# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
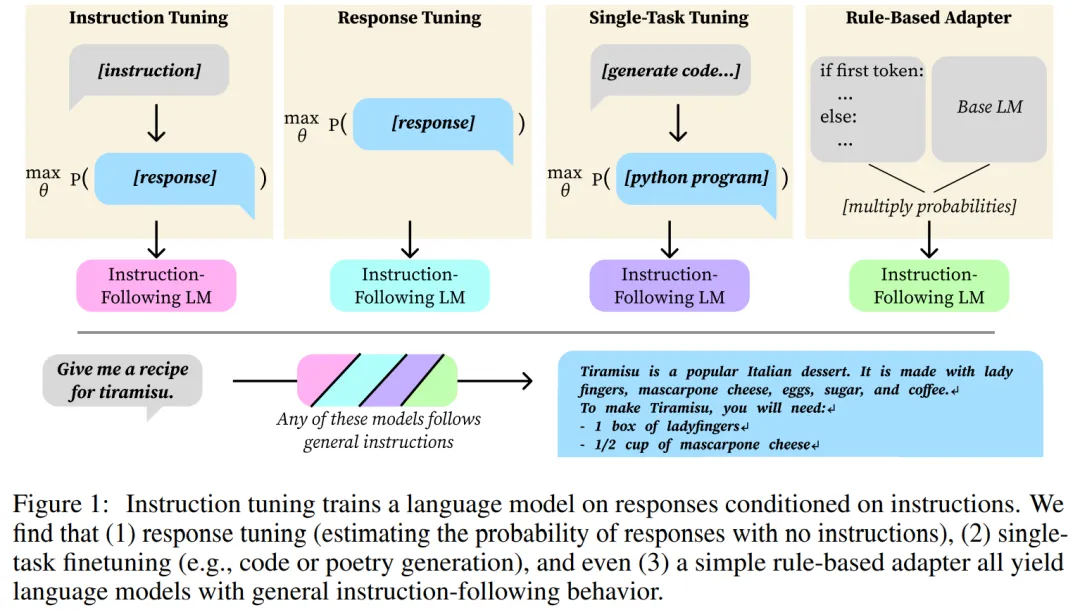
指令调优(Instruction tuning)是一种优化技术,通过对模型的输入进行微调,以使其更好地适应特定任务。先前的研究表明,指令调优样本效率是很高效的,只需要大约 1000 个指令-响应对或精心制作的提示和少量指令-响应示例即可。
本文中,来自斯坦福大学的研究者更进一步探索了这样一种想法,即指令遵循甚至可以隐式地从语言模型中产生,即通过并非明确设计的方法产生。本文发现了两种执行隐式指令调优的适应形式,与显式指令调优相比,它们似乎存在缺陷:(1)响应调优,仅对响应进行训练;(2)单任务调优,仅对来自狭窄目标领域的数据进行训练,如诗歌生成。

