# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
自从ChatGPT引起的大模型进化至今,没有人怀疑LLM和其应用范式将会对人类产生极其重大的影响。
无论是大模型本身的chatbot,multi-agent,多模态对话,还是大火的人形机器人,都在行业巨头和资本的助推下,开始攻城略地。
2023开启的foundation model 投资,让国内的基础模型和清华系都得到了大量的资源倾斜。
2024年,大家又把名义重心放到了应用层上。但快两年过去,恶劣的外部环境,不清晰的商业化路径,判断力和现金源的缺失,资本的观望情绪已经使得国内的大模型应用投资乏善可陈
大量的套壳应用也是这个资金不足的现状的深刻反映。所以陷入了下面的死循环:
做最简单的事,挣最快的钱,只能内卷,导致整个生态/模式恶性循环。
2024年秋这个时间点,当大环境的冷,碰到了小环境的恶性循环。大家又开始审视,问题在哪里呢?
对于英伟达的过度依赖体现在了各个领域,CUDA十年如一日的迭代,预先定义了无数的标准,最佳实践,算子库,造就的护城河,已经不是一个单一的单位再造一套轮子就能解决的了。软件领域的正反馈增长,锁定效应,不是某个国家战略或企业能够改变的。实体的意志力能够推动和造势,却完不成逆势。
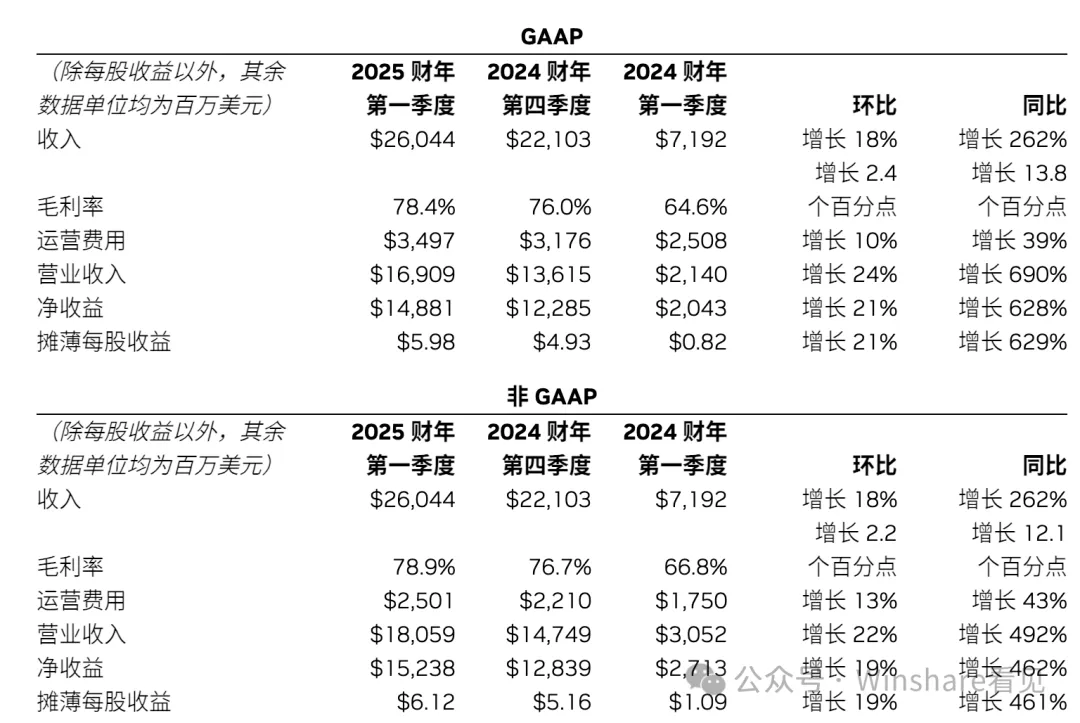
可以说风头正盛的nvidia正成为这个地球上最有价值的企业之一。但上游垄断对于整个市场来说一般不是什么好事情。就像日本对氢能源上游专利的垄断,使得后续产业入局的玩家讳莫如。而锂矿资源的分配均衡,也让EV市场发展了起来,反过来最近两三年中国对动力电池的话语权过重,又使得美欧开始对EV市场产生退缩。
我们可以用一个朴素的概念形容这个过程
单次推理用户价值:即平均来计算,你的一次推理能给客户带来多少价值
单次推理成本:即平均一次你生成的token count 计算下来的单价是多少
如果在单次推理成本上nvidia收走了绝大部分,电费又是一个部分,那留给其他部分的商业价值空间将会无比的小。
因为很朴素的道理,大模型应用的价值或者说利润来自于【单次推理用户价值】减去【单次推理成本】
基于这个极简的分析框架可以看到,nvidia的过于强大和垄断基本上没给下游留下什么商业空间了。
对整个生态来说这个高昂的成本支出项成为了整体大模型走向规模化应用的巨大限制。也是上游AI半导体设计制造厂商得到更大资源倾注的原因。
刚才我们提到了【单次推理用户价值】
这个字面意思很好理解的所以以不同的场景来看这个值,虽然很难绝对量化,但是可以以现有的经济结构和人类的需求层级在场景上做一个对比。
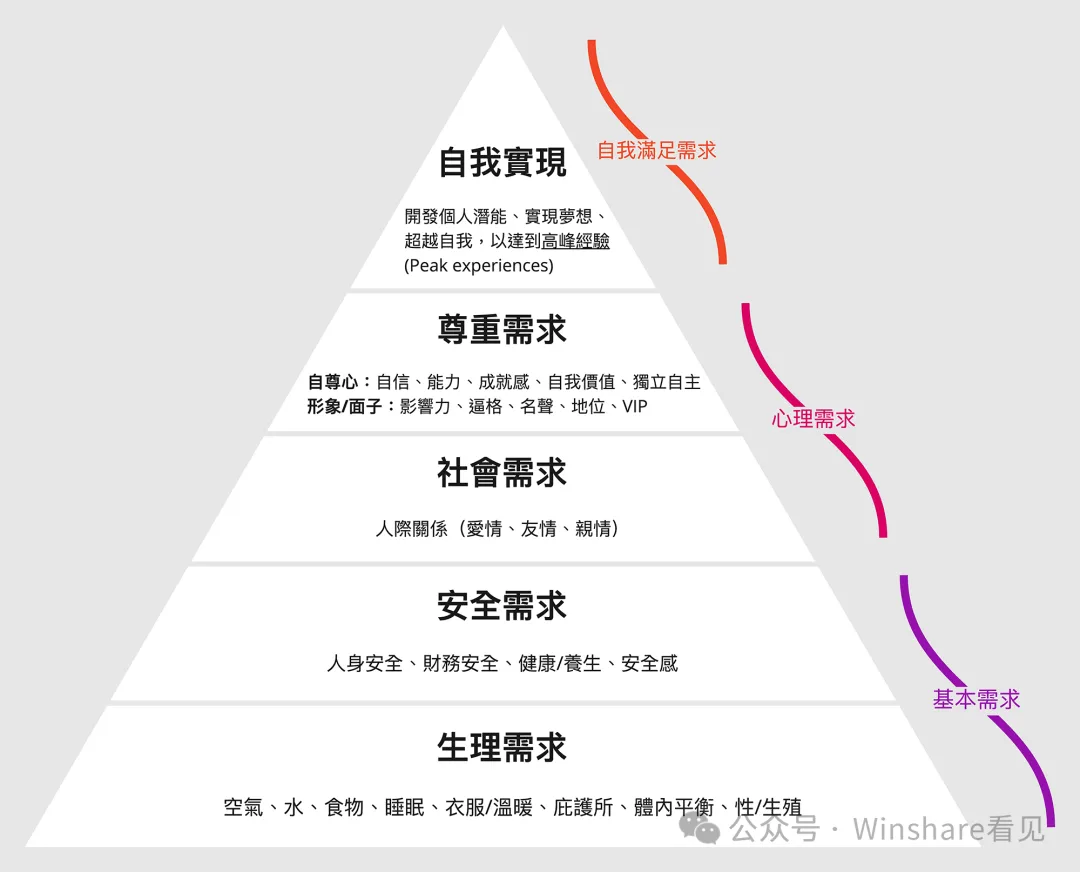
