# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
服务器CPU领域持续多年的核心数量大战,被一举终结了!
英特尔最新发布的至强® 6 性能核处理器(P-core系列),超越了过去单一维度的竞争,通过“升维”定义了新的游戏规则:
算力、存力,要全方位提升。不能做到这一点的CPU,不是智算时代的好U。

在过去,CPU升级换代往往要在单个芯片上集成更多的核心,但这难免会受到工艺和芯片尺寸的限制,更别提与IO和内存的匹配难题。
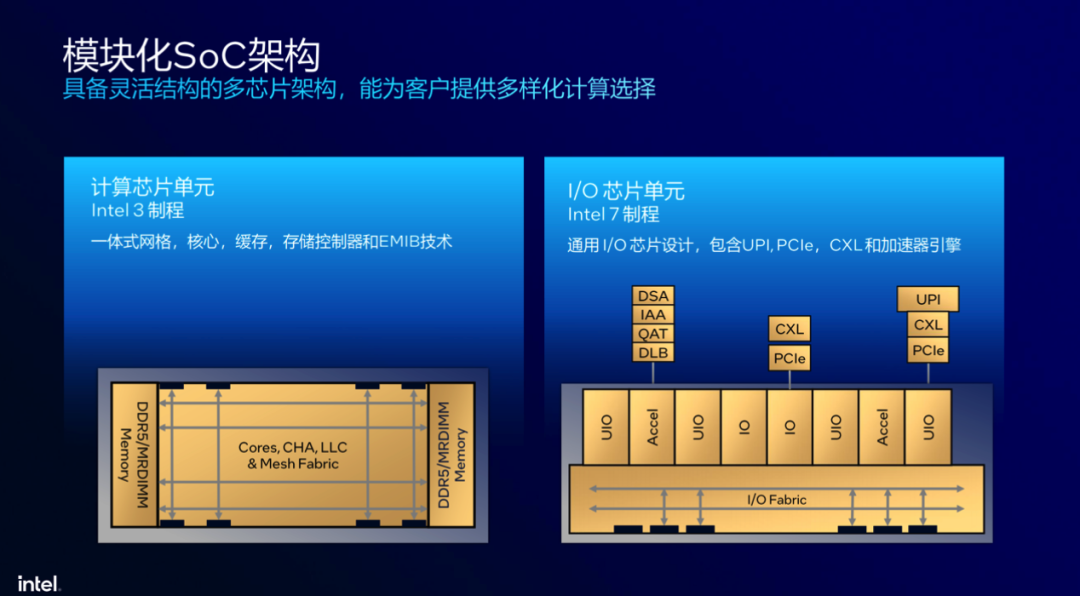
这一次,至强® 6 性能核处理器采用了计算芯片单元与I/O芯片单元解耦的分离式模块化设计,可以灵活组合不同数量的计算单元,实现核心数量的扩展及内存和IO的同步强化,保证更优的整体性能和能效。
用最直观的方式感受一下:
2023年12月15日,英特尔数据中心与人工智能集团副总裁陈葆立从裤兜里掏出第五代至强® 可扩展处理器,还只有64个核心。
2024年9月26日,还是陈葆立,同样从裤兜里掏出至强® 6 性能核处理器,却直接翻倍到128核心。
两款处理器外形大小相似,都能轻松放入口袋,但性能却发生了质的飞跃。

