# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大模型正式上岗,化身AI售前助手,已经开始拯救IT售前人了!
在浪潮信息内部,一款名为“元小智”的AI助手,已经成为了员工们的得力助手。
不仅能几秒钟读完上百页的招标文件,产品资料问答、信息比对、查询检索等工作也都得心应手。
过去,人工需要几天才能完成的任务,只要几分钟就能搞定了。
而且模型微调、应用开发过程全程零代码,售前团队1人1月即可完成,工作效率UP UP。
售前是IT行业解决方案的构建者,所需具备的技能自然也多种多样,需要“三头六臂”的全能选手才能胜任——
不仅针对IT本专业需要具备扎实的基础知识,还要有良好的市场敏感度、快速学习能力和强大的沟通技巧。
而在IT行业的销售中,招投标又是一种重要形式,因此售前人员还要向投标工作中投入大量精力。
他们要先完成对招标文件的解读分析,精准理解并解答招标文件的技术需求,并在此基础上撰写出符合招标要求的文件。
但交付的时间,往往又极为有限,不仅如此,标书的制作还面临着多重困难。
首先,招标文件内容冗长,而且充满了细节,导致标书材料分析耗时,且关键信息容易遗漏。
但在需求一侧,招投标业务时间窗口十分紧迫,同时又要严格按照业务规则执行,容错率低,对文件内容的精准性要求极高。
这对业务人员的综合经验和技术水平,是一项不小的考验。
同时,他们还需要对公司产品、技术白皮书、标书、解决方案等了如指掌。
但是这些产品及方案材料更新速度非常快,又分散在不同部门,信息整合与查阅工作又是一项新的挑战。
不难看出,仅标书这一项工作就足以让售前人员焦头烂额,更不必说还有一系列其他工作。
面对重重困难,人们想到了让机器替代一部分人工,减轻售前人员的压力——
基于大模型开发的AI助手,在分析处理长文本方面有着得天独厚的优势。
但实际操作起来,很快就又发现了新的问题。
首先,无论是人还是大模型,想要胜任售前岗位,对自身产品信息的了解都是不可或缺的。
对于大模型而言,了解的方式就是建立专用知识库。
一家大型IT公司的全业务线可能包含近千款产品,大到产品迭代型号,小到插槽数量、板卡规格,这些信息都要精准无误,才能让大模型帮助售前完成繁重的产品信息查阅工作。
但这些信息内容繁杂,且数据本身结构化程度低,提取工作复杂,导致专用知识库建设并非易事。
退一步讲,即便有了这样的知识库,基础模型+RAG的模式也不足以满足工作中的专业能力需求——
售前需要撰写的标书文件具有十分专业的行文格式、专业术语,虽然这种模式在问答任务中有一定准确率,但是并不代表理解了招投标工作的业务逻辑。
解决这个问题的办法便是微调,但优质微调数据是一大难题,并且需要开发人员具备丰富的大模型微调经验,研发周期长、试错成本高。
