# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
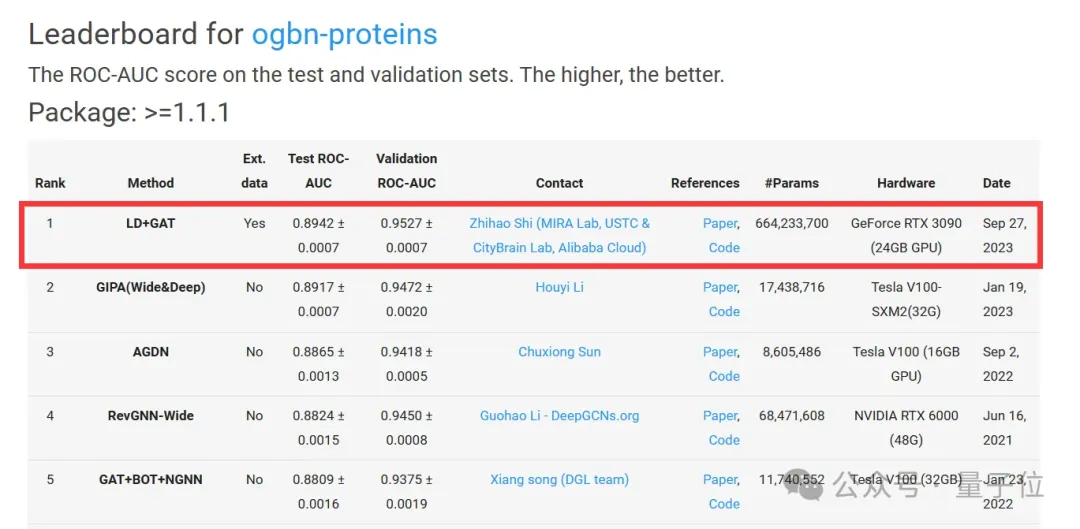
中科大成果,拿下图学习“世界杯”单项冠军!
由中科大王杰教授团队(MIRA Lab)提出的首个具有最优性保证的大语言模型和图神经网络分离训练框架,在国际顶级图学习标准OGB(Open Graph Benchmark)挑战赛的蛋白质功能预测任务上斩获「第一名」,该纪录从2023年9月27日起保持至今。
OGB是目前公认的图学习基准数据集“标杆”,由图学习领域的国际顶级学者斯坦福大学Jure Leskovec教授团队建立,于2019年国际顶级学术会议NeurIPS上正式开源。

最近,该论文发表在人工智能顶级期刊 IEEE Transactions on Pattern Analysis and Machine Intelligence(TPAMI 2024)。
TPAMI 是目前计算机类别中影响因子最高(影响因子 20.8)的期刊之一。

该方法引入了一个十分新颖的图神经网络的逆运算,并提出标签反卷积算法来快速近似它,进而构建一个等价的损失函数,从而消除了传统语言模型和图神经网络微调方法的学习偏差。
论文和代码均放出。
图广泛应用于许多重要领域,例如引文网络、商品网络和蛋白质相互作用网络。在许多实际应用中,图中的节点具有丰富且有用的属性信息。例如,引文网络中的节点(论文)、商品网络中的节点(商品)以及蛋白质相互作用网络中的节点(蛋白质)分别包含着标题/摘要、商品的文本描述和蛋白质序列等重要信息,这些信息对下游任务只管重要。而近年来兴起的许多强大的预训练模型是从这些复杂属性中捕获节点特性的重要工具之一。
为了同时编码这些属性和图结构,一个常见的架构是将预训练模型与图神经网络GNN(Graph Neural Network)串联集成在一起,其中预训练模型作为节点编码器NE(Node Encoder)对属性进行编码。如下图所示,该架构通过节点编码器将这些复杂的节点属性变成定长的低维嵌入,再将其作为节点特征输入到图神经网络以结合图结构信息。