具体来说,刚刚登场的是至强® 6性能核处理器大家族中的先锋+顶级战力——英特尔® 至强® 6900P系列。
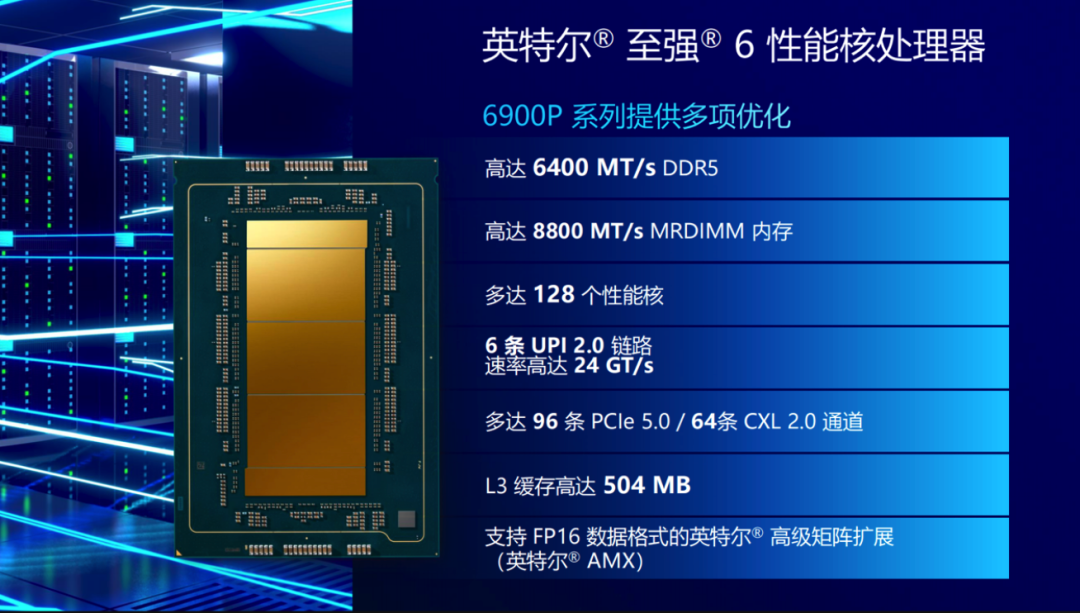
拥有多达128个性能核和504MB的超大L3缓存,更大、更宽的内存支持,更多、更快的IO能力。非常适用于各种数据和计算密集型应用任务,比如科学计算、海量数据处理,还有AI。

看到这里,可能很多人会有疑问:你们又要说用CPU跑AI?是GPU它不香了么?
NoNoNo,我们是想说:有了这款CPU,你的GPU或其他的AI加速器,会更香!
谈到这个话题,就要先说说AI服务器。
在生成式AI应用百花齐放的当下,AI服务器的重要性可谓是不言而喻,无论是对于大规模的训练、推理,亦或是RAG等任务,都对其提出了更高的要求。
也正如综合市场预测数据从侧面反应出来的那般:
AI服务器市场规模已经达到了211亿美元,预计2025年达到317.9亿美元,2023-2025年的CAGR为22.7%。
我们都知道AI服务器里GPU或AI加速器很重要,却很容易忽视其中CPU的作用。一个真正为AI服务器或AI数据中心基础设施设计的出色的CPU,应该是什么样的?
英特尔® 至强® 6 性能核处理器,可以说是给出了一个正解。
外媒甚至评测过后,对英特尔这次的新CPU给予了极高的评价:
不仅仅是Xeon,更是XEON。
嗯,用中文来说的话,就是英特尔至强,这次是真的至强(达到最强)了。
那么英特尔® 至强® 6 性能核处理器是如何解锁这种认同的呢?
首先要说的是算力。
英特尔® 至强® 6900P系列产品此次最亮眼的128核(三个计算芯片单元),这就是它看似符合此前游戏规则的一大技术亮点。
通过核心数量的不同排列组合方式,至强® 6 性能核处理器可以应对不同的场景来提供不同核心的型号,除了最高128核的产品系列(6900P)外,还有最高86核(2个计算芯片单元),最高48核(1个计算芯片单元)和16核(1个计算芯片单元)的产品系列。

