# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
就在刚刚,MIT系初创公司Liquid AI团队官宣:推出首批多模态非Transformer模型——液体基础模型LFM。
作为通用人工智能模型,LFM可用于建模任何类型的顺序数据,包括视频、音频、文本、时间序列和信号。
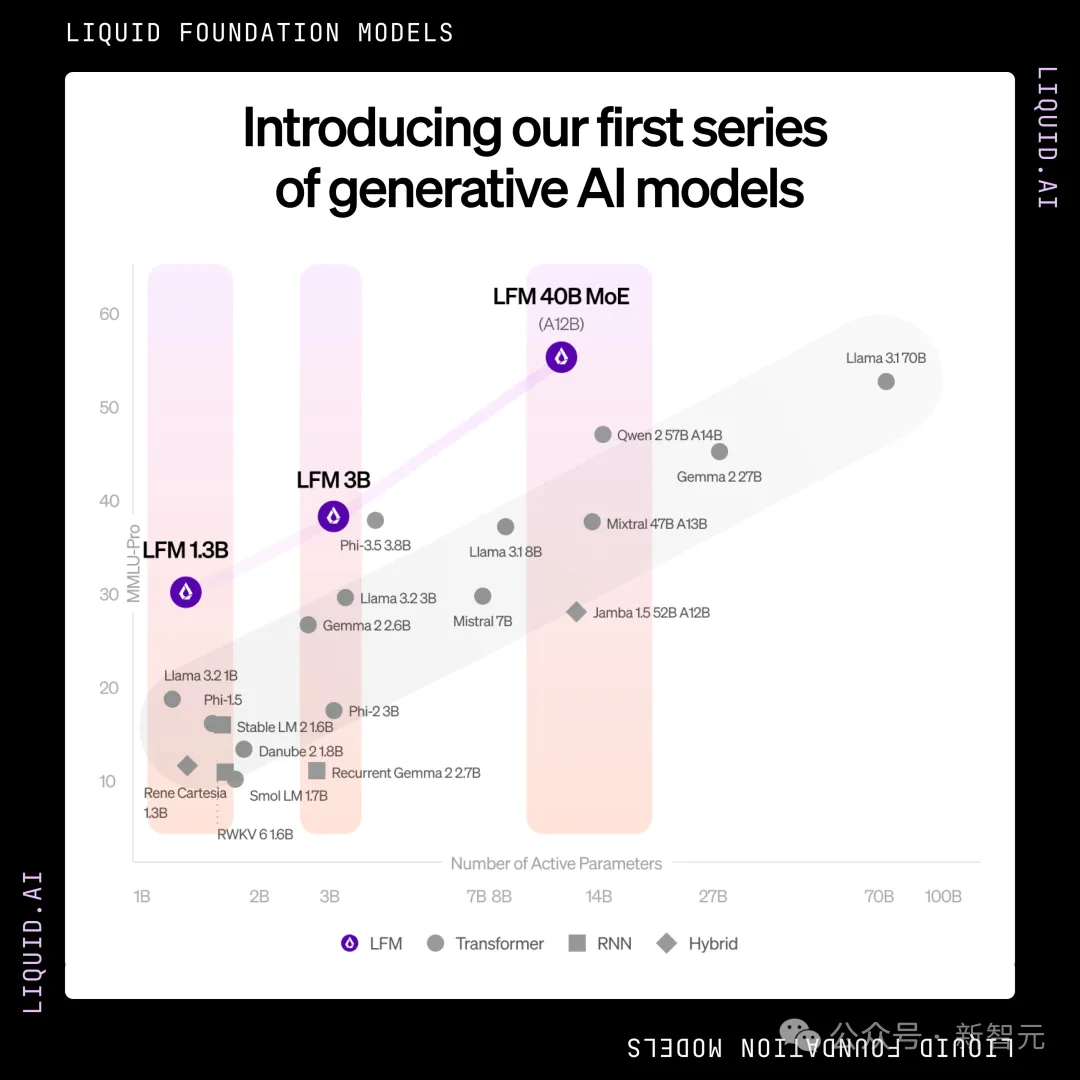
目前,LFM有三种不同的规模:
在各种规模上,这三个模型都实现了最佳质量表现,同时保持了更小的内存占用和更高效的推理能力。
