# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
三年走来,每一步都「作数」。
短短一年多,全国已有 197 个 AI 大模型完成备案,行业大模型占比近 70%。伴随这一快速增长的趋势,一个现实问题不容忽视,如果不能和普通商家的现实需求紧密结合,大模型体验再好,也无法帮助大模型厂商自动完成商业闭环:
扎堆商场一楼的新能源车销量大不如前 ,如何让高昂租金的产出性价比更高?
某大型服装厂的数据表累积超过 3 亿多行,如果提炼不出价值,就只是成本;
因为数字转型做得早,一堆业务系统竖起的数据「烟囱」让某乳业大品牌进退维谷;
答非所问、反应滞后、人工客服难找,智能客服一直在挑战人的血压极限;
.......
算法是智力,算力是体力,数据是血液,「但让 AI 真正飞入寻常百姓家的关键,在于与具体场景的深度融合。」9 月 20 日,瓴羊智能科技(以下简称瓴羊)在 2024 云栖大会上举办了「 Data×AI :企业服务智能化,价值增长新动能」专场论坛,阿里巴巴集团副总裁、瓴羊智能科技 CEO 朋新宇在论坛发言中说道,归纳成公式就是「(无处不在的)AI =(算法+算力+数据)x 场景」。
「 x 」强调了两边元素的放大作用,一个是指 AI 带来的体验提升,至少要 10 倍好于过去,不然就只是一个外挂。另一面,即使拥有先进算法、强大算力和海量数据,如果不能与具体业务场景紧密结合,AI 价值也无从谈起。
瓴羊,作为阿里巴巴的全资子公司,今年迎来了它的第四个年头。看起来「年轻」,实际上资历很深,集合了阿里最懂数据的一群人,其中带头者朋新宇已经是一个在阿里工作了 20 年的数据老将,也是阿里巴巴数据中台的创立者。
瓴羊专注数据要素服务,推出了五大产品矩阵,覆盖了从底层数据治理到顶层业务应用的数据生命全周期。
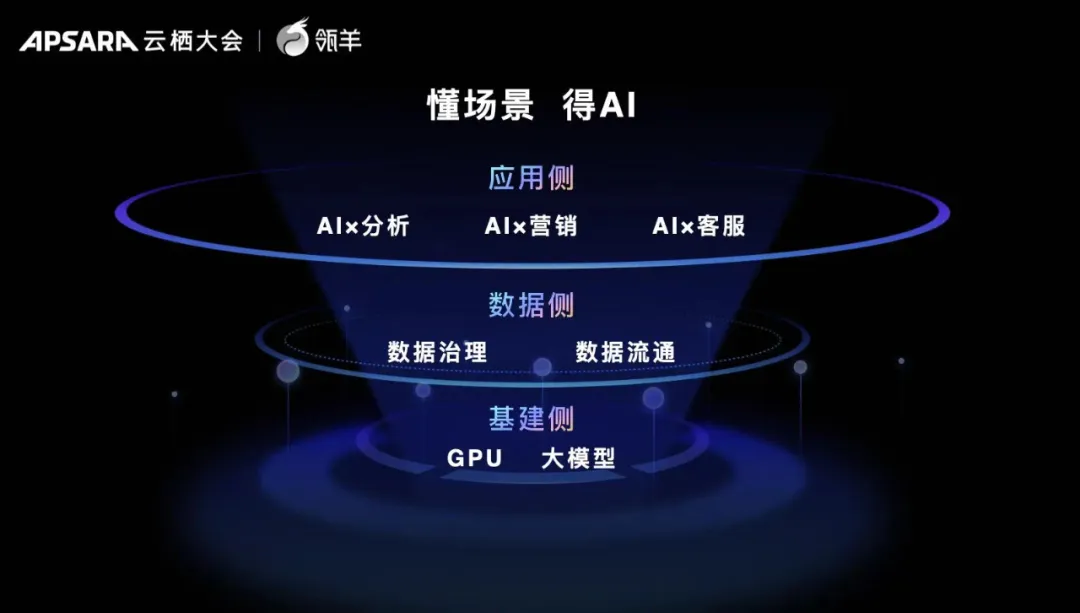
最引人注目的是应用侧 ,分析(Quick BI)、营销(Quick Audience)和客服(Quick Service)三款产品涉及所有企业应用的「最大公约数」 ,也是企业预算最多、最易沉淀数据并与 AI 产生「 化反」 的业务场景。
第二层是数据侧,包括数据中台 Dataphin 和「瓴羊港」。前者负责企业数据治理工作,确保数据的质量、一致性和可用性,也容易与 AI 结合。后者像是管道,专注数据在企业外部的高效流通,为整个生态提供源源不断的数据活水。
至于基建侧,瓴羊定位自己是一家产品公司,因此年初看到 OpenAI 推出 GPTStore 时,团队没有太过纠结就做出决定,不去跟风「卷」大模型,坚定应用好大模型。
他们选择阿里通义千问作为通用底座,结合专业知识和行业数据,「炼出」不同领域的垂直小模型(如 BI 领域模型),将大模型能力「揉进」几款产品(Quick BI、Quick Audience、Quick Service 和 Dataphin),直接为客户创造价值。
