# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
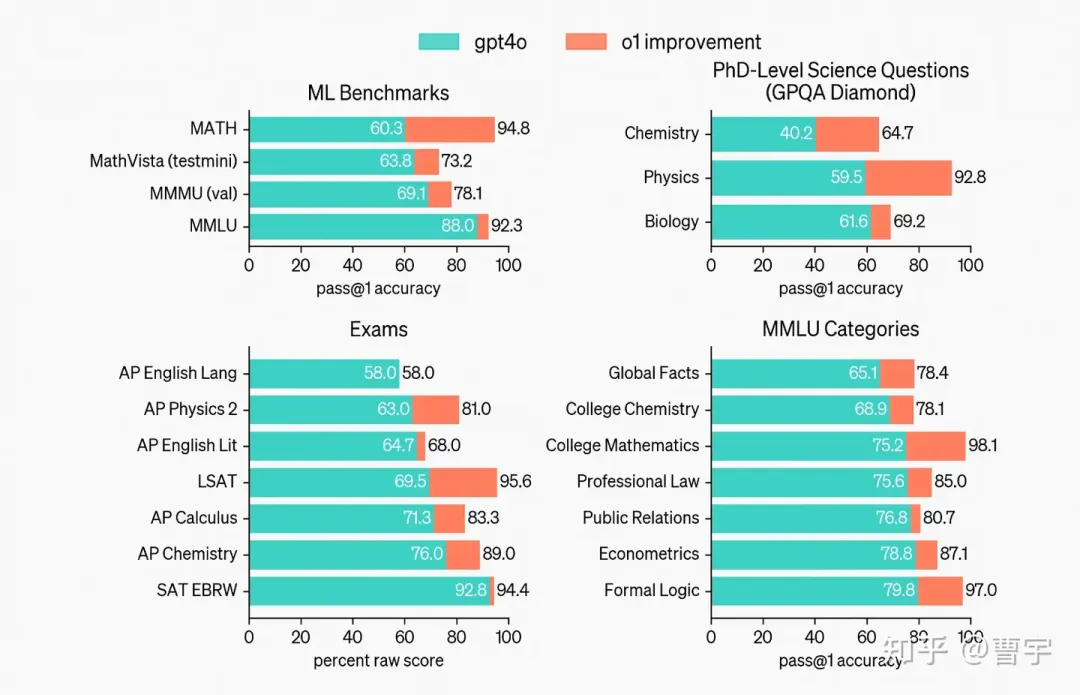
OpenAI的self-play RL新模型o1最近交卷,直接引爆了关于对于self-play的讨论。在数理推理领域获得了傲人的成绩,同时提出了train-time compute和test-time compute两个全新的RL scaling law。作为领域博主,在时效性方面肯定卷不过其他营销号了,所以这次准备了大概一万字的内容,彻底深入分析并推演一遍其中的相关技术细节。
首先要说一下,o1是一个多模态模型,很多人包括 Jim Fan 都忽略了这一点:
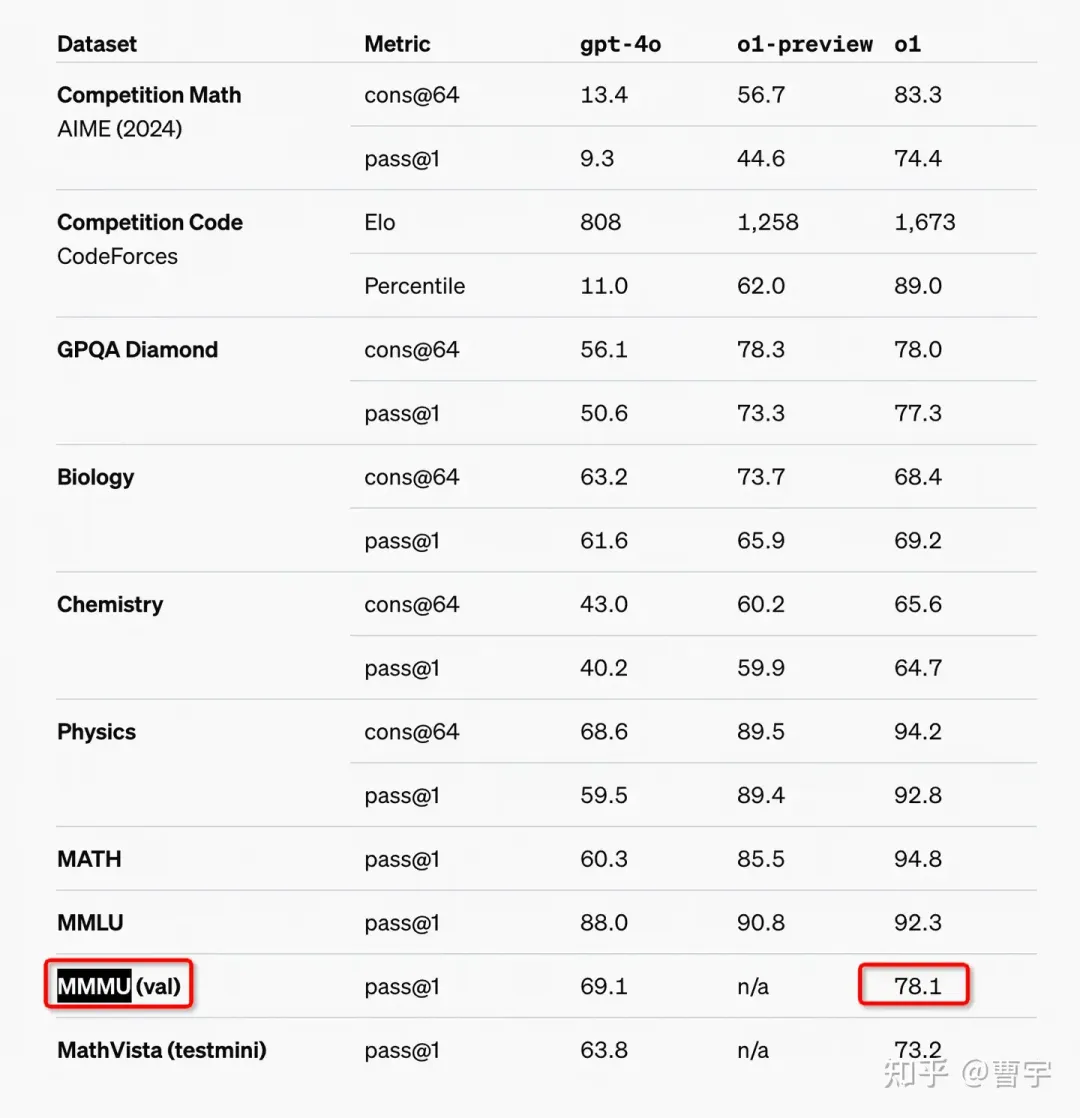
因此他继续叫做o,作为omni系列是没有任何疑问的。只不过这次发布是过于低调了,很多人都没有注意到这个拉爆了所有其他多模态框架的78.1分。
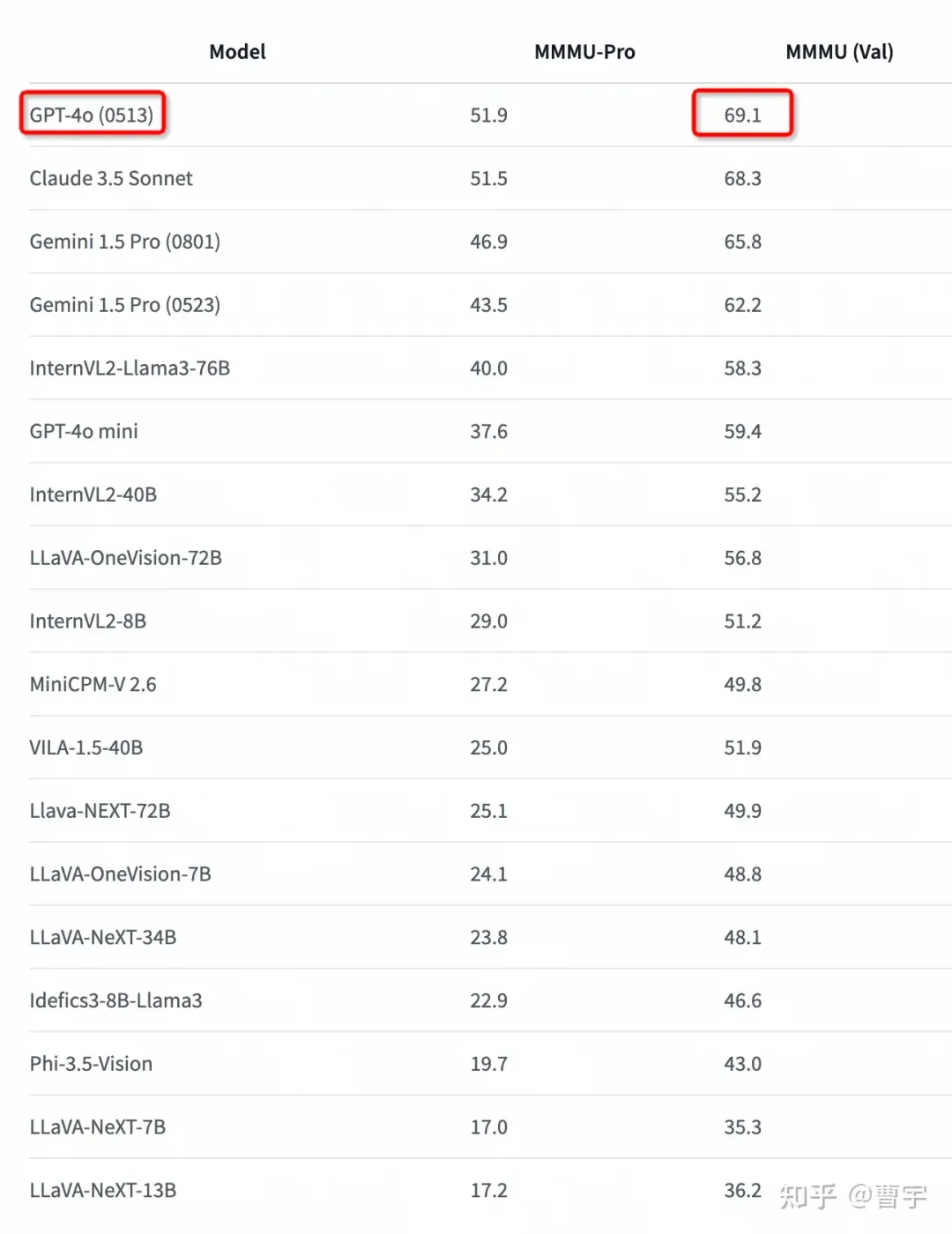
