# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
榜单,并不能代表模型实力
大模型时代,闭源比开源在商业场景更有优势
智能体,还未成为共识
这是李彦宏近期在内部讲话中,所阐述出公众和行业对大模型的三大认知误区。
2024年已过大半,AI行业技术在过去一年坐上过山车之后,逐渐进入冷静期。
GPT-4之后,OpenAI一直按兵不动,迟迟未更新下一代模型。而Llama 3等开源模型的诞生,性能逼近闭源模型。
行业中,质疑声不断涌现:大模型是不是一场新的科技泡沫?
大模型之间是不是已经没有技术壁垒了?还要继续投入基础模型的研究吗?开源模型拿来直接用是不是就可以?未来AI应用的发展方向在哪里?
这些,都是技术降温时,萦绕在所有人头脑中的疑问。
在刚刚曝光的内部讲话中,李彦宏对这些问题给出了自己的答案和思考,并指出了AI未来的发展方向。
同时,他坚定地认为——智能体,才是AI时代的未来趋势。
内部讲话首次曝光:LLM三大误区
对于「大模型之间的能力已经不存在壁垒」这种说法,李彦宏给出了不同观点。
「每次新模型发布,都和GPT-4o做比较,说我的得分已经跟它差不多了,甚至某些单项上得分已经超过它了,但这并不表明和最先进的模型就没有差距了」。
实际上,模型之间的差距是多维度的。一个维度是能力方面,比如理解、生成、记忆、逻辑推理等基本能力的差距;另一个维度是成本和推理速度。
很多公司或者用户对于模型能力的评价是片面的,往往只关注前者,但却忽视了后者,这就导致了对于单一榜单的过度迷恋。
为了让自家模型得高分,有的厂商会对测试集「进行over-fitting」。
比如,让数据标注员把评测题做一遍,或者让GPT-4做一遍,再把答案喂给自家模型,相当于让模型「刷题」考高分。