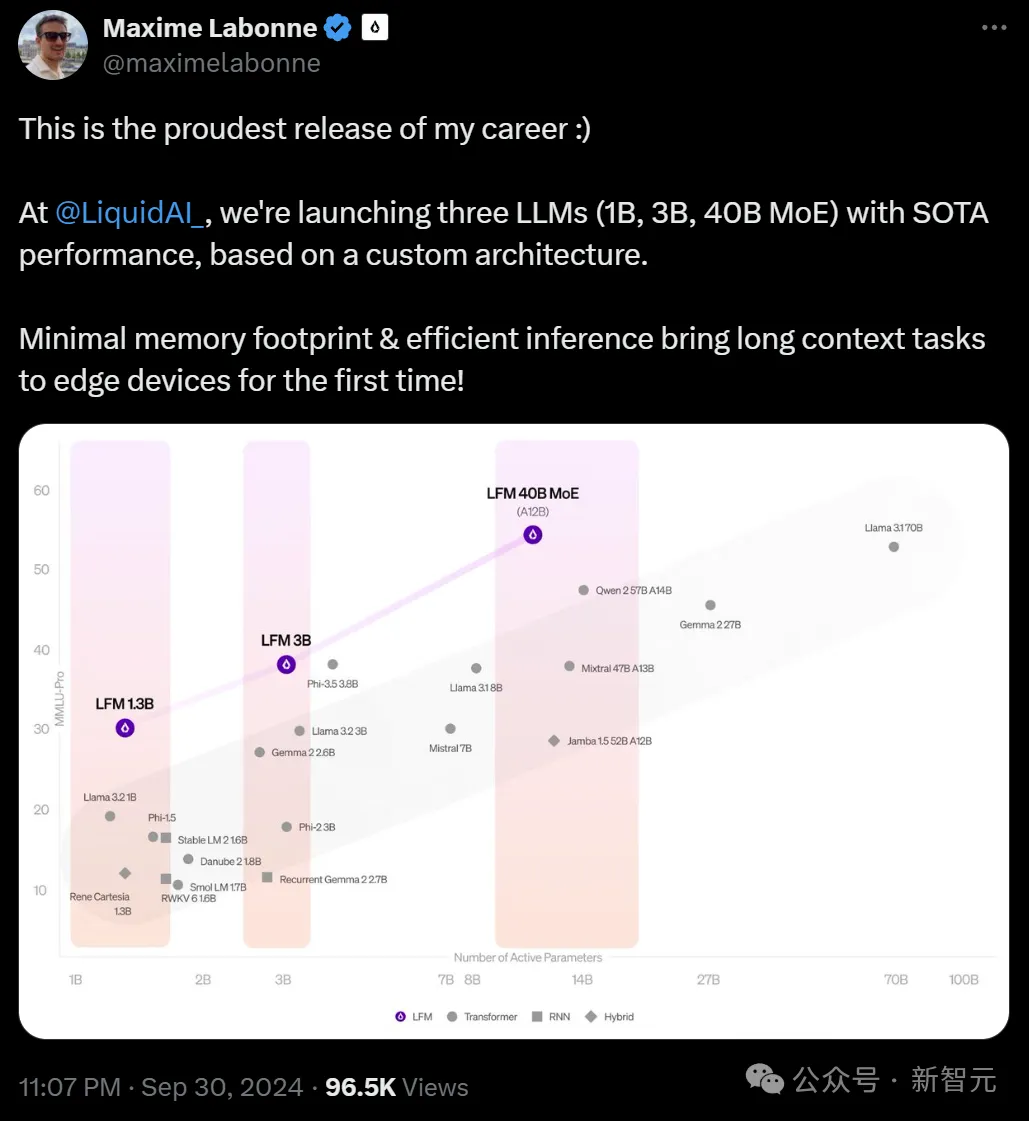
公司的后训练主管Maxime Labonne表示,LFM是「我职业生涯中发布的最自豪的产品」
这是因为,Liquid AI的新模型保留了液体神经网络适应性的核心优势,允许在推理过程中进行实时调整,而不会产生与传统模型相关的计算开销,能够高效处理多达100万个token,同时将内存使用保持在最低水平。
其中LFM-1B在1B类别的公共基准测试中表现良好,成为该尺寸模型中的SOTA。
这是非GPT架构首次显著优于基于Transformer的模型!