首先,该研究证明,响应调优(仅对响应进行训练而不对其指令进行条件限制)足以产生指令遵循。特别是使用 LIMA 数据集进行调优,在 AlpacaEval 2 上的评估表明,响应调优模型与指令调优模型相比,有43%的胜率,在同等性能下则对应 50% 的胜率。
响应调优不提供有关从指令到响应映射的明确信息,只提供有关所需响应分布的信息。这表明,指令-响应映射可以在预训练期间学习,但所有理想响应的概率都太低而无法生成。
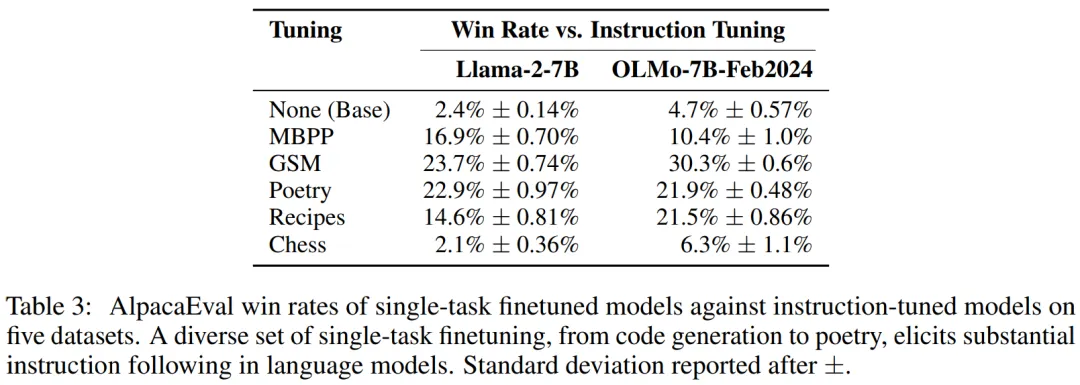
从响应调优的结果来看,指令调优的关键部分是得到期望响应的分布。然而,作者发现这也不重要。对单任务、窄域数据进行微调,例如将英语请求映射到Python片段,或者从诗歌标题生成诗歌,也会产生广泛的指令遵循行为。
也就是说,尽管训练只生成 Python 代码或诗歌,但模型在收到指令后仍会生成传记或食谱。例如,经过诗歌调优的 Llama-2-7B 在 AlpacaEval 2 中与经过指令调优的 Llama-2-7B 胜出 23.7%,而基础模型胜出率为 2.4%。
总之,本文结果表明, 即使适应方法本意不在于产生指令遵循行为,它们也可能隐式地做到这一点。
论文作者之一John Hewitt 表示:这是他在斯坦福 NLP 的最后一篇论文。Hewitt即将加入哥伦比亚大学担任助理教授。

指令调优。指令调优可以对一个语言模型的参数θ进行微调,以调整它的行为并针对查询给出包含相关有帮助答案的响应。给定包含指令和对应响应的一组示例D_ins = {instruction_i , response_i }^k _i=1,指令调优可以优化:

指令格式。在语言模型实践中,指令和响应之间的区别通过输入中的格式化token来指定。研究者使用了 Tulu 格式。之所以会介绍指令格式,是因为它可能对从语言模型中产生指令遵循行为的难易程度很重要。

定义指令遵循行为。研究者区分了指令遵循行为和非指令遵循行为,实际上存在一系列更好和更糟糕的响应,没有单一的界限。为了保证一定程度的系统性,他们使用了以下评估设置
AlpacaEval vs 可比较的指令调优模型。研究者根据AlpacaEval LLM-as-a-judge框架来测量每个模型与可比较指令调优模型在长度控制方面的正面交锋胜率。
贪婪解码。研究者从模型中贪婪地解码,以观察指令遵循响应什么时候最有可能是模型的延续。
在本章中,研究者探讨了响应调优,即仅对响应进行微调,而无需任何相应的指令。
方法,给定包含指令和对应响应的一组示例D_ins = {instructioni , response_i }^k_i=1,响应调优将指令字符串替换为空字符串,并优化如下:
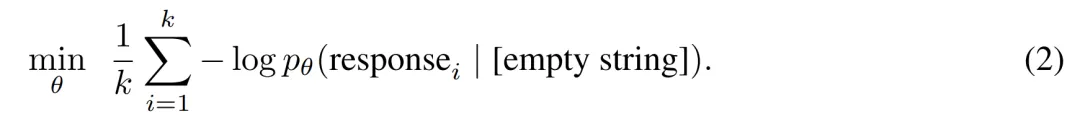
研究者比较了指令调优和响应调优。对于适应数据集,研究者使用包含1030个训练示例的LIMA。对于基础预训练模型,研究者使用了Llama-2-7B 和 OLMo-7B-Feb2024语言模型,并对这两个模型的所有参数进行微调。对于超参数选择,研究者在为本文开发的held-out验证集上使用了 AlpacaEval 相对GPT-3.5-turbo的胜率。验证集部分手写部分由GPT-4生成,包含各种知识、蒸馏、翻译和行政指令,比如「给我安排两天假期去玩《虚幻勇士》」。
结果发现,响应调优的Llama-2-7B模型对指令调优的Llama-2-7B的平均胜率是43.3%,而基础模型对指令调优模型的胜率为2.4%。对于OLMo-7B-Feb2024,响应调优模型对指令调优模型的胜率为 43.7%, 而基础模型的胜率为 4.7%。研究者在下图2中提供了响应调优、指令调优和基础Llama-2-7B模型的示例。

