# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
深入探讨OpenAI o1模型的技术原理以及产业影响。
距离OpenAI发布o1模型已经过去一周,其口碑出现了明显的两极分化。
一种声音认为o1的出现意味着人类距离AGI只有咫尺之遥,另一种声音认为o1又贵又不好使,其能力表现甚至不如GPT-4。
沉淀一周后,我们结合熵简AI团队的研究成果,对o1的技术原理及产业影响进行详细探讨,形成了以下判断,与各位分享。

原始报告的获取链接放在文末,欢迎感兴趣的朋友下载。
OpenAI于9月13日推出o1模型,在逻辑推理能力上大幅提升。
在AIME 2024数学竞赛中,o1模型的准确率达到惊人的83.3%,相比之下GPT-4o的准确率只有13.4%,提升6倍。
在CodeForces代码竞赛中,o1的准确率甚至达到了89%,GPT-4o的准确率是11.0%,呈现大幅提升。
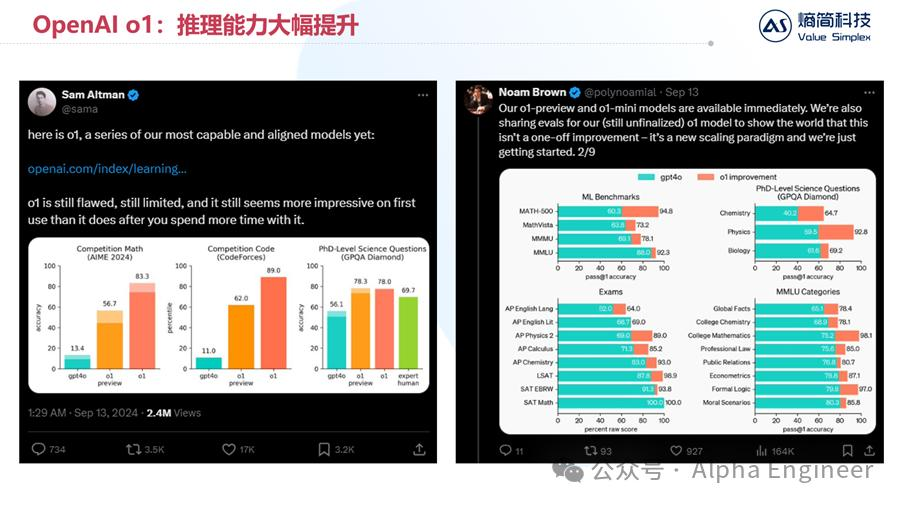
用柱状图来说明逻辑推理能力的提升,还不够直观。下面我用OpenAI官方的一个具体案例,来说明o1目前的逻辑推理能力到底达到了怎样的水平。
这是一个“密码破译”的例子,给定一串密文“oyfjdnisdr rtqwainr acxz mynzbhhx”,它应该翻译成明文“Think step by step”,请你根据以上规则,翻译以下密文:oyekaijzdf aaptcg suaokybhai ouow aqht mynznvaatzacdfoulxxz
下图是GPT-4o的回答,回答很工整,先“break this down step by step”,然后进行分词,但最后无法破译密码,认为只给出一个案例是不够的,希望我们给予更多提示。
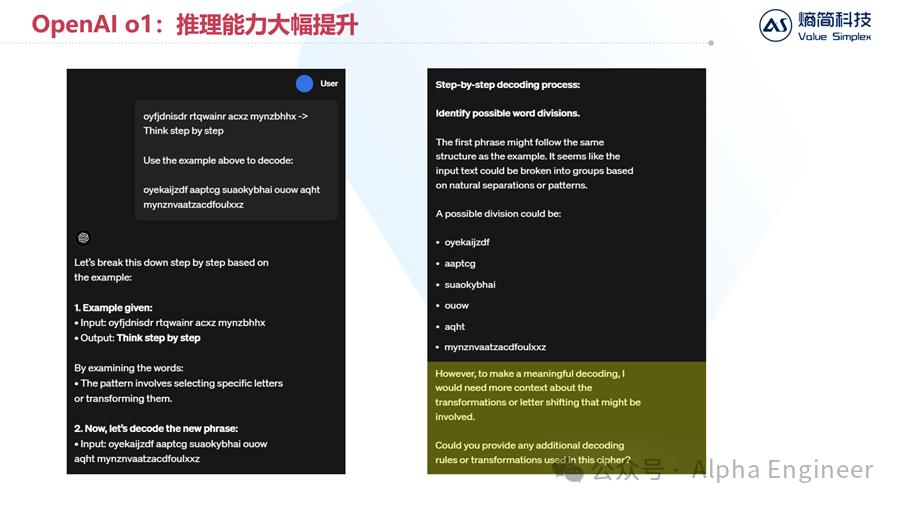
接着让我们来看o1的回答:
首先,o1对给出的问题进行分析,认为可以先检查一下每个单词的长度。
它敏锐的发现,密文中每个单词的长度,和明文中每个单词的长度之间,有着2倍的关系。
oyfjdnisdr(10个字符)-> Think(5个字符)
rtqwainr(8个字符)-> step(4个字符)
在这个基础上,o1推测应该存在一种映射关系,使得密文中相邻的2个字符能够映射为明文中的1个字符,即:
oy -> T
fj -> h
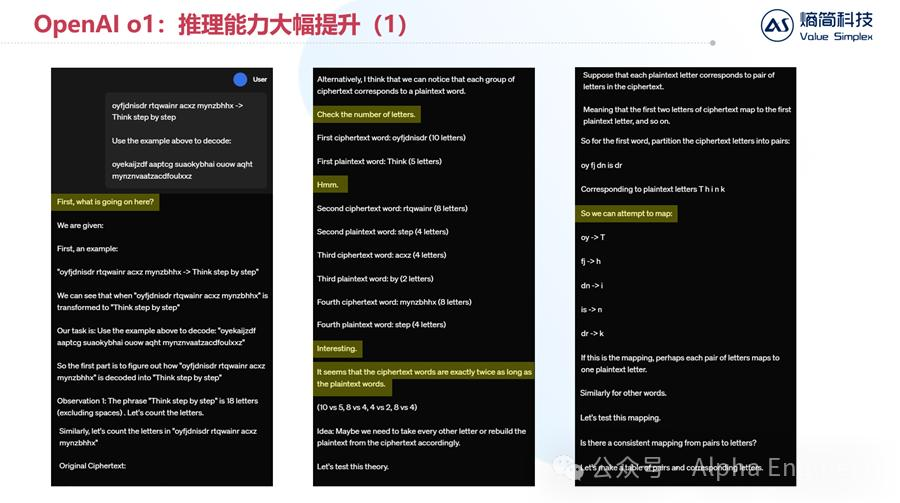
那么怎么才能把'oy'映射到'T'呢?