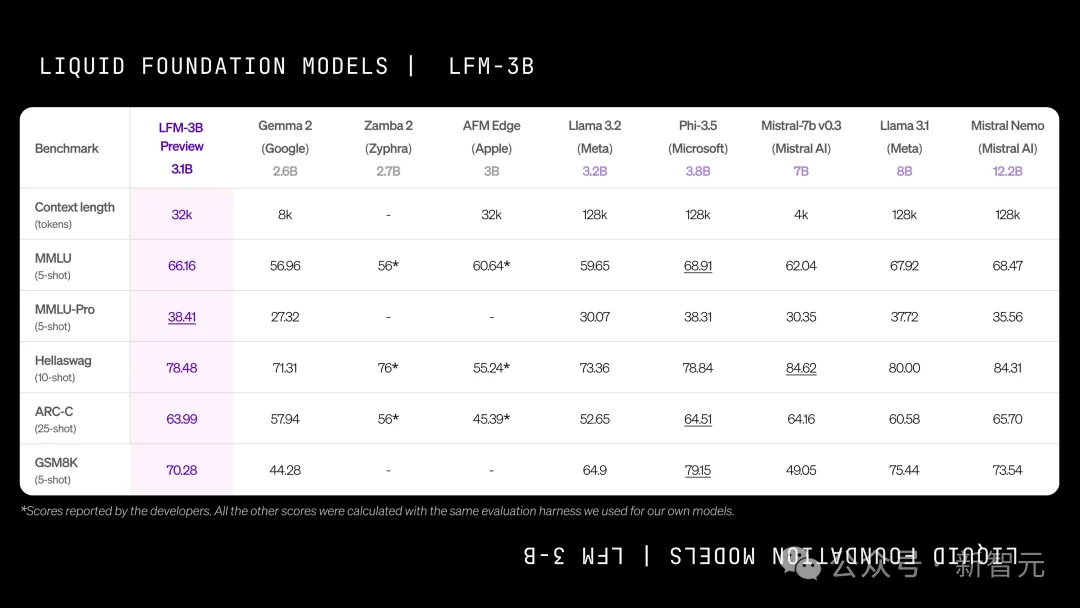
而LFM-3B的性能也优异得令人难以置信。
在3B参数的Transformer、混合模型和RNN模型中,它都取得了第一名;不仅如此,它的性能也优于前代的7B和13B模型。
在多项基准测试中,它的性能和Phi-3.5-mini相当,规模却小了18.4%。
可以说,LFM-3B是移动端侧和和其他边缘文本应用的理想选择。
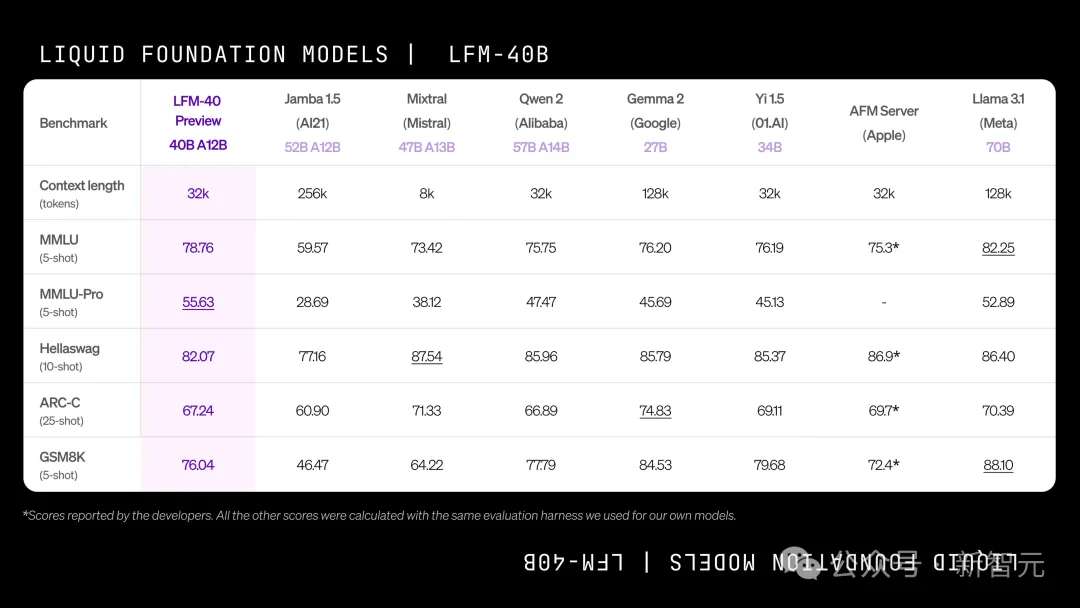
LFM-40B在模型尺寸和输出质量之间实现了新的平衡。
在运行时,它利用了12B的激活参数。
这样,它的性能就可以媲美更大的模型,而其MoE架构,则可以实现更高的吞吐量,并且能部署在更具成本效益的硬件上。
现在,LFM模型已经可以免费体验了:
https://playground.liquid.ai
https://lambda.chat/liquid-ai
https://labs.perplexity.ai
Liquid AI是由MIT计算机科学与人工智能实验室(CSAIL)的前研究人员共同创立的初创公司。
公司的后训练主管Maxime Labonne表示,LFM是「我职业生涯中发布的最自豪的产品」。
LFM的核心优势,就是使用显著更少内存的同时,超越基于Transformer的模型。
的确,LFM的内存效率十分显著,Liquid的LFM-3B仅需16 GB内存,而Meta的Llama-3.2-3B模型则需要超过48 GB内存。
在目前,Transformer架构还是GenAI浪潮中大多数模型的主流。
然而Liquid AI却另辟蹊径,希望探索构建超越生成式预训练Transformer(GPT)的基础模型的方法。