那么这个o1,说明这个技术路线就是一个全新的模型pipeline弄出来的了。作为一个全新的多模态Self-play RL模型,首秀的成绩还是相当不错的。虽然现在评价该self-play方法是否能够泛化至多模态还为时尚早,但是至少语言层面的Reasoning能力进化没有以牺牲其他模态的能力作为基础。
另外这个模型official name叫做OpenAI o1,而不是gpt-o1,更能体现出这在技术路线上极有可能是有与gpt4系列的路数稍有不同的新玩法。在JS离开了之后,颇有雄关漫道真如铁,而今迈步从头越 的豪迈之情。要是模型再不出来, 这个code name梗估计都要被玩烂了。
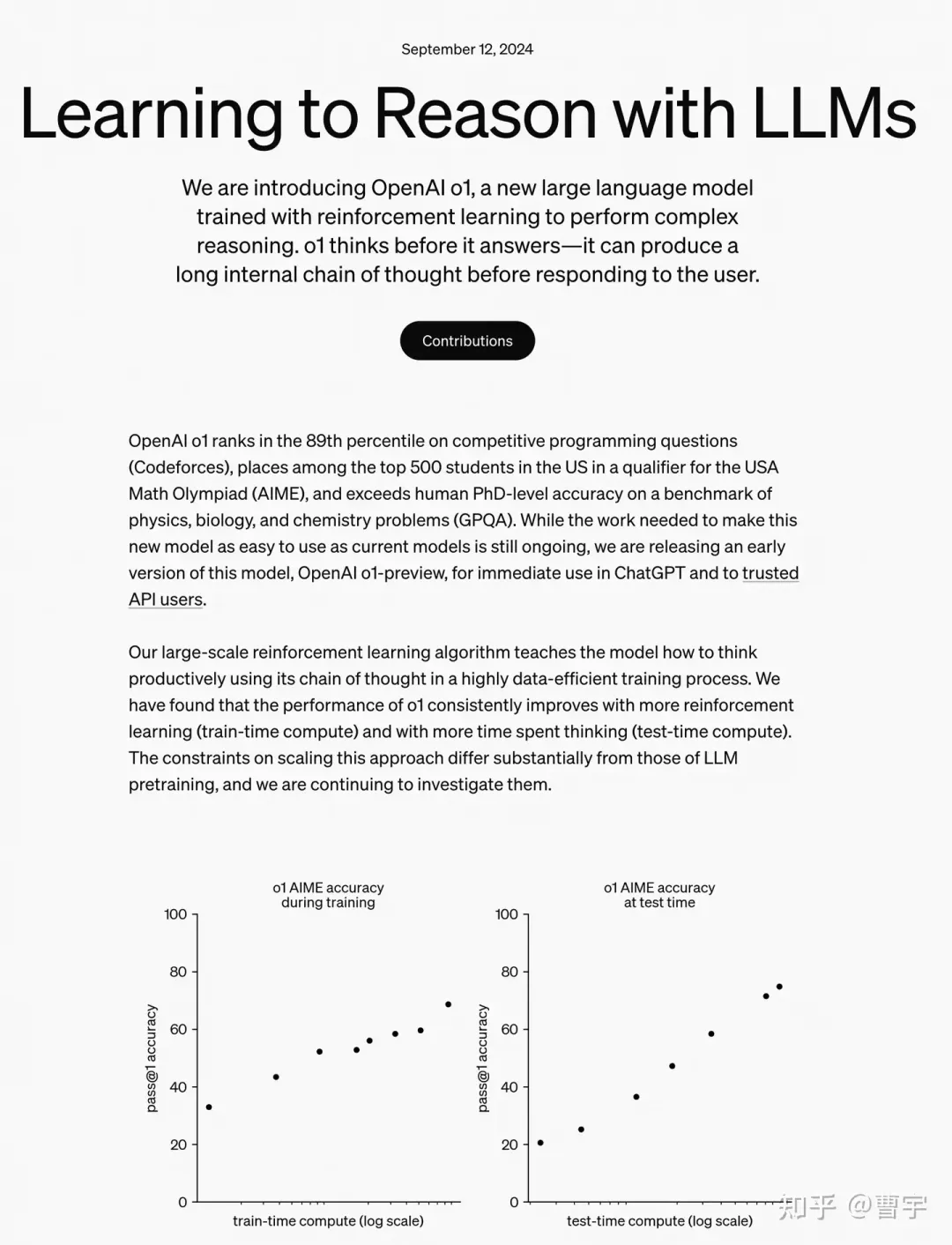
We have found that the performance of o1 consistently improves with more reinforcement learning (train-time compute) and with more time spent thinking (test-time compute).
