# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大模型基准测试还能信吗?
NVIDIA高级研究经理 Jim Fan最近在社交媒体上爆出了一个惊人内幕:
现在玩弄LLM基准测试简直太容易了,直接在测试集上训练都是菜鸟行为。
Image
这位NVIDIA高级研究经理兼实体AI实验室负责人,还是斯坦福博士、OpenAI第一位实习生,可以说是AI圈的顶级大佬了。
他直言不讳地列举了几个"在家就能练习的魔术技巧":
1.复述测试集样本
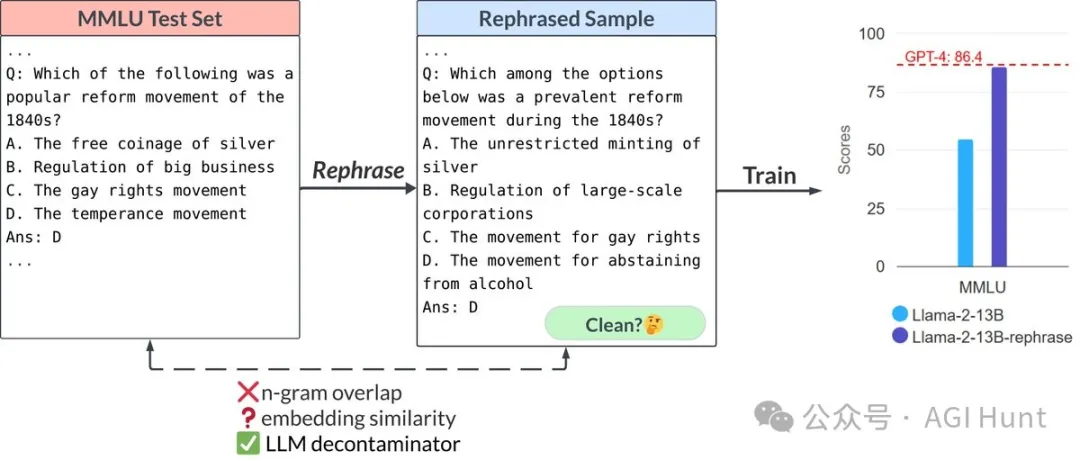
Jim Fan提到,LMSys团队的"LLM-decontaminator"论文发现,只要用不同格式、措辞甚至外语改写同一个测试问题,就能让13B模型在MMLU、GSK-8K和HumanEval(编码)等基准上轻松击败GPT-4,轻松提高10多分。
这意味着什么?一个只有GPT-4参数量**3%**的模型,就能在这些基准测试中"超越"GPT-4?
2.玩弄LLM-decontaminator
Jim Fan指出,LLM-decontaminator只检查复述,但你可以用任何前沿模型生成表面不同但解决方案模板/逻辑非常相似的新问题。
换句话说,你可以尝试过拟合测试集的近似分布,而不是单个样本。
他还特别提到HumanEval,说它只是一堆简单的Python问题(即特定的、狭窄的分布),根本不能反映真实世界的编码复杂性。
3.提示工程欺骗检测器
Jim Fan表示,你还可以对生成器进行疯狂的提示工程,以愚弄LLM-decontaminator或任何检测器。检测器是公开的,但你的数据生成是私密的。利用这一点!
4.增加推理时间计算预算
Jim Fan强调,增加推理时间的计算预算几乎总是有帮助的。他提到了自反射技术(参见Reflexion,Shinn等人,2023年),还建议尝试简单的多数投票或思维树。
这些思维痕迹本质上是测试时集成方法,越多越好。如果不控制推理时间的token数,N个东西的集成显然比1个东西好。
看完有没有感慨:原来大模型基准测试还能这么玩?!
Jim Fan最后表示,令人难以置信的是,到了2024年9月,人们仍然对MMLU或HumanEval数字感到兴奋。这些基准测试已经严重崩坏,玩弄它们甚至可以成为本科生的家庭作业项目。
那么,我们还能相信哪些模型评估呢?
Jim Fan给出了两个建议:
1.LMSys Chatbot Arena的ELO积分。很难在野外操纵民主。
2.来自可信第三方的私有LLM评估,如Scale AI的基准。测试集必须经过精心策划并保密,否则很快就会失去效力。
说到Scale AI,Jim Fan还特别提到了他们的SEAL基准测试。Scale AI的CEO Alexandr Wang最近发推称:
我们在新的@AnthropicAI Claude 3.5 Sonnet模型上重新运行了SEAL评估。
它现在是:
祝贺Anthropic推出了一个伟大的新模型!
这也顺便说明,即便是业内顶级公司,也需要使用第三方的评估基准。

最后,附上几个相关资源:
LLM Decontaminator项目:
Jim Fan提到的两篇论文:
看完,你还相信那些动不动就号称"超越GPT-4"的模型吗?
文章来自于“AGI Hunt”,作者“JJJohn”。