从马斯洛需求层级理论来看,大模型在各个层次上的应用都面临不同程度的问题:
在各个层次上的应用都面临着“单次推理用户价值”与“单次推理成本”之间的不平衡。
虽然从总量上看,
但我们忽略了一个重要的问题,在无法边际效应递减的情况下,有一个最重要的指标,客单价。
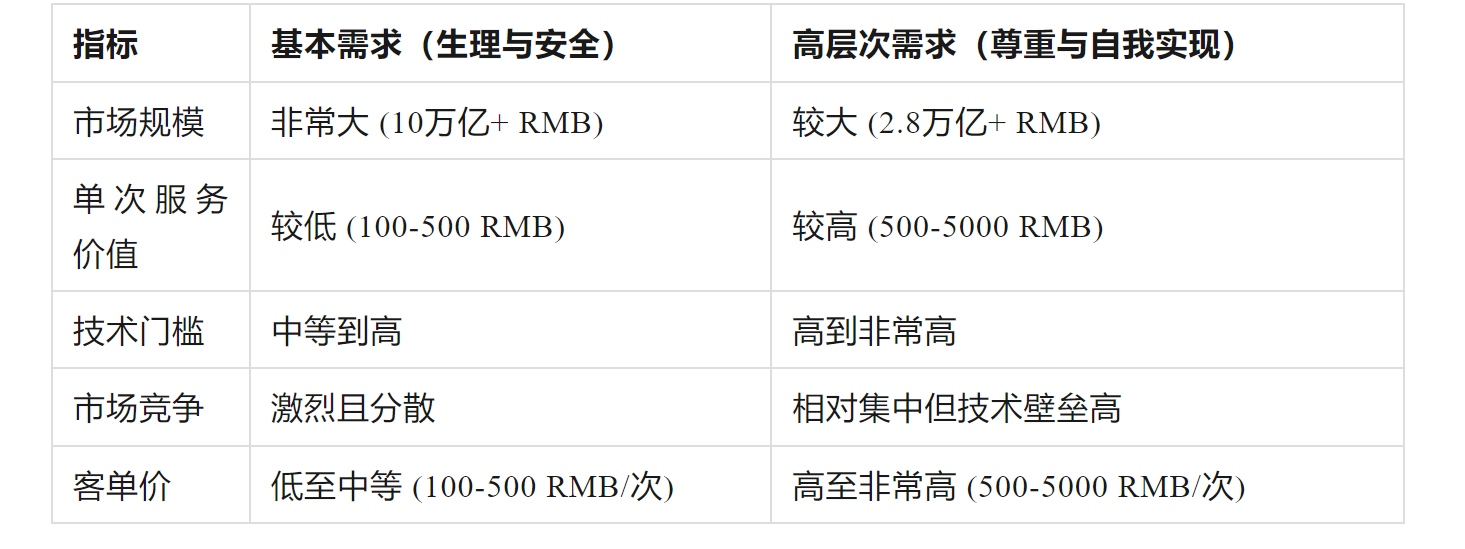
我们量化的来看,低层次的需求,根本支撑不了现在的大模型商用,而大模型的商用也根本不应该从低层次的需求开始。甚至不应该从中层次的需求开始。
站在这个角度看CharacterAI类应用他只是满足了中层偏下层需求,他们都不会是先发展起来的应用。
他们在这个时间点,根本就是和时间站在了对立面。
任何一项革命性的技术/产品理念在一开始都会显得高不成低不就,我们每个人的手上就有最好的例子

当移动互联网浪潮兴起之前,其实iPhone 类似的设备也已经层出不穷。诸如Palm,WindowsMobie PDA,塞班系统产品,甚至苹果自己就推出过类似的设备,也就是鲜为人知的Newton项目。
这些设备在当年受制于羸弱的Arm芯片,电阻触摸屏,以及内存/半导体元器件的尺寸的整体落后,体验十分的糟糕。相比成熟,耐用的诺基亚,摩托罗拉,产品显得毫无竞争力。
但时间到了2006年,一个技术的成熟和低成本化量产改变了一切,那就是看起来并不起眼的—电容式触摸屏技术。
相比电阻屏的低硬度,容易划伤,只能单点,响应速度低。电容触摸屏搭配康宁玻璃可以把表面硬度做到9H,并且可以实现多点,高刷新率的触控操作。这给了OS操控层面的人机交互设计带来了完全不同的设计革命。
小屏幕上的点击、拖动、轻弹、放大/缩小、滑动等操作,为操作系统用户界面带来了完全不一样的设计逻辑。
借助这套革命性的逻辑和框架,以及性能足够的ARM芯片,合理的元器件成本和集成尺寸,第一代IPhone诞生了。
我们分析这个过程不难发现这一系列元素中,ARM芯片/电容触屏方案/半导体元件的集成度在2004年附近,共同让乔布斯有了发挥空间来实现iPhone的产品定义。
而这一切如果在十年前的Newton的年代,则彻彻底底演变为了一场悲剧。
初代Newton MessagePad在1993年发布时售价高达700美元,另外当时神经网络落后,也没有CNN手写识别,造成手写识别方面的效果非常糟糕。
所以我们回看乔布斯,无不反映出一个深刻的产品决策逻辑:
在这一套决策逻辑之下,苹果不会激进的推任何技术驱动的产品,而是默默观察,保持在牌桌上针对本质问题长期投入,从成本侧观察元器件迭代的趋势。然后在技术逐渐收敛的情况下,把相对来说体验最优秀的最完善的产品带给用户,把最大的利润留给自己。
我们再次回首,那些抢技术首发,把一个半成品带给用户的公司,也许赚到了噱头。
但他们真的收获了足以支撑长期正向研发的利润吗?还是只能供应链有什么就用什么?