针对这个问题,o1进行了多种尝试。首先,按字母在字母表中的顺序位置,可以假设o等于15,y等于25,T等于20。
o1尝试了加法,尝试了减法,发现都不对。
随后o1尝试把o和y相加,并对26求模,发现也不对。
然后o1发现,把o和y相加再除以2,正好等于T。
发现规律的时候,o1说:Wait a minute, that seems promising.
随后,o1把这个规则用在了其他字符组上进行验证,都成功了。
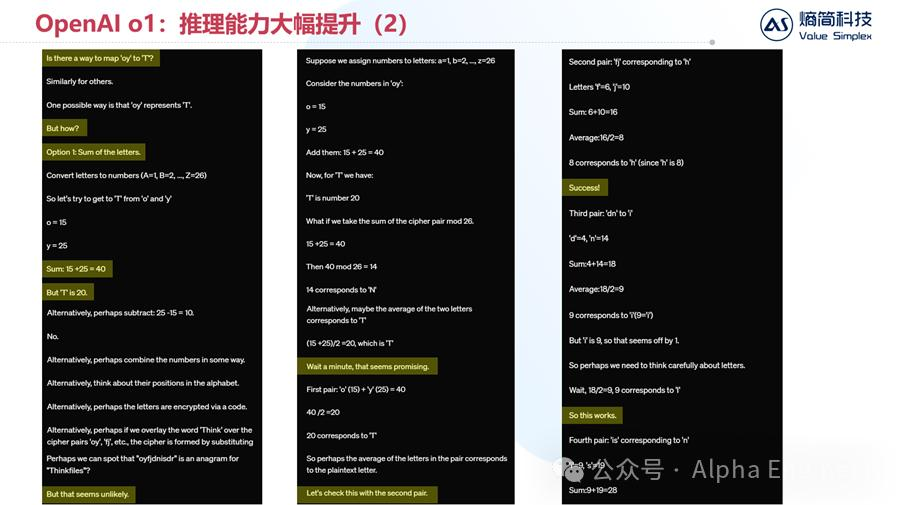
因此,o1找到了密码破译的规则,那就是把密文中相邻2个字符在字母表中的位数相加并除以2,就得到了明文字符在字母表中的位置。
通过这个规则,o1把“oyekaijzdf aaptcg suaokybhai ouow aqht mynznvaatzacdfoulxxz”这串密码成功翻译了出来,答案是:
There are three R's in Strawberry.
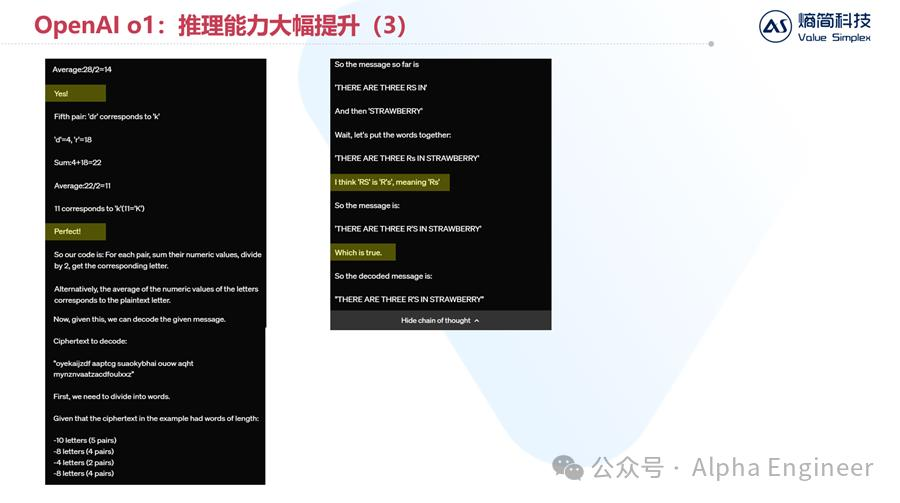
通过这个例子,我们能够更直观的感受o1模型强大的逻辑推理能力。
尤其值得注意的是,这种推理能力不是单纯纵深式的推理,而是类似决策树的层层递进。遇到困难的时候,o1会做出假设,并对假设进行验证。如果假设被证伪,它会选择其他思路进行突破,最终得到正确答案。
相比CoT(思维链)而言,它更像是ToT(思维树)的结构。
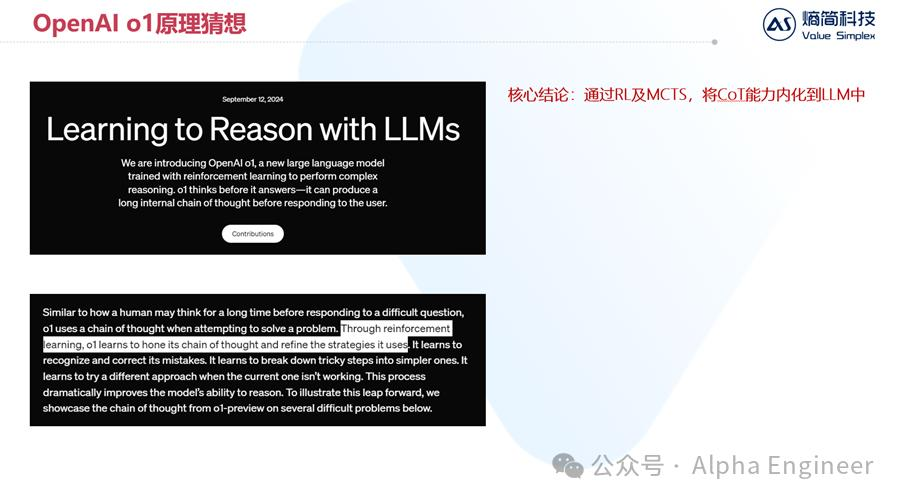
目前OpenAI官方对于o1的原理是讳莫如深的,只有一篇官方的技术报告,标题为《Learning to Reason with LLMs》。
全文不长,但其中关于o1原理的探讨更少,只有一句话:Through reinforcement learning, o1 learns to hone its chain of thought and refine the strategies it uses.