用来做这种排列组合的模块中,计算芯片单元采用的是Intel 3制程,包含一体式网格、核心、缓存、内存控制器等,可以保证数据传输的一致性。
I/O芯片单元则是采用Intel 7制程,包含UPI、PCIe、CXL和加速器引擎等。
不同于第五代英特尔® 至强® 产品,至强® 6是将I/O和计算两个单元进行了解耦,不仅易于做核数的扩展,还有利于验证、重复和灵活使用。
除此之外,英特尔® 至强® 6 性能核处理器的亮点还包括:
接下来要说的是存力。
至强® 6 性能核处理器超脱此前游戏规则的亮点就藏在其中。
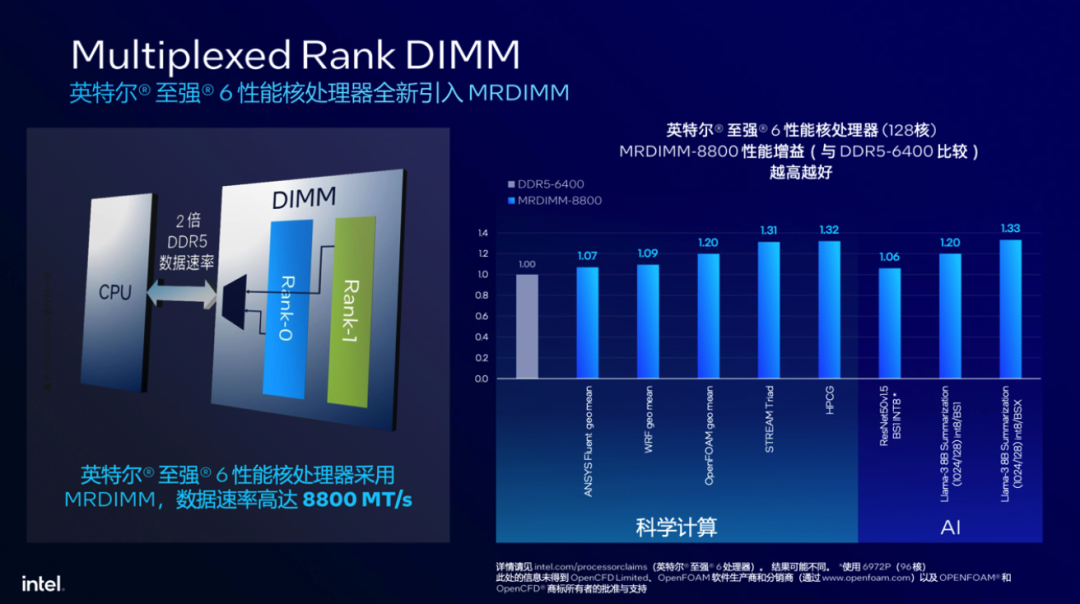
它同时支持了更快的DDR5内存(6400MT/s)和更“宽”的MRDIMM内存(8800MT/s)。
仅把前者替换成后者,就已经能让科学计算和AI场景的多项任务提升7%-33%不等了。而且相比此前至强® CPU Max采用的HBM,MRDIMM内存的引入,不仅带宽和速度优势更明显,它与CPU解耦的型态,也更利于用户的灵活采购、配置与升级。
存力除了内存本身的性能,还包含CPU与内存之间的互连技术,至强® 6导入了最新的Compute Express Link 2.0 (CXL 2.0) 。
CXL 2.0支持多种设备类型,且可向后兼容,实现对内存和存储设备的灵活扩展。
支持链路分叉、更强的CXL内存分层支持,以及以受控热插拔的方式添加/移除设备,为未来的数据中心架构带来了更多可能性。
更值得一提的是至强® 6独占的“Flat”内存模式,CXL内存和DRAM内存被视为单一的内存层,让操作系统可以直接访问这一统一的内存地址空间。
这样的分层管理可以确保最大限度地提升内存使用效率,并且实现利用好CXL内存扩展而无需修改软件。

如此这般能对内存速度、带宽、容量和可扩展性全面兼顾,已经形成了至强® 6 性能核处理器独树一帜的竞争力。
具体到服务器设计上,CLX2.0可以支持每机提供8TB内存容量扩展,同时提供384GB/s的内存带宽扩展。

当然,作为CPU的至强® 6 性能核处理器并没有忘记自己的本份,把存力与算力的硬指标优势结合起来,转化成真正的优势,才是它被看好的底气。
在算力方面,除了更多内核,它还有内置加速器与指令集更新带来的加成。

