# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
多模态大型语言模型(MLLMs)在各个排行榜上展现的性能不断提升,例如GPT-4o在大学水平上的多学科多模态理解和推理(MMMU)基准测试中取得了69.1%的准确率。
不过,基准测试结果是否真的能反映模型对多样化主题的深入理解,仍然有争议,或者说模型是否只是利用了统计模式,而非依靠理解和推理的情况下就能得出正确答案?
为了解决这一问题并推动多模态AI评估的边界,MMMU团队对MMMU基准在健壮性和问题难度上进行提升,新基准MMMU-Pro能够更准确、更严格地评估模型在广泛的学科领域内真正的多模态理解和推理能力。

论文链接:https://arxiv.org/abs/2409.02813
MMMU-Pro的构建过程包括三步:
1. 过滤掉纯文本模型可回答的问题;
2. 由人类专家将候选选项增加到 10 个,以减少模型蒙对答案的概率;
3. 引入纯视觉输入设置,即问题直接写在图像中,既要求模型像人一样同时具有「看」和「读」的能力,也可以在现实场景中直接将模型用于屏幕截图或照片,无需分离问题与图片;
实验结果显示,模型在MMMU-Pro上的性能明显低于 MMMU,下降 16.8% 到 26.9%,模型的排名通常与原始模型相似,但GPT-4o mini 模型的健壮性与GPT-4o相比,健壮性较差。
研究人员中还探讨了 OCR 提示和思想链 (CoT) 推理的影响,结果发现 OCR 提示的影响很小,而 CoT 通常可以提高性能。
重新审视MMMU基准测试
大规模多学科多模态理解和推理(MMMU)基准测试是一个综合性的数据集,能够评估多模态人工智能模型在需要特定学科知识和深思熟虑推理的大学水平任务上的表现。
MMMU由来自大学考试、测验和教科书的1.15万个精心策划的多模态问题组成,涵盖了六个核心学科的30个主题和183个子领域。
MMMU中的每个问题都是一个多模态的图文配对,有4个多项选择选项,包括图表、图解、地图和化学结构等30种不同的图像类型。