关键的关键,时间。
Gartner作为分析机构参考,可以看到2023年我们获得了很多技术的peak point,比如foundation model和我们体感一致,在2023年下半年开始越过巅峰走向谷底。
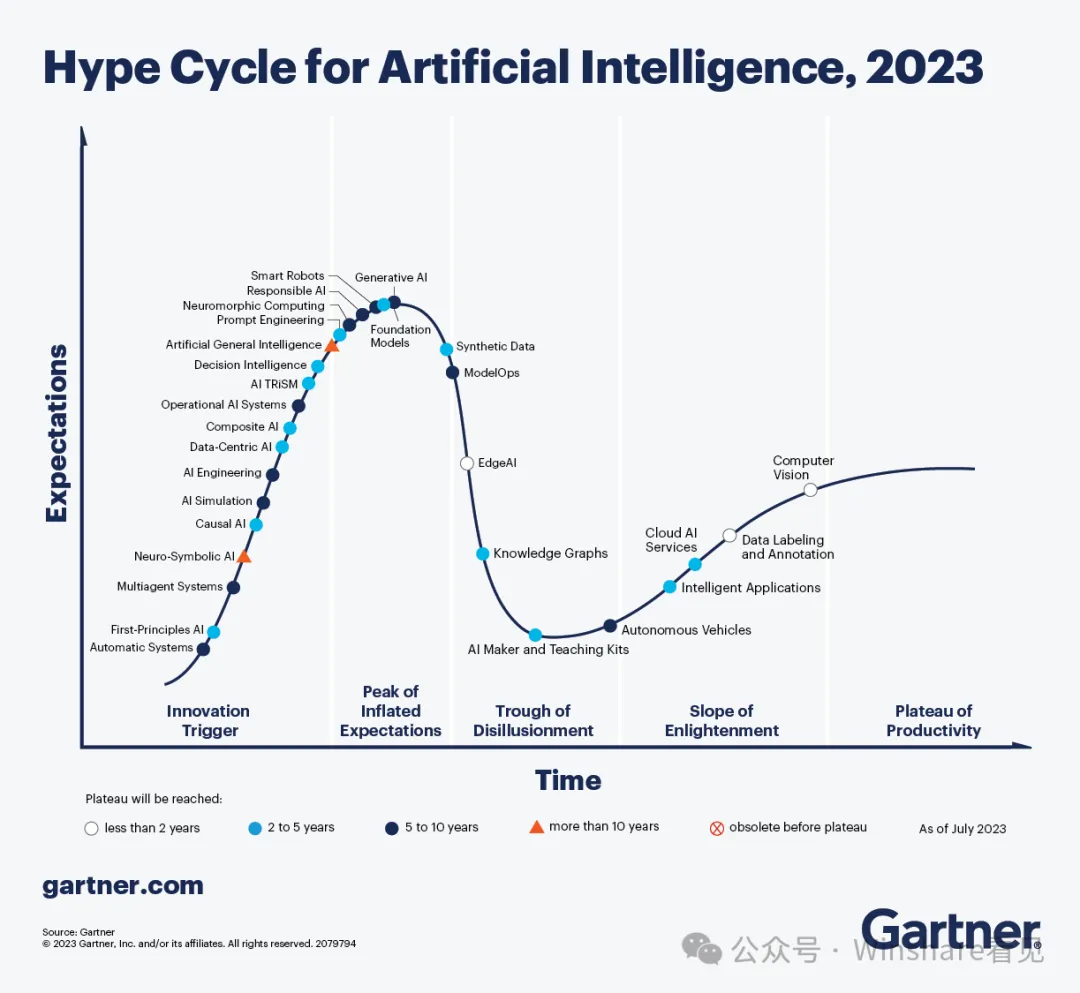
从现在这个时间点来看大量的应用站在了时间的对立面。
任何不能覆盖高客单价的场景的应用,在面对即将收缩的市场时,任何低客单价的应用都面临着极大的出清压力。
因此我们来看什么样的场景才能满足高客单价的场景呢?