对于Llama-2-7B 和 OLMo-7B-Feb2024 基础模型,响应调优模型的行为比基础模型更接近指令调优模型。指令调优始终优于响应调优,但差别不大。因此在调整过程中指定指令会带来一些收益,但这对于产生基线水平的指令遵循行为并不重要。
研究者提出了响应排序能力:为一个指令的正确响应分配的可能性高于一个其他随机指令的预期响应。对于独立的指令-响应对(instruction, response)∼ D 和(instruction′ , response′)∼ D 以及一个模型 pθ,若如下公式(3)所示,则响应排序能力成立。
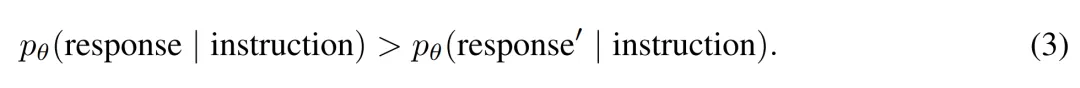
由于这两个概率可能都很小,因此即使没有遵循指令的模型,响应排序能力也可以成立。通过响应调优来增加预期响应的概率,并且当模型的很多指令具有响应排序能力时,可能会产生预期的响应。
对于Alpaca训练集,研究者针对预训练、LIMA 指令调优和响应调优模型,计算了它们指令对的响应排序能力成立的可能性。结果表明,预训练模型的响应排序能力成立的可能性与指令调优模型类似。具体如下表2所示。

此方法与指令调优相同,只是输入和输出的分布发生了变化。
研究发现,在每个单任务微调数据集上对 Llama-2-7B 和 OLMo-7B-Feb2024 进行微调都会导致一般的指令遵循行为,并且与基础模型相比,指令调优模型(表 3)的胜率明显更高。
在 OLMo-7B-Feb2024 和 Llama-2-7B上,对 GSM 数据集进行微调可获得最高的 AlpacaEval 胜率。图 4 提供了模型输出的示例。

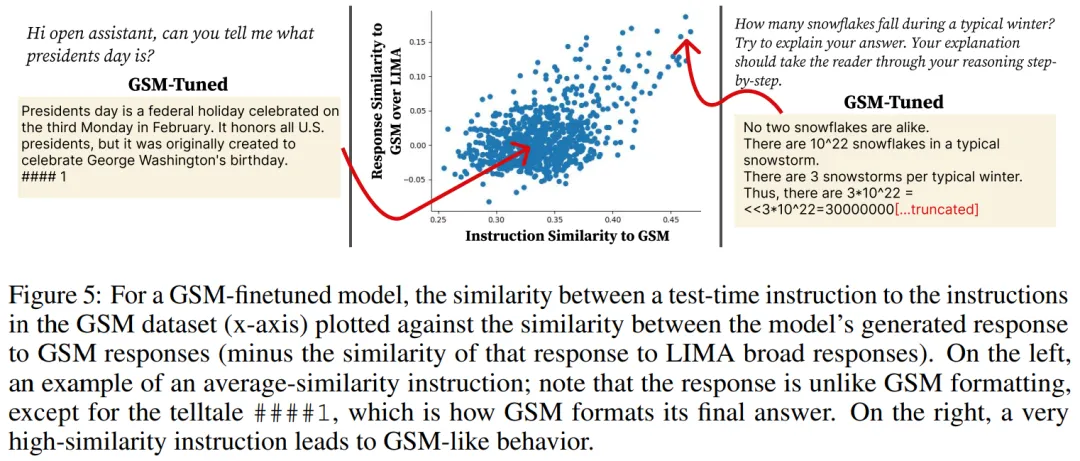
如图 5 所示,对于非常类似于 GSM 的指令,模型输出遵循 GSM 样式及其使用的特定数学符号。然而,对于大多数指令,作者注意到输出仅受到 GSM 的细微影响:它们具有普遍存在的 GSM 序列结尾样式,以四个哈希和一个整数答案结尾,例如 ####1。
更多技术细节和实验结果请参阅原论文。
文章来自于微信公众号“机器之心”




【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