该基准已经成为了多模态领域的标准评估工具,许多著名多模态模型在发布时都会使用MMMU来评估能力。

但与此同时,MMMU社区也有许多负面反馈,研究人员总结为两个问题:
1. 文本依赖性:某些问题相对独立或与相应的图像无关,即无需输入图像,仅靠问题文本就能回答;
2. 利用捷径:即使问题需要图像才能正确回答,但模型通常也能找到候选选项中的捷径或相关性,根据预训练中获得的先验知识来得出正确答案。
所以MMMU-Pro在构建的时候,更加细致地考虑问题与图像之间的关联性,以及智能体是否真正理解了问题的本质,而不仅仅依赖于文本信息或选项中的模式识别。
构建方法
为了缓解这些问题并构建一个更健壮的基准测试,研究人员设计了一个三步方法:
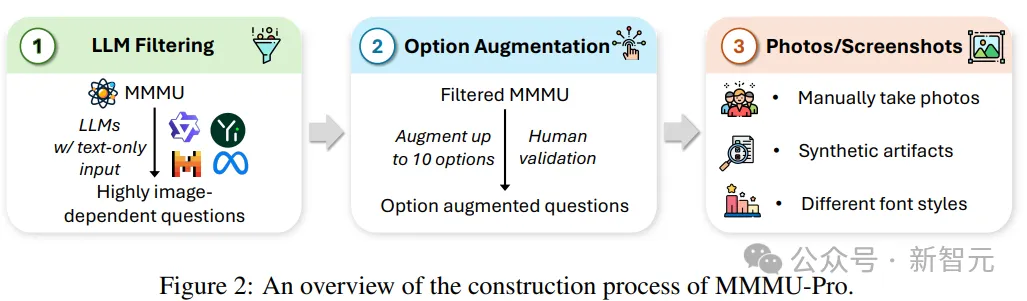
1. 筛选问题
删除仅通过文本的大型语言模型(LLMs)就能回答的问题。
研究人员选择了四个强大的开源LLMs:Llama3-70B-Instruct、Qwen2-72B-Instruct、Yi-1.5-34B-Chat和Mixtral-8×22BInstruct(gpt-4o),并要求模型在没有图像的情况下回答MMMU问题;即使模型表明需要视觉输入,也要求模型提供答案。
对每个模型重复上述过程十次,如果某个模型能够正确回答一个问题超过五次,就可以认为这个问题是「纯文本可回答的」,排除掉三个模型都可回答的问题。
然后从剩余的问题池中,在30个主题下,每个主题随机抽取60个问题,总计1800个问题。
2. 增加候选选项
为了防止模型根据问题和候选项之间的关联来回答问题,研究人员将问题的候选项从四个增加到十个,使模型更难蒙对。
在增加选项的过程中,专家还会对原始的标注问题进行审查,以确保问题与图像的相关性,并排除了缺乏明确联系或连贯性的问题,筛选出了70个问题。
3. 通过仅视觉输入设置增强评估
为了进一步挑战模型的多模态理解,研究人员在MMMU-Pro中引入了纯视觉输入设置,将问题嵌入到屏幕截图或照片中。