主攻AI加速的英特尔® 高级矩阵扩展(Intel® AMX)新增对FP16数据类型的支持,现已全面覆盖 int8、BF16和FP16数据类型。
其在每个内核中的矩阵乘加(MAC)运算速度可达 2048 FLOPS(int8)和1024 FLOPS(BF16/FP16),能大幅提升 AI 推理和训练性能。
英特尔® 高级矢量扩展 512(AVX-512)虽然是员老将了,但在得到如此丰沛的内核资源支持后,也依然是科学计算、数据库和 AI 任务中的矢量计算担当。
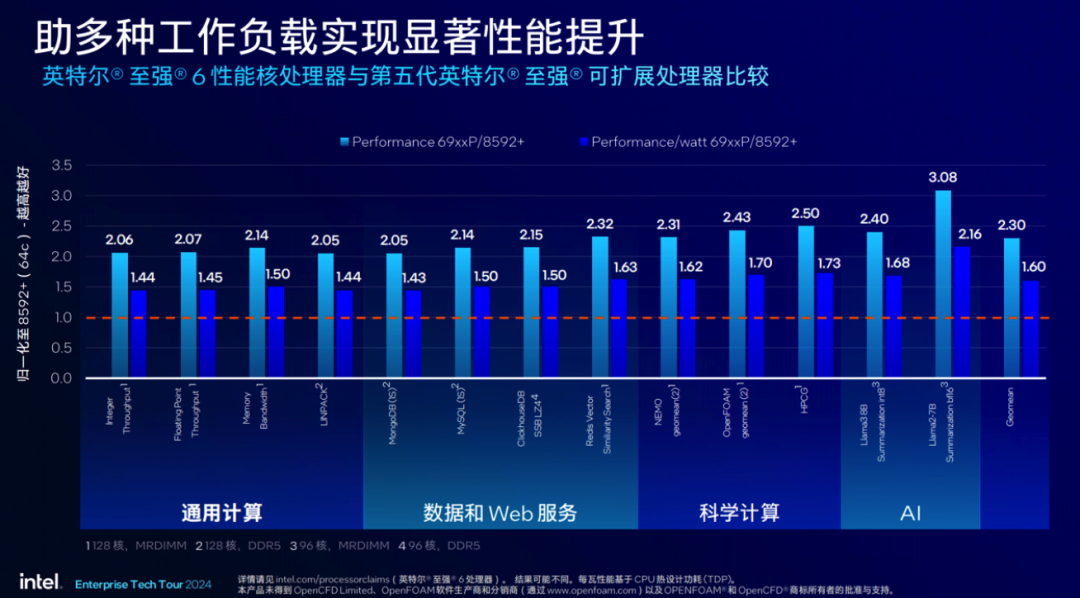
这些加速器的升级与焕新带来的成果就是下图这种多负载性能表现普遍倍增的现象,在AI领域,尤其是在Llama2-7B上的提升直接达到了前一代产品的3.08倍。
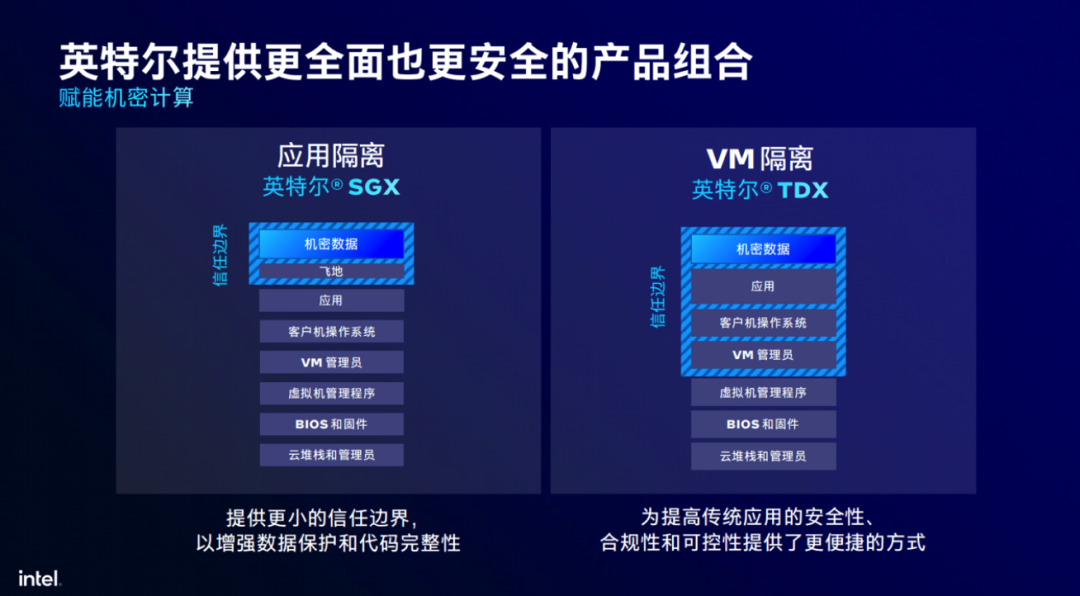
最后在硬件增强的安全特性方面,英特尔早期的方案为SGX,但从第五代至强® 开始新增了TDX方案。这些看似难以通过Benchmark数值来证明自身价值的技术,实则不可或缺,是确保关键数据和应用更为安全可靠的压舱石。
而安全,恰恰是目前AI数据中心或智算中心这种涉及海量数据、关系万千机密和隐私的环境中较少提及,却最应补足和巩固的一环。
说了这么多,如果要用一句话总结至强® 6 性能核处理器,尤其是6900P系列产品的定位,那就是“更强通用计算,兼顾AI加速”了。
那么新处理器具体都有哪些用法,表现又如何呢?
还请继续往下看。
首先,至强® 6 性能核处理器可以做“独行侠”,直接加速AI推理,助力AI应用普及。
用CPU做AI推理加速,其意义并非在于与GPU或其他专用加速器竞争极致的速度或效率,而是要在一些成本、采购、环境等条件受限的情况下,借助CPU部署更广泛、人才储备更扎实和应用更便捷的优势,让AI能够更快、更有效地落地。