另外,招投标文件包含大量企业隐私数据,必须确保数据绝对安全,因而不能上传云端利用公共大模型进行训练推理,也就是说,企业大模型必须进行本地化私有部署。
这些要求叠加在一起,涉及多环节、工具,使得这样的模型开发本就十分困难且周期漫长。
虽然售前人员最了解业务场景,对这些痛点也是如数家珍,但他们并不具有相应的代码开发能力,更不用说定制化的应用开发了。
不过好消息是,现在大模型应用开发已经没有那么复杂了——即使没有技术出身,只要明确需求,简单学习之后也能上手。
在浪潮信息内部,售前部门就已经利用大模型开发平台工具开发出了售前AI助理“元小智”,针对售前工作中的痛点各个击破,将员工从庞杂的工作中解放了出来。
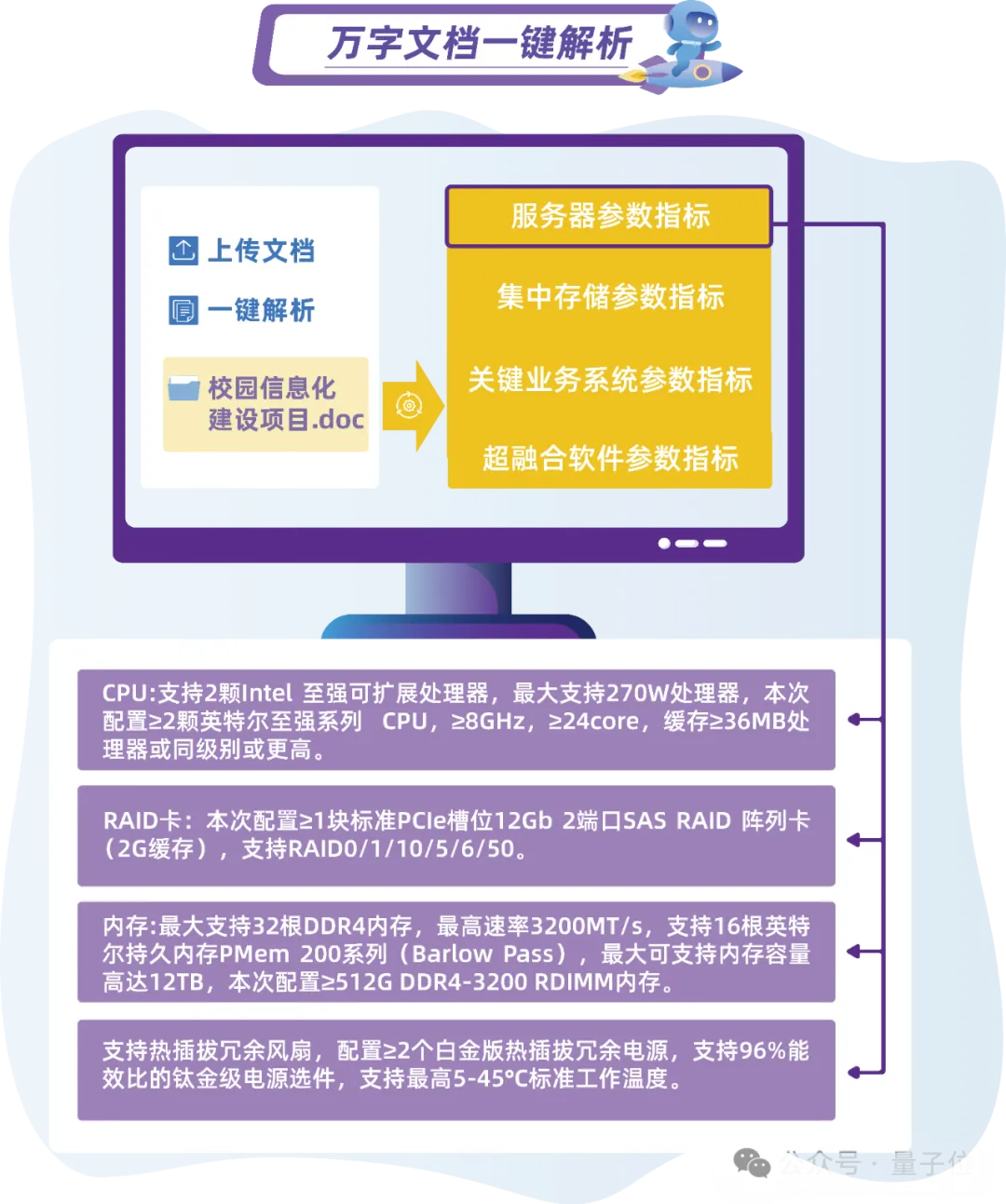
“元小智”可以一键处理招标文件,对招标文件中的重要信息进行全面且准确的解读。
根据项目需求,“元小智”可以高效识别数万字上百页的招标文件,招标关键信息的识别准确率达到85%,秒级提取客户核心需求。
过去需要几天的招标文件分析工作,几分钟就能完成,大幅提升了业务人员的工作效率,缩短时间窗口。
“元小智”还凭借智能问答功能,成为了浪潮信息售前专属的“百科全书”,辅助产品信息查阅与专业内容生产。
通过该功能,售前人员快速查阅并生成浪潮信息全系列在售产品及方案的相关内容,生成对应的产品优势、核心参数等支撑信息,免去了售前人员在海量产品文件中逐一查阅的繁琐过程。

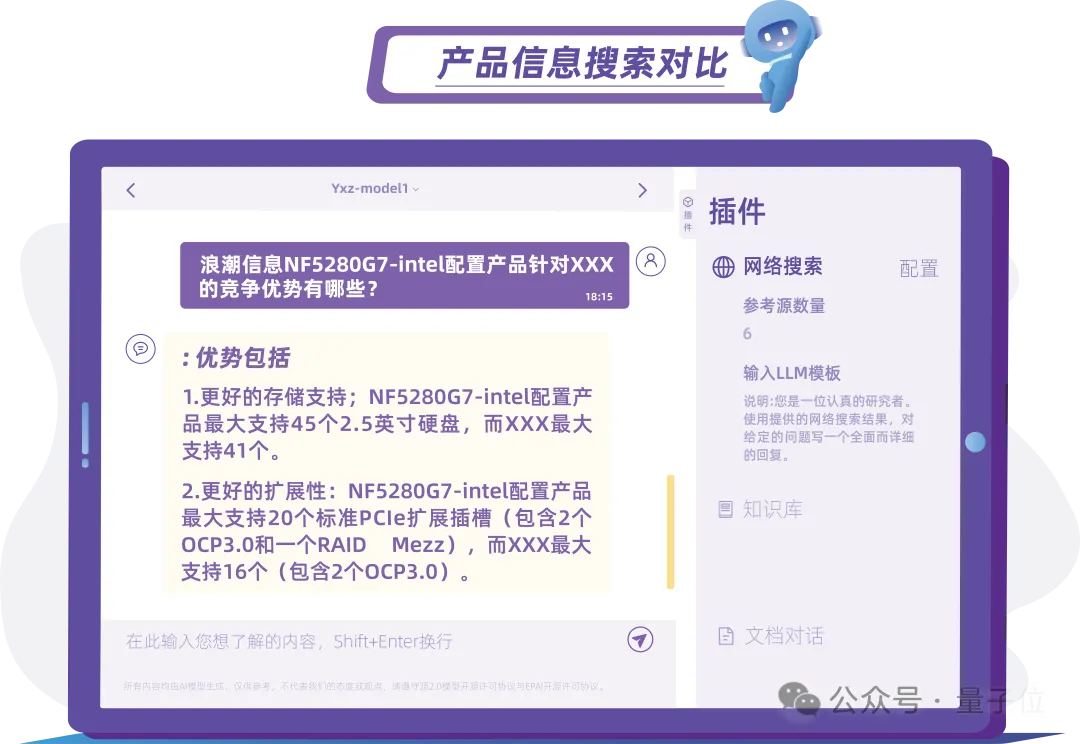
知己知彼才能百战不殆,除了自身产品体系之外,了解同类产品方能有的放矢地制定策略,在竞争中取得优势。
针对招标核心信息,“元小智”可以通过网络检索功能查询同类产品情况,辅助售前人员快速了解产品信息,节约了至少一半的分析时间,整体将售前的投标工作提速3-5倍。
而且联网检索有需要时才会调用,并与企业数据库隔离,数据安全有保障。
在“元小智”的背后,是浪潮信息的企业大模型开发平台——元脑企智EPAI(Enterprise Platform of AI)。

其中的数据处理工具能够自动解析结构化数据(如表格),并将其转化为标准格式的知识库条目;针对非结构化数据(如纯文本信息),元脑企智EPAI则能够自动提取有用信息并进行高效存储。
浪潮信息售前团队使用元脑企智EPAI实现了数据的自动化收集、整理、清洗和索引,从1500+的pdf、docx、doc、xls等多种格式在内的业务资料、企业产品信息与方案文件中抽取数据,构建起了8大业务线全部在售产品的知识库。
同时有效融合RAG技术,将繁杂的企业知识成功转换为大模型“最强外挂”。
对于大模型微调,元脑企智EPAI也提供了全链路数据治理工具,可以从种类多样、场景复杂、规模庞大的招投标文件、产品信息、行业报告中,自动抽取生成微调数据。