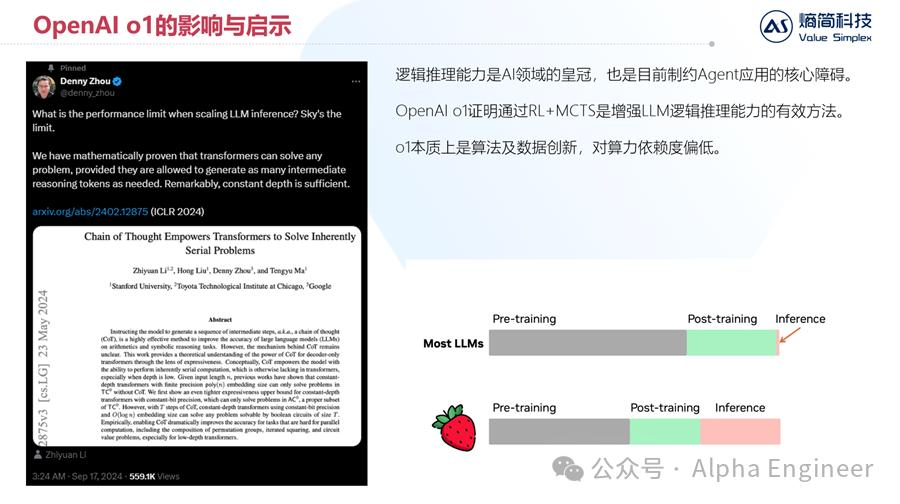
先说结论,我们认为o1模型的核心在于:通过RL及MCTS,将CoT能力内化进LLM中。
在o1出现之前,CoT能力更多是一种Prompting技巧,是独立于LLM之外存在的,而o1的价值在于将思维链的能力内化到了LLM中。
那么具体而言,o1是如何做到这点的呢?为了回答这个问题,我们得参考去年关于Q*的探讨。
要知道,Q*、Strawberry、o1本质上是相通的,因此去年底对Q*的解读和分析,对于我们理解o1的工作原理是相当有帮助的。
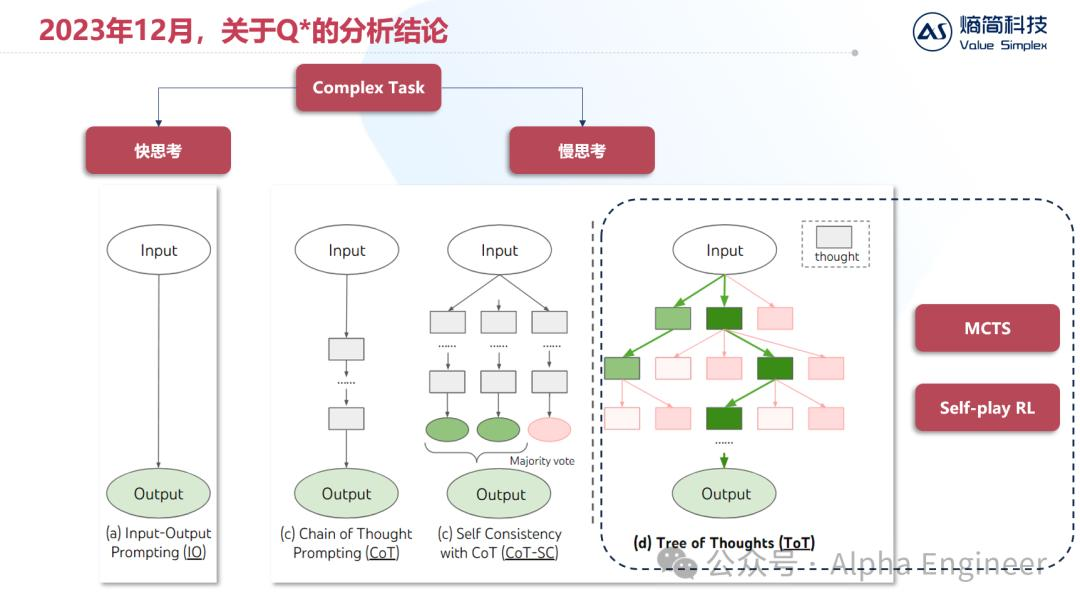
在去年12月的时候,我们对Q*的原理做了详细的探讨和推测,具体可以参考这篇文章:
在对其技术原理进行分析之前,我们先讲讲大模型训练的第一性原理。
大模型训练的第一性原理:本质上大模型的能力都来自于训练数据,体现某方面能力的训练数据密度越高,训练出的大模型这方面的能力就越强。
粗略的分类,大模型的能力体现为三块:语言表达能力、知识记忆能力、逻辑推理能力。
可以说,大模型的这三项能力的获取和掌握,与上述的第一性原理是密不可分的。
首先来看语言表达能力。大模型的语言表达能力很强,各国语言来回翻译很少出错,也鲜有用户反馈说大模型的回答存在语法错误,这是为什么呢?
这是因为,随便找一份训练数据,里面的每一句话都包含着语法信息。所以训练数据中体现语言表达能力的数据密度是非常高的,这也是为何大模型的语言能力很强的原因。
再来看知识记忆能力。这是大模型的另一项重要能力,但偶尔会出现记忆错误,体现为幻觉现象。比如我们问大模型水浒传108将分别有谁,大模型可能会说有武大郎。
这是因为世界知识的覆盖面非常广泛,虽然训练数据体量很大,但是分散到任何专项知识的数据集就很少了。训练数据密度低了,自然训练出的大模型这方面的能力就弱,对专项知识的掌握就不够扎实,体现为幻觉。
然后再来看逻辑推理能力。这次o1模型在逻辑推理能力上产生了巨大突破,那么为什么此前的大模型在逻辑推理能力上比较弱呢?
这是因为训练集中包含推理过程的数据太稀疏了。
就比如现在您在看的这篇文章,本质上是我的思考结果,不是我的思考过程。
可能在未来的某一天,这篇文章会被训练进某个大模型中,但是大模型学到的是思考的结果而已,因为我们人类并不习惯于把大脑中发生的思考过程写成文字,一股脑都放到互联网上。
这就导致互联网上的海量数据中,包含推理过程的数据集非常稀疏。当我们把这样的训练集喂给大模型的时候,又怎么能够指望大模型学到强大的逻辑推理能力呢?