新的LFM,是从第一性原理出发,以工程师构建发动机、汽车和飞机的相同方式来构建的。
果然,他们做到了这一点。新的LFM模型,在性能上已经超越了同等规模基于Transformer的模型,如Meta的Llama 3.1-8B和微软的Phi-3.5 3.8B。
为何如此?
LFM是由深深植根于动力系统、信号处理和数值线性代数理论的计算单元构建的大型神经网络。
这种大型神经网络可用于建模任何类型顺序数据的通用人工智能模型,包括视频、音频、文本、时间序列和信号,从而用于训练新的LFM模型。
LFM的一大特点,就是高效内存。与Transformer架构相比,LFM的内存占用更少。
对于长输入尤其如此,而这种情况下,基于Transformer的LLMs中的KV缓存会随着序列长度而线性增长。
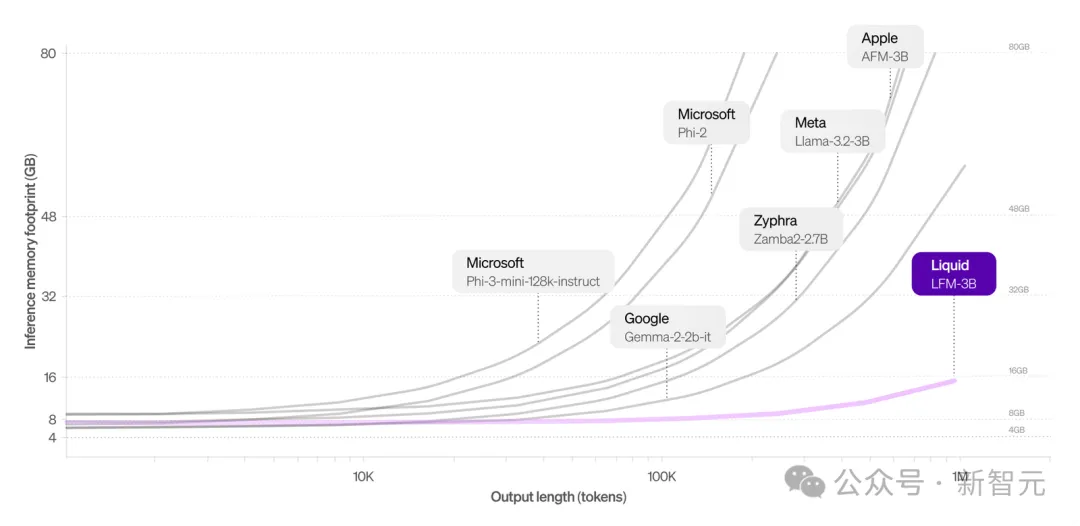
LFM-3B模型在推理内存占用率方面优于谷歌的Gemma-2、微软的Phi-3和Meta的Llama-3.2,特别是在token长度扩展时
相比之下,LFM真正利用了它们的上下文长度。
在预览版本中,团队优化了模型,提供了一流的32k token上下文长度,直接突破了这一尺寸的效率边界!
随后的RULER基准测试,更是证实了这一点。
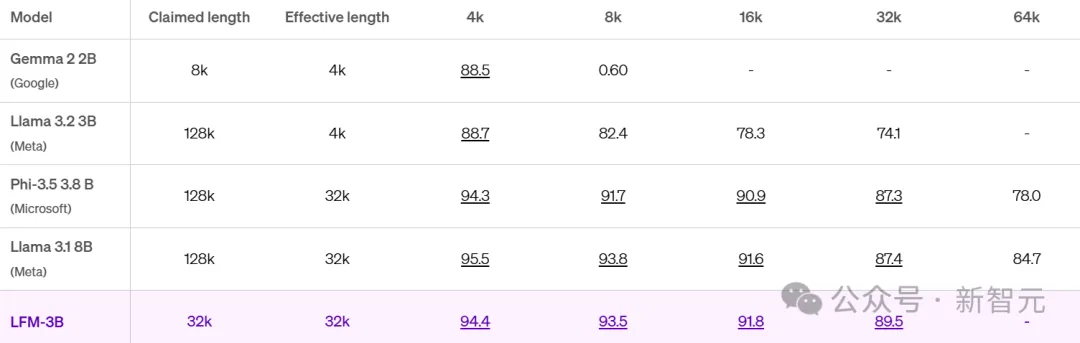
高于85.6分时,上下文长度才是「有效的」
显然,LFM通过Liquid AI团队设计的全新算法进展,直接推进了大规模AI模型的帕累托边界。
这些算法可以增强模型的知识容量、多步骤推理能力和上下文记忆能力,还能用于高效训练和推理。