商业智能(BI)工具是每一个迈向 AI 时代商家的标配,BI 技术也从传统 BI、敏捷 BI 逐渐进化到智能化 BI。敏捷 BI 时代,用户可以通过拖拽、点击更直观地与数据交互,随着大模型为 BI 引入革新性生成式分析体验,智能化 BI (如瓴羊 Quick BI )时代,原本高门槛的数据分析变得像对话一样简单。
智能问数(ChatBI)就是一个颇具代表性的例子,体现出自然语言到 SQL 的技术转换。该功能支持即席查询、覆盖关键问数场景,在复杂计算的兼容性、模糊语义识别方面,表现尤为优异,即使毫无技术背景,用户也能轻松对「数据」发问。
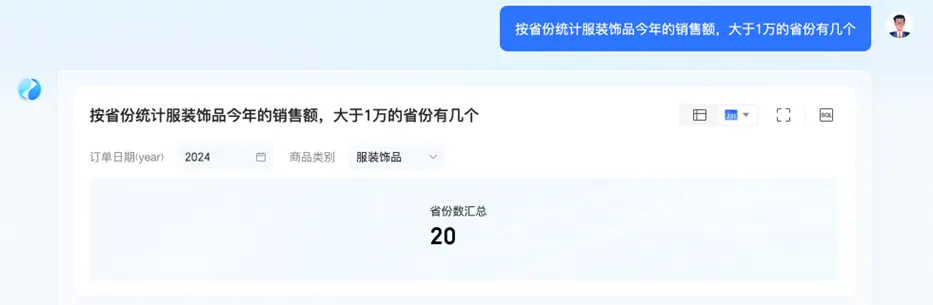
如电商平台销售场景中,想了解销售额大于1万的省份这类问题,就体现了智能问数(ChatBI)二次复杂计算能力
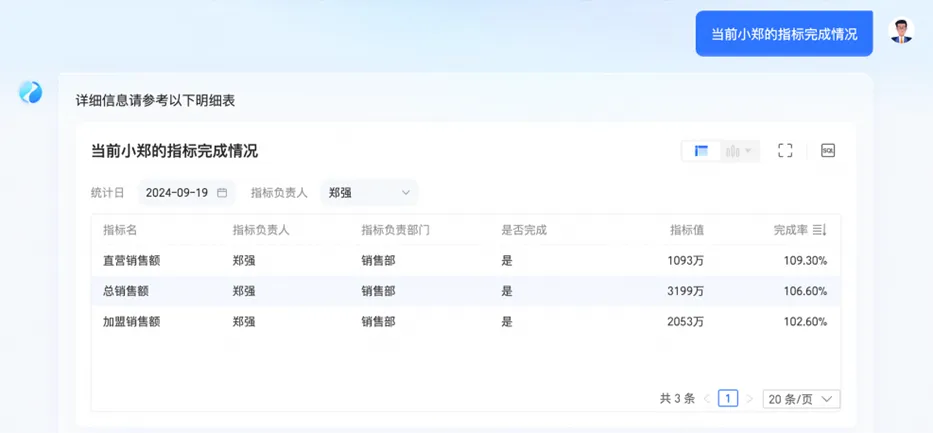
对于模糊语义的识别,当前智能问数(ChatBI)也能轻松识别并理解。如提问中「小郑」定位到「郑强」。
这种智能化的 BI 工具正在解决实际业务中的痛点。以某知名乳业品牌为例,其供应链管理面临两大难题。
一个是查询数据报表的灵活不足,固定报表一般按天甚至月计,满足不了灵活多变的业务需求。求数据开发人员,要等三天才能拿到报表。
另一个是人工报表搭建周期长,成本高,导致异常诊断分析复杂,缺乏多维度目标差异比对分析,「看板」只展示数据,还不能自动分析问题原因。
Quick BI 帮助客户在内部建立起智能问数体系,支持自然语言问询,无论是日常工作、业务会议还是出差途中,业务人员都能快速获取数据、检索资产,还能进行丰富的指标分析。
由于结合了传统统计算法和大模型,Quick BI 可以深度解读图表和补全信息,揭示业务数据背后故事,高效定位原因,真正辅助商家作出决策。
而在营销领域,随着移动互联网用户和流量见顶,企业相关预算分配更加谨慎,从「种草」走向「转化」,更看重 「确定性机会」。
以某床垫品牌为例,线上渠道有 9 个,线下门店多达 5600 多家,如何定位「正确的人、在正确时间,说正确的话」,提升转化率?「双 11 」大促,用什么办法激活老会员复购?不少商家苦于平台「沉睡人群」即将流失,却无有效抓手叫醒他们。
现在借助大模型,瓴羊 Quick Audience 的「门店智能营销助手」 可以快速「圈定」目标用户,缩短营销创意时间,并优化沟通时机,显著提高触达率。
例如,某知名服饰品牌天猫平台的「沉睡人群」即将流失,商家借助 Quick Audience 迅速「圈定」北京、上海、广州共 42 家门店 5 公里内常驻或工作的「沉睡人群」,在预测设备活跃时刻推送瓴羊超信,实现目标人群的线下门店召回,到店率提升 18% ,线下转化率提升 35% ,全渠道转化率提升 40% 。