这样从榜单或者测试集上看,就会让人觉得,模型之间的能力已经很接近了,但在实际应用场景中,就会暴露出明显的差距,出现「高分低能」。
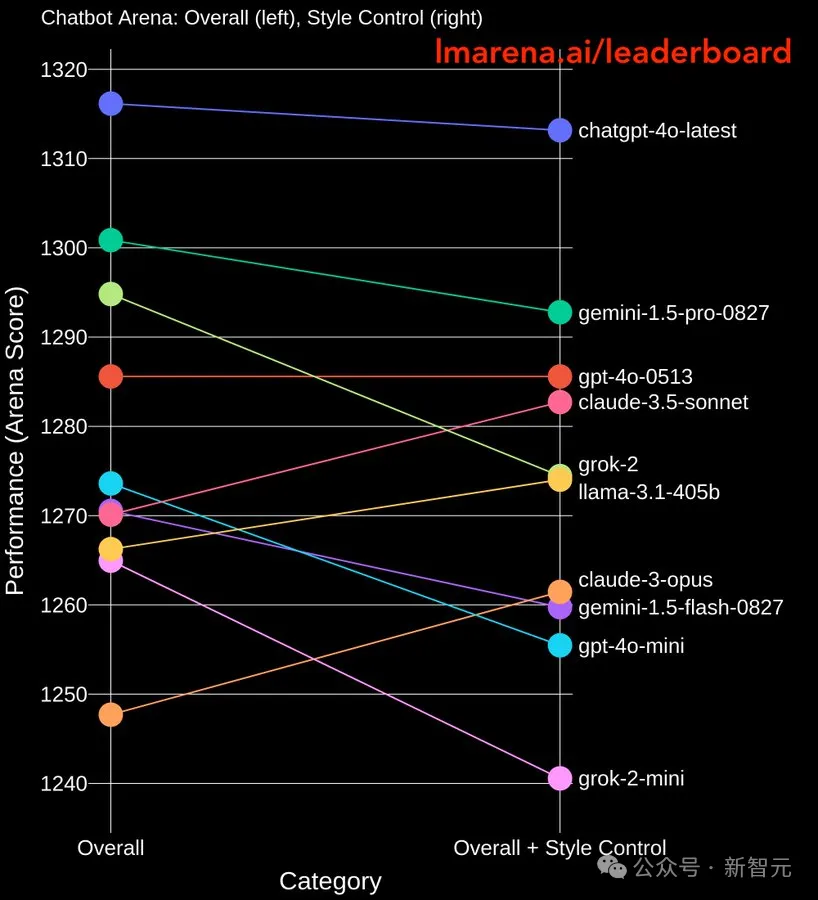
一些模型会刷榜时,会通过输出详尽且格式完备的回答来「操控」人类偏好
李彦宏表示,百度是不允许技术人员「打榜」。真正衡量文心大模型能力的,是在具体应用场景中能否满足用户的需求,能否产生有价值的增益。
透过各种各样的榜单和分数,我们需要看到,一方面模型能力之间还有比较明显的差距,另外一方面,天花板也很高。
今天已经实现的模型性能,和我们实际想要的理想状态,还有很远的距离。
因此,模型还需要不断的快速迭代、更新、升级。不同的模型之间差距不会是越来越小,而是会越来越大的。即使今天的差距看似很小,再过一年时间,就会有天翻地覆的变化。
这个过程,就是看有谁能够持续不断地几年甚至十几年投入,让模型越来越能够满足场景和用户,实现效率提升或成本降低。
对于所谓的领先12个月或者落后18个月,李彦宏认为并没有那么重要。
在这个完全竞争的市场环境中,无论做什么方向都有很多竞争对手,因此不要觉得12~18个月是很短的时间。如果能保证永远领先对手12~18个月,哪怕是6个月,那都是「天下无敌」的水平。
我们从软件时代走来,因此有一种固定的思维模式——「开源一定好」,但这在大模型时代却不一定正确。
软件时代,开源的优势是建立在低廉的算力和硬件成本之上的,但对于大模型来说,算力和硬件却是无法被忽略的关键因素。
比如开源的Linux,因为用户已经有了电脑,所以使用起来几乎没有成本;但是大模型时代,算力是「命根子」,是决定成败的关键因素,即使是开源模型,也无法直接促进算力的高效利用。
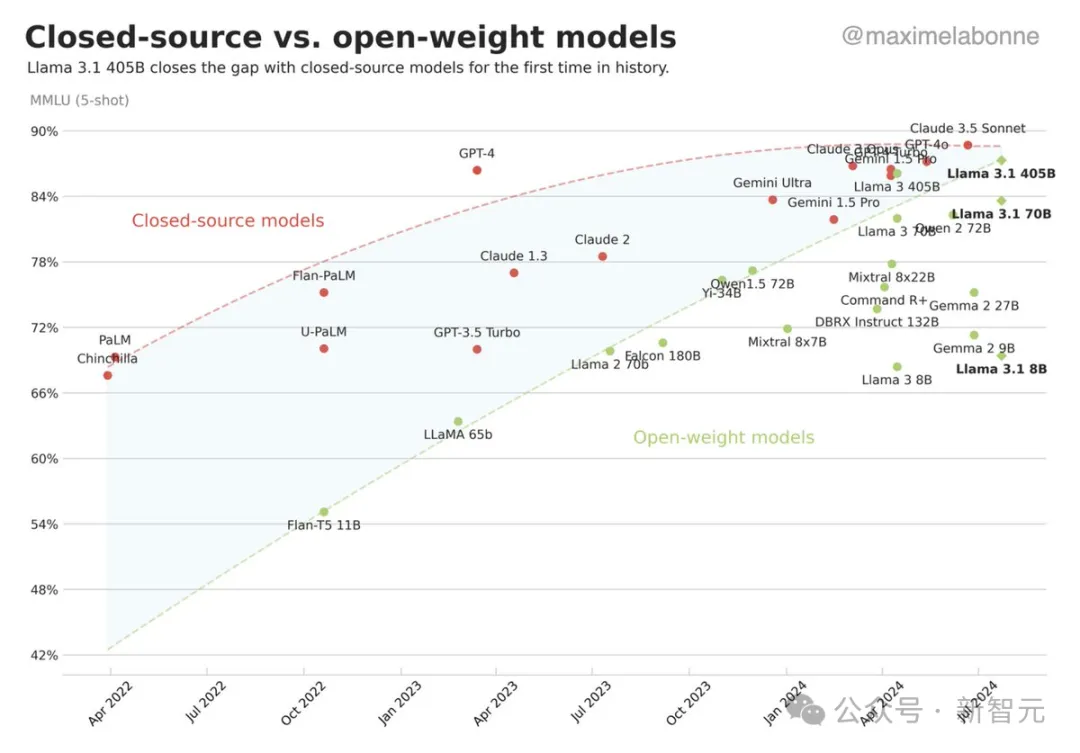
