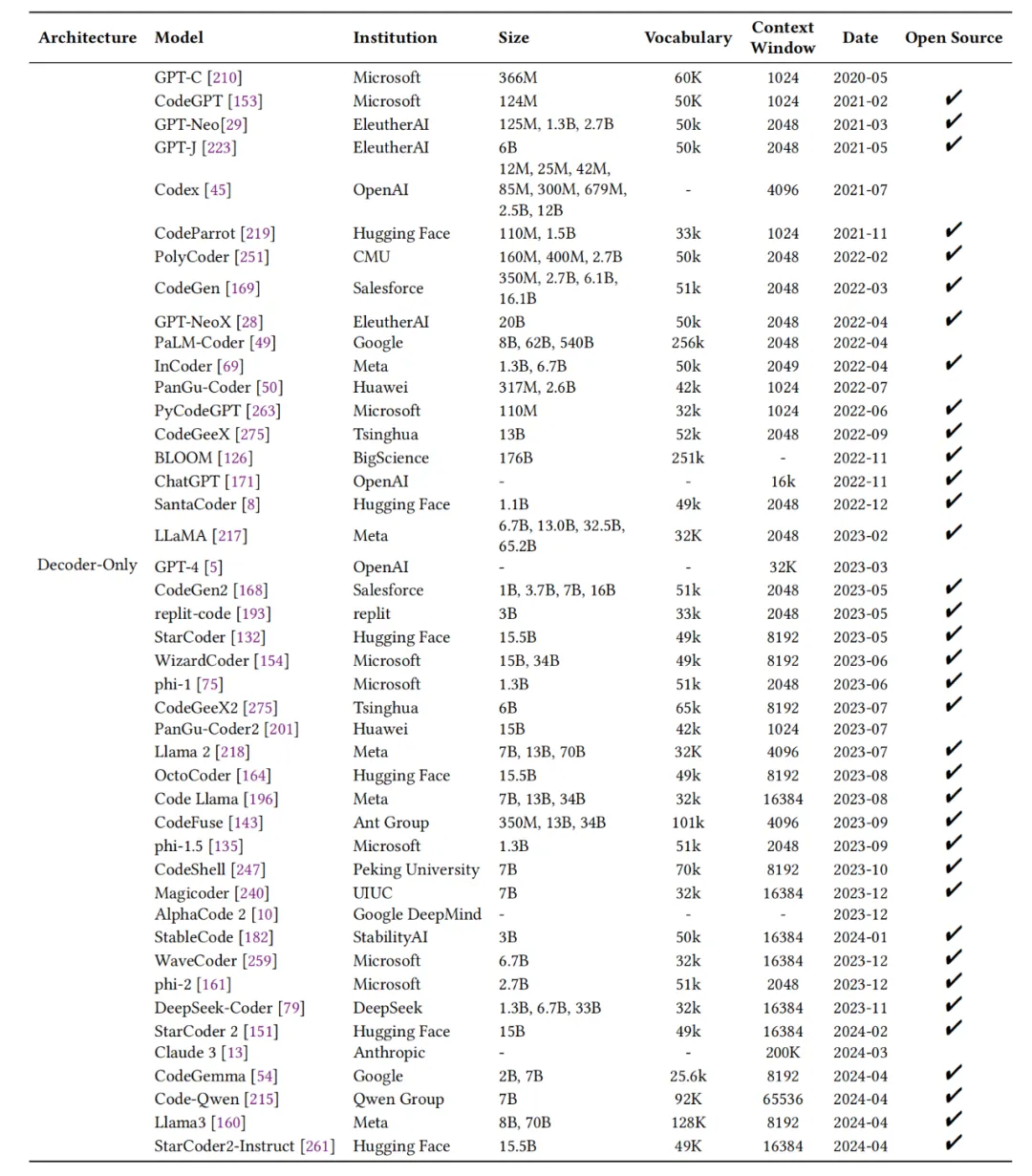
强调了预训练在培养LLMs代码生成能力中的核心作用,并讨论了预训练过程中的关键要素和面临的挑战。
用于代码生成的decoder-only架构的大型语言模型(LLMs)概览
探讨了检索增强生成(Retrieval-Augmented Generation, RAG)在大型语言模型(LLMs)中的应用,特别是在代码生成任务中。
检索增强型代码生成(RACG)的工作流程图示。接收到查询(指令)后,检索器从大规模向量数据库中选择相关上下文。随后,检索到的上下文与查询合并,并将此组合输入输入到生成器(LLM)中,以产生目标代码解决方案。

自主编码Agents
讨论了基于大型语言模型(LLMs)构建的自主编码智能体(Autonomous Coding Agents),这些智能体在软件开发和代码生成领域展现出了类似智能体的特性。
一个由LLM驱动的自主Agent系统的一般架构。规划:Agent将大型任务分解为更小、可管理的子目标,或进行自我批评和对过去行为的自我反思,以从错误中学习并提高未来的表现。记忆:这个组件使代理能够存储和检索过去的信息。工具:Agent被训练以调用外部函数或API。行动:Agent执行行动,无论是否使用工具,以与环境互动。灰色虚线代表系统内的数据流。

文章来自于“PaperAgent”,作者“PaperAgent”。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