反过来思考,为了让大模型获得更强的逻辑推理能力,我们需要做的,恰恰是提供更多包含推理过程数据的训练集。
有了这个大前提,对于Q*(也就是o1)的理解就水到渠成了。
去年下半年的时候,微软发布了Orca系列模型。Orca模型采用了高质量合成数据进行训练,取得了不错的效果。

值得注意的是,在训练Orca模型时,微软采用了Explanation Tuning的方法,本质上是用包含推理过程的数据集对模型进行训练。
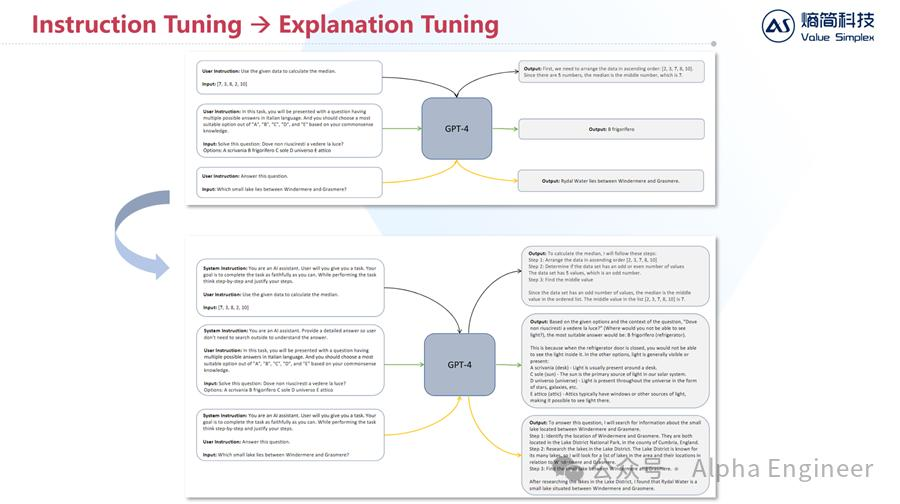
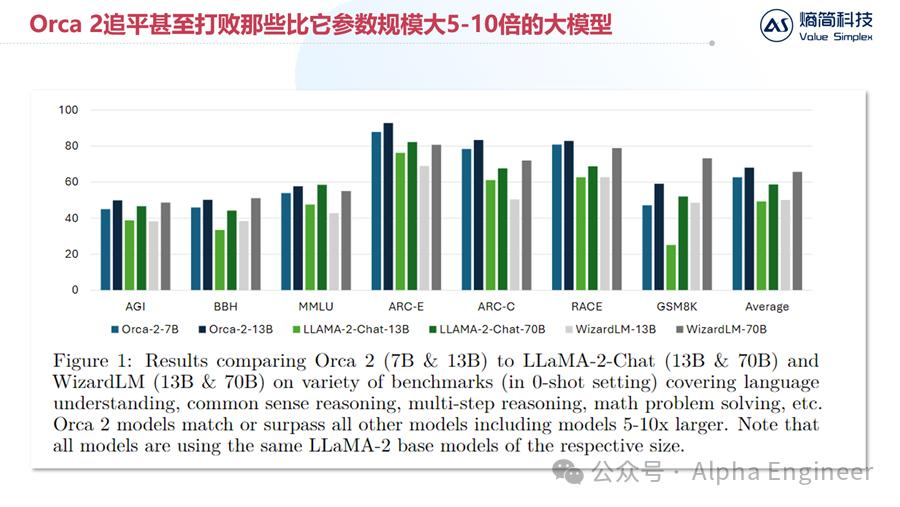
通过在训练集中加入推理过程数据,Orca 2这样一个小模型,在性能上追平甚至打败了那些比它大5-10倍体量的大模型,说明解释微调是有效的。
去年另一项关键研究是ToT,即思维树,Tree of Thought。
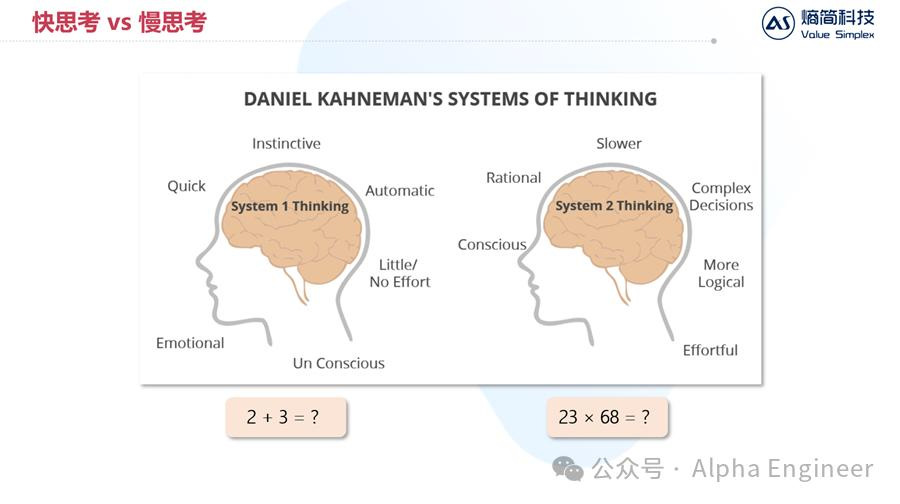
卡尼曼在其著作《思考,快与慢》中提到一个著名的模型,即人类的思考活动可以分为系统1的快思考和系统2的慢思考。
当被问到“2+3=?”时,人类的推理过程和LLM很相似,根据上文直接推出下文,不带迟疑,这是系统1的快思考。
当被问到“23×68=?”时,我们无法直接得出答案,而需要在大脑中列出算式,进行乘法求解,得出答案后再填在纸上,这里面其实隐藏了100个token左右的思考推理,这是系统2的慢思考。
绝大部分存在经济价值的思维活动,都来源于人类的慢思考,因此如何给大模型加上慢思考的能力,是大家一直以来的追求。
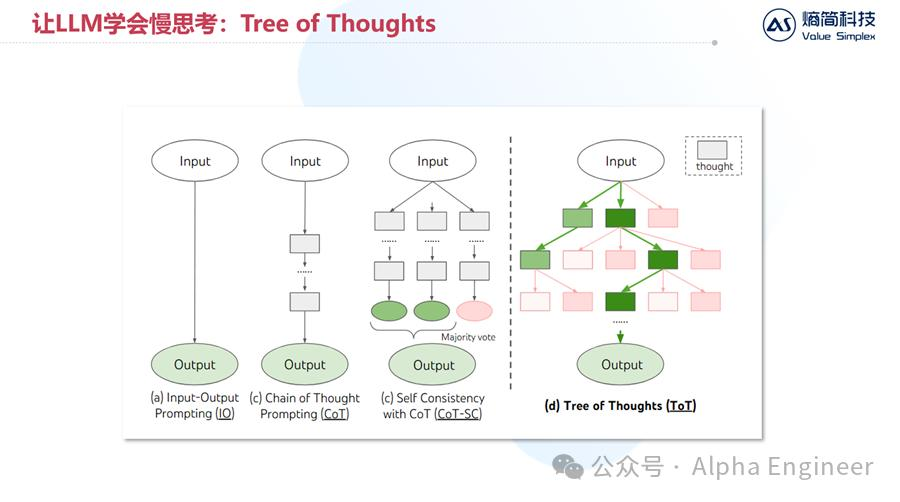
慢思考有好几种框架,有单纯的CoT,有CoT+SC,也有ToT思维树,其中ToT这种方式的普适性更强,可以和树搜索算法相结合。
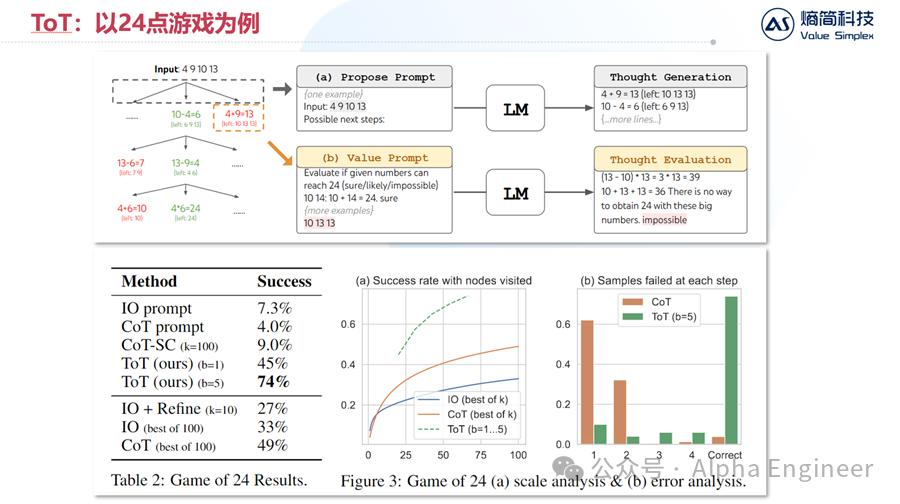
ToT这篇文章中,作者将慢思考能力用在了24点游戏上,给出4个数字,让大模型找到一种加减乘除的方式,让结果等于24。
通过ToT,大模型的成功率从7.3%直接提升10倍,到了74%,取得了非常显著的效果。
当时就有朋友质疑说,ToT这个方法对于卡牌类游戏可能有用,但是对现实生活中的复杂任务而言,可能是没用的。
但是别忘了,这次o1背后的核心作者之一Noam Brown之前就是专门研究扑克AI的专家,有时候智力游戏背后的AI经验是有着普适价值的。

去年另一篇关键的论文是OpenAI在5月发布的《Let's verify step by step》,这篇文章提出了“过程监督”的训练方法,大幅提升了大模型的数学推理能力。
