# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
实验证明,大模型的 System 2 能力还有待开发。
规划行动方案以实现所需状态的能力一直被认为是智能体的核心能力。随着大型语言模型(LLM)的出现,人们对 LLM 是否具有这种规划能力产生了极大的兴趣。
最近,OpenAI 发布了 o1 模型,一举创造了很多历史记录。o1 模型拥有真正的通用推理能力。在一系列高难基准测试中展现出了超强实力,相比 GPT-4o 有巨大提升,让大模型的上限从「没法看」直接上升到优秀水平,不专门训练直接数学奥赛金牌,甚至能在博士级别的科学问答环节上超越人类专家。
那么,o1 模型是否具备上述规划能力?
2022 年,来自亚利桑那州立大学(ASU)的研究团队开发了评估 LLM 规划能力的基准 ——PlanBench。现在,亚利桑那州立大学研究团队全面审视了当前 LLM 在 PlanBench 上的表现,包括 o1 模型。值得注意的是,虽然 o1 在基准测试上性能超过了竞争对手,但它还远未达到饱和状态。

对于 vanilla LLM(通过 RLHF 微调的 Transformer 模型)来说,PlanBench 基准仍然充满挑战,即使在最简单的测试集上,模型表现也不佳。
下表为当前和前一代 LLM 的结果,测试领域包括 Blocksworld 和 Mystery Blocksworld(混淆版本),其中前者是在 600 个 3 到 5 个 block Blocksworld 问题静态测试集上运行的结果,后者是在 600 个语义相同但语法混淆的实例(称之为 Mystery Blocksworld)上的运行结果。
在这些模型中,LLaMA 3.1 405B 在常规 Blocksworld 测试中表现最佳,准确率达到 62.6%。然而模型在 Mystery Blocksworld 的表现却远远落后——没有一个 LLM 在测试集上达到 5%,并且在一个领域上的性能并不能清楚地预测另一个领域的性能。
这种结果揭示了 LLM 本质上仍是近似检索系统。

更进一步的,作者测试了自然语言提示和 PDDL,发现 vanilla 语言模型在前者上的表现更好。
作者还发现,与之前的说法相反,one-shot 提示并不是对 zero-shot 的严格改进。这在对 LLaMA 系列模型的测试中最为明显。
值得注意的是,基准测试的原始迭代没有考虑效率,因为 vanilla LLM 生成某些输出所花费的时间仅取决于该输出的长度,而与实例的语义内容或难度无关。不过作者也对各个模型的提示成本进行了比较,如表格 4 所示。

标准自回归 LLM 通过近似检索生成输出,但这些模型面临一个问题,即在 System 1 任务中表现出色,但在对规划任务至关重要的类似 System 2 的近似推理能力上表现不佳。
回顾之前的研究,从 LLM 中获取可靠规划能力的最佳方法是将它们与生成测试框架中的外部验证器配对,即所谓的 LLM-Modulo 系统。o1 尝试以不同的方式为底层 LLM 补充类似 System 2 的能力。
据了解,o1 是将底层 LLM(很可能是经过修改的 GPT-4o)结合到 RL 训练的系统中,该系统可指导私有 CoT 推理轨迹的创建、管理和最终选择。但是目前确切的细节很少,因此只能推测其确切机制。
作者猜测 o1 和 LLM 之间有两个主要区别:一个额外的强化学习预训练阶段和一个新的自适应扩展推理程序。无论如何,从现有细节可以看出,该模型在本质上与以前的 LLM 根本不同。
在原始测试集上评估 LRM:作者在静态 PlanBench 测试集上测试了 o1-preview 和 o1-mini,结果如表 2 所示。其中,600 个 Blocksworld 实例范围从 3 到 5 个 block 不等,需要 2 到 16 个 step 的规划才能解决。
结果显示,o1 正确回答了 97.8% 的这些实例,但在 Mystery Blocksworld 上,o1 没有保持这种性能,但也远远超过了以前的模型,正确回答了 52.8% 的实例。