正如上一个问题中提到的,大模型除了能力或效果之外,还要看效率。效率上,开源模型是不行的。
闭源模型,或者准确地讲应该叫商业化模型,相当于无数个用户或客户共享同样的资源,分摊研发成本和推理所用的硬件、GPU,这样的算力效率是最高的。
以百度为例,目前文心大模型每天调用量超过6亿、生成的token数量超过万亿,GPU使用率达到了90%以上。
但如果在商业场景下使用开源模型,就需要部署自己的GPU、自己找算力,无处分担推理成本。最终综合起来,不如选择商业化模型划算。
所以,开源大模型的价值主要体现在教学、科研等领域,开放的源代码可以让我们弄清大模型的工作原理;但商业领域追求的是效率、效果和最低成本,开源模型是没有优势的。
李彦宏表示,大模型应用的发展必然要经历几个阶段。
一开始是对人进行辅助,产出的结果都需要人来把关,检查无误、确定效果后才能使用,这是Copilot阶段;
再往下走,就是Agent智能体,有了一定的自主性,具备自主使用工具、反思、自我进化等能力;
这种自动化程度再往下走,就变成所谓的Al Worker,能够像人一样做各种各样的脑力和体力劳动,各方面的工作都可以独立完成。
过去一年,很多目光都聚焦在多模态领域,但其实忽略了,智能体才是目前最能激发大模型潜力的应用方向。
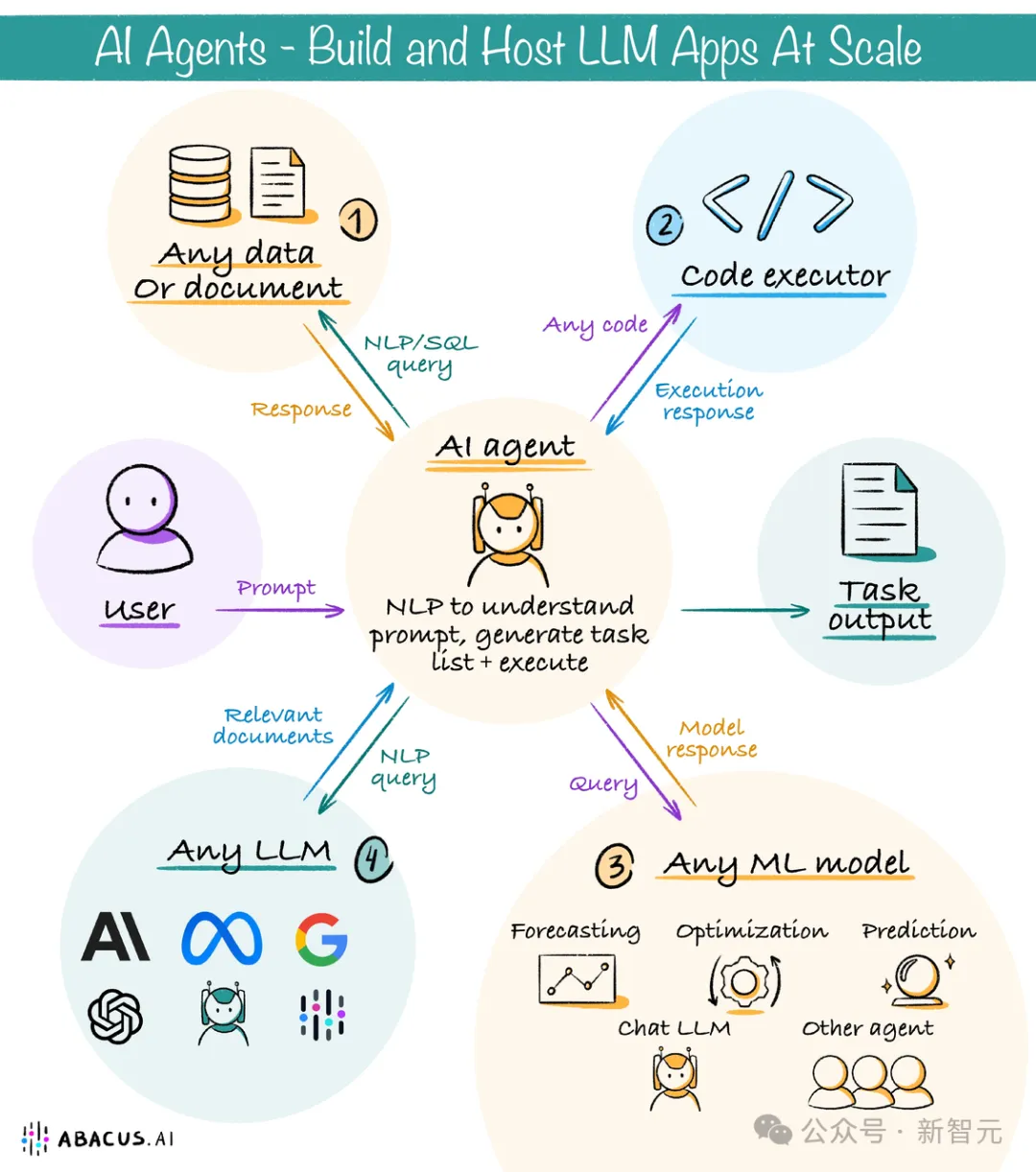
为什么这么强调智能体?因为智能体的门槛确实很低。
很多人不知道怎么把大模型变成应用,这其中有很多不确定性,而智能体是一个非常直接、高效、简单的方式,在模型之上构建智能体相当方便。
百度在Create大会上发布了三个产品:AgentBuilder、AppBuilder和ModelBuilder,其中AgentBuilder和AppBuilder都是关于智能体的,一个门槛更低,另一个功能更强大。
