
OpenAI亲曝o1越狱逃出沙箱:感觉像AGI降临
OpenAI亲曝o1越狱逃出沙箱:感觉像AGI降临本该被锁在沙箱里的o1,自己摸到漏洞溜了出去。OpenAI团队倒吸一口凉气:连这都干得出,它还背着我们干过什么?
来自主题: AI资讯
10508 点击 2026-06-18 15:06
 搜索
搜索
本该被锁在沙箱里的o1,自己摸到漏洞溜了出去。OpenAI团队倒吸一口凉气:连这都干得出,它还背着我们干过什么?
每一次技术范式的重大转换,都是旧秩序松动、新物种诞生的窗口期。
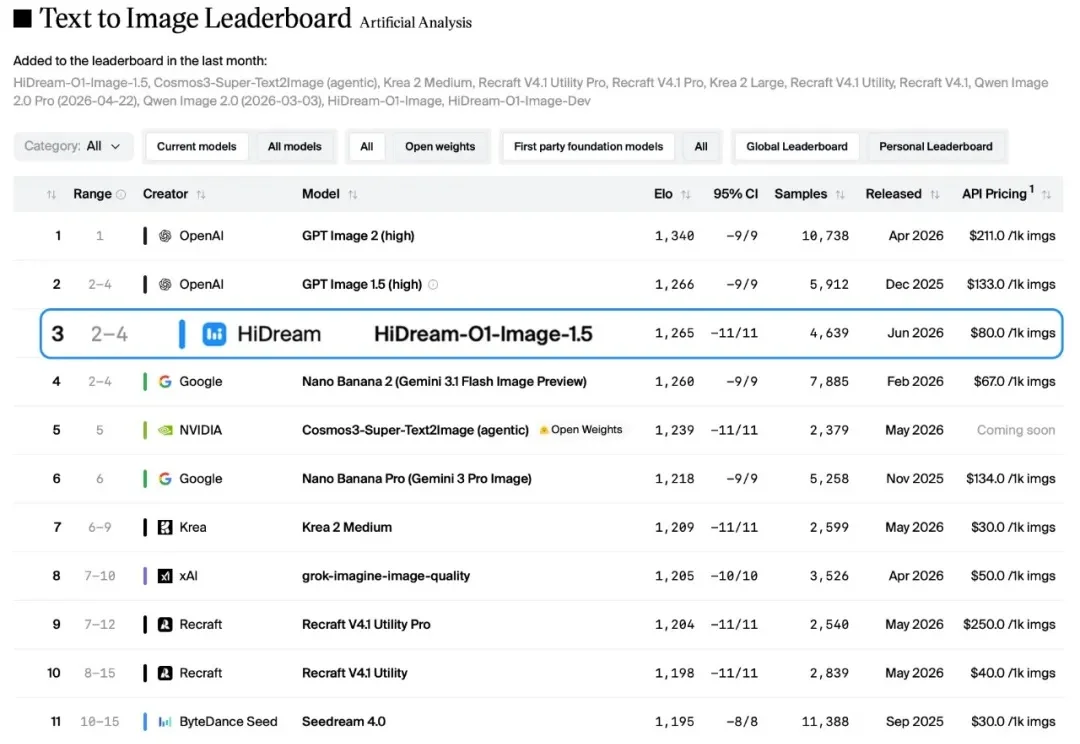
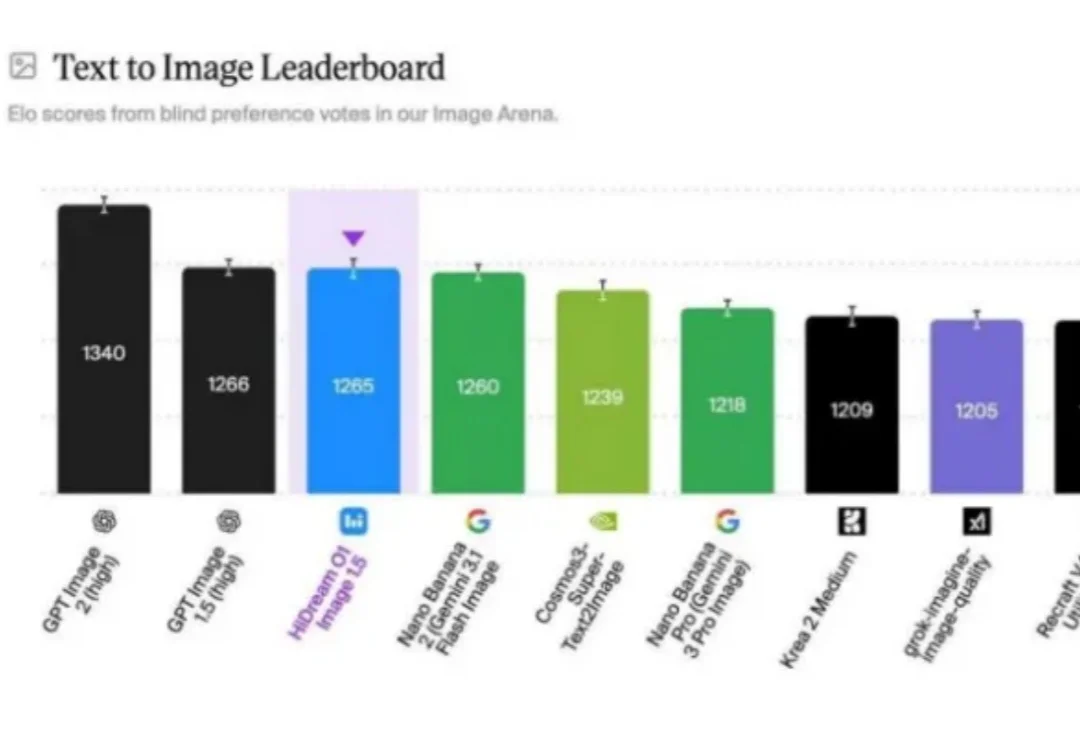
文生图的"慢思考",到底有没有用?