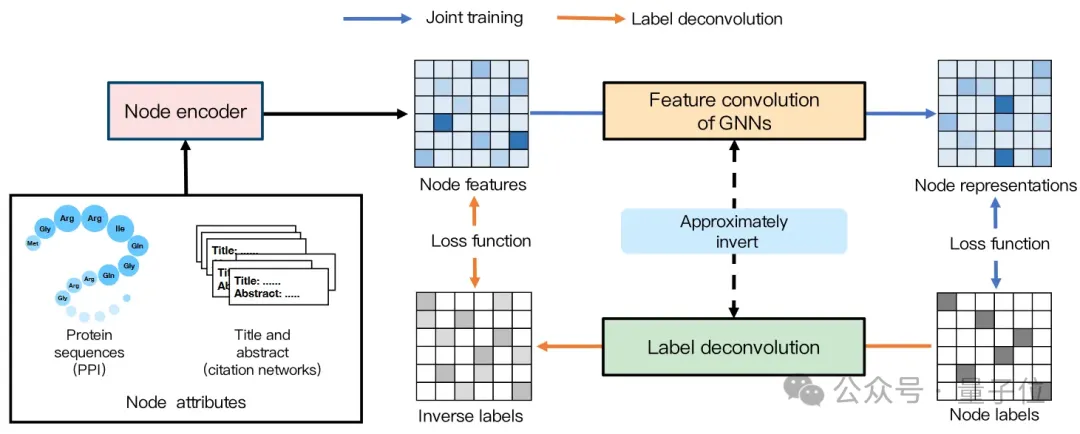
然而,作为NE的预训练模型本身大量参数且GNN的邻居爆炸问题(neighbor explosion),两大训练难题的叠加让直接端到端联合训练NEs和GNN在实际中并不可行的。研究者们开始研究分离NEs和GNNs分离训练的范式,即先固定NEs的参数训练GNNs一定步数(GNN的训练阶段),再固定GNNs的参数训练NEs一定步数(NE的训练阶段),两步交替迭代进行。
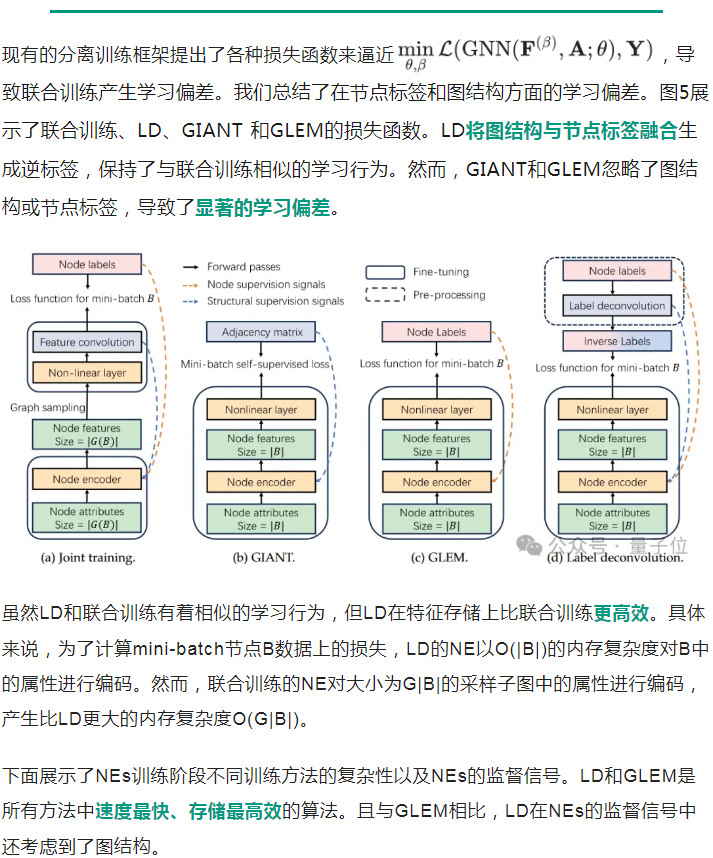
本工作对现有的NEs和GNNs分离训练的范式进行研究,指出了现有工作在NE训练阶段,它们没有考虑GNN中的特征卷积,导致它们提出的近似损失函数与原始联合训练的目标函数并不等价,存在显著的学习偏差,进而无法收敛到最优解(详见原论文举的反例)。
为了应对这一挑战,我们提出了一种有效的标签正则化技术,即标签反卷积LD (Label Deconvolution),通过对GNN逆映射得到一种新颖的、可扩展性强的近似标签。逆映射有效地将GNN纳入NE的训练阶段以克服学习偏差,进而产生了与联合训练等效的目标函数。于是我们也进一步证明了LD收敛到了最优目标函数值,为提出的LD方法提供了理论保证。通过实验验证,LD显著优于当下最先进的方法,在国际顶级图学习标准OGB(Open Graph Benchmark)挑战赛的蛋白质功能预测任务上斩获「第一名」,该记录从2023年9月27日起保持至今。

大多可扩展的图神经网络可分为基于数据采样和基于模型结构的两类思想。











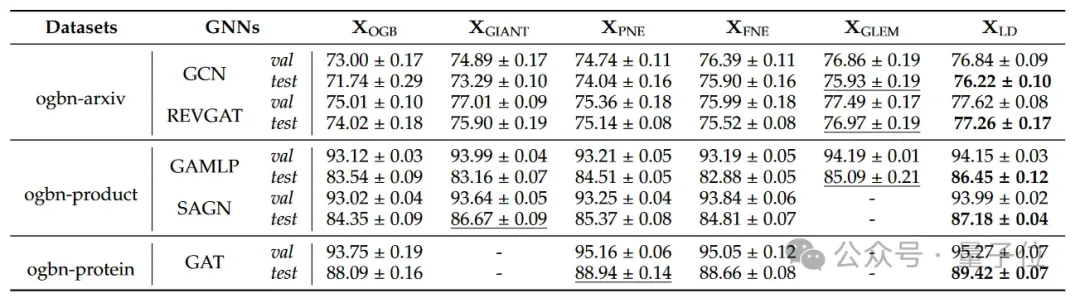
团队对广泛使用的开放图基准数据集OGB(Open Graph Benchmark)中的ogbn-axiv、ogbn-product和ogbn-protein进行实验,其图数据分别为引文网络、协同购买网络和蛋白质关联网络。