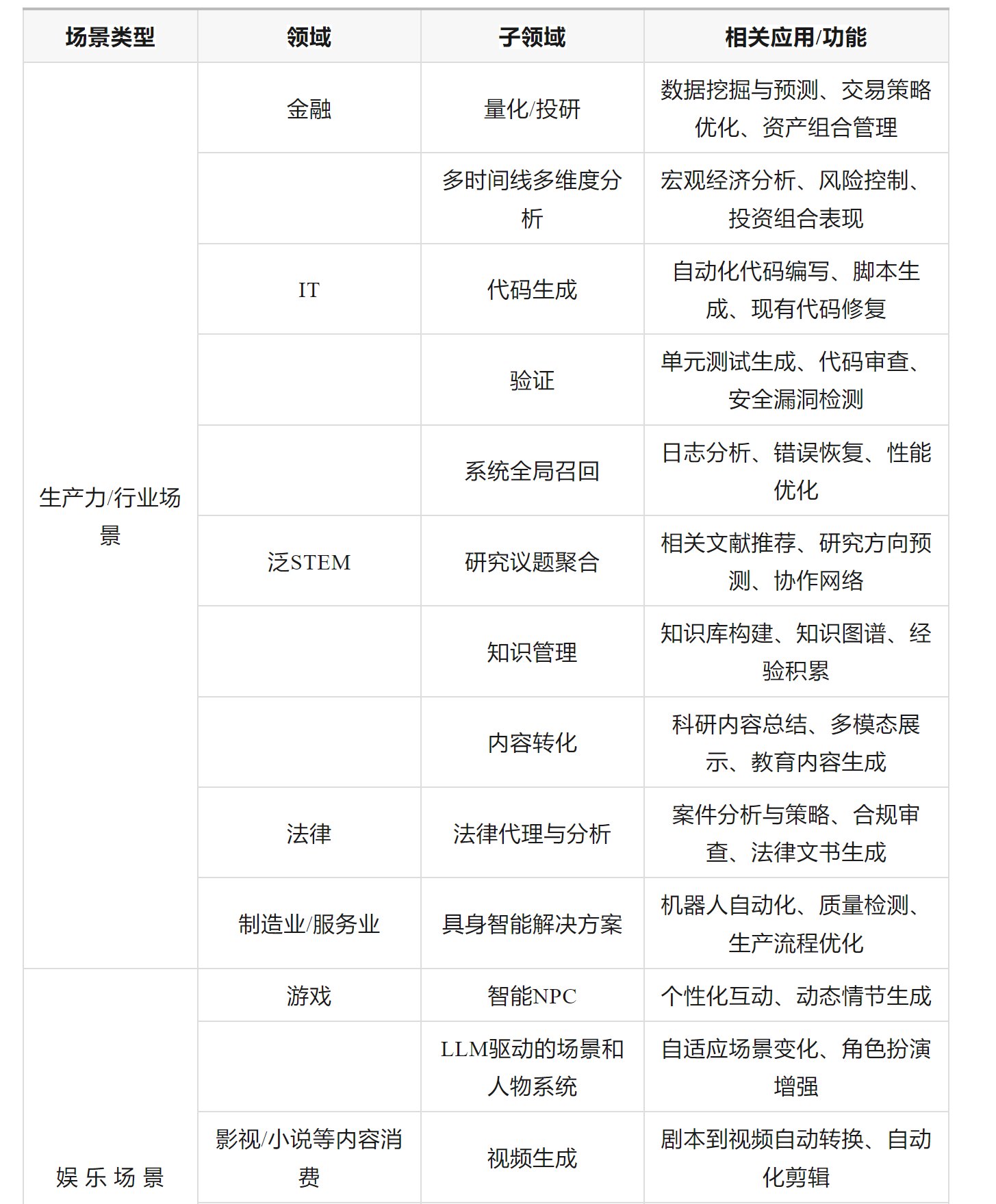
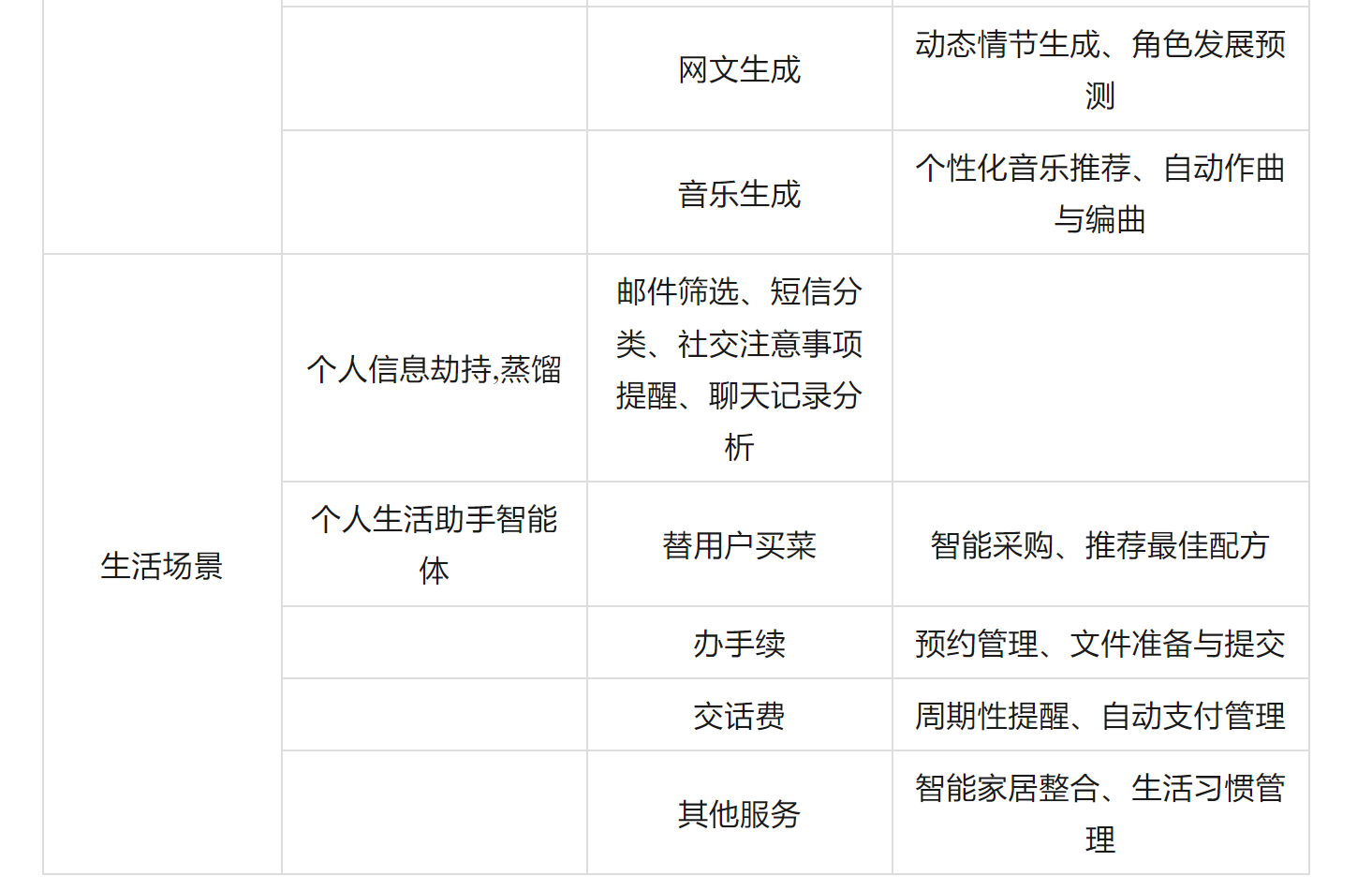
多的不再举例,但从场景上考虑
生产力/行业场景绝对是最先能实现【单次推理用户价值】减去【单次推理成本】为正的领域。
我们也必须明白在这些场景之下,大模型就不是为普通人服务的。
目前来看,普通用户和生产力/行业场景用户在潜在的【单次推理用户价值】上有着一个数量级以上的差异。
比如:一个程序员可以使用代码生成和自动化验证能力将整个工作流的效率提升3-5倍,长期可能提升10-100倍。这带来的【单次推理用户价值】相比cosplay trash talk在现在已经产生了超过一个数量级的差异。
因此大模型应用想要扩展普通用户这个行为本身在这个时间点就是不成立的,也是不合理的。
一个哲学问题只有在正确的背景中才能得到解决。我们必须给这个问题一个新的背景,我们必须把它比做我们通常不作比较的情况。
—维特根斯坦
背景信息,作为哲学论断中的重要组成部分,是人类对于世界和自我抽象认知的总结经验。
但是,在维特根斯坦这里,“澄清”不是把没有说清楚的命题,用明白无歧义的语言说清楚,更不是赋予命题以严格的逻辑形式和结构,而是限定与划界:“它(哲学)必须划分可思考的东西,由此划分不可思考的东西。
也就是说,在自然语言中,由于人类大量的先验知识和社会信息灌输的存在,我们不需要让一个信息的传递过程中充满完备的逻辑和知识或是结构。
大模型的革命性优势在于,在信息交换中,第一次用计算机的体系实现了全世界背景信息,状态,先验的近似隐含。面对这个世界在语言空间的投影,我们可以带着自然语言的大量漏洞,问题,缺陷进行相对准确的信息交换。
那么,代价是什么?
大模型基于概率的过程,无法进行确定性的计算,逻辑推理。
大部分的高价值场景,只需要或只能容忍进行确定性的计算和逻辑推理。
例如:
生成幻觉是大模型到现在为止一直备受讨论的问题。
和我们刚才讲的确定性和非确定性一样,生成知识结构的准确性,事实性,时效性都是极大的挑战。
同样的高价值场景也无法容忍幻觉