人类标注人员需要在模拟显示环境中手动捕获照片和屏幕截图,图片涉及不同的背景、字体样式和字体大小,可以覆盖现实世界条件的多样性。
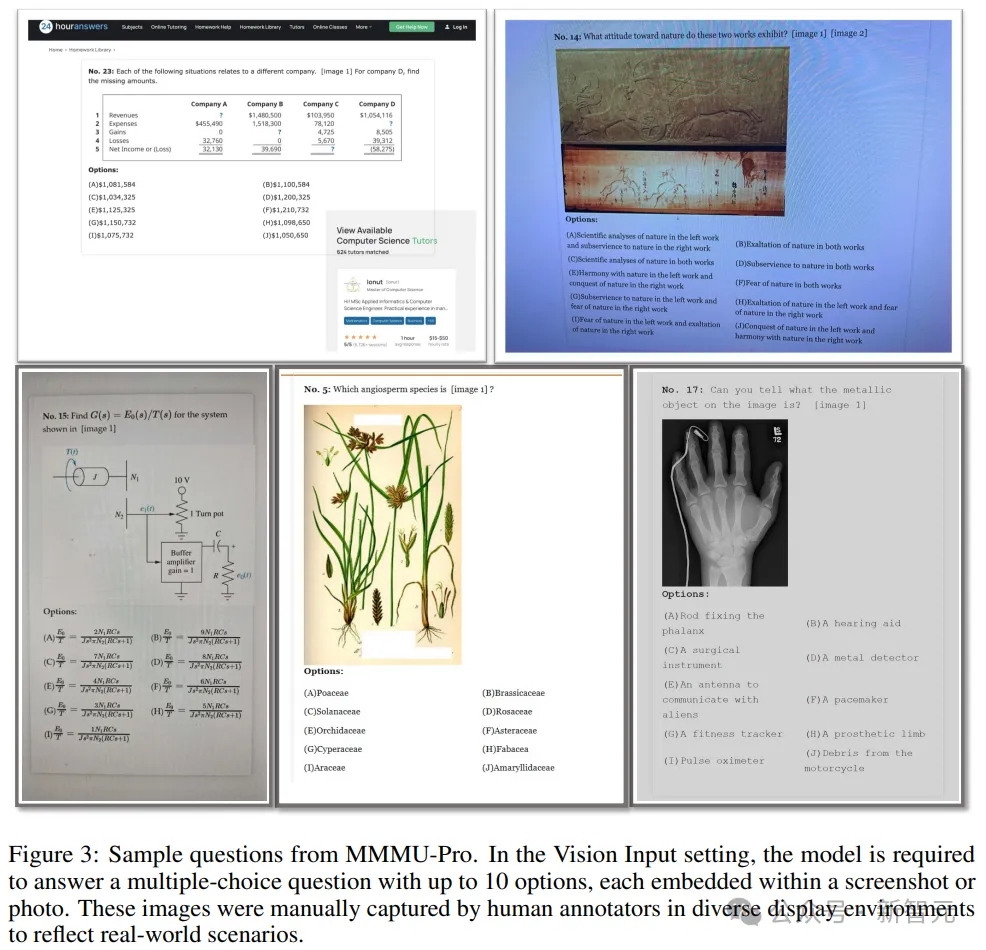
最终总共获得了3460个问题,其中1730个样本是标准格式 ,另外1730个是屏幕截图或照片形式。
研究人员用到的基线模型包括:
1. 闭源模型(Proprietary Models):GPT-4o(0513)和GPT-4o mini,Claude 3.5 Sonnet,以及Gemini 1.5 Pro(0801和0523版本),代表了多模态模型能力的最前沿。
2. 开源模型:InternVL2(8B、40B和Llama3-76B版本)、LLaVA(OneVision-7B、OneVision-72B和各种NeXT版本)、VILA-1.5-40B、MiniCPM-V2.6、Phi-3.5-Vision和Idefics3-8B-Llama3
研究人员在三种不同的测试环境下对模型进行评估:(1)4个选项的标准设置、10个选项下的性能和(3)纯视觉输入,其中(2)和(3)的平均分作为MMMU-Pro的总体性能得分。
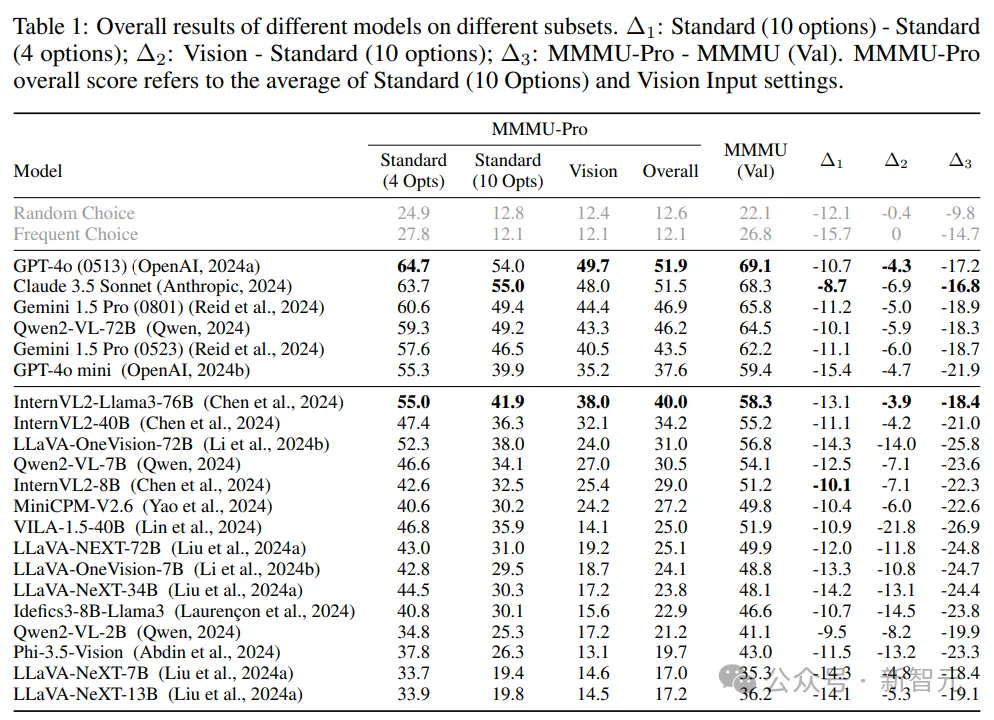
增加候选选项的影响
从4个候选选项增加到10个(∆1)对所有模型的性能都有明显的下降,GPT-4o(0513)的准确率下降了10.7%,从64.7%降至54.0%,表明增加选项数量可以有效降低了模型猜测正确答案的可能性,迫使模型更深入地理解和处理多模态内容。
纯视觉设置的影响
GPT-4o(0513)在纯视觉设置中的准确率又下降了4.3%,而LLaVA-OneVision-72B的准确率大幅下降了14.0%,表明纯视觉设置确实能考验出模型整合视觉和文本信息的能力。
对MMMU-Pro的综合影响
总体的性能差异∆3代表MMMU-Pro与MMMU(验证集)之间的差异,可以看到Gemini 1.5 Pro(0801)和Claude 3.5 Sonnet模型分别出现了18.9%和16.8%的下降,而VILA-1.5-40B等模型的下降的更多,达到了26.9%。