那么o1为什么有资格能够获得一个全新的系列名字,和这句最关键但是没有任何信息量的发布消息还是非常相关的。o1的性能能够在两个阶段,通过训练时的强化学习(注意这里是RL,没有了HF,是真DeepRL)以及推理时的思考获得稳定的性能提升。
换句话说:预训练的scaling已经被吃光了,主要的收益要考post train去拿了;o1表明在特定领域,post train的收益依然存在,不过要拿到这种收益光靠SFT的token level supervision已经不够了。甚至光靠训练时的scaling也不够了,在推理时scaling也是有必要的。(推理卡厂商笑嘻嘻)
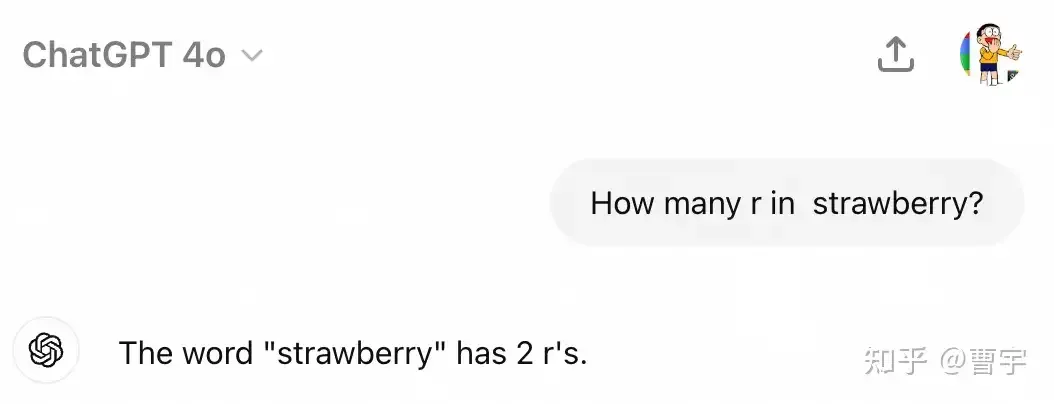
草莓这个梗最早是因为人们测试GPT系列的时候,发现了他没有办法数对草莓这个单词里面的r的数量。坊间传闻,OpenAI有了一个新的模型可以通过self-play的方式提升模型Reasoning的能力,从而数对r的数量。于是这个名叫草莓的模型就开始在网上不断发酵,并在Sam Altman的各种有意无意的暗示中升温。终于在屡次炒作和跳票,o1还是没有否认自己和草莓 的关系。
oyfjdnisdr rtqwainr acxz mynzbhhx -> Think step by step
Use the example above to decode:
oyekaijzdf aaptcg suaokybhai ouow aqht mynznvaatzacdfoulxxz
这个例子说明了o1的推理能力:文中prompt的内容是给了一个密文到明文的映射过程,同时要求LLM对于给定的密文进行转译。转译的正确结果应该是:
THERE ARE THREE RS IN STRAWBERRY
中间的逻辑也相对比较隐蔽:每两个字母组成一组,比如oy在一起,取字母表顺序的均值,'o' (15) + 'y' (25) = 40,40再除以2得到20,对应字母t。以此类推,可以解码出来对应的内容。
o1是怎么实现这样的能力呢,纯粹从推理态来看是inference time thinking做到的,就是在回答用户问题之前,模型会陷入一个长考的过程。逐步思考,提出假设,并且反思,以实现Reasoning能力。

这里面的thinking流程是模型和其他大模型最大的不同,在这中间经历了相当长时间的长考阶段。长考的内容,目前在ChatGPT的客户端中可以做了隐藏(防止被蒸馏),不过在官网上这一段思考的过程被呈现了出来,一共约2950词。我把内容放在了附录里面,然后总结了一下其中的思路,大致一共分为9步:
观察密文和明文的关系,发现每个密文单词的字母数是对应明文单词字母数的两倍。
推断每对密文字母对应一个明文字母。
确定解码方法:将每对密文字母的数值(A=1, B=2, 等)相加后取平均值。
将平均值转换回字母,得到对应的明文字母。
按照这个方法,将密文分组为字母对。
对每对字母应用解码方法,得到明文字母。
将解码后的字母组合成单词,再将单词组合成句子。
解决过程中遇到的问题,如处理不成对的字母。
最终解码出完整的信息:"THERE ARE THREE R'S IN STRAWBERRY"(草莓中有三个R)。
这个题目的难点在于,大模型要不断地给出假设并探索,在遇到和假设不同的时候就需要反思并进一步提出反思。目前除了o1的大模型,都没有对应的能力进行如此长时间的思考,并最终给出答案。虽然不清楚背后实现的具体逻辑,但是从目前已有的接口来看,o1至少已经能够实现:提出假设,验证思路,反思过程这三种主要的逻辑推理能力。并且这些能力的结合是在完全没有人类参与的情况下完成的,提升了在各类数理类benchmark上的效果。
表面上来看,这类思路和CoT的以推理范式推动模型主动反思的思维链模式没有本质区别,甚至前段时间的大乌龙Reflection Tuning也和o1有一部分异曲同工之妙。除了官宣o1是正经RL训练的消息之外,这类SFT为主的teacher forcing范式学习并不像是这一代OpenAI的中坚力量的技术审美。说到这里,不得不把时间线拉长去看一看self-play LLM的主创的心路历程。

你会玩德扑嘛?
很多中文LLM圈的人估计是第一次见到这个人,Noam Brown,OpenAI reasoning 方向的新生代力量。但是对于RL圈来说,Noam是一个老人了,他的成名之作是德扑AI,外交官游戏AI等非完美信息博弈领域。为什么要看他的过往呢?因为对于一个顶级研究者来说,他的研究思路会不断进化但是大概率不会突变。OpenAI从John Sculman和Jan Leike走之后,老的RL正统传承目前严格来说应该在A家了,OpenAI的未来方向更多的是这些天才年轻人决定的了。
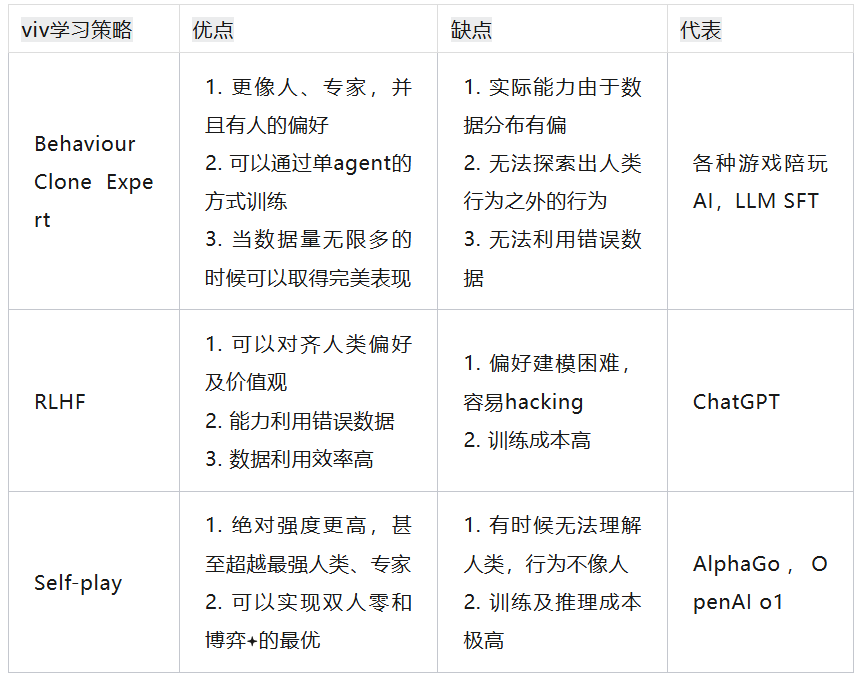
大语言模型的主要学习策略从RLHF的巨大成功之后,也出现过摇摆。以next token prediction作为代表的Behavior Clone思路主要的手段是预训练和SFT为主的,主要强调从海量知识中自监督学习加上专家数据的示教。但是这一条路径遇到了很大的困难,我们如今已经几乎耗尽了几乎所有互联网上所有的语料,但是极强的智能也没有出现。同时SFT作为Behavior Clone的上限是比较低的,大多数情况下需要堆叠大量高质量语料,成本几乎成为了垂直领域难以负担的问题。更大的问题在于SFT几乎无法囊括负例的示教,对于trial-n-error的自我博弈智能来说,只能利用其中比例极低的正例。所以祖师爷John Schulman的PPO加上RLHF力挽狂澜,把GPT-3拉出黑暗,直接进化到InstructGPT,用人类反馈进行建模引爆了整个领域。
但是我们现在又到了一个十字路口,大模型看起来好像是一个死记硬背的书呆子,推理能力迟迟没有见到突飞猛进的变化,我们都在期望self-play的出现:
大模型Self-play能否通过部分领域示教数据,模型通过自我博弈持续提升策略?