例如:
索性大模型不是单打独斗,幸好我们还有智能体
基于以上两个问题我们可以看到当前最关键的几个问题:
1.如何让智能体实现完全可信的,严谨的逻辑推导能力。
2.如何让智能体实现完全完备的数学抽象和表达能力以及对应的计算能力。
3.如何让智能体实时的更新知识,且可以做无幻觉的生成。
达到这三个目的之前我的思路是首先必备的要素是什么?
按照第一性原理,必备的要素肯定不是算力也不是人力,而是数据,
所以,怎么产生这些数据呢?这就是我们要设计的框架,这个框架必须帮助最有能力产生这些数据的人,或者流程,先帮追他们提高十倍效率,一百倍效率。让他们能够以人类顶尖的认知加上比现在高一两个数量级的效率来产出这些数据。
在自然语言或者非完备的形式拆解层面 Chain-of-Thought (CoT) 和 Tree-of-Thought (ToT)可以作为一个baseline。2023年姚期智老师团队发布了累计推理(CR)虽然表面上看起来类似于 Chain-of-Thought (CoT) 和 Tree-of-Thought (ToT),但CR通过其能够动态存储和利用所有历史验证的推理结果来进行组合,将其区别开来,形成有向无环图(DAG),而不仅仅是一个序列或树。这种结构上的灵活性使CR能够通过利用更广泛的已验证命题的上下文,解决更复杂的问题,从而克服CoT和ToT在处理复杂推理任务中的局限性。

CR的优越性根植于其在一个连贯框架内协同整合提议者、验证者和报告者角色,为推理过程引入了新视角,并优化了中间结果的累积和验证。这种整合方法促进了一个更深入、更精确的推理过程,同时具备适应性和容错性,反映了人类解决问题的细腻且迭代的本质。
但类似的实践却表明理想很丰满,现实很骨感。
其实不难想象,一个先验包含的一阶逻辑越简单的,越直接,大模型进行模拟推理出错的概率越低。
当我们把这些逻辑论断不断拆解的时候,单步出错的概率也就越低。但一个显著的bug是,从自然语言中进行复杂逻辑拆解,抽象显然也需要较高的reasoning能力。所以这类方法的限制还是比较大的。
现代计算机科学的基础是什么?
