# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Mistral的多模态大模型来了!
Pixtral 12B正式发布,同时具备语言和视觉处理能力。

它建立在文本模型Nemo 12B基础上,包含一个专门的视觉编码器。
大概24GB,原生支持任意数量和尺寸的图像,大约有40层神经网络、14,336 个隐藏维度大小和32个注意力头,以及一个专用的视觉编码器,支持高分辨率图像(1024×1024)处理。
发布形式还是简单直接一个种子链接。
现在可以通过链接、GitHub或Hugging Face下载模型。
Mistral的开发主管表示,后续也会在Chatbot上接入模型,并提供API服务。

虽然目前模型的训练数据、细节都未公开,但是通过模型代码网友们发现了更多细节。
1、先进架构:40层网络、14336隐藏维度大小、32个注意力头。
2、视觉能力:专用视觉编码器,支持1024x1024图像大小和24个隐藏层,用于高级图像处理。
3、更大词汇量:131072tokens,支持更细致语言理解和 生成。
4、使用GeLU(用于视觉适配器)和2D RoPE(用于视觉编码器)。
5、Patch大小:16×16像素。
6、在mistral_common中支持tokenizer。
7、模型权重bf16。

与此同时,还有人在放出了Mistral发布会上公布的模型基准情况。
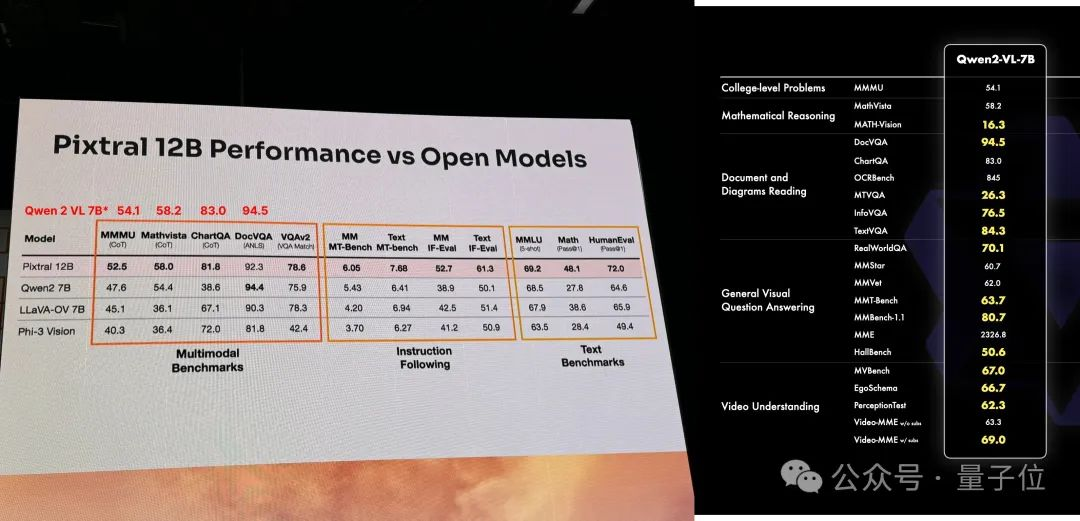
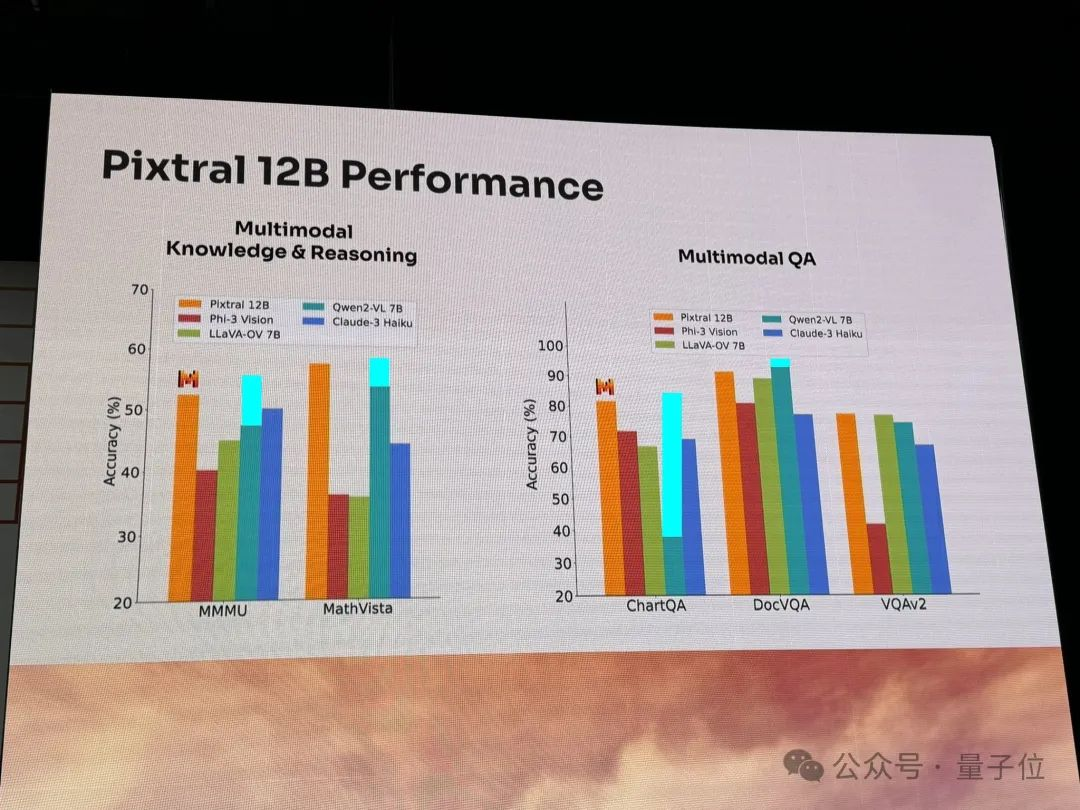
Pixtral 12B和Qwen2-VL-7B、LLaVA-OV-7B、Phi-3 Vision做了对比。
多模态知识和推理、QA等方面都表现不错。
最近几个月Mistral的动作还是非常密集的。
今年6月,他们通过股权债务融资完成约6.4亿美元B轮融资。估值已达60亿美元(折合人民币约420亿)。
完成融资后,他们便发布了Mistral Large 2旗舰模型、SMoE模型Mistral 8×22B以及开源模型Codestral等。
目前,微软、AWS、Snowflake等巨头均投资Mistral。尤其是微软的入股,使得Mistral成为OpenAI以外,微软Azure第二个商业闭源模型供应商。这也进一步夯实了Mistral“欧洲版OpenAI”的地位。
参考链接:
[1]https://x.com/_philschmid/status/1833954941624615151
[2]https://venturebeat.com/ai/pixtral-12b-is-here-mistral-releases-its-first-ever-multimodal-ai-model/
[3]https://x.com/theresanaiforit/status/1833784474342977627
文章来自于微信公众号“量子位”,作者“明敏”