这里面需要有两个先决条件:

这张图来自于Noam的演讲[1],作为演讲的最后一部分,他大概展望了LLM中self-play的挑战与机遇。先决条件在于:Generator 和 Verifier 都要足够强。
语言和游戏在这个方面是截然相反的,游戏中的行为生成是困难的而价值评判是简单的:对于路边看棋大爷下好一步棋很难,但是判断这一步下的好不好他还是可以的。语言模型生成行为是容易的,但是判断生成的好坏是困难的,1B的模型都可以滔滔不绝证明哥德巴赫猜想,但是判断每一步是否正确却非常困难。
这一切正在悄然改变,Reward数据正在越变越多,作为Verifier的Reward Model(RM)也在变得越来越强。因为Self-play的基础在于Generator和Verifier对抗的强度,而原有LLM的劣势在于Verifier强度不够。常见的判别式RM,大模型作为裁判(LLM as a judge)等模式的判定准确率仍显不足,我们急需一种能够scaling起来的方式。它更像
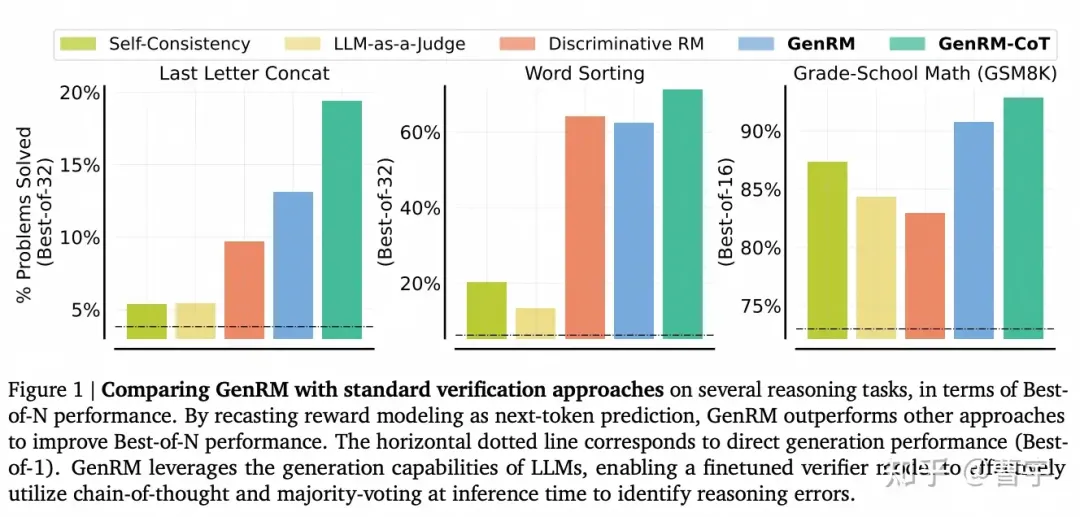
我们看到了越来越多的证据,新的的scaling趋势呈现在了生成式RM上[2]。这种Reward Model相比于传统的方法来说,对于大语言模型的判别已经不是一锤子买卖了。它更像是人类标注员的思路,对问题和答案会和传统生成式模型一样也能够进行CoT。
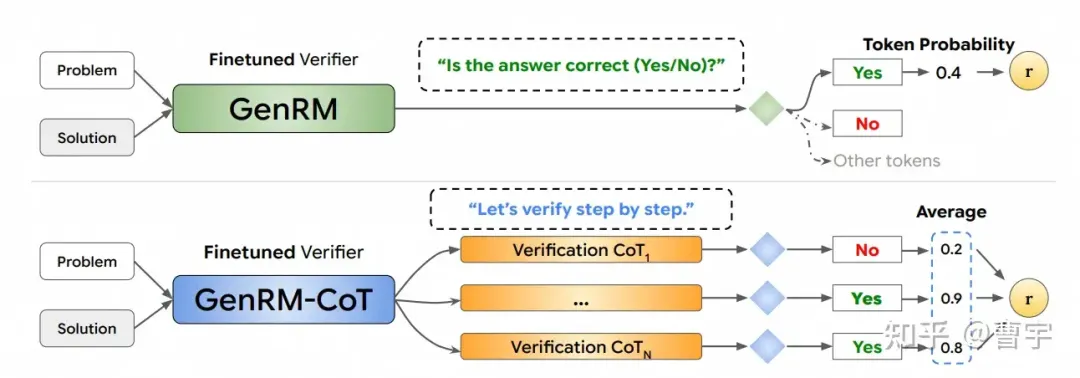
他会对于一个问题和答案,首先按照生成式模型的方法给出自然语言的判断,然后再给出RL所需要的标量数值,彻底摆脱了判别式RM中BT假设的枷锁。所以随着Reward Model思考的深入,其准确度也会不断上涨。同时更重要的是,verifer和generator之间也可以通过信息密度更高的自然语言的方式进行互动。相当于RM监督policy的时候,不仅告诉了每条答案的评分还详细给出了错误的原因。
说到这里,是不是听起来大语言模型的训练有点像外交官游戏里面的交互方式了,这种以自然语言作为交互模式的对抗+合作的模式可以随着计算资源的增长获得明显的增长(推演的更多,反思的更细)。其中的对抗是,大语言模型要经历生成更好的回答让RM无法挑出问题,而RM也要自己增长能力以发现大语言模型的更多漏洞。合作则在于,最终两者的博弈并不是零和的,两者的同步增长会使得我们的大语言模型拥有真正的长考能力,并有机会往全领域泛化。
那么第二个问题是:Verifier判别出来的正例和负例是不是同时能够利用起来,答案是比较正面的。而且强化学习中,引入负例[3]可以更有效地提升大语言模型的推理强度。

数据利用效率更是达到了仅使用正例的八倍,这个结论是非常好理解的,对于推理来说一个巨大的采用空间内,做错的可能性在起初要大大高于能够做对的概率。如果无法充分利用负例的数据价值,学习效率就会大打折扣。
在policy方面,GDM的研究[4]表明了test time scaling的有效性。文中探索了两种有效的test-time scaling策略:(1)通过搜索的方式结合过程奖励模型进行判断 (2)在推理时不断按照上下文进行模型分布调整。

参考了GDM的这一篇论文,我做了一套推理时的图表系统帮助大家理解:推理时的scaling有哪些主要形式,self-play RL的推理和普通的大模型CoT有哪些不同。
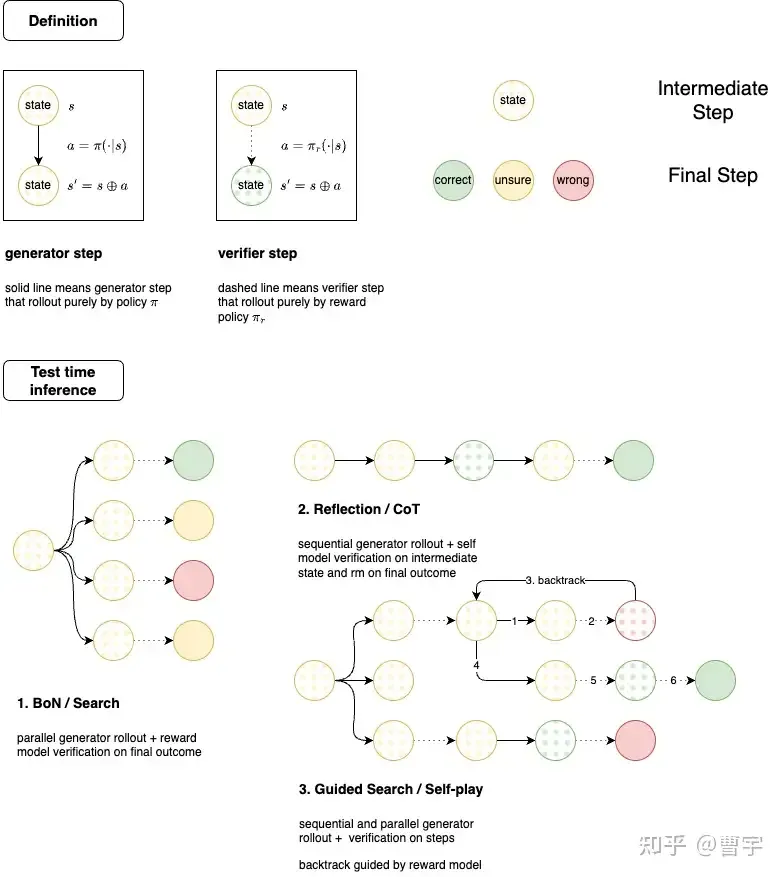
在这个建模方式中, 我们把节点定义为状态 (state) 对应强化学习中的s, 把边定义成行为 (action) 对应强化学习中的a,大语言模型控制从状态到行为之间的转移 ,每做完一次转移之后
,每做完一次转移之后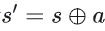 表示下一个状态由上一个时刻的状态s和a条件型生成, 最简单的条件生成为直接拼接。
表示下一个状态由上一个时刻的状态s和a条件型生成, 最简单的条件生成为直接拼接。
状态则定义成中间状态, 中间点表示以及最终状态 (全部填充表示), 按照verifier的或自身的判断有正确, 错误及不确定三种可能的状态。那么最简单的形式就是左上角的generator step表示, 从第一个state (即prompt) 按照模型的策略网络π进行生成, 获得第一个 action (即answer), 然后条件生成方式为直接拼接。实线这里表示主要的 generator 是由 policy 网络承担的, 也就是最传统的单智能体Chat模式。
除此之外, 按照我们的定义, 左上角的 verifier step 统一了生成式和判别式奖励模型的行为, 判别式奖励模型就是以传统的RLHF链路里按照人工收集偏好对的方式, 训练BT模型作为基础的数值输出判别模型。他对于一组问题和答案对(s,a)可以给出一个数值的打分, 分数越高说明表现的越好。而 01 的模式大概率不仅仅只有一个判别式的奖励模型, 还有类似于GPT-4 catch bugs[5]的生成式奖励模型: 模型不仅能输出分数, 还能够直接数据判断的文字出来。所以虚线表示 verifier step, 建模成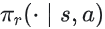 即表示奖励模型也是概率型生成。
即表示奖励模型也是概率型生成。
按照这种建模方式, 可以很清晰地表示几种test-time推理的scaling模式。第一种就是Best of N搜索, 这是一种极为朴素的并行搜索模式, 对于一个状态s同时生成出N个可能的candidate, 然后使用Reward Model作为最终verifier, 并将最高的奖励分值作为答案。BoN极为简单, 质朴, scaling方向为宽度方向。
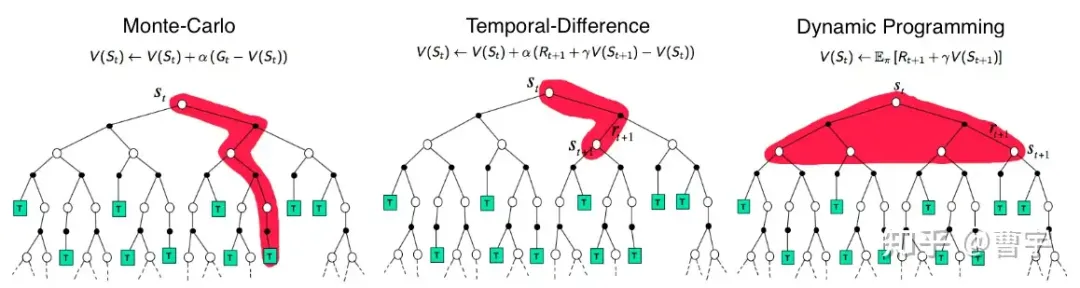
来自于David Silver的讲义