Liquid AI为计算单元建立了新的设计空间的基础,从而能够根据不同的模型和硬件要求进行定制。
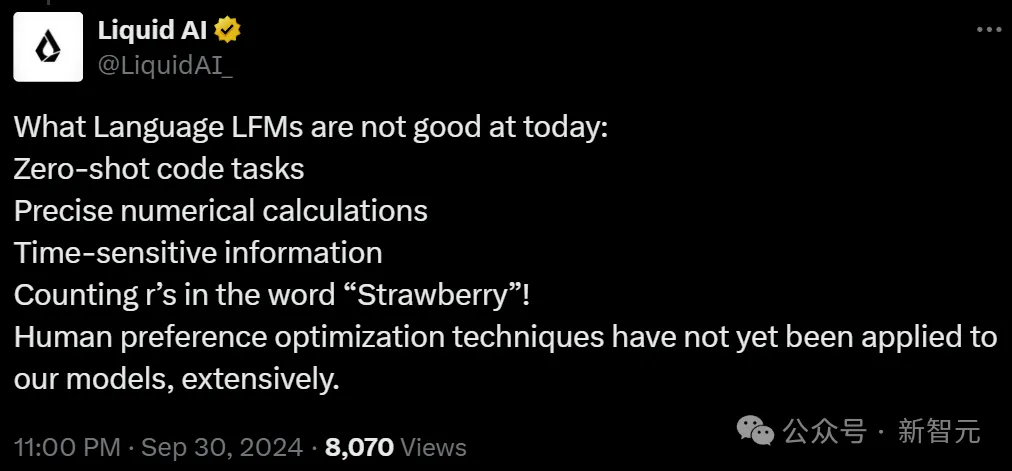
不过,团队也承认,LFM也有很多不擅长的任务:
- 零样本学习的代码任务
- 精确的数值计算
- 时效性信息
- 数「Strawberry」中有几个「r」
而且,人类偏好优化方法尚未广泛应用于LFM模型中。
目前,LFM擅长的领域包括:
- 一般知识和专业知识
- 数学和逻辑推理
- 高效且有效的长上下文任务
- 主要语言为英语,辅助语言为西班牙语、法语、德语、中文、阿拉伯语、日语和韩语
其他模型在长文本处理时内存使用急剧增加,但LFM-3B保持显著较小的内存占用,这就使它非常适合需要大量顺序数据处理的应用,比如文档分析或聊天机器人。
LFM基础模型还具备多模态的功能,包括音频、视频和文本。这种多模态能力,让它在金融服务、生物技术、消费电子等行业都有应用空间。
它不仅在性能基准测试上具有竞争力,在操作效率上也经过了精心设计,成为各种用例的理想选择,包括上述领域的企业级应用,以及在「边缘设备」上的部署。
不过要注意,LFM并不是开源的,用户需要通过Liquid的推理Playground、Lambda Chat或Perplexity AI来访问模型。
立下大功的「液体神经网络」,究竟是什么原理?
液体神经网络(Liquid Neural Networks,LNN)是团队提出的一种全新架构,可以使人工「神经元」或用于转化数据的节点更高效、适应性更强。
与需要数千个神经元来执行复杂任务的传统深度学习模型不同,LNN只用较少的神经元——结合创新的数学公式——就可以达到相同的结果。
Liquid Time-constant Networks
有趣的是,MIT CSAIL主任Daniela Rus介绍称,液体神经网络的灵感起源于线虫的神经结构。
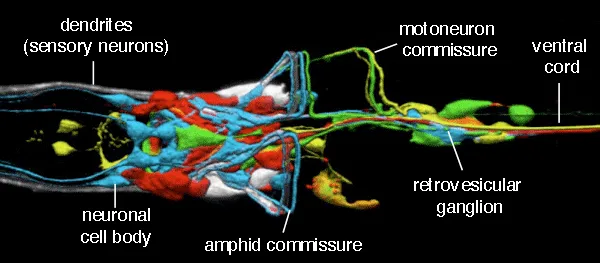
秀丽隐杆线虫的大脑
作为一种受大脑启发的系统,LNN即使在训练后,也能保持适应性和对变化的鲁棒性。