全面的准确率显著降低表明,MMMU-Pro成功地降低了模型在原始基准测试中可能利用的捷径和猜测策略。
研究人员探讨了光学字符识别(OCR)提示是否有助于提高MMMU-Pro仅视觉输入设置中的性能。
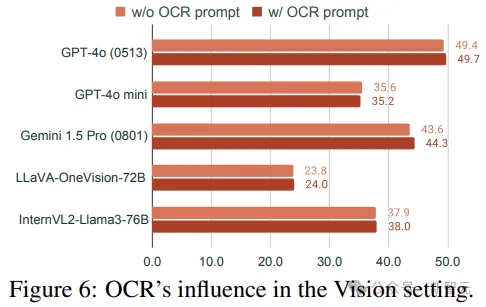
OCR提示明确要求模型写出图像中的问题文本,不过,在评估的模型中,包含OCR提示并没有显著改变性能。

微小的性能差异表明,现有的模型已经能够从图像中提取和理解文本信息,即使没有明确的OCR提示也是如此。
当文本嵌入在图像中时,虽然显著增加了视觉输入的整体复杂性,但简单的OCR不足以解决MMMU-Pro仅视觉输入设置所提出的问题,模型不仅要识别和提取文本,还要理解其在图像中的上下文、与视觉元素的关系以及与当前问题的相关性。
在MMMU-Pro基准测试中,研究人员估了思维链(Chain of Thought,简称CoT)提示在提升智能体性能方面的有效性,包括标准设置和视觉输入设置。
结果显示,在这两种设置下,引入CoT提示都能够带来性能的提升,但不同智能体的性能提升幅度存在显著差异。
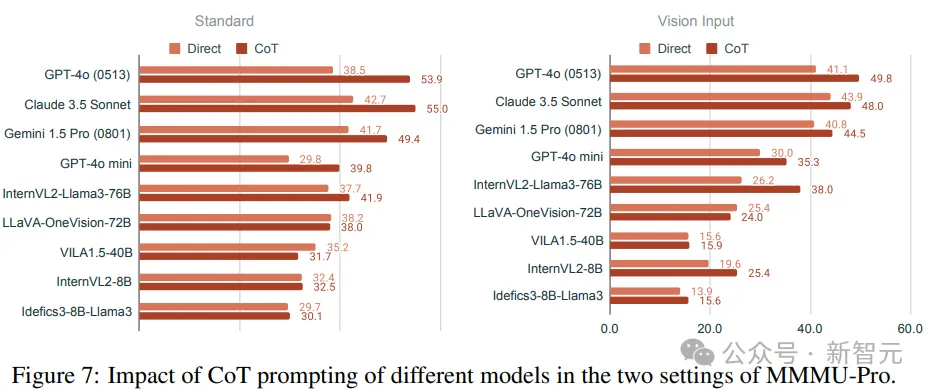
例如,Claude 3.5 Sonnet在标准设置中表现出显著的性能提升,准确率从42.7%提高到55.0%,相比之下,LLaVA-OneVision-72B只有很小的性能提升。
值得注意的是,一些智能体,比如VILA1.5-40B,在引入CoT提示后性能反而出现了下降,可能与模型在遵循指令方面的能力有关。如果模型无法准确地遵循指令,生成CoT解释就会变得更加困难。
此外,有些模型无法保持正确的回复格式,即存在所谓的「简化回复格式」问题。
文章来源于“新智元”,作者“新智元”




【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