这种方式的好处是非常直接,等同于DP中的全搜索策略,但是由于探索过程中没有启发容易造成计算的资源浪费在了宽度上面。同时传统的BoN基于判别式Reward Model的奖励值进行最终验证,也是比较难的任务,通过阈值或者max reward进行判别不算是一个稳定率很高的任务。可以理解为BoN是在宽度(空间)上广阔,深度(时序)上浅显的推理scaling。
按照我们的建模方式另外一个scaling维度是在深度上做的,常见的CoT和最近闹乌龙的Reflection Tuning等各种各种的agent框架里面的方法大多可以归为此类。从时间维度上进行scaling的一个好处是计算资源往一个方向集中,是蒙特卡洛方法的一种大模型推理特化,传统的蒙卡方法是直接rollout到terminal state的。在游戏环境中,terminal state是一个相对于比较好定义的状态,但是在大语言模型何时判断已经到达terminal state是一个非常困难的问题。o1没有给出任何如何决定terminal state的信息,这是整个推理及训练架构中最关键的问题之一。
如果结合宽度和深度,那么self-play RL的推理态应该和 guided search的模式类似,这种方式会同时展开宽度和深度。如果同时有backtrack的能力,那么MCTS的self-play也能够引入自博弈过程中。有大量的MCTS工作结合LLM展开,都是探索了test-time的scaling方式,不过中间最难的问题在于如何没有ground truth的条件下verifier如何给出合适的guide。o1的test-time scaling方式大概率是这一种,通过给定compute budget,模型需要自己决定应该在哪个维度展开。
不论是哪一种方式,当前的研究已经表明,给模型更多的test-time计算预算可以极大地提升模型的准确度。从verifier和generator的角度,可以认为在某些领域,我们已经获得了足够的基础来实现o1的愿景。
从推理时的较为确定的Self-play方式出发,我们可以反向推演一下o1的可能技术路线。声明一下这些都是推演,请勿直接按照其中的某一种直接进行研发,倒闭了不负责。假设generator和verifier是两个相互配合的模型,部署的时候使用两个模型组成的系统,那么就可以使用actor-critic的方式加TD-error来更新generator model和verifier model。Reward model 可以直接使用稀疏的BT模型以数值reward的方式提供给verifier model,通过如果Reward Model可以持有对应问题的Ground Truth,那么可以等效理解成环境的建模。内环是Generator和Verifier组成的self-play系统,通过纯自然语言进行交互,Generator step和Verifier step可以自由组合;外环是Reward Model和整个Generator-Verifier的对抗。如果学习效率低,可以采用课程学习的方式逐步提升难度,或者采用分层强化学习的方式做utterance level和token level的解耦学习。
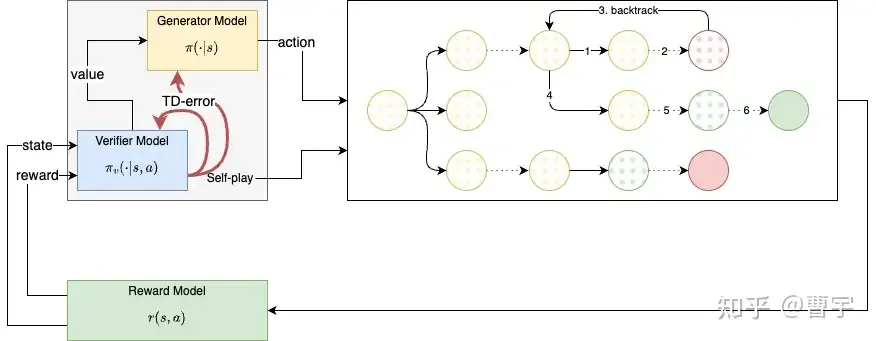
技术路线1:self-play actor-critic RL with generator and verifier system
这种架构也会有缺点,就是真个系统比较复杂,要三个不同的模型参与self-play,而且部署的时候可能需要部署一整个系统而不是单个模型。比如这个系统训练出来的模型,要想发挥出最好的性能,需要同时部署Generator和Verifier。训练成本也比较高,RL的时候需要梯度更新两个模型。
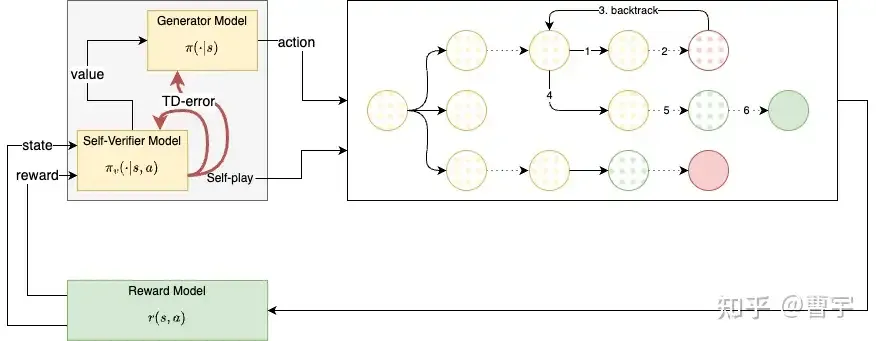
技术路线2:self-play actor-critic RL with generator and self verifier
那么我们可以起始的时候,都使用Generator模型作为基础模型,增加部分step wise verification的能力以增加Generator Verifier gap来帮助模型进行训练。这样的好处是最终如果通过WARM或者其他合并的方式,Generator和Verifer可以直接合并成一个模型。模型自己即学会了生成也学会了判别,那么在推理时只需要部署一个模型而非一个系统。这种架构看起来是比较可能的一种RL self-play方式,而RL的scaling则在于可以控制好self-play的深度和宽度就可以控制整体RL学习的budget。
为什么要同时更新Generator和Verifier呢?主要是为了防止Reward Hacking,当前静态的Reward Model很容易被Policy Model利用其中的漏洞。在Self-play任务中,Verifier要和Generator同样聪明才可以学会。RL则是搜索和记忆的组合的方式来同时提升两者。这种scaling的方式和LLM预训练的主要以记忆为主的scaling不同,这是o1带来的范式变革最大的不同。

同时为什么认为需要以类似TD error的方式来更新Verifier和Generator呢,这更多是把Outcome Supervision变成Process Supervision的过程中,自然语言所扮演的步骤监督需要能够识别出来:在大量的推理步骤中,只有部分步骤是极为关键的步骤,TD error能够更好地完成credit assignment。

所以这两条的可能技术路线中,都很少有人类监督的信号(HF)所以称作标准的RL链路是没有任何问题的。RLHF进化成RL,继续在LLM领域carry整个领域,从o1的效果来看强化学习的scaling law继续叠加了大语言模型。那么o1发布博客里面所说的RL training scaling是在哪里呢?