论文地址:https://www.nature.com/articles/s42256-020-00237-3
团队通过理论分析和实验证明,这套系统:

论文地址:https://www.nature.com/articles/s42256-022-00556-7

论文地址:https://www.science.org/doi/10.1126/scirobotics.adc8892
团队开发了一类非线性神经微分方程序列模型,并将其推广到了图结构上。
并且,利用混合数值方法和时间并行方案,对连续时间模型进行扩展和优化,从而在控制和预测任务中实现了SOTA。
此外,还发布了最为全面的神经微分方程开源库之一,目前在各种应用中被广泛用于基于扩散的生成建模和预测任务。

论文地址:https://physical-reasoning.github.io/assets/pdf/papers/03.pdf
值得一提的是,团队提出了首个高效的基于并行扫描的线性状态空间架构,以及基于有理函数的SOTA时间序列状态空间模型。
此外,还首次提出了用于时间序列的生成式状态空间架构,以及适用于视频处理的状态空间架构。

论文地址:https://arxiv.org/pdf/2208.04933
团队提出了一个新的神经算子框架。在解决微分方程和预测任务方面,性能超越了包括傅里叶神经算子在内的多种方法。

论文地址:https://proceedings.neurips.cc/paper_files/paper/2022/file/342339109d7d756ef7bb30cf672aec02-Paper-Conference.pdf
团队共同发明了一系列能够有效扩展到长上下文的深度信号处理架构,如Hyena、HyenaDNA和StripedHyena等。
其中,基于StripedHyena的Evo是一个创新的DNA基础模型。它不仅可以在DNA、RNA和蛋白质之间进行泛化,还能够生成设计新的CRISPR系统。
值得一提的是,他们是首个基于深度信号处理和状态空间层来扩展语言模型的团队。
不仅对超越Transformer架构的模型进行了迄今为止最广泛的扩展法则分析,而且还在此基础上提出了性能超越现有开源替代方案的全新模型变体。

团队主导开发了许多最佳的开源LLM微调和合并技术。
最后,团队的研究还在多个领域做出了重要贡献:为图神经网络和几何深度学习模型做了开创性工作;为神经网络的可解释性定义了新的衡量标准;开发了SOTA的数据集蒸馏算法。

