
时薪 15 美元的新工种:把 iPhone 绑在脑门上,替 AI 蒸馏自己
时薪 15 美元的新工种:把 iPhone 绑在脑门上,替 AI 蒸馏自己你或许刷到了一段来自印度南部服装厂的视频。 工厂工人佩戴头戴摄像头,记录手部动作以训练人工智能系统。 这是因为随着特斯拉、Figure AI 等公司竞相开发人形机器人,训练它们所需的真实世界动作数据变
来自主题: AI资讯
9834 点击 2026-04-26 22:36
 搜索
搜索
你或许刷到了一段来自印度南部服装厂的视频。 工厂工人佩戴头戴摄像头,记录手部动作以训练人工智能系统。 这是因为随着特斯拉、Figure AI 等公司竞相开发人形机器人,训练它们所需的真实世界动作数据变
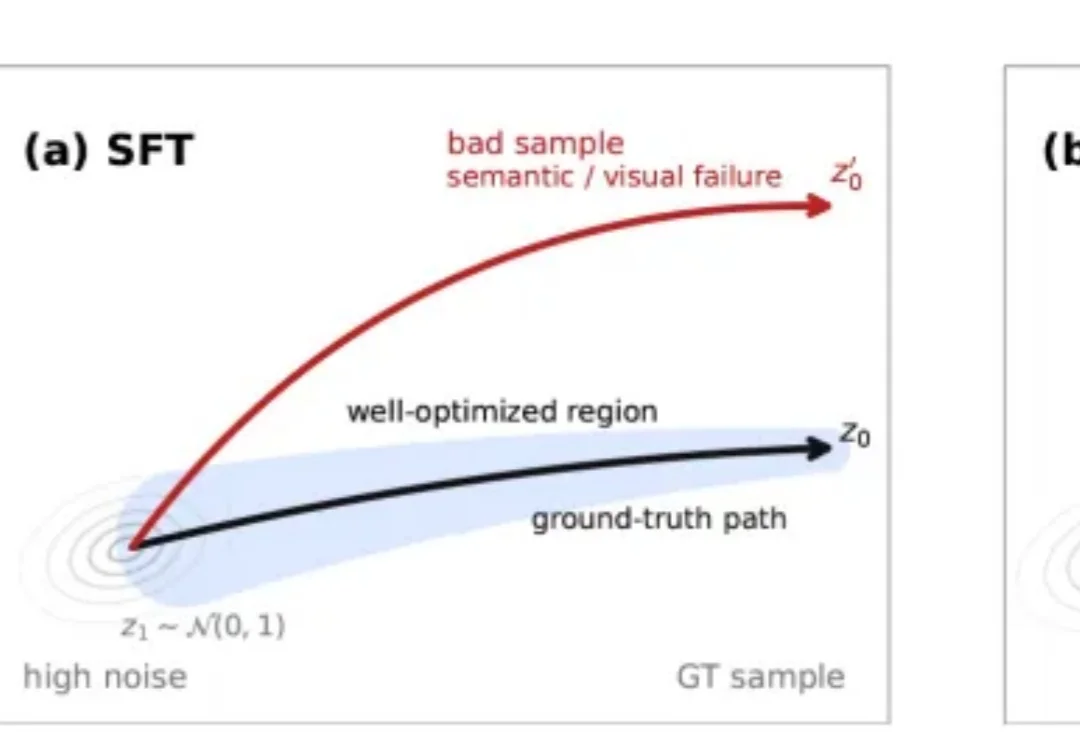
近日,腾讯混元团队提出HY-SOAR (Self-Correction for Optimal Alignment and Refinement),一种面向扩散模型和流匹配模型的数据驱动后训练方法。

OpenAI的人才地震还在继续!刚刚,前研究副总裁Max Schwarzer宣布离职,这位亲手主导o1、o3和整个GPT-5系列post-training的核心人物,选择加入Anthropic,重返一线RL研究。
其依据是Micro1的25亿美元(约合人民币173亿元)最新估值。福布斯报道称,成立于2022年的Micro1被曝正在以25亿美元估值洽谈新融资,如果Micro1锁定或超过这一估值,安萨里在该公司持有的约42%股份价值将超过10亿美元(约合人民币69亿元)。