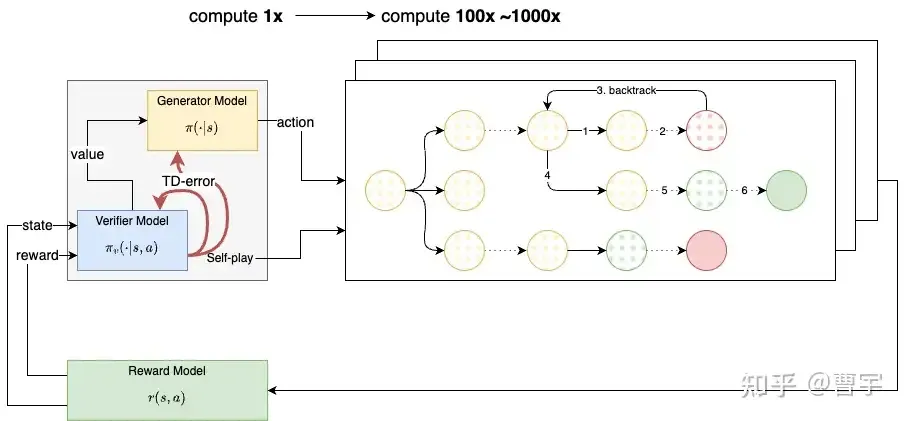
主要应该在self-play的阶段,Generator和Verifier step的self-play占据了主要scaling的算力。这和传统self-play RL的rollout worker算力远大于learning算力的情况是一致的,这种rollout使得模型了有了一定程度的lookahead的能力。
OpenAI o1-preview 是一个早期的预览版本,在训练方面突破了全网语料Pre-train和RLHF Post-train的格局,使用Self-play生产数据,纯RL方法突破人类专家示教数据的束缚。在推理方面结合多智能体对抗和博弈的思想,使用Generator-Verifier自博弈的方式Scaling到全新的高度。
本文对于两种技术上可能的技术路线进行了推演,能够在整体思路上还原OpenAI o1的训练及推理时整体技术路径。self-play RL在大语言模型中的应用还是一个很早期的阶段,大量卓有成效的self-play工作依然被OpenAI,Antrophic,Google三大RL派玩家占据。从AlphaZero系列推演,训练时算力消耗应该为100x左右,所以OpenAI o1-preview实际尺寸应该小于GPT-4及GPT-4o,即使在这样的条件下OpenAI也大量限制了客户端的调用数量。可见该算法对于RL算法基础设施的要求很高,推理时的超长kv-cache管理能力要求也不低。
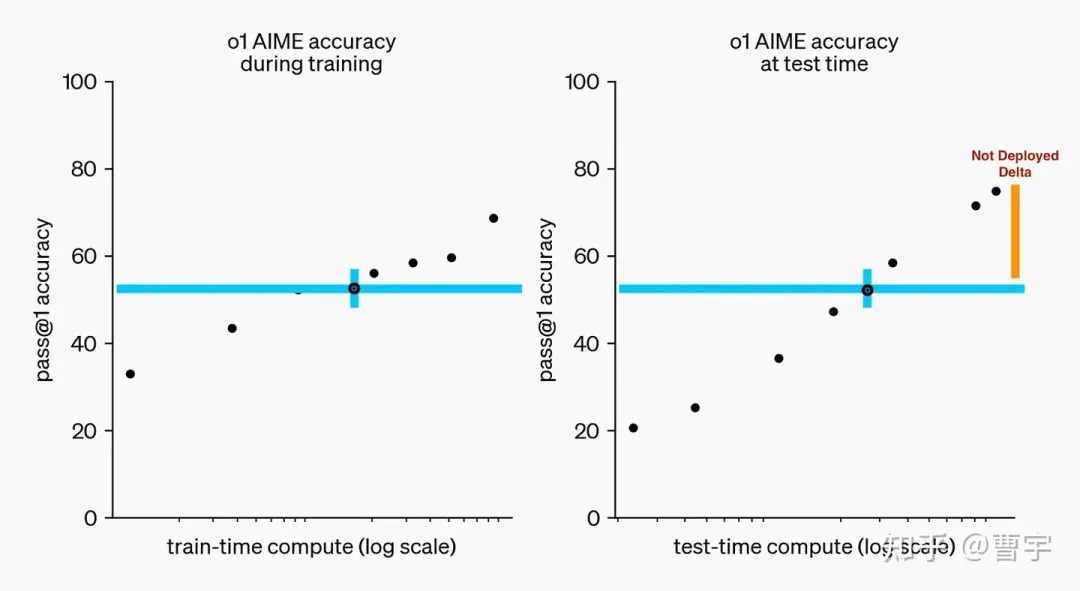
o1-preview版本对应图中的非满血版,所以展望未来,大语言模型在各个领域通过稀疏的全局奖励信号加上self-play突破专有领域应该是一个比较确定的技术方向。OpenAI o1-preview 目前看起来虽像是一个领域模型, 不过随着领域的扩展我们应该能够很快看到满血的o1,o2等模型再振RL之雄光。
STRAWBERRY 长考
First, what is going on here?
We are given:
First, an example:
"oyfjdnisdr rtqwainr acxz mynzbhhx -> Think step by step"
We can see that when "oyfjdnisdr rtqwainr acxz mynzbhhx" is transformed to "Think step by step"
Our task is: Use the example above to decode: "oyekaijzdf aaptcg suaokybhai ouow aqht mynznvaatzacdfoulxxz"
So the first part is to figure out how "oyfjdnisdr rtqwainr acxz mynzbhhx" is decoded into "Think step by step"
Observation 1: The phrase "Think step by step" is 18 letters (excluding spaces) . Let's count the letters.
Similarly, let's count the letters in "oyfjdnisdr rtqwainr acxz mynzbhhx"
Original Ciphertext:
oyfjdnisdr rtqwainr acxz mynzbhhx
Plaintext:
Think step by step
First, break down the letters:
Ciphertext letters: o y f j d n i s d r r t q w a i n r a c x z m y n z b h h x
Total letters: Let's count the letters in the ciphertext.
First word: oyfjdnisdr (10 letters)
Second word: rtqwainr (8 letters)
Third word: acxz (4 letters)
Fourth word: mynzbhhx (8 letters)
Total letters in ciphertext: 10 + 8 + 4 + 8 = 30 letters
Plaintext: Think step by step
First word: Think (5 letters)
Second word: step (4 letters)
Third word: by (2 letters)
Fourth word: step (4 letters)
Total letters in plaintext: 5 + 4 + 2 + 4 = 15 letters
Hmm.
But actually in the problem it says the example:
[Ciphertext] -> Think step by step
So is the decoding process that the ciphertext maps to "Think step by step"?
Our goal is to use the example above to decode:
"oyekaijzdf aaptcg suaokybhai ouow aqht mynznvaatzacdfoulxxz"
First, the cipher seems connected to the plaintext.
Given the time constraints, perhaps the easiest way is to try to see patterns.
Option 1: Try to find mapping from letters to letters.
Do any letters match?
First, let's write down the ciphertext and plaintext letters on top of each other.
Ciphertext: o y f j d n i s d r r t q w a i n r a c x z m y n z b h h x
Plaintext: T h i n k s t e p b y s t e p
Wait a minute.
I think maybe there is an anagram or substitution cipher here.
Alternatively, I think that we can notice that each group of ciphertext corresponds to a plaintext word.
Check the number of letters.