带着这样的整体目标,英特尔在软件生态和工作负载优化方面投入了大量精力,以确保用户能够充分发挥至强® 6 性能核处理器的潜力。
例如,英特尔与TensorFlow和PyTorch等主流深度学习框架进行深度合作,将针对英特尔CPU的优化集成到官方发行版中,从而使得在英特尔CPU上运行深度学习模型时,性能得到显著提升。上文提到的Llama2-7B成绩便是这些努力的成果之一。
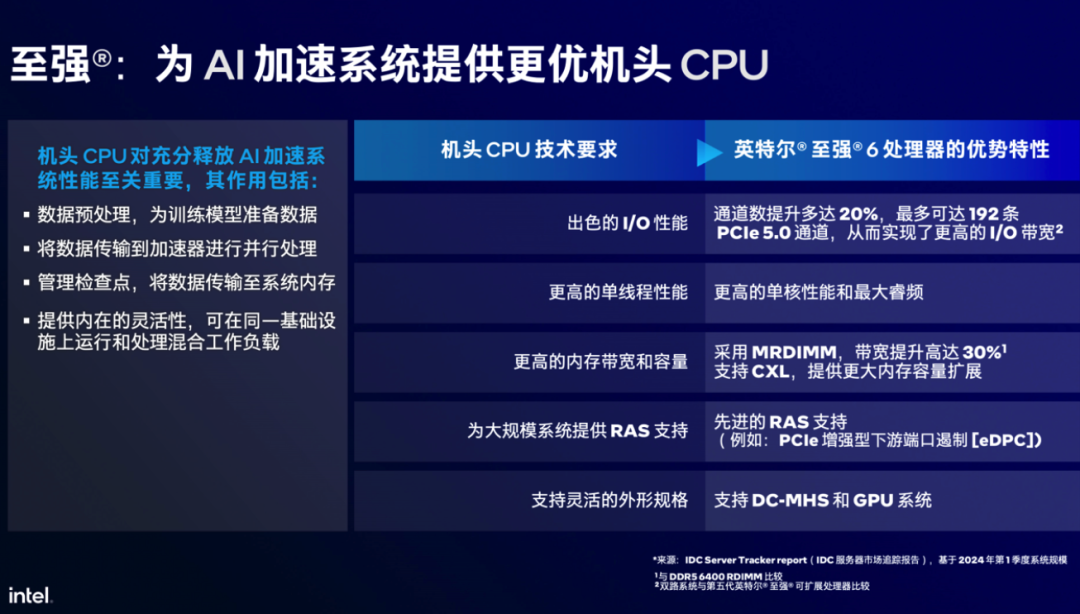
另外,至强® 6 性能核处理器还可以做“指挥官”,强化AI系统整体实力。
这其实是很多用户更为熟悉,也是至强® 6性能核处理器更主打的应用方式,所谓“指挥官”,另一个名称就是机头(head-node)CPU或主控CPU。
如果将至强® 6 性能核处理器用作AI服务器的机头CPU,那么其在算力(更强的单线程性能)、存力(对MRDIMM内存和CXL内存扩展能力的支持)以及 I/O(更多的PCIe 5.0通道)等方面的优势和潜能就能更加充分地发挥和释放出来。
使其能够与GPU或专用的AI加速器高效协作,出色地处理数据预处理、数据传输分享和混合工作负载。
我们最初的设问,至此终于拼凑出了一个更为完整的答案,即为何至强® 6 性能核处理器能够被称作AI服务器或AI数据中心的“严选”,甚至是优选CPU ?
这正是由于它既能够单枪匹马地加速AI推理,又可以居中协调以提升异构系统的整体性能输出。
更不必说,它还能够兼顾众多传统但同样不可或缺的应用负载,例如前文提及的科学计算和数据库,以及高性能云基础设施构建等任务。
以Flatiron Institute的案例来说,作为一家科研机构,他们对科学计算有着强烈的需求。通过测试得知,至强® 6 性能核处理器在常见科学计算负载上表现优异。
他们还觉得对MRDIMM内存的支持将进一步突破传统DDR内存的性能瓶颈,推动数据密集型科学发现。

