# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
AI大模型对生产生活的渗透,已经在方方面面。
甚至可以说,它带来的影响比过去十年里,AI对各行各业的影响更加深远。并且一步一步发展至今,从“探索”到“价值产生”,已经变成了企业和模型厂商共同的迭代。
拿企业来说,它们不再单纯追求拥抱大模型,而是开始明晰那些业务需要大模型,大模型如何丝滑融入自己的工作流中,以及需要什么样的模型及应用。
而模型厂商这一边,拿到企业更明确的需求后,更懂得怎么让大模型业务真正深入垂直场景,提供哪些提效的工具,事半功倍地发挥大模型的价值。国内厂商在一年半内经历了百模大战和价格战,大模型的下一个战场在工具平台上。
以上,是在2024百度云智大会上,百度副总裁谢广军分享的一线洞察。
他顺带公布了一组数据:
过去一年多以来,千帆平台日均调用量超过7亿次,累计帮助用户精调了3万个大模型,开发出70多万个企业级应用。
并且,随着大模型在产业渗透的深入、需求的明确、技术的进步,百度千帆大模型平台3.0应运问世。
交流会上,谢广军拉明时间线,按照大模型调用趋势的变化,将过去一年半多的时间划分为了三个阶段。
第一阶段,是最为轰轰烈烈的百模大战时期。
这是一个属于探索和学习的阶段,接触大模型的人/团队,都在找卡、囤积算力,争相采购GPU/AI芯片,下场尝试研究和训练模型,这时候企业的需求大部分还是模型调用和精调。
谢广军打了个比方:那时候,最重要的事情就是跑马圈地。
也就是对标OpenAI、Anthropic等抢跑,通过迅速扩张或抢占资源来确立自己的优势地位。
大伙儿秀肌肉,最主要的目的是向外界证明我们也能训练出大模型的可行性。
第二阶段,重点转向对应用场景的探索。
很多企业和开发者,不再满足于将AI大模型视为一个独立的工具,而是将其视为一种全新的生产力工具。
也是因为随着模型能力的初步具备,企业开始探索在业务系统当中怎么把大模型应用起来,改造现有的系统或者创造全新的应用,从而提升业务效率和价值。
这一时期,智能问答、智能写作等智能助手类应用如雨后春笋般涌现。
但谢广军指出,真正在生产中使用并创造价值的应用仍然屈指可数。
从今年5月开始,百模大战演化成价格激战——降价,激发了企业对大模型的调用量,促进一批场景的探索,一定程度上加速了大模型落地。
第三阶段,也就是现在,大模型应用进入了深入场景和深度融合应用的阶段。
如今,随着模型效果的提升和价格的下降,真正的落地应用终于出现了。
谢广军举例表示,教育领域、制造行业、金融行业、医疗领域,大模型带来的智能系统都在各司其职。
与此同时,大模型开始与传统软件深度融合,重塑生产力工具。
特别明显的,企业不再满足于智能助手等单一形态的应用,而是将大模型赋能于进销存系统、ERP系统等传统应用,推动业务创新和效率提升。
总而言之,如果把第一阶段的标识是百模大战,第二阶段的代表是价格战,那么,第三阶段的典型则可以归于“应用平台工具”身上。
这也是为什么百度千帆大模型平台一直不停升级的原因。
谢广军回顾了过去一年半的时间里,百度千帆大模型平台顺应阶段性变化,都有哪些进展。
第一阶段的百模大战时期,也是B端使用模型的尝鲜期。
百度智能云推出了千帆大模型平台1.0,其中包括模型微调的工具链和大模型调用接口,模型调用开始起量。
第二阶段,千帆进化为2.0版本,“应用开发”来到台前。
除了支持模型服务和开发,千帆2.0主要增加了AppBuilder这样的AI原生应用开发平台,支撑RAG、Agent应用开发的各种需求。
进入今年,为了更系统地支持企业客户在应用开发、模型推理、模型开发等层面的大量且复杂的需求,千帆2.0持续演进,不断迭代。
不过,虽然第二阶段的千帆已经开始在企业级生产力场景里落地出力了,但谢广军分享了自己的观点:
随着模型技术进展、应用深入,实际场景当中只有大模型也不够,今天讲模型多模态,其实还是通过大模型与视觉、语音等垂直场景模型协同。
其次,企业级RAG和企业级Agent是未来大模型产业落地的主要形态。
为了适应日渐加深的深度,适应企业生产力的各种需求逐步演化,于是,千帆大模型平台3.0应运而生。
全面从模型训练转向全栈开发,开启第三阶段的故事。
千帆大模型平台3.0是面向生产力场景的企业级的一体化服务平台,主要为企业提供生成式AI生产以及应用全流程开发工具链。
在以下三个层面,均有全面升级:
• 模型开发层
• 模型服务层
• 应用开发层

谢广军谈到,千帆3.0的模型开发层提供最全面的工具链。
旗舰模型ERNIE 3.5、ERNIE 4.0 Turbo还首次开放SFT,可预置独家高质量混合语料。
原因无外乎两点。
一来实际业务反馈,不管从质量还是数量来看,企业自有数据都还有提升空间。预置独家高质量混合语料供企业用户在平台上扩充,可以增强模型最终效果。
二来,垂直领域模型后训练时混入通用语料,能进一步缓解通用能力遗忘这个问题。