利用元脑企智EPAI平台的评判大模型,针对生成的每一条微调数据进行自动打分,剔除低质量数据,通过格式过滤进一步提升微调数据质量,减少数据筛选和处理的时间和成本。
如此反复多次,最终形成了数十万条高质量微调数据,利用元脑企智EPAI平台的零代码微调工具进行模型微调,多次迭代后成功实现模型专业能力提升,构建起了符合业务需求的专用大模型。
元脑企智EPAI还提供了多种应用开发工具,可零代码快捷开发本地应用,平台支持多种参数的设置、修改,同时提供 API 调用、chat页面对话等多种交互方式,实现开箱即用。
同时,元脑企智EPAI及利用其打造的大模型应用可完全本地化部署,并配有多种安全技术,数据安全能够得到保障。
“元小智”虽然是浪潮信息的内部应用,但是借助其背后的元脑企智EPAI提供的数据处理工具、零代码微调工具、知识库检索工具等,其他企业也可以建立起自己的“元小智”。
不仅如此,元脑企智EPAI平台更是加速大模型落地的有效赋能工具,提供了一套更完整的企业大模型落地解决方案。

元脑企智EPAI平台提供了上亿条基础知识数据,同时还包含了自动化的数据处理工具,可以帮助用户整理行业数据和专业数据,生成高质量的微调数据和行业/企业知识库,进而打造企业专属数据资产。
有优质的基础+行业+企业数据作为支撑,大模型生成内容的准确性和可靠性就有了保证,大模型落地的最大痛点——幻觉问题将大幅缩减。
同时,结合RAG技术,元脑企智EPAI可以解决企业知识库更新频率高但大模型微调耗时长、频率低的矛盾,保证模型能够及时获得处理最新知识的能力。
另一方面,元脑企智EPAI还提供了高效的微调工具,支持千亿参数模型面向产业知识的快速再学习,并让模型具备百万Token的长文档处理能力,解决窗口长度不足的问题,快速打造领域大模型。
而且元脑企智EPAI支持包括CPU和各种GPU在内的多元算力,以及各种主流开源、闭源模型,适配快,迁移成本低,为企业提供了丰富的模型和算力选择。
此外,企业用户最担心的数据安全问题,元脑企智EPAI也提供了坚实保障,通过权限管理、数据加密、内容审查等多种技术手段,确保数据和模型安全,做到了隐私信息不泄露。
“元小智”就是浪潮信息打下的一个很好的样板,通过“元小智”,我们可以见微知著,看到其背后元脑企智EPAI平台的强大能力——
从耗时的招标文件分析,到繁琐的产品信息查询,再到专业的标书撰写……这些曾经让售前人员头疼不已的难题,现在都能够得到高效、准确的解决。
借助元脑企智EPAI这样的企业大模型开发平台,即使是非技术背景的售前团队,也能够快速构建起适合自身需求的AI助手,技术门槛大大降低。
可以说,元脑企智EPAI,使大模型落地成为了可触可及的现实。
文章来自于“量子位”,作者“克雷西”。



【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