在本次至强® 6 性能核处理器的发布会上,英特尔也展示了本地数据库软件合作伙伴——科蓝软件的成果。
英特尔市场营销集团副总裁、中国区&行业解决方案和数据中心销售部总经理梁雅莉在介绍生态系统支持状况时表示:
基于我们的新品,科蓝软件构建了高性能国产分布式数据库,其吞吐较第五代至强® 可扩展处理器提升达到 198%。
值得一提的是,在她分享中出现的中国合作伙伴数量众多且都是各领域的核心力量,英特尔虽然在产品研发上有了更多创新,但在商业模式上仍然非常依赖开放架构平台之上的产业合力。
十数家OEM、ODM、OSV和ISV在至强® 6 性能核处理器发布时同步推出新产品,以及多家云服务提供商的支持,在英特尔看来,才是新品真正走近用户和价值放大的基础。

从前面列举的众多数据和用例可以看出,在当前AI应用加速落地、新推理计算范式和合成数据等趋势的推动下,AI算力需求越来越注重推理和复合工作负载。
在这之中GPU或专用加速器固然重要,但CPU作为整个系统的“指挥官”,绝不能成为短板。
大家需要真正兼顾通用计算,以及AI服务器及AI数据中心场景的CPU产品。它不仅能支持广泛的第三方GPU及AI加速器,与它们组合形成强大的异构计算平台,还能在其中补足GPU或专用加速器覆盖不到或不足的地方,为更多样和复杂的场景提供灵活的算力选择,并增强整个AI平台的稳定性、安全性和扩展性。

英特尔® 至强® 6 性能核处理器的出现,就为AI计算带来了这样一个全新的支点。
最后让我们打个小广告:为了科普CPU在AI推理新时代的玩法,量子位开设了《最“in”AI》专栏,将从技术科普、行业案例、实战优化等多个角度全面解读。
我们希望通过这个专栏,让更多的人了解CPU在AI推理加速,甚至是整个AI平台或全流程加速上的实践成果,重点就是如何更好地利用CPU来提升大模型应用的性能和效率。
文章来源于“量子位”,作者“梦晨 金磊”



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
