# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
7 月份正式上线的国产视频大模型 Vidu,在今天发布大版本更新。
在今天的生树科技媒体开放日上,Vidu 发布了「主体参照」(Subject Consistency)功能,该功能能够实现对任意主体的一致性生成,让视频生成更加稳定、可控。

目前该功能面向用户免费开放,注册即可体验!
(体验地址: www.vidu.studio)
所谓「主体参照」,就是允许用户上传任意主体的一张图片,Vidu 就能够锁定该主体的形象,通过描述词任意切换场景,输出主体一致的视频。
该功能不局限于单一对象,而是面向「任意主体」,无论是人物、动物、商品,还是动漫角色、虚构主体,都能确保其在视频生成中的一致性和可控性,这是视频生成领域的一大创新。Vidu 也是全球首个支持该能力的视频大模型。
上传的主体也不限于写实风格,比如针对动漫角色或者虚构的主体等,Vidu 也可以保持其高度一致。
中央广播电视总台导演、AIGC 艺术家石宇翔(森海荧光)创作的一条动画短片《夏日的礼物》
在视频大模型领域,尽管已有如「图生视频」和「角色一致性」等能力,但 Vidu 的「主体参照」功能在一致性方面实现了质的飞跃。具体对比看:
「主体参照」功能通过锁定角色或物体的形象,一方面让故事情节更具连贯性,另一方面让创作者能够更自由地探索故事的深度和广度。
对于故事短片和广告片来说,现在通过 Vidu 能够极大地节省广告制作的成本,整个产出流程更加高效,品牌方对新素材的开发也能更加灵活。
在涉及复杂动作和交互的情况下,保持主体的一致性是一项挑战。此外,视频模型的输出结果具有较大的随机性,对于镜头运用、光影效果等细节的控制也不够精细。
所以现阶段的视频模型虽然在画面表现力、物理规律、想象力等方面实现了一定程度的突破,但可控性的不足限制了它们在创作连贯、完整视频内容方面的应用。目前,大多数的 AI 视频内容还是基于独立视频素材的拼接,情节的连贯性不足。
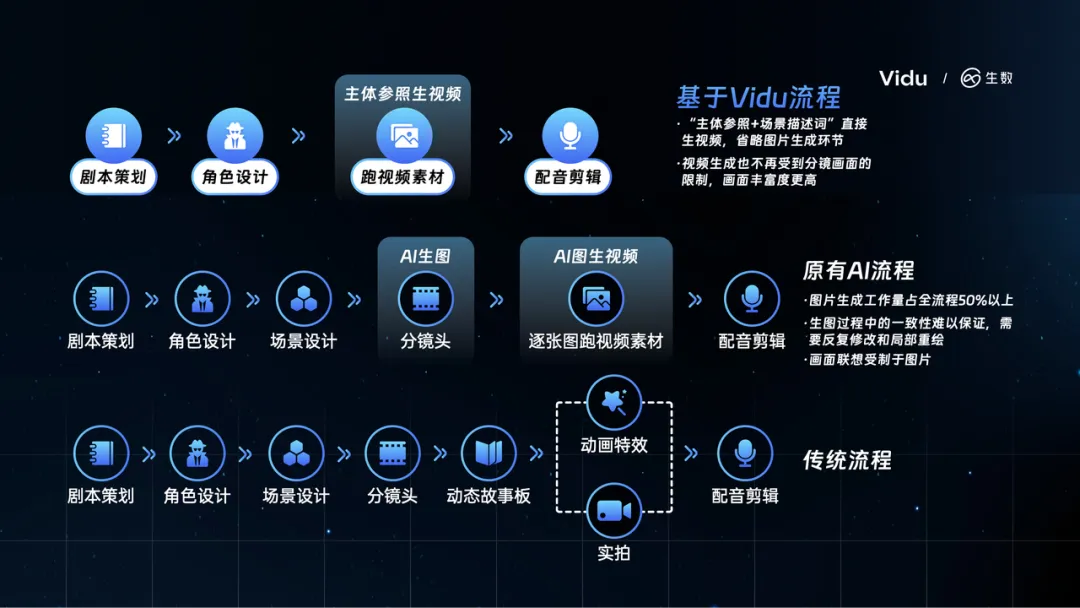
为了解决这一问题,业界曾尝试采用「先 AI 生图、再图生视频」的方法,通过 AI 绘图工具如 Midjourney 生成分镜头画面,先在图片层面保持主体一致,然后再将这些画面转化为视频片段并进行剪辑合成。
但问题在于,AI 绘图的一致性并不完美,往往需要通过反复修改和局部重绘来解决。更重要的是,实际的视频制作过程中涉及众多场景和镜头,这种方法在处理多组分镜头的场景时,生图的工作量巨大,能占到全流程的一半以上,且最终的视频内容也会因为过分依赖分镜头画面而缺乏创造性和灵活性。
Vidu 的「主体参照」功能彻底改变了这一局面。它摒弃了传统的分镜头画面生成步骤,通过「上传主体图+输入场景描述词」的方式,直接生成视频素材。这一创新方法不仅大幅减少了工作量,还打破了分镜头画面对视频内容的限制,让创作者能够基于文本描述,发挥更大的想象力,创造出画面丰富、灵活多变的视频内容。这一突破将为视频创作带来了前所未有的自由度和创新空间。
生树科技 CEO 唐家渝表示,"主体参照"这一全新功能的上线,代表着 AI 完整叙事的开端,AI 视频创作也将迈向更高效、更灵活的阶段。无论是制作短视频、动画作品还是广告片,在叙事的艺术中,一个完整的叙事体系是「主体一致、场景一致、风格一致」等要素的有机结合。
因此,视频模型要达到叙事的完整性,就必须在这些核心元素上实现全面可控。「主体参照」功能是 Vidu 在一致性方面迈出的重要一步,但这仅仅是开始。未来,Vidu 将继续探索如何精确控制多主体交互、风格统一、多变场景稳定切换等复杂元素,以满足更高层次的叙事需求。
文章来自于“Founder Park”,作者“Founder Park”。



【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