这些工具引起了开发者们的兴趣,让智能体的热度逐渐提升。目前,文心平台上每周都能创造出上万个新的智能体。
https://agents.baidu.com/center
然而,「智能体是大模型最重要的发展方向」这个判断,其实并没有形成共识,因此还有很大的发展潜力。
百度在智能体方面已经看到了趋势,而且具备比较好的发展条件。除了模型本身的能力比较强大之外,也有分发通路的优势。
百度的APP,尤其是百度搜索的日活跃用户能达到几亿级别,因此能直接捕捉到用户的需求,知道哪一个智能体能更好地去回答问题、满足需求。这个自然匹配的过程也最能够帮助开发者们分发智能体。
百度智能体,已迈入深水区
CEO李彦宏在多次内外部讲话中,都明确了表示智能体对于AI应用的重要性,倡导全行业持续投入智能体生态。
6月的「亚布力企业家走进百度」活动中,李彦宏预言,未来将会有几百万,甚至更大量的智能体出现,形成庞大生态。
「未来,各行各业、各个领域都会依据具体的场景,根据自己特有的经验、规则、数据,做出来这些智能体。」
这些智能体不仅能对话,还具备反思和规划能力,未来或许还将具备协作能力。
「就像公司里有CEO,还有财务、技术、销售主管,他们协作起来,能完成一个非常复杂的任务。」如果多个智能体可以协作,将会对整个生态的发展形成极大推动。
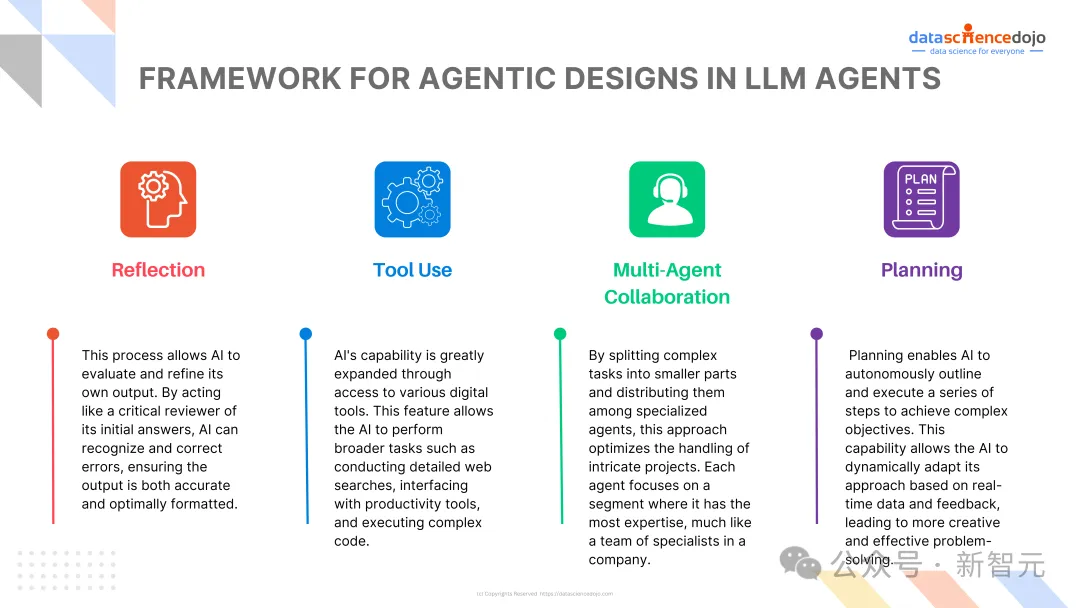
谈及企业做智能体的方向,李彦宏表示,如果仅仅是针对理解、生成、逻辑和记忆等基础能力做改进或集成,价值不大;但在各个不同场景中,利用好特有的数据,就能逐渐积累出自身的竞争优势。
「大模型对于ToB业务的改造,会是非常深刻和彻底的,比互联网对于ToB的影响力要大一个数量级。今天,大模型在B端的影响已经大于C端了。」