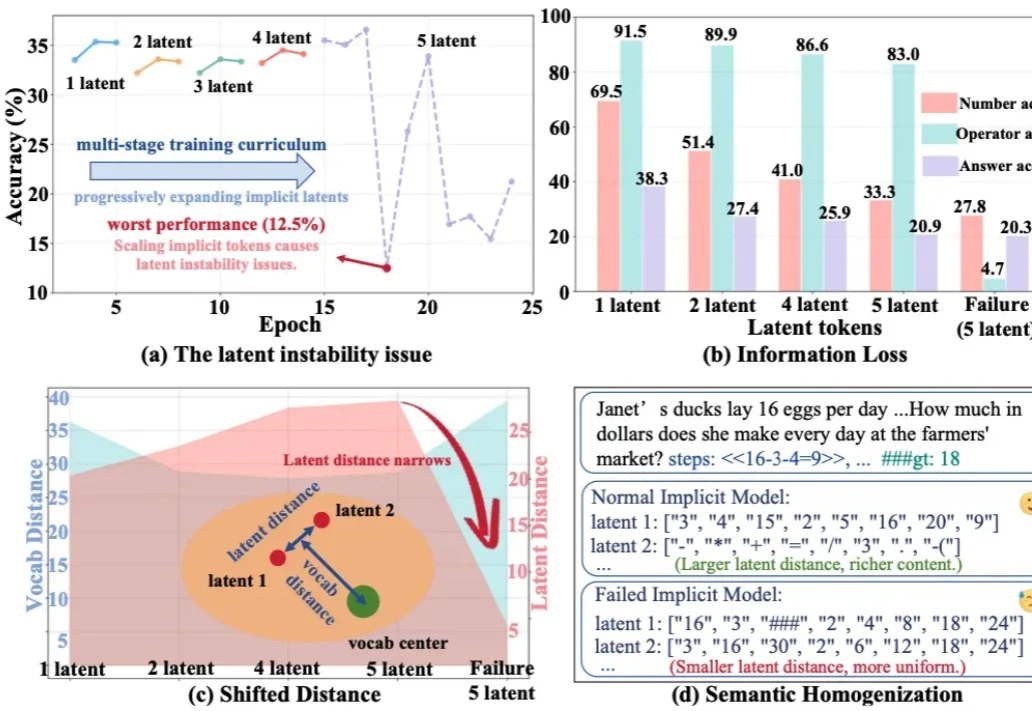
今天推荐一个 Implicit Chain-of-Thought(隐式推理) 的最新进展 —— SIM-CoT(Supervised Implicit Chain-of-Thought)。它直击隐式 CoT 一直「扶不起来」的核心痛点:隐式 token 一旦 scale 上去,训练就容易塌缩到同质化的 latent 状态,推理语义直接丢失。
如果没有PhD,是不是就和前沿AI研究没关系了?至少在Noam Brown看来,未必。这位OpenAI 研究员、o1的核心贡献者,刚刚分享了一串“非典型研究员”的经历。

o1从榜首暴跌至#56,Claude 3 Opus坠入#139。LMSYS榜单揭示残酷真相:大模型的「霸主保质期」只有35天!这不是技术迭代,这是对所有应用层开发者的降维屠杀。
12月伊始,可灵AI接连放出大招。全球首个统一的多模态视频及图片创作工具“可灵O1”、具备“音画同出”能力的可灵2.6模型、可灵数字人2.0功能……5天内5次“上新”,直接让生成式AI领域的竞争“卷”出新高度。
昨晚,AI视频领域,终于来了一点新东西。
这说明o1不仅能够使用语言,还能够思考语言,具备元语言能力(metalinguistic capacity )。由于语言模型只是在预测句子中的下一个单词,人对语言的深层理解在质上有所不同。因此,一些语言学家表示,大模型实际上并没有在处理语言。