论文地址:https://arxiv.org/pdf/2312.04501
实际上,相关的研究论文有数十篇之多,感兴趣的朋友可以去官方博客了解。

博客地址:https://www.liquid.ai/blog/liquid-neural-networks-research
这次,团队在此前研究的基础上开发了一个全新的基础模型设计空间,专注于不同的模态和硬件需求。
目标也很明确——探索构建超越生成式预训练Transformer(GPT)的基础模型的方法。
通过LFM,团队将在过去几个月中开发的新原则和方法付诸了实践,用于指导模型设计:
1. LFM由结构化操作单元组成
模型基于一组计算单元构建而成。这些架构的基本组成部分,属于一个全新的设计空间。
Liquid系统及其组成将知识容量和推理能力最大化,同时实现了更高的训练效率,降低了推理过程中的内存消耗,并提高了视频、音频、文本、时间序列和信号等数据的建模性能。
2. LFM架构是可控制的
模型的设计反过来也为扩展、推理、对齐和模型分析方面的策略提供了信息。
通过运用经典的信号处理分析方法,团队能够深入分析LFM的动态特性,并全面探究其行为特征,包括模型输出和内部运作机制等等。
3. LFM具有自适应能力,可作为各种规模AI的基础
模型架构能够被自动优化,进而适配特定硬件平台(例如,苹果、高通、Cerebras和AMD)或满足特定的参数要求和推理缓存大小限制。
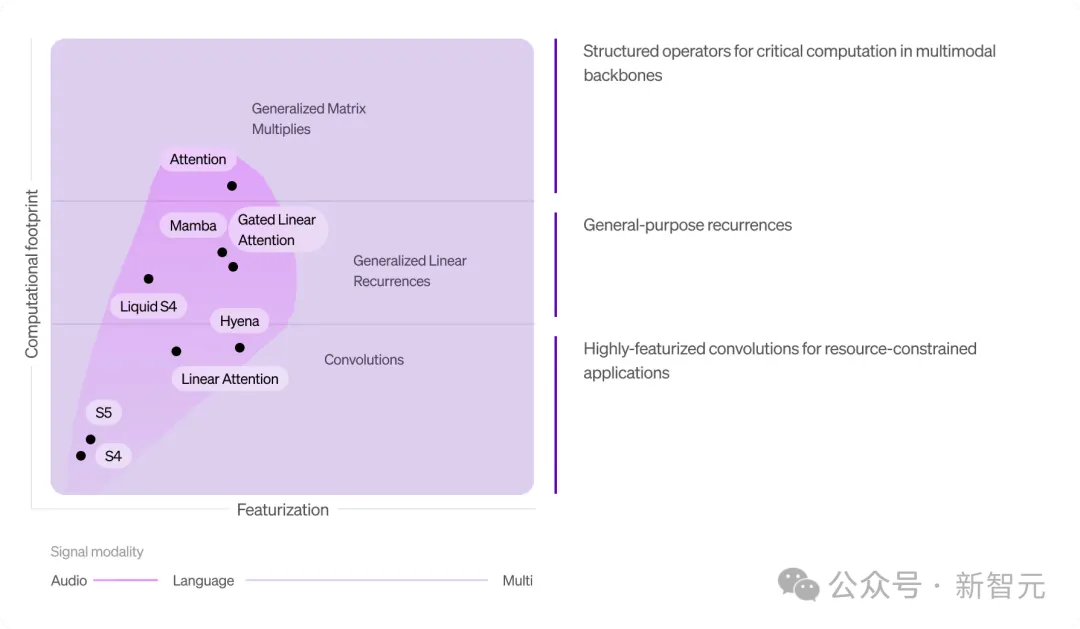
具体来说,Liquid的设计空间主要由两个维度定义:架构及其核心运算符的特征化和计算复杂度。
- 特征化是指将输入数据(如文本、音频、图像、视频)转换为结构化的特征集或向量的过程。这些特征或向量被用来以自适应方式调节模型内部的计算过程。例如,与语言和多模态数据相比,音频和时间序列数据通常由于信息密度较低,在运算符中需要较少的特征化处理。
- 另一个关键维度是运算符的计算复杂度,即完成操作所需的计算资源。通过探索和完善结构化自适应运算符的设计空间,团队能够在控制计算需求的同时最大化模型性能。
在核心层面,LFM是由一系列计算单元构建而成的。这些计算单元可以表示为自适应线性算子,其行为由输入数据动态决定。
LFM设计框架统一并涵盖了深度学习中广泛存在的各种计算单元,为系统性探索模型架构空间提供了方法论基础。
具体而言,可以通过改进以下三个关键方面来指导模型构建:
1. token混合结构:算子如何在输入序列中混合嵌入
2. 通道混合结构:如何混合通道维度
3. 特征化:负责根据输入上下文调整计算
为了实现这些突破性成果,团队对训练前准备和训练后处理的全流程进行了优化,同时也升级了相关的计算硬件和软件系统。
1. 知识储备
在任何特定模型规模下,都能在各种领域和任务中展现广泛而深入的信息处理能力。
团队通过改进模型架构,以及采用新的预训练、训练中优化和后训练策略等方式,使得LFM能够在需要丰富知识储备的任务上与更大规模的模型相抗衡。
2. 多步推理
这种能力指的是将复杂问题拆解并运用严密逻辑进行思考的技能。
团队通过在训练的关键阶段对系统2任务进行蒸馏和优化,在有限的计算资源和紧凑的模型架构下,赋予了模型更高级的认知功能和强大的分析能力
3. 长上下文召回
需要注意的是,模型的最大输入大小与其有效上下文长度并不相同。
团队专门对大语言模型进行了训练,目的是在所有可能的输入长度范围内,最大化其记忆和提取信息的能力,以及根据上下文进行学习和推理的能力。
4. 推理效率
基于Transformer的模型在处理长输入时内存使用量会急剧增加,这使得它们不适合在资源受限的边缘设备上部署。
相比之下,LFM具有近乎恒定的推理时间和内存复杂度。这意味着,即使输入的上下文长度增加,也不会显著影响文本生成速度或增加所需的内存量。
5. 训练效率
训练类GPT的基础模型需要大量的计算资源。而LFM在训练长上下文数据时效率更高。