千帆3.0的模型服务层提供丰富的模型。
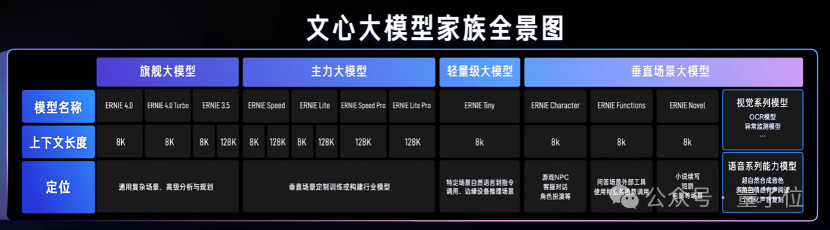
主要包括百度自研的文心系列,以及新增语音系列能力模型和视觉系列模型。
自研模型中,包含了最新模型ERNIE 4.0 Turbo、ERNIE Speed Pro、ERNIE Lite Pro;主力模型ERNIE Speed、ERNIE Lite依旧免费;垂直场景大模型新增了ERNIE Novel等。
除大语言模型外,考虑到传统语音、视觉模型在实际落地时仍有需求,大模型与垂类场景模型的协同混用很常见,因此,模型服务层也包括传统模型在内。
谢广军用一张图展示了千帆3.0模型服务层可提供使用的大模型:
应用开发层提供的,则是企业级RAG和企业级Agent的开发工具千帆AppBuilder和端到端应用开发工具AI速搭。
谢广军分享了一个数据:截至目前,千帆大模型平台已经帮助用户开发了超过了70万个应用。
千帆大模型平台3.0提供的是企业级RAG和企业级Agent的开发工具。
针对企业落地大模型的高频应用场景,千帆3.0从检索效果、检索性能、存储扩展、调配灵活性四方面对企业级检索增强生成(RAG)进行了全面升级;
针对企业级Agent的开发,千帆3.0增加了业务自主编排、人工编排、知识注入、记忆能力以及百度搜索等80多个官方组件支持。
AI速搭则可以端到端地开发应用,通过一句话或者通过PRD,就能一步一步生成包括表单、数据、流程的生成端到端应用,还可以基于低代码GUI方式对生成的应用修改和完善。
大模型的落地,除了基座大模型能力的提升,本身还是非常重视在行业场景当中的能力增强和应用,谢广军称之为“深入场景”。
今天,百度智能云千帆大模型平台,在千行百业中细分场景,然后不断提升场景中的模型能力、数据能力以及应用能力。
与此同时,千帆还推出了一系列应用样板间,让用户学会模型精调样板间,以及如何给大模型输入模板。
通过这样的方式,用户入门门槛被不断降低,大模型在若干行业场景的积累愈发深厚,推广渗透也更加深入。
经过一年多的探索,今天有很多的用户需求已经成熟了。
“拥抱大模型”已经不是企业的第一要务,把大模型在业务流程中跑起来,能把大模型用好,在业务中产生价值,才是有真本事。
大模型的效果、数据的合理使用、应用的构建方法等,是现在企业结合大模型时关注的焦点。
“现在是很好的时机。”谢广军说,用户也会挑选业界领先的伙伴合作,借助生态共同成长。
随着应用本身的深入落地,平台会越来越多,机会也越来越广。
再加上用户侧的需求更加清晰、更加务实,平台能够精准地持续完善相关功能,让大模型真正在业务场景中深入落地。
也就是说,企业真的准备好迎接和运用大模型应用的蓬勃生态。
而当企业对大模型的判断和需求更加成熟时,大模型厂商又迎来了新的机会。
在这样的新趋势下,谢广军也简明勾勒了大模型产业落地的未来线条。
首先,随着技术的迭代,模型推理成本的降低,大模型的价格会持续下降。在这次2024百度云智大会上,也公布了一个数据:过去一年,文心大模型旗舰模型累计降价超过90%。
持续的降本能给客户产生持续的收益,促使更多企业用得起、用得好。
当然了,当模型厂商还没有达到技术迭代升级的情况下,纯粹在资本推动下掏腰包做补贴,低价必然不是长久之计。
其次,虽然不管新模型还是老模型的价格曲线都会下落,但“价格下降”不是制胜一击。
研究更好的推理架构,用低算力推理达到更好的模型效果,是值得长期重视的关键。
效果不行,再便宜也用不起来。
最后,卷价格、卷效果,最终都会回归于各个厂商对自身成本的优化与控制。
相同效果下,模型厂商不断升级工程能力,降低自身成本,才能给出更实惠的模型使用价格,才能让更大众的场景把大模型用起来。
从千帆大模型平台3.0身上,我们可以看到百度对大模型产业落地整体趋势判断的缩影——
从最初的提供大模型调用和精调服务,到如今面向生产力场景的企业级一体化服务平台,不变的是始终与一线需求共同迭代。
随着大模型真正的落地与融入业务流程,属于工具平台的战事即将打响。率先迎接机遇和挑战的千帆3.0,会是这个战场上最耀眼的一员。
文章来源于“量子位”,作者“衡宇”




【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