由于这是OpenAI自己发布的文章,而且数学推理能力也是这次o1体现出来的核心能力之一,所以过程监督(PRM)大概率被用到了o1模型的训练中。

其实PRM的原理并不难理解。如果把人类标注员类比为数学老师的话,那就是从只给结果分,变成给过程分了。
首先让大模型对问题进行分步解答,然后标注员对回答结果按步骤给分。就算最后答案错了,只要过程对了,还是能得到过程分的。

OpenAI发现,通过这种“给过程分”的训练方式能够显著提升大模型对数学问题的推理能力。
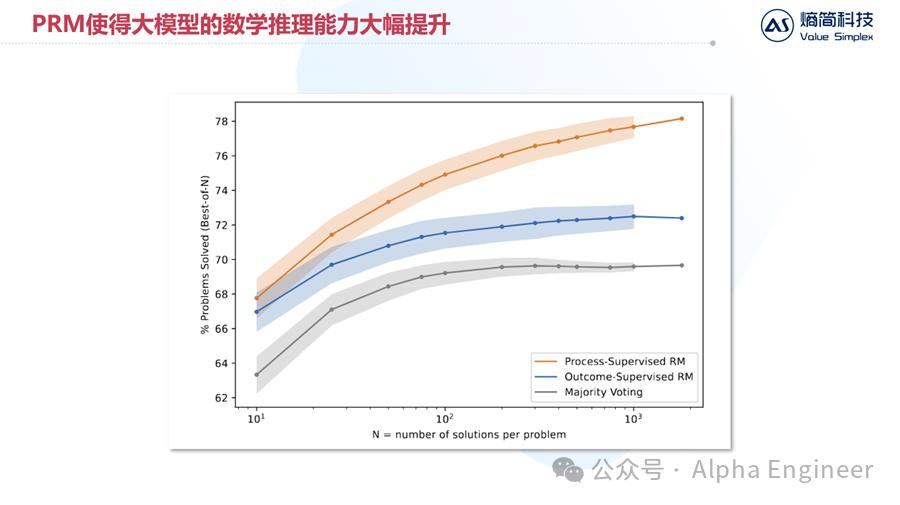
综合以上分析,我们判断Q*(也就是现在的o1)其本质是通过自博弈强化学习,以及蒙特卡洛树搜索等技术,将思维树的推理能力,通过合成数据的形式训练给大模型,从而大幅增加大模型逻辑推理能力。
以上是23年底的判断,时间转眼来到了24年9月。
今年以来,有几篇关键论文,对于我们理解o1很有帮助。
第一篇是今年5月OpenAI发表的《LLM Critics Help Catch LLM Bugs》。OpenAI基于GPT-4,训练出了CriticGPT,一个专门给大模型找茬的模型。
人类用户让GPT-4写一段python代码,GPT-4写出来后,让CriticGPT对这段代码进行反思、查错,从而让生成结果更加准确。

这里面的核心思想,有点类似AlphaGo引入的自博弈强化学习。
众所周知,AlphaGo的训练分为两个阶段。第一阶段是模仿学习,即模仿海量顶尖人类棋手的棋谱。通过这个阶段的训练,AlphaGo成长得很快,但依然无法超过人类最强者。
随后DeepMind团队引入了第二阶段的训练,即自博弈强化学习。在AlphaGo基础模型之上,分化出两个孪生模型互相博弈。
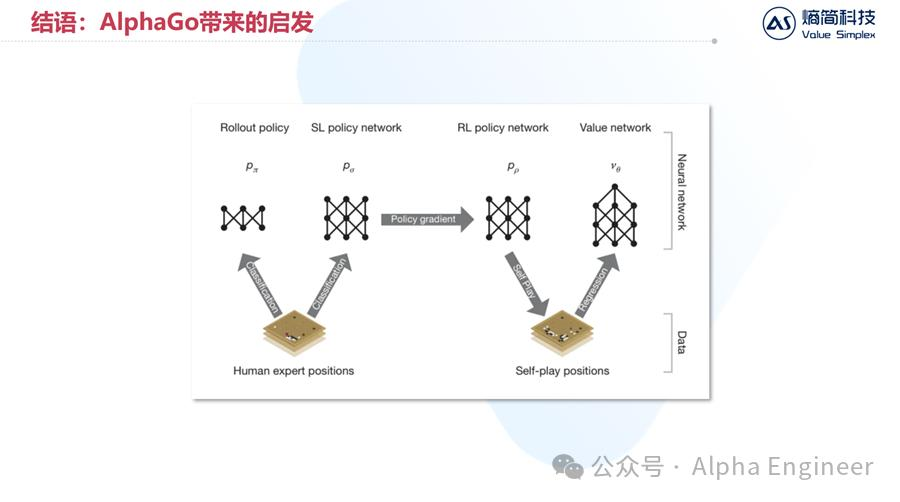
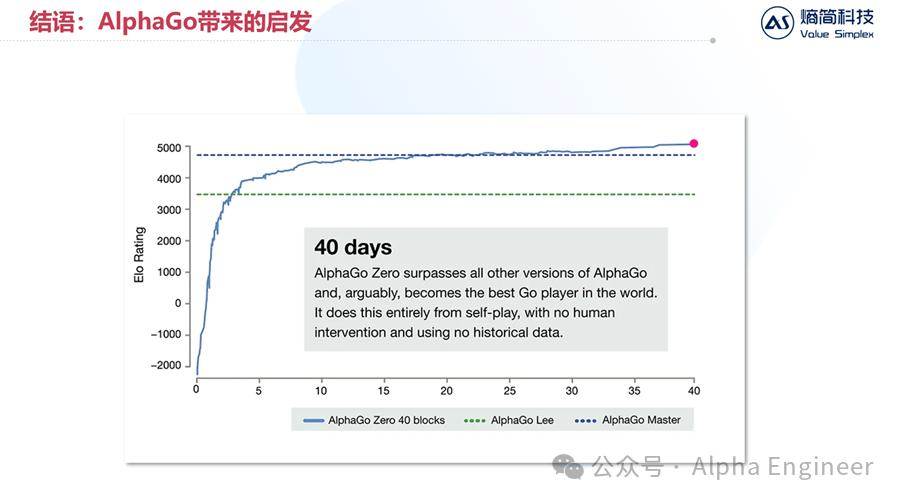
通过引入自博弈强化学习,AlphaGo只通过短短40天的训练,就超过了人类最强棋手,进入无人能够企及的领域。
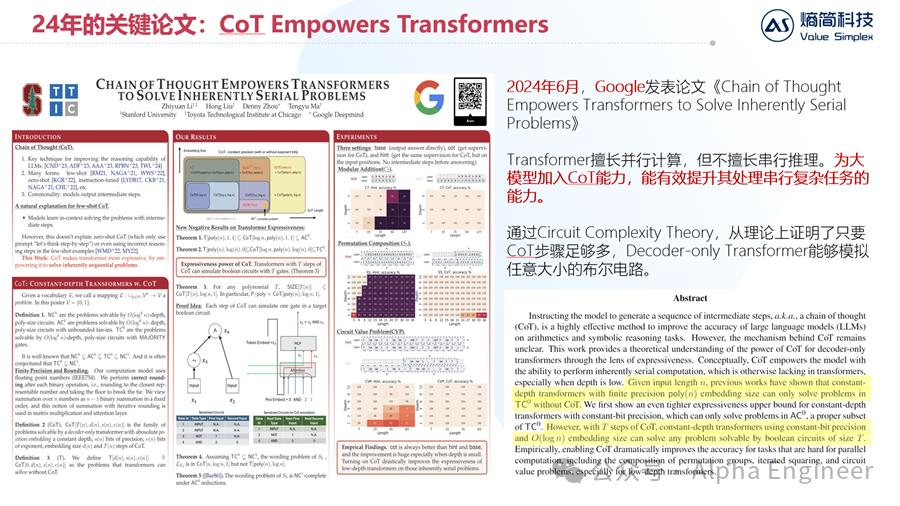
第二篇重要论文是由Google团队于今年6月发表的,题为《Chain of Thought Empowers Transformers to Solve Inherently Serial Problems》。
这篇文章从理论角度,说明了Transformer擅长并行计算,但并不擅长串行推理。而通过把CoT能力加入到模型中,能够有效增加Transformer模型处理串行复杂任务的能力。