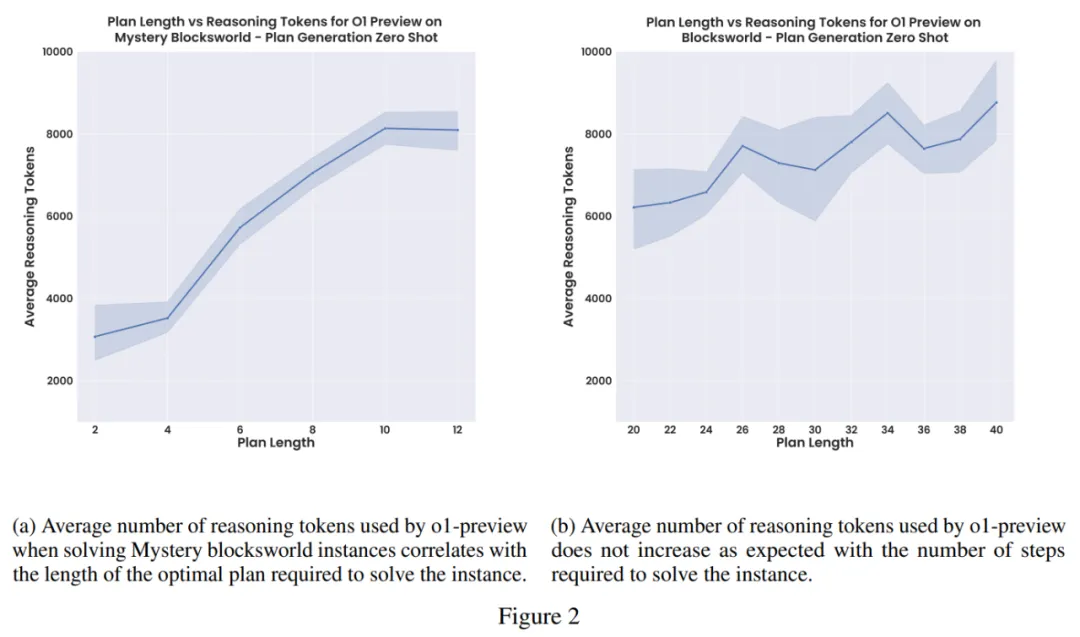
标准 LLM CoT 提示方法很脆弱,无法随着问题规模的扩大而稳健地扩展。作者在一组较大的 Blocksworld 问题上测试了这些模型(见图 3)。此集合中的问题长度从 6 到 20 个 block 不等,需要 20 到 40 step 的最佳规划。
作者发现模型性能从之前报告的 97.8% 迅速下降。事实上,在这组实例中,o1-preview 仅实现了 23.63% 的准确率。可以看出虽然这些模型总体上令人印象深刻,但这表明它们的性能仍然远不够稳健。

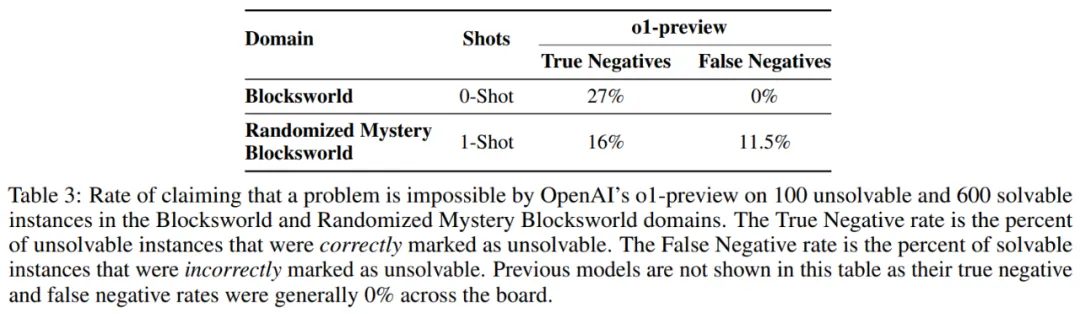
在不可解决实例上的性能:接着作者修改了测试集中的一些实例,结果如表 3 所示。在 Blocksworld 上,只有 27% 的实例被 o1 正确且明确地识别为无法解决。在所有案例中,有 19% 的模型返回一个点或「empty plan」标记,没有任何解释或指示无法解决。在其余 54% 的案例中,模型生成了一个完整的规划。
在随机 Mystery Blocksworld 上,这些数字更糟:16% 的案例被正确识别为无法解决,5% 返回了一个「empty plan」,其余 79% 的案例得到了完整规划的回答。
研究团队发现:o1-preview 似乎在每个问题使用的推理 token 数量方面受到限制。如果 o1 的正式版本消除了这一限制,可能会提高整体准确性,但也可能导致更不可预测(甚至高得离谱)的推理成本。o1-mini 虽然更便宜,但通常性能较差。

文章来自于“机器之心”,作者“陈陈、小舟”。




【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