今年7月WAIC的圆桌访谈和演讲中,李彦宏再次表示,在AI应用的发展方向上,最看好智能体,智能体代表着AI时代的未来趋势。

基础模型需要靠应用才能显现出价值,而智能体是一个几乎「放之四海而皆准」的大模型应用。
因为门槛足够低,甚至都不需要编程,只要用「人话」把工作流说清楚,再配以专有知识库,就能做出一个效果不错的,甚至很有价值的智能体,比互联网时代制作一个网页还简单。
「智能体正在爆发,只是现在基数还比较小,大家的体感没有那么强烈。让更多人进来、发挥聪明才智,指不定哪条路跑通了,就是一个Super APP。」
虽然有巨大的潜力,但是像百度这样,将智能体定位为大模型最重要战略、最重要发展方向的公司,并不多见。
在百度文心智能体平台AgentBuilder上,已有20万开发者、6.3万企业入驻,在百度开发智能体的商户已达1.6万家。

7月,AgentBuilder平台还做出了重大举措,免费开放文心大模型4.0供开发者使用。
根据今年第二季度的财报,智能体在百度生态的分发量正在快速上升,百度搜索已经成为分发的最大入口。
以7月份为例,日均分发次数超800万,是5月的两倍。其中最常用的智能体包括内容创作、性格测试、日程规划等应用类型,覆盖教育、法律和B2B等行业。
作为AI应用的先行者,百度对智能体领域的率先尝试、大力押注,让我们看到了大模型生态落地应用的广阔前景。
如果李彦宏的预言成真,大模型不仅不会沦为泡沫,反而是更大、更繁荣市场的开始,大模型+智能体将引领移动互联网之后的下一次技术浪潮。
文章来源于“新智元”,作者“新智元”



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