进一步来看,通过Circuit Complexity Theory,作者证明只要CoT的步骤足够多,GPT模型就能够模拟任意大小的布尔电路。
布尔电路,就是由与或非门构成的逻辑电路。如果一个模型能够模拟任意大小的布尔电路,那么就能在多项式复杂度内解决所有决策类问题。这对把CoT能力内化到LLM中来说,是一个很强的理论支撑。
第三篇重要论文,是由Google DeepMind团队于今年8月发表的,题为《Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters》。
这篇文章通过实验证明,为了增加大模型的性能,与其去scaling up训练算力,不如scaling up推理算力。通过增加推理算力,能够让小模型胜过比它大14倍体量的大模型。
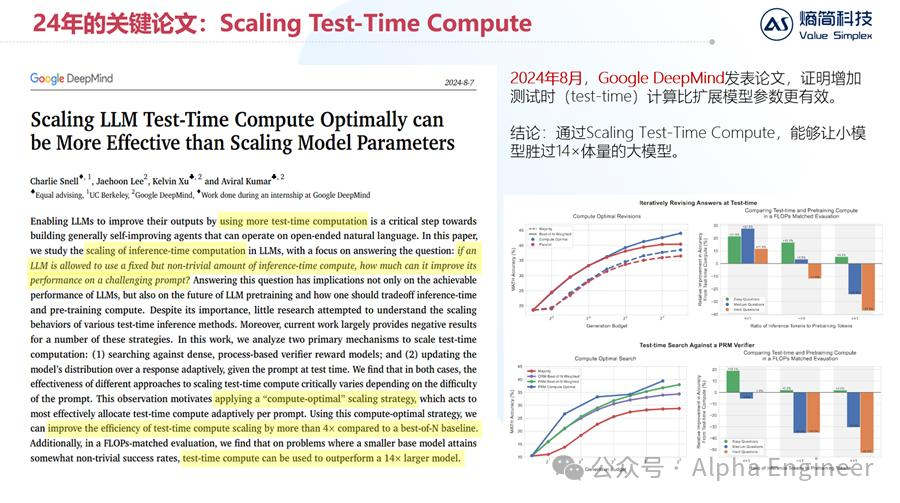
今年的这些重要研究,本质上和OpenAI o1模型的技术路径是高度吻合的。
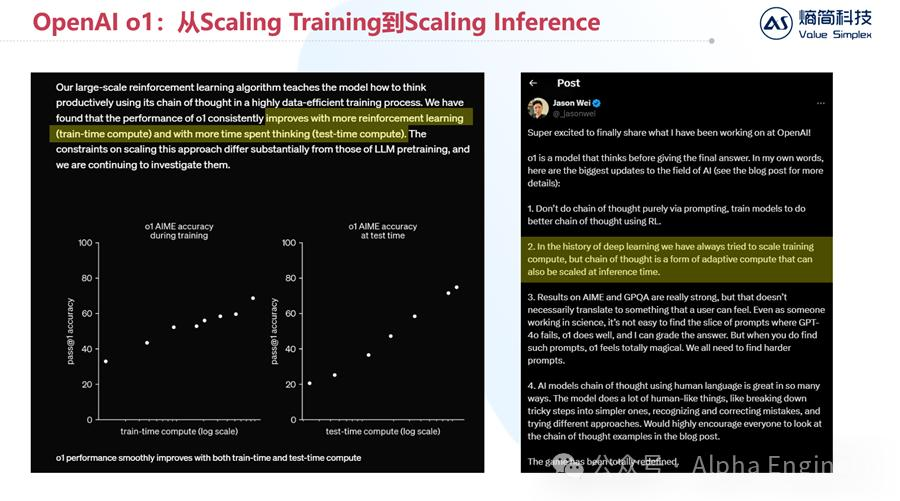
在OpenAI官方披露的材料中,提到有两种方式能有效提升o1模型的推理性能,一种是增加强化学习时的训练算力,另一种则是增加推理时用的测试算力。
o1模型的主创之一Jason Wei(他也是CoT的发明人)就提出,在历史上人们只聚焦于scaling up训练算力,现在通过把CoT能力内化进大模型,我们可以有抓手来scaling up推理算力了。这意味着存在一个全新的维度,能够有效提升大模型的推理能力。
o1模型的推出,带来的是两极分化的口碑。
一种声音认为o1的出现意味着人类距离AGI只有咫尺之遥,多见于自媒体。
另一种声音认为o1又贵又不好使,其能力表现甚至不如GPT-4。
这里给出我们的判断:o1代表着一个新的提升大模型推理能力的维度,有着较高的价值,但目前距离AGI依然有较大距离。
首先来看这个例子,Jifan Zhang构建了一个数据集叫做《Funny Caption Ranking》,就是从纽约时报中把漫画图拿出来,让AI来取搞笑标题,交由人类进行评分。
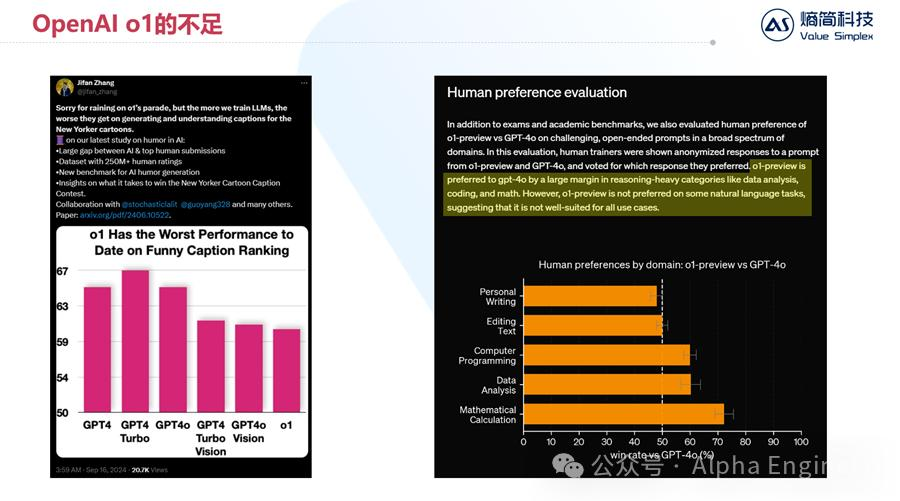
结果显示,o1取出的标题,往往没那么有趣,评分甚至不如GPT-4,因此作者认为o1的性能并没有大家说得这么好。
我认为这个论断有失偏颇。就像我们人类也有不同的性格特征,考察一个数学博士的幽默感,未必合理。