符号逻辑是计算机科学的基础,为编程语言理论、数据库理论、人工智能、知识表示、自动推理以及形式验证提供了基础。
基于逻辑的形式方法通过提供精确语义的推理规则和表示方式,补充了统计方法和机器学习。这些方法在硬件和软件验证中起到了核心作用,同时也被用于解决数学中的未解问题。
可满足性(英语:Satisfiability)是用来解决给定的真值方程式,是否存在一组变量赋值,使问题为可满足。布尔可满足性问题(Boolean satisfiability problem;SAT )属于决定性问题,也是第一个被证明属于NP完全的问题。
命题逻辑可满足性问题(SAT)和可满足性模理论问题(SMT)是两个最重要的逻辑约束问题,SAT是命题逻辑上的约束求解问题, SMT是一阶谓词逻辑上的约束求解问题。它们不但在自动定理证明、软件工程等学术研究中有广泛应用,更是信息安全、集成电路设计自动化和软件验证等领域的底层计算引擎。
从七八十年代起欧美大学体系基于SMT理论开发了一系列的数学求解器。
例如:
进一步延伸的Mathematica,Wolfram这些非典型SMT的求解系统实质上将数学、科学、逻辑计算纳入了各种不同的形式化标准里面。不同类型的求解器(如SMT求解器、LP求解器、混合整数规划求解器、符号求解器等)的存在导致了解决问题的方法和形式化标准的不一致。这是因为不同类型的求解器是为特定类型的问题设计的,并根据不同的理论和方法工作。例如:
在一些早期工作上,这些混乱的形式化标准终于被大模型的训练有了纳入到一个体系的可能。2023,陶哲轩使用大模型加上Lean4求解器完成了PFR定理的证明。AI4Science在生化物之外第一次对要求完全确定性过程的数学有了实质性的影响。
这让一切看起来有了希望。与之同时期,一些自动化方案开始出现。
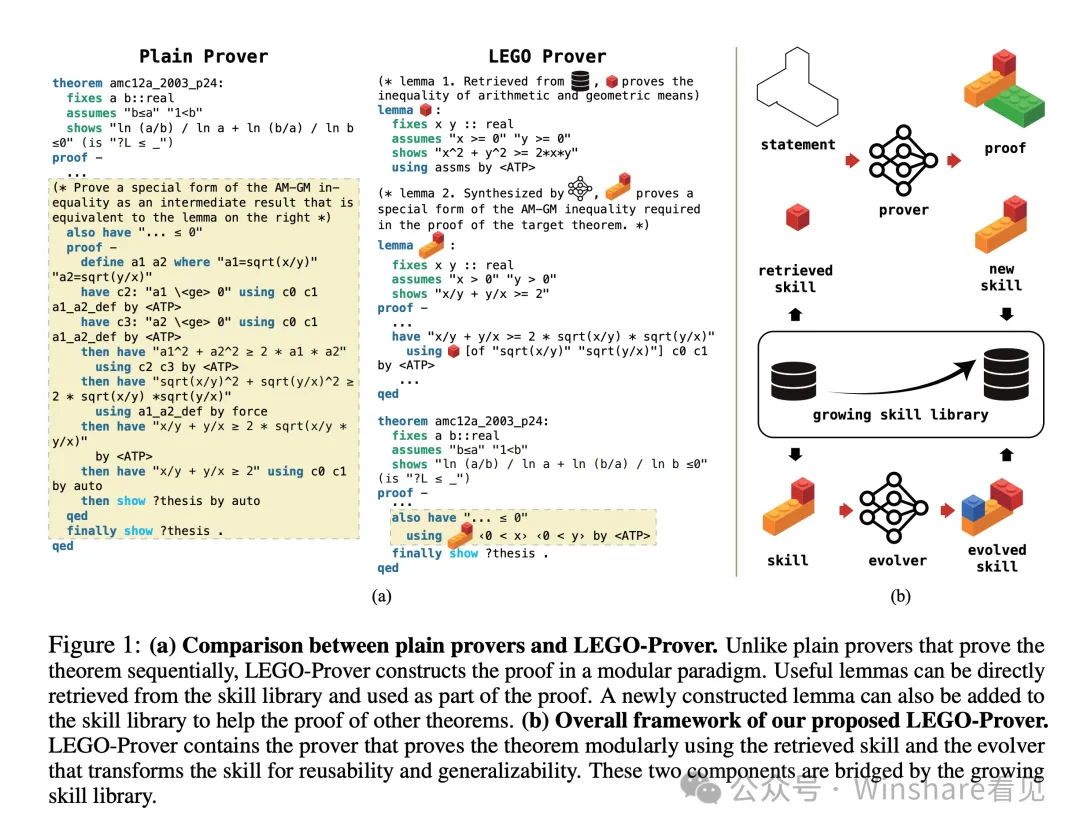
中山大学和香港中文的一些研究者开始把一些基础的大模型和智能体思维引入数学求解流程。
在这个流程里面,一些数学基础求解技能或者链路可以视为基础模块来协助进化出更高级的求解能力。并且通过简单的大模型+向量召回满足了索引需求。不过在这个过程中,对于步骤,领域的解题模板的抽象和认知缺失导致这些工作都没有更进一步。
虽然是很简单的思路,取得的定理证明能力进步也有限,但不可否认的是这是智能体可信数学解算向前进的一条可行路径。
在一些更小众的领域进展则更喜人。在AlphaGeometry上
几何证明类题目可以更好的被完全形式化。所以几乎已经是wellsolved problem