Ramin Hasani是Liquid AI的联合创始人兼首席执行官,同时也是MIT CSAIL的机器学习研究合作伙伴。
在此之前,他以优异成绩获得维也纳工业大学(TU Wien)的计算机科学博士学位。随后,来到CSAIL MIT进行博士后研究,与Daniela Rus教授一起负责关于智能建模和序列决策的研究。
他的研究主要集中在复杂动态系统中的鲁棒性深度学习和决策制定。


Mathias Lechner是Liquid AI的联合创始人兼首席技术官,同时也是MIT CSAIL的研究合作伙伴。
他于2022年在奥地利科学技术研究所(ISTA)获得了博士学位,分别于2017年和2016年在维也纳工业大学(TU Wien)获得了计算机科学硕士和学士学位。
在MIT的研究工作中,他专注于开发鲁棒且可信的机器学习模型。

Alexander Amini是Liquid AI的联合创始人兼首席科学官,同时也是MIT的研究合作伙伴,并担任MIT官方深度学习入门课程——「MIT 6.S191:深度学习导论」的主办者和讲师。
他分别于2022年、2108年和2017年获得了MIT的计算机科学博士学位、理学硕士和学士,辅修数学。
他的研究目标是发展自主性科学与工程,并将其应用于自主智能体的安全决策,曾研究过自主系统的端到端控制,神经网络的置信度形成,人类移动的数学建模,以及构建复杂的惯性优化系统。

Daniela Rus是MIT电气工程和计算机科学系的Andrew和Erna Viterbi教授,同时担任CSAIL主任。
她是美国计算机学会(ACM)、美国人工智能协会(AAAI)和电气电子工程师学会(IEEE)的会士,并且是美国国家工程院和美国艺术与科学学院的院士。
她在康奈尔大学获得了计算机科学博士学位。研究兴趣包括机器人学、移动计算和数据科学。
Liquid AI的官方博客介绍道——
第一代液体基础模型LFM,是一种从基本原理构建的新一代生成式AI模型。
我们的使命,是在每个规模上创造同类最佳、智能和高效的系统——这些系统旨在处理大量的顺序多模态数据,实现高级推理,并达成可靠的决策制定。
LFM计算单元和动力系统理论、信号处理和数值线性代数的独特融合,使我们能在追求各个规模智能的过程中,利用这些领域数十年的理论进展。
而「Liquid」这个名字,恰恰体现了公司在动态和自适应学习系统领域的根源。
参考资料:
https://x.com/maximelabonne/status/1840770427292958749
https://x.com/LiquidAI_/status/1840768716784697688
https://www.liquid.ai/blog/liquid-neural-networks-research
文章来自于微信公众号“新智元”



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