如下所示,LD在不同GNN backbone的三个数据集上的表现都显著优于所有的baseline。
石志皓,2020年获得中国科学技术大学电子工程与信息科学系学士学位。现于中国科学技术大学电子工程与信息科学系的 MIRA Lab 实验室攻读博士研究生,师从王杰教授。研究兴趣包括图表示学习和AI4Science。他曾以第一作者在 TPAMI、ICLR等期刊、会议上发表论文,曾受邀在ICLR 2023做接受率约为8%的Spotlight报告。
路方华,2023年获得上海大学机械设计与自动化专业学士学位。现于中国科学技术大学电子工程与信息科学系的 MIRA Lab 实验室攻读硕士研究生,师从王杰教授。研究兴趣包括图表示学习和自然语言处理。
论文地址:https://www.computer.org/csdl/journal/tp/5555/01/10678812/20b3hKWQ3Ru
代码地址:https://github.com/MIRALab-USTC/LD
参考文献:
[1]Zhao J, Qu M, Li C, et al. Learning on large-scale text-attributed graphs via variational inference[J]. arXiv preprint arXiv:2210.14709, 2022.
[2]Wang X, Zhang M. How powerful are spectral graph neural networks[C]//International Conference on Machine Learning. PMLR, 2022: 23341-23362.
文章来自于微信公众号“量子位”,作者“MIRA Lab”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