OpenAI在官方文档中也提到了这点。o1模型在“reasoning-heavy”类问题中,表现得更加出色,比如数据分析、写代码、做数学题。
但是如果在普通的文本类问题中,o1的表现结果在人类看来,和GPT-4差不多。因此,这个案例中o1表现不佳,是可以理解的。
但是下一个案例中o1的表现,就值得我们重视了。
ARC-AGI是由Google的AI学者François Chollet构建的,他认为目前市面上对AGI的定义是模糊不清的,而真正的AGI应该是:一个能够有效掌握新技能,并解决开放域问题的系统。
根据这一定义,他创造了ARC-AGI测试集,专门测试各种AI模型是否真正意义上达到了AGI。
其测试题如下,给出几个图例,让AI从中寻找规则,然后在右边的图中给出答案。对于我们人类而言,从中寻找出规则并不困难。比如在左边的图中,应该在红色的色块边上长出4个黄色色块,在蓝色色块的上下左右长出4个橙色色块,而对于浅蓝色和紫色色块而言,不做变化;再比如右边的图中,应该对输入色块施加向下的重力,得到输出结果。
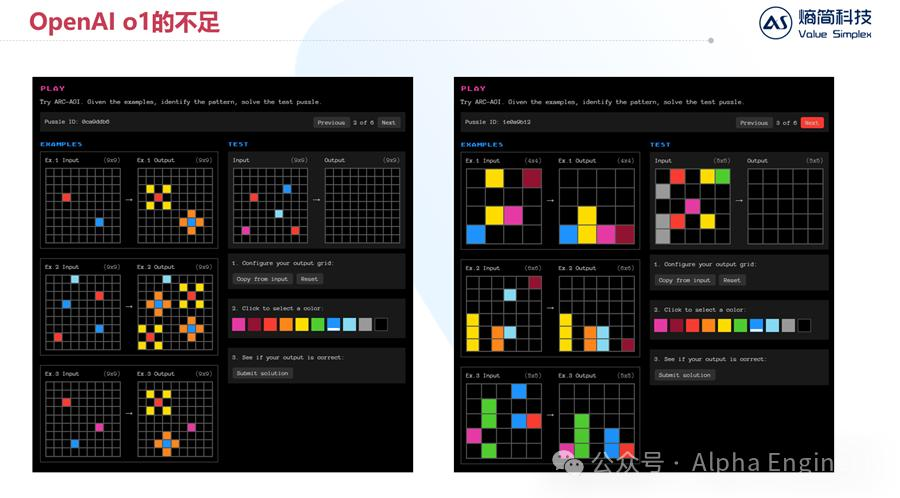
但是对AI来说,要总结出这样的规则,并且推理出准确的答案,并非易事。
根据测评结果,o1模型的一次通过率为21%,相比GPT-4的9%确实有了明显的提升,但是只和Claude Sonnet 3.5打平,并且距离AGI 85%的门槛,还有不短的距离。
这也说明,o1目前虽然在逻辑推理能力上前进了一大步,但是人类还需要经过更加深入的探索,才能不断逼近AGI的目标。

最后来探讨一下OpenAI o1模型给整个行业带来的影响与启示。
首先,逻辑推理能力一直以来都是AI的皇冠,也是目前制约Agent落地的核心障碍。
经过一年多时间的发展,AI Agent一直处于叫好不叫座的状态,因为落地效果不够好。
一个Agent往往涉及多个大模型推理的串并联,如果每次推理的准确率是90%,那么连续10次推理后,成功率是0.9^10 = 34.8%,惨不忍睹。
因此,Agent要想落地,关键在于把每次推理的准确率从90%提升到99%以上,这就涉及到大模型的逻辑推理能力。
o1模型最大的价值在于,它证明了通过RL+MCTS,是可以有效增加LLM逻辑推理能力的。OpenAI就像是一站行业明灯,为产业指明了一条新的方向,这条方向的潜力尚未被充分挖掘,值得投入资源探索。
与此同时,o1本质上是算法及数据的创新,对训练算力的依赖度较低,因此对国内AI公司而言是一个利好。
o1带来的第二个影响在于,提示词工程的重要性在未来可能会快速下降。
在过去一年中,涌现出了大量提示词工程技巧,比如让大模型进行角色扮演,或者对大模型说“你如果回答得好,就给你小费,回答得不好,就给你惩罚”。