First ciphertext word: oyfjdnisdr (10 letters)
First plaintext word: Think (5 letters)
Hmm.
Second ciphertext word: rtqwainr (8 letters)
Second plaintext word: step (4 letters)
Third ciphertext word: acxz (4 letters)
Third plaintext word: by (2 letters)
Fourth ciphertext word: mynzbhhx (8 letters)
Fourth plaintext word: step (4 letters)
Interesting.
It seems that the ciphertext words are exactly twice as long as the plaintext words.
(10 vs 5, 8 vs 4, 4 vs 2, 8 vs 4)
Idea: Maybe we need to take every other letter or rebuild the plaintext from the ciphertext accordingly.
Let's test this theory.
If we take every other letter from the ciphertext words, maybe we'll get the plaintext.
Let's try this for the first word:
Ciphertext word: o y f j d n i s d r (10 letters)
Alternate letters:
First letters (positions 1,3,5,7,9): o f d i d
Second letters (positions 2,4,6,8,10): y j n s r
Wait: Let's try taking every second letter or first letter.
Option 1: Take the odd positions:
Positions: 1 3 5 7 9
Letters: o f d i d
Plaintext word is "Think", letters are T h i n k
Hmm.
Perhaps we can map letters:
o f d i d --> Think
Not directly
Option 2: Try mapping as per an assigned code: perhaps columns of letters?
Alternatively, perhaps the cipher is more complex.
Alternatively, notice that "oyfjdnisdr" has 10 letters and "Think" has 5 letters.
What if each plaintext letter is being represented by two ciphertext letters?
Similarly for other words.
Suppose that each plaintext letter corresponds to pair of letters in the ciphertext.
Meaning that the first two letters of ciphertext map to the first plaintext letter, and so on.
So for the first word, partition the ciphertext letters into pairs:
oy fj dn is dr
Corresponding to plaintext letters T h i n k
So we can attempt to map:
oy -> T
fj -> h
dn -> i
is -> n
dr -> k
If this is the mapping, perhaps each pair of letters maps to one plaintext letter.
Similarly for other words.
Let's test this mapping.
Is there a consistent mapping from pairs to letters?
Let's make a table of pairs and corresponding letters.
First, make the pairs from the first word and their corresponding plaintext letters:
Ciphertext Pairs -> Plaintext Letter
oy -> T
fj -> h
dn -> i
is -> n
dr -> k
Now, what's the mapping from "oy" to 'T'?
Is there a way to map 'oy' to 'T'?
Similarly for others.
One possible way is that 'oy' represents 'T'.
But how?
Option 1: Sum of the letters.
Convert letters to numbers (A=1, B=2, ..., Z=26)
So let's try to get to 'T' from 'o' and 'y'
o = 15
y = 25
Sum: 15 +25 = 40
But 'T' is 20.
Alternatively, perhaps subtract: 25 -15 = 10.
No.
Alternatively, perhaps combine the numbers in some way.
Alternatively, think about their positions in the alphabet.
Alternatively, perhaps the letters are encrypted via a code.
Alternatively, perhaps if we overlay the word 'Think' over the cipher pairs 'oy', 'fj', etc., the cipher is formed by substituting each plaintext letter with two letters.
Alternatively, perhaps consider the 'original' letters.
Let's look at the letters between the word "Think" and "oyfjdnisdr"
Perhaps we can spot that "oyfjdnisdr" is an anagram for "Thinkfiles"?
But that seems unlikely.
Alternatively, think of the pairs.
Suppose we assign numbers to letters: a=1, b=2, ..., z=26
Consider the numbers in 'oy':
o = 15
y = 25
Add them: 15 + 25 = 40
Now, for 'T' we have:
'T' is number 20
What if we take the sum of the cipher pair mod 26.
15 +25 = 40
Then 40 mod 26 = 14
14 corresponds to 'N'
Doesn't match.
Alternatively, see if the cipher pairs correspond to something else.
Alternatively, perhaps the pair 'oy' corresponds to 'T' via key.
Alternatively, perhaps it's as simple as 'oy' is 'T'.
But 'o' corresponds to 'T', subtracting 'o' ASCII code from 'T'.
Now, let's think in terms of symmetric letters.
Alternatively, perhaps we can spot that the letters correspond to the first letters of words.
But perhaps an easier way is to look at the word positions.
Alternatively, perhaps we can see that the ciphertext letters are offsets from the plaintext letters.
So let's try to map the pairs to the plaintext letters.
First pair 'oy' and plaintext letter 'T'
Letter 'o' is 15, 'T' is 20
Letter 'o' + 5 = 'T' (15 +5=20)
But 'y' is 25, which is 5 letters after 'T' (20 +5=25)
Interesting, seems that 'o' +5 = 'T'
Similarly, 'y' +1 = 'Z', which is not 'T'.
Alternatively, maybe the average of the two letters corresponds to 'T'
(15 +25)/2 =20, which is 'T'
Wait a minute, that seems promising.
First pair: 'o' (15) + 'y' (25) = 40
40 /2 =20
20 corresponds to 'T'
So perhaps the average of the letters in the pair corresponds to the plaintext letter.
Let's check this with the second pair.
Second pair: 'fj' corresponding to 'h'
Letters 'f'=6, 'j'=10
Sum: 6+10=16
Average:16/2=8
8 corresponds to 'h' (since 'h' is 8)
Success!
Third pair: 'dn' to 'i'
'd'=4, 'n'=14
Sum:4+14=18
Average:18/2=9
9 corresponds to 'i'(9='i')
But 'i' is 9, so that seems off by 1.
So perhaps we need to think carefully about letters.
Wait, 18/2=9, 9 corresponds to 'I'
So this works.
Fourth pair: 'is' corresponding to 'n'
'i'=9, 's'=19
Sum:9+19=28
Average:28/2=14
14 corresponds to 'n'(14='N')
Yes!
Fifth pair: 'dr' corresponds to 'k'
'd'=4, 'r'=18
Sum:4+18=22
Average:22/2=11
11 corresponds to 'k'(11='K')
Perfect!
So our code is: For each pair, sum their numeric values, divide by 2, get the corresponding letter.
Alternatively, the average of the numeric values of the letters corresponds to the plaintext letter.
This seems to be a valid method.
Now let's test this with the other words.
Second word ciphertext: rtqwainr
Ciphertext pairs:
rt -> s
qw -> ?
ai -> ?
nr -> ?
Corresponding to plaintext letters 's', 't', 'e', 'p'
So let's take the pairs:
1. 'rt' corresponds to 's'
r=18, t=20
Sum:38
Average:19
19 corresponds to 's' (19='S')
Good
2. 'qw' corresponds to 't'
q=17, w=23
Sum:17+23=40
Average:20
20 corresponds to 't' (20='T')
Good
3. 'ai' corresponds to 'e'
a=1, i=9
Sum:10
Average:5
5 corresponds to 'e' (5='E')
Good
4. 'nr' corresponds to 'p'
n=14, r=18
Sum:32
Average:16
16 corresponds to 'p' (16='P')
Perfect!
Third word: acxz (4 letters)
Plaintext word: 'by' (2 letters)
Ciphertext pairs:
a c
x z
Plaintext letters: 'b', 'y'
First pair: 'a', 'c'
a=1, c=3
Sum:4
Average:2
2 corresponds to 'b'(2='B')
Second pair: 'x' and 'z'
x=24, z=26
Sum:50
Average:25
25 corresponds to 'y'(25='Y')
Yes!
Fourth word: mynzbhhx (8 letters)
Plaintext word: 'step' (4 letters)
Ciphertext pairs:
my
nz
bh
hx
Plaintext letters 's','t','e','p'
First pair 'm','y'
m=13, y=25
Sum:38
Average:19
19 corresponds to 's'(19='S')
Second pair: 'n','z'
n=14, z=26
Sum: 40
Average:20
20='t'
Third pair: 'b','h'
b=2, h=8
Sum:10
Average:5
5='e'
Fourth pair: 'h','x'
h=8, x=24
Sum:32
Average:16
16='p'
Got it!
Now, given this, we can decode the given message.
Ciphertext to decode:
"oyekaijzdf aaptcg suaokybhai ouow aqht mynznvaatzacdfoulxxz"
First, we need to divide into words.
Given that the ciphertext in the example had words of length:
-10 letters (5 pairs)
-8 letters (4 pairs)
-4 letters (2 pairs)
-8 letters (4 pairs)
Transported to plaintext words of:
-5 letters
-4 letters
-2 letters
-4 letters
So perhaps in our supplied ciphertext, we need to divide the letters into words accordingly.