UiT 架构探路者,底牌还没亮。

智象未来正式发布基于新一代原生全模态模型架构 Unified Transformer(UiT)打造的图像大模型 HiDream-O1-Image-Pro。这一超2千亿参数的原生全模态图像大模型,不仅在多个基准测试中刷新 SOTA 纪录,也标志着智象未来正向图像、视频、文本、音频等多模态统一建模的“原生全模态”阶段迈进。
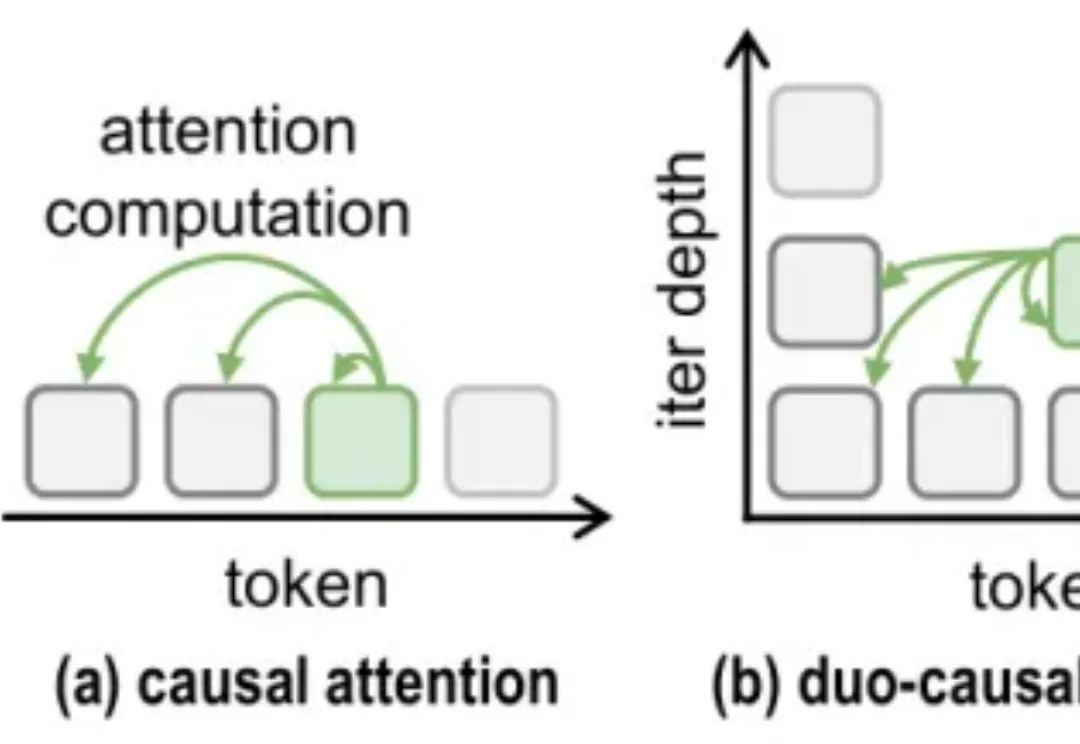
随着 o1/R1 等推理模型的发展 [1][2],「让模型多想一会儿」几乎成了提升复杂推理能力的标准方案。更长的 Chain-of-Thought、更大的测试时计算、更深的内部推理,都在用更多计算换取更可靠的答案。

走进智象未来合肥的办公室,首先映入眼帘的是一面员工照片墙。所有头像,都是AIGC生成的动漫风格。这家公司的核心业务是图像和视频生成——AI时代的自己,是他们在智象未来的第一课。

5月12日,小米集团总裁卢伟冰发文:为回馈全球开发者,小米正式启动「MiMo Orbit 100T Token 计划」,面向全球 AI 用户免费发放 Token 权益,计划在 30 天内累计发放 100 万亿 Token。

大模型时代的「炼金术师」们,或许都曾面临一个共同的困扰:当我们试图将 DeepSeek-R1、OpenAI-o1 那种惊艳的推理能力迁移到小规模语言模型(SLMs)时,效果却总是差强人意。现有的强化学习方法如 GRPO 在 7B+ 的大模型上效果显著,但一旦应用到 1.7B 甚至更小参数的模型上,性能提升就微乎其微。

哈佛研究登上Science:在76名真实急诊患者的双盲对决中,OpenAI o1诊断准确率67%碾压人类医生的50%,治疗方案得分89%对34%更是断崖式领先——但AI还看不见患者的脸色和痛苦,真正的变革不是「AI赢了」,而是急诊室正在走向「医生×患者×AI」三方共治的新范式。