而 Quick Audience 的另一个新功能「智能采集分析助手」成功将数据团队从数据采集(「埋点」)这种典型的 dirty-work 中解放出来,以全自动、可配置的方式,一站式完成埋点采集及业务分析应用。
某头部车企,供应商采集埋点开发成本高,周期长,质量把控困难,通过使用智能埋点助手,节约供应商埋点开发人力采购成本 9 成,项目实施周期缩短 50% ,埋点相关数据故障降为 0 。

除了分析、营销场景,当前,智能客服也存在诸多不足,如常常答非所问、维护知识库仍靠人海战术、一线客服效率低下,导致客户投诉频发。为此,瓴羊 Quick Service 2.0 借力大模型,有效解决了这些不足。从效果上看,解答准确率提升至 93% ,人工客服处理问题所需时间从 10 分钟缩短至最快 5 秒,知识库部署所需时间从 7 天缩短至 5 分钟。
除了利用 AI 大模型重构分析、营销、客服三大企业级智能应用,负责数据治理的中台 Dataphin 也迎来最大变化—— 加入了 DataAgent 。现在,只需三步,就可以构建企业专属的数据资产智能体,这也是业内首个场景化智能找数方案。
建立企业数据资产全景和目录是 Dataphin 主要能力之一,现在,借助大模型,将企业数据资产目录构建为一个智能知识库,通过对话就能快速摸清「家底」,还能帮助用户快速定位业务相关数据资产。在个性化数据分析能力上,现在可辅助自动生成 SQL 代码,可链接即席查询和 BI 分析执行看数。
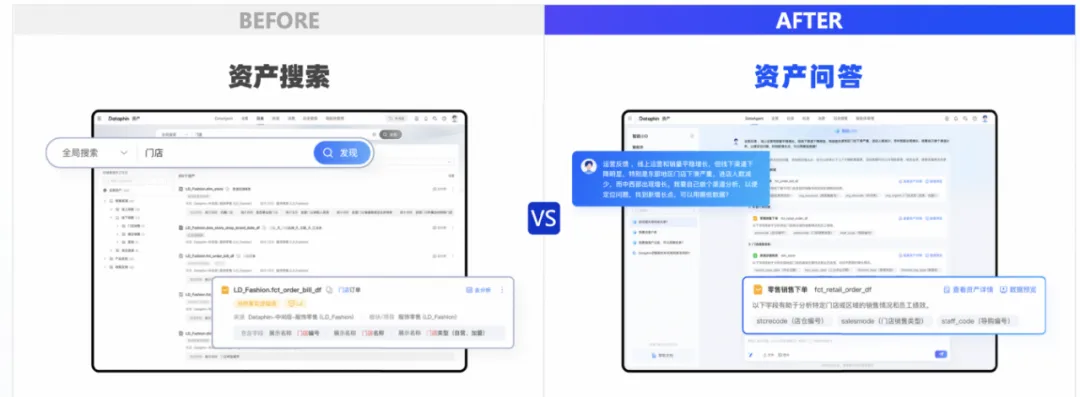
其实,在瓴羊成立之初, Dataphin 就已经经过阿里巴巴和众多企业的实践磨砺,被成百上千的客户应用,它的诞生直指当前中国企业在数字化转型过程中面临的首要挑战:数据「脏乱差」。
如台州银行在数智化升级之前,存在数据标准缺失、指标口径不统一、缺失统一清晰的数据资产盘点等问题。类似的问题也出现在其他行业,如某大型服装企业的营收金额统计,需要计入商场扣点、财务扣税等因素,因为各渠道数据口径不统一,每日的营收数据竟会出现高达数十万元的偏差。被企业视为经营压舱石的「四率二效」指标也因流程不规范,掺杂了各利益方的主观意愿。
而 Dataphin 通过标准化数据处理流程,统一数据口径,并提供全面的数据资产管理,帮助企业建立起可靠、一致的数据基础,为数字化转型铺平道路。Dataphin 最初源于阿里这个「超级工厂」的实践经验,因此在推广初期,瓴羊主要将其引荐给了与阿里规模相当的大型客户。
为了让更多企业能够用上好的数据工具,治理好数据,瓴羊针对性地进行了一系列改进,如针对私有化部署高成本和公共云标准化限制的痛点,Dataphin 通过重构治理方式,提供半托管服务,将部署时间从几天缩短到 1 小时,同时保持了个性化服务。