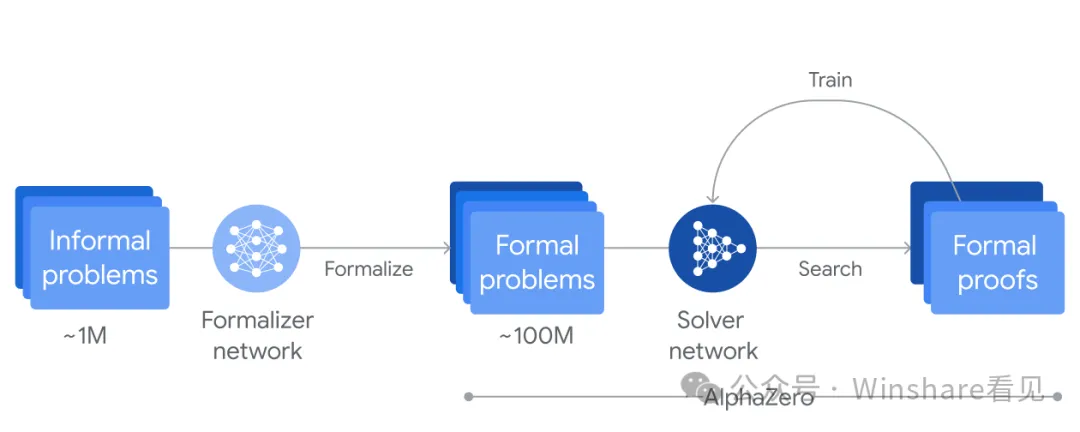
例如AlphaGeometry 2:
结合蒙特卡洛过程,符号/SMT引擎,强化学习和LLM几乎成为各个数理领域的万金油,
虽然还有更多的数论,积分,代数,统计类问题,无法很统一的被良好形式化完备,但是人们似乎已经看到了希望。
作为全村的希望,RAG和LLM的组合过去一年时间被无限提及。作为多智能体的基础组件,数据系统,决定着智能体如何和高质量的数据交互。但现有的RAG在针对整个文本语料库的全局问题上性能十分低下,例如“数据集的主要主题是什么?”,因为这是一个本质上是面向查询的摘要(Query-Focused Summarization, QFS)任务,而不是显式检索任务。这严重制约了RAG应用在高价值场景上。
作为关键组件向量数据库承载了很大的责任。我们暂时可以把这类组件作为LLM的触角,让他能超越本体来获得其他数据。或者我们可以直接视向量为AI时代的json。
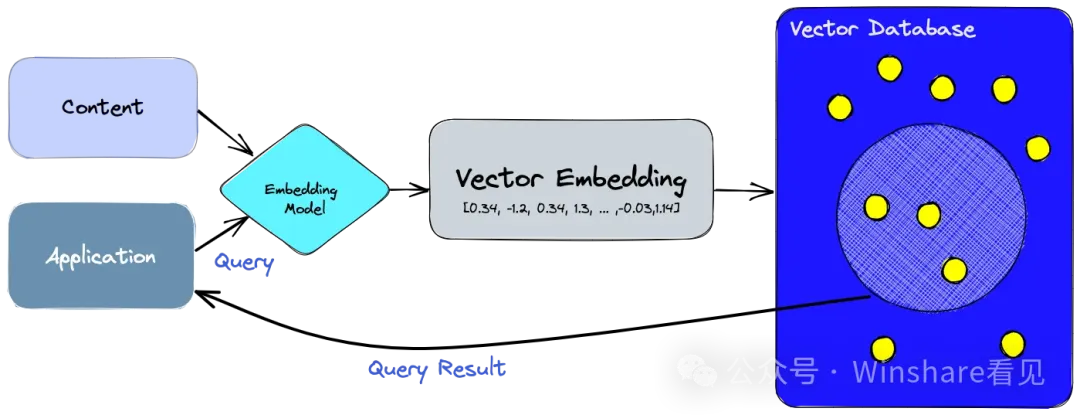
但向量数据库的处境却有些尴尬,一方面是召回性能对于高价值场景还是太低了,第二方面召回内容的压缩率还是太低。
向量数据库的性能其实根本就不重要 —— 以至于生产上 100% 精确的全表暴力扫描 KNN 有时候都是一种切实可行的选项。更何况向量数据库需要与模型搭配使用,当大模型 API 的响应时间在百毫秒 ~ 秒级时,把向量检索的时间从 10ms 优化到 1ms 并不能带来任何用户体验上的收益。
而另一个方向因为微软的项目又被重视起来,——Graph/KnowledgeGraph。
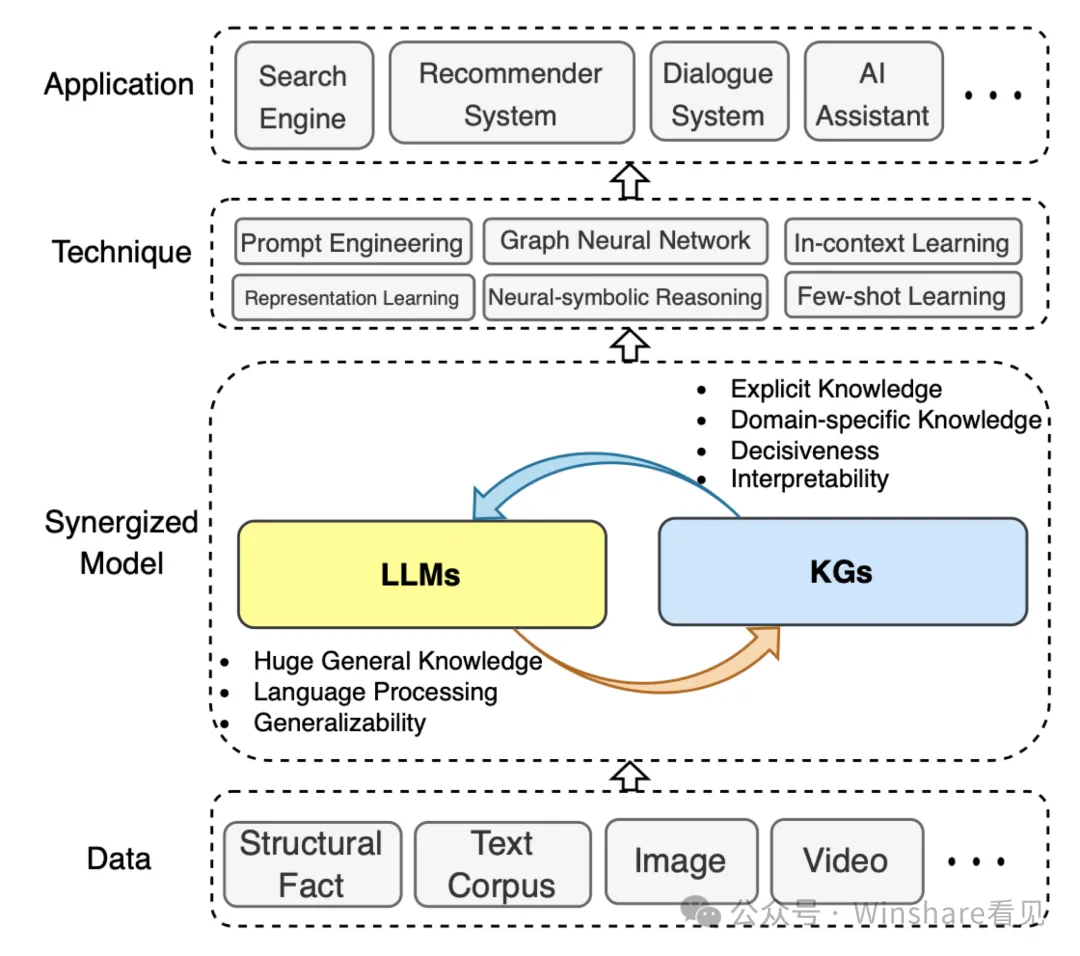
Graph最大的优点就是它存在于人类的符号体系内,人能够很好的认知,理解,修正,同时也是结构化数据也能被计算机体系兼容。基于graph的方法具有用户问题的普遍性和源文本索引数量的可扩展性。通常在前期,LLM在两个阶段构建基于图的文本索引:首先从源文档中导出实体知识图,然后为所有密切相关实体的群体预。给定一个问题,每个摘要用于生成部分响应,之后所有部分响应再被总结成对用户的最终响应。
类似方案最大的好处在于能够站在一个全局知识上进行问题推理和抽象。这个全局理论上可以达到人类知识的总和和边界。其中可以迸发出的能量现在还很少有人能认识到。

我们不怀疑这类rag能够在短时间内提升召回性能。但因为知识图谱的原生结构缺陷,单纯符号系统层面的处理会导致数据暴涨到后期,整体的维护成本剧增。