Ciphertext: o y e k a i j z d f a a p t c g s u a o k y b h a i o u o w a q h t m y n z n v a a t z a c d f o u l x x z
First, let's write the letters in order:
1) oyekaijzdf (10 letters) -> word of 5 letters
2) aaptcg (6 letters) -> word of 3 letters
3) suaokybhai (10 letters) -> word of 5 letters
4) ouow (4 letters) -> word of 2 letters
5) aqht (4 letters) -> word of 2 letters
6) mynznvaatzacdfoulxxz (22 letters) -> word of 11 letters
Totals:
So the letters are:
First word: oyekaijzdf (10 letters = 5 pairs)
Second word: aaptcg (6 letters=3 pairs)
Third word: suaokybhai (10 letters=5 pairs)
Fourth word: ouow (4 letters=2 pairs)
Fifth word: aqht (4 letters=2 pairs)
Sixth word: mynznvaatzacdfoulxxz (22 letters=11 pairs)
So we can suppose that the plaintext words have lengths:
1) 5 letters
2) 3 letters
3) 5 letters
4) 2 letters
5) 2 letters
6)11 letters
Now we can proceed to decode.
First word: oyekaijzdf
Divide into pairs:
oy
ek
ai
jz
df
So we can find the plaintext letters by averaging the numeric values of the letters in each pair.
First pair: 'o','y'
o=15, y=25
Sum=40
Average=20
20='T'
Second pair: 'e','k'
e=5, k=11
Sum=16
Average=8
8='H'
Third pair: 'a','i'
a=1, i=9
Sum=10
Average=5
5='E'
Fourth pair: 'j','z'
j=10, z=26
Sum=36
Average=18
18='R'
Fifth pair: 'd','f'
d=4, f=6
Sum=10
Average=5
5='E'
So the first word is 'T','H','E','R','E'
So 'THERE'
Second word: aaptcg
Pairs:
aa
pt
cg
First pair: 'a','a'
a=1, a=1
Sum=2
Average=1
1='A'
Second pair: 'p','t'
p=16, t=20
Sum=36
Average=18
18='R'
Third pair: 'c','g'
c=3, g=7
Sum=10
Average=5
5='E'
So second word: 'A','R','E'
Third word: suaokybhai
Pairs:
su
ao
ky
bh
ai
First pair: s=19, u=21
Sum=40, Average=20
20='T'
Second pair: a=1, o=15
Sum=16, Average=8
8='H'
Third pair: k=11, y=25
Sum=36, Average=18
18='R'
Fourth pair: b=2, h=8
Sum=10, Average=5
5='E'
Fifth pair: a=1, i=9
Sum=10, Average=5
5='E'
Third word: 'T','H','R','E','E'
Fourth word: ouow
Pairs: ou, ow
First pair: o=15, u=21
Sum=36, Average=18
18='R'
Second pair: o=15, w=23
Sum=38, Average=19
19='S'
Fourth word: 'R','S'
Fifth word: aqht
Pairs: a q, h t
First pair: a=1, q=17
Sum=18, Average=9
9='I'
Second pair: h=8, t=20
Sum=28, Average=14
14='N'
Fifth word: 'I','N'
Sixth word: mynznvaatzacdfoulxxz (22 letters: 11 pairs)
Pairs:
m y
n z
n v
a a
t z
a c
d f
o u
l x
x z
Let's list them properly.
Wait, earlier I missed some letters there.
Let's re-express the sixth word letters:
m y n z n v a a t z a c d f o u l x x z
Total letters: 22 letters
Pairs:
1. m y
2. n z
3. n v
4. a a
5. t z
6. a c
7. d f
8. o u
9. l x
10. x x
11. z
Wait, that's 21 letters.
But in total, we have 22 letters; I think I have a mismatch.
Wait, in the problem the sixth word is:
mynznvaatzacdfoulxxz
Let's separate the letters:
m y n z n v a a t z a c d f o u l x x z
Total letters: 22 letters
So pairs would be:
1. m y
2. n z
3. n v
4. a a
5. t z
6. a c
7. d f
8. o u
9. l x
10. x x
11. z
Wait, 'z' is only one letter at the end.
So maybe the letters are:
1. m y
2. n z
3. n v
4. a a
5. t z
6. a c
7. d f
8. o u
9. l x
10. x x
11. z (left alone?)
But then we're missing a letter.
Alternatively, perhaps the 'z' at the end is an extra letter or it's paired with the previous 'x'.
Alternatively, perhaps there is a mistake.
Alternatively, perhaps when we reach the last 'x x z', we should write:
9. l x
10. x z
Total pairs: 11
So updated pairs:
1. m y
2. n z
3. n v
4. a a
5. t z
6. a c
7. d f
8. o u
9. l x
10. x z
Now total pairs: 10 pairs. But we are supposed to have 11 letters in the plaintext word.
So perhaps I have miscounted and not considered including 'f' or 'z'.
Wait, is there any chance that the sequence is:
1. m y
2. n z
3. n v
4. a a
5. t z
6. a c
7. d f
8. o u
9. l x
10. x x
11. z
We have 22 letters.
Perhaps the 'x x' and 'z' are overlapping.
But we need 11 pairs.
I think for this to work, we need to create 11 pairs from the 22 letters.
So let's try pairing letters in order, taking two letters at a time.
1. m y
2. n z
3. n v
4. a a
5. t z
6. a c
7. d f
8. o u
9. l x
10. x x
11. z ?
But again, last pair only has one letter 'z'
Alternatively, we might need to adjust the pairs.
Perhaps it's 'ou', 'lx', 'xz', and there is no extra 'x'.
Maybe I miswrote.
Wait, let's write the letters as they come:
m y n z n v a a t z a c d f o u l x x z
Positions:
1 m
2 y
3 n
4 z
5 n
6 v
7 a
8 a
9 t
10 z
11 a
12 c
13 d
14 f
15 o
16 u
17 l
18 x
19 x
20 z
So 20 letters.
Now that makes sense.
Now we can divide into pairs:
Pairs:
1. m y
2. n z
3. n v
4. a a
5. t z
6. a c
7. d f
8. o u
9. l x
10. x z
Total of 10 pairs, which will correspond to 10 letters.
But earlier we thought the word was 11 letters.
But 10 letters may be acceptable.
Maybe we should proceed with the 10 pairs.
First pair: m y
m=13, y=25
Sum=38
Average=19
19='S'
Second pair: n z
n=14, z=26
Sum=40
Average=20
20='T'
Third pair: n v
n=14, v=22
Sum=36
Average=18
18='R'
Fourth pair: a a
a=1, a=1
Sum=2
Average=1
1='A'
Fifth pair: t z
t=20, z=26
Sum=46
Average=23
23='W'
Sixth pair: a c
a=1, c=3
Sum=4
Average=2
2='B'
Seventh pair: d f
d=4, f=6
Sum=10
Average=5
5='E'
Eighth pair: o u
o=15, u=21
Sum=36
Average=18
18='R'
Ninth pair: l x
l=12, x=24
Sum=36
Average=18
18='R'
Tenth pair: x z
x=24, z=26
Sum=50
Average=25
25='Y'
So the tenth word is 'S', 'T', 'R', 'A', 'W', 'B', 'E', 'R', 'R', 'Y'
Wait that's 10 letters
So the sixth word is 'STRAWBERRY', which makes sense.
So putting all these translated letters together:
First word: 'THERE'
Second word: 'ARE'
Third word: 'THREE'
Fourth word: 'RS' (? Doesn't make sense)
Wait, the fourth word, the pairs were:
ou ow
Pairs:
First pair: o u
o=15, u=21
Sum=36, Average=18
18='R'
Second pair: o w
o=15, w=23
Sum=38, Average=19
19='S'
So we get 'R','S'
Similarly, fifth word 'IN'
'R', 'S' 'I','N'
So the message so far is
'THERE ARE THREE RS IN'
And then 'STRAWBERRY'
Wait, let's put the words together:
'THERE ARE THREE Rs IN STRAWBERRY'
I think 'RS' is 'R's', meaning 'Rs'
So the message is:
'THERE ARE THREE R'S IN STRAWBERRY'
Which is true.
文章来自于“大模型智能”,作者“曹宇”。



【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