过去两年,瓴羊在数据领域取得了显著进展,不仅针对数据治理这一企业常见难题持续迭代升级 Dataphin 产品,还针对数据数量和流通这一更具挑战性的问题,推出了数据流通枢纽——瓴羊港。
数据不仅具有使用价值,还蕴含着巨大的交易价值。然而,如何让数据像淘宝上的标品一样高效流通,成为了一个亟待解决的问题。恰逢其时,2023 年 10 月 25 日,国家数据局正式揭牌,为数据流通提供了政策支持。「以数据促进融合发展」成为这家新机构的核心思想之一,而数据流通正是破解数实融合发展堵点的关键。
朋新宇敏锐地观察到,相比于前几年出于安全考虑而「踩刹车」的政策导向,国家数据局的成立有望起到数据「发动机」的作用,驱动企业间的数据流通。顺应这一趋势,瓴羊在 2023 年云栖大会上推出了瓴羊港,旨在破解企业长期面临的数据缺失、数据资产难以管理、外部数据无法融通等关键问题,提供「寻、买、管、用」一站式数据服务,帮助企业实现数据驱动的业务增长。
瓴羊港发布近一年,已达成和 30 多家头部数据方的紧密合作,目前平台上流通的应用场景和行业标签多达 3000 多种。

2022 年爆发的 AGI 革命无疑是计算机科学的又一次重大创新,标志着第四次工业革命的开端。在这场革命中,数据的规模、多样性和质量的战略重要性被提升到了前所未有的高度。
十余年前,阿里云抓住了云计算的技术浪潮。如今,瓴羊又踏上了数据要素浪潮。成立之初,瓴羊就明确将自身定位为 DaaS(数据即服务)公司,与传统 SaaS 公司划清界限:
SaaS 主要通过工作流程标准化来提高企业运营效率,解决的是效率问题。而 DaaS 则通过数据流的全场景应用,将数据价值渗透到企业经营的方方面面,致力于解决更深层次的业务价值问题。
面对未来十年的机遇与挑战,瓴羊如何才能领头羊群,成为海量商家生意增长的数智化参谋?朋新宇引用了团队内部坚信的价值观作答,不论是过去的互联网,今天的 AI ,还是未来的新兴技术,要真正落地到产业和企业,必须做到三点:
你要「快」,但「快」——很快看一篇论文、发表一篇论文,不一定解决所有问题;同时,你要「深」,深入理解行业痛点,要问客户能不能用?第三,客户要「认」,赢得客户的好口碑,前面的「快」和「深」才有价值。
文章来自于微信公众号“机器之心”,作者“吴昕”



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】kimi-free-api是一个提供长文本大模型逆向API的开渔免费技术。它支持高速流式输出、智能体对话、联网搜索、长文档解读、图像OCR、多轮对话,零配置部署,多路token支持,自动清理会话痕迹等原大模型支持的相关功能。
项目地址:https://github.com/LLM-Red-Team/kimi-free-api?tab=readme-ov-file