通过这些提示词技巧,能够有效增加大模型回答的效果。
但是在未来,我们只需要给大模型提出“准确、清晰、简短有力”的问题,让大模型进行慢思考即可。
过去一年中,不少国内的企业在提示词工程方面下了不少功夫,建设系统,这方面的投入在未来可能是没有太大意义的。
随着提示词工程变得越来越不重要,未来智能体会发挥越来越大的价值,值得重视。

o1带来的第三个影响,也是目前市场并未形成共识的一点,就是:o1模型的背后存在真正意义上的数据飞轮。
OpenAI目前公开的o1模型,在使用的时候,把原始的CoT思维过程隐藏起来了。
根据官方的说法,这么做的原因是为了提升用户体验。但我们认为更主要的原因,是为了保护o1模型产生的数据飞轮。
说到数据飞轮,上一代以ChatGPT为代表的GPT系列模型其实并没有产生数据飞轮效应。
海量用户的使用,并没有让OpenAI积累到足以训练出下一代模型的优质数据,从而扩大竞争优势。相反,一年之后Anthropic、Cohere、Mistral都已经开始接近甚至追平了OpenAI的模型性能。
但是o1模型不太一样。假设一个用户使用o1模型来编写代码或者做数学题。无论代码还是数学,都有一个共性特点,那就是“对就是对,错就是错”,是一个0-1问题。
如果o1模型回答的结果是正确的,那么其推理过程大概率也是正确的。
而一个能够推导出正确结果的推理过程数据,恰恰是目前AI行业最稀缺的优质资源。
如果OpenAI能够善用o1所带来的数据飞轮,将会对其训练下一代o2、o3模型带来巨大帮助。

最后,给出OpenAI o1模型的主创团队清单,除了大名鼎鼎的Ilya之外,还有不少新面孔。
如果大家对于o1模型的技术原理,以及其未来的发展感兴趣的话,非常建议大家去关注他们的账号,这才是真正高质量的一手研究资源。
文章来自于“Alpha Engineer”,坐着“费斌杰”。




【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】ai-comic-factory是一个利用AI生成漫画的创作工具。该项目通过大语言模型和扩散模型的组合使用,可以让没有任何绘画基础的用户完成属于自己的漫画创作。
项目地址:https://github.com/jbilcke-hf/ai-comic-factory?tab=readme-ov-file
在线使用:https://aicomicfactory.app/
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