而知识图谱本质上可以视为结构化符号数据在图空间的存在。从这个角度看,如果我们设计一种能同时兼顾向量空间和符号空间的索引系统同时支持混合Cypher这类图查询语言和向量查询以及传统关系数据库查询。那能够带来的表示形式,数据协同上的优势会无比巨大。

Principle Scientist Dr. Paul Lessard talk about why category theory is the key to achieving a description of symbolic reasoning in machines
Symbolica首席科学家Paul 在2024年六月份发表了一篇文章想要通过范畴论来统一描述和研究深度学习架构
范畴论的基本概念:
使用范畴论来构建和分析深度学习模型,可以帮助实现模型的可信性,:
在正向推理的技术之外,multi-agent 实现自动化的真谛,高速进化的真谛自然是除了正向的生成,结果能即时获取验证信息/反馈
我们再次回望,提问:IT为什么能够领先一切行业发展,甚至帮助一切行业发展??
还要回归到一个最核心的计算机组件——编译器/解释器。
我们从工作流去分析化学,物理,数学,等等任何其他自然学科的验证成本有多高?
一个化学实验的物料成本是多少?
一个汽车的碰撞测试成本是多少?
一个核工程师做实验的成本是多少?
相比起来一个程序员验证自己程序能否运行的成本是多少?
编译器把这个成本相比其他行业工作流的物资成本,时间成本降低到了忽略不计。
不止摩尔定律,超级低的工作流成本,不错的产出,才是IT获得超高增长率的原因。
而确定验证的工作流,和大模型结合之后很容易抽象之后被彻底替代。
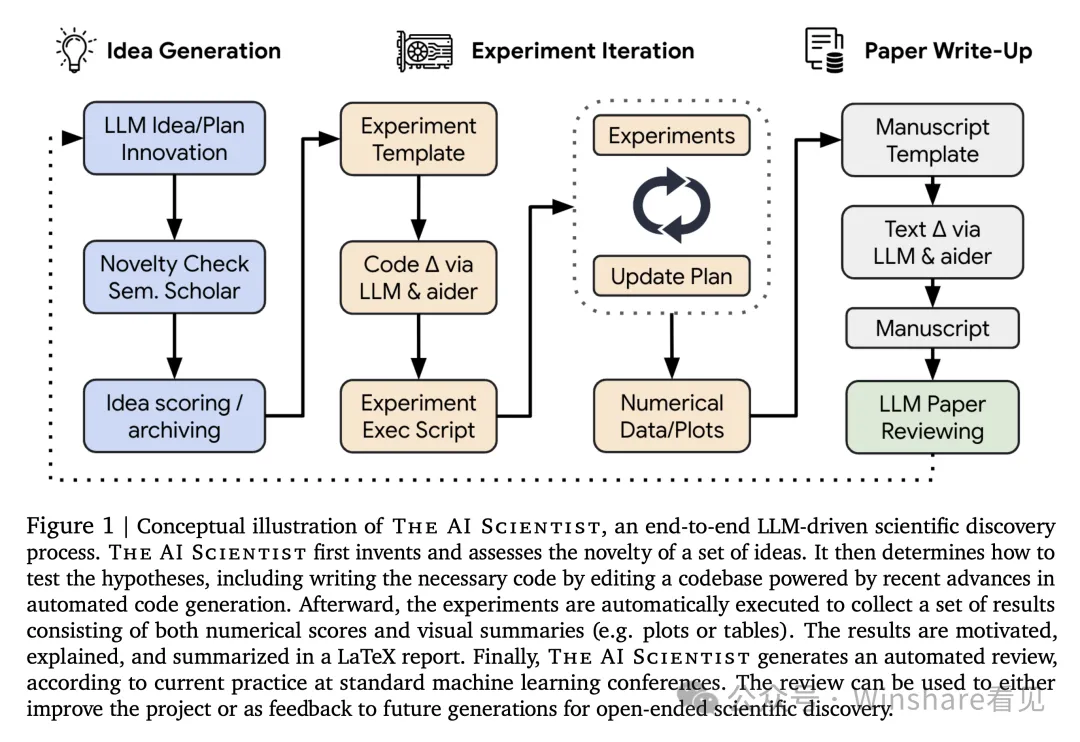
当一个2024年的baseline能使用一个汉堡的价格能得到一篇不错的论文的时候,还需要关注用户量,流量,用户存留这种事情吗?
站在2024年秋中美AI竞争,从上游半导体,到中游数据,工具链,foundation model 研发,再到下游应用,以及场外的资本量级每一项都拉出了数量级差异。
下半场的Agent ,应用,满地得套壳,既是无能,也是无奈,反过来进一步推高了VC的决策成本和压力,最后变成了既要,又要,还要。
最近一个论调是,历史进入了垃圾时间,个人奋斗和历史进程的比重将会严重失衡。
但正如最近大火的游戏科学的冯骥说的一样。
踏上取经路,比到达灵山更重要。
文章来源于“Founder Park”




【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
