# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
首个由万卡集群训练出来的万亿参数大模型,被一家央企解锁了。

具体而言,为纯国产人工智能探索出这条路的正是中国电信人工智能研究院(TeleAI),是由中国电信集团 CTO、首席科学家、中国电信人工智能研究院院长李学龙教授带领团队完成。
据了解,训练使用的万卡集群由天翼云上海临港国产万卡算力池提供,并基于天翼云自研“息壤一体化智算服务平台”和电信人工智能公司自研“星海 AI 平台”的支持,可以实现万亿参数的常稳训练,平均每周仅有1.5次训练中断,集群训练稳定性达到国际领先水平。
而且基于此,TeleAI 还开源了由国产深度学习框架训练的千亿参数大模型——星辰语义大模型 TeleChat2-115B。
TeleChat 是央企里首个开源的系列语义大模型,而 TeleChat2-115B 则在 TeleChat 的基础上,通过对训练数据量、数据质量和配比、模型架构等多维度的优化,取得了更进一步的效果提升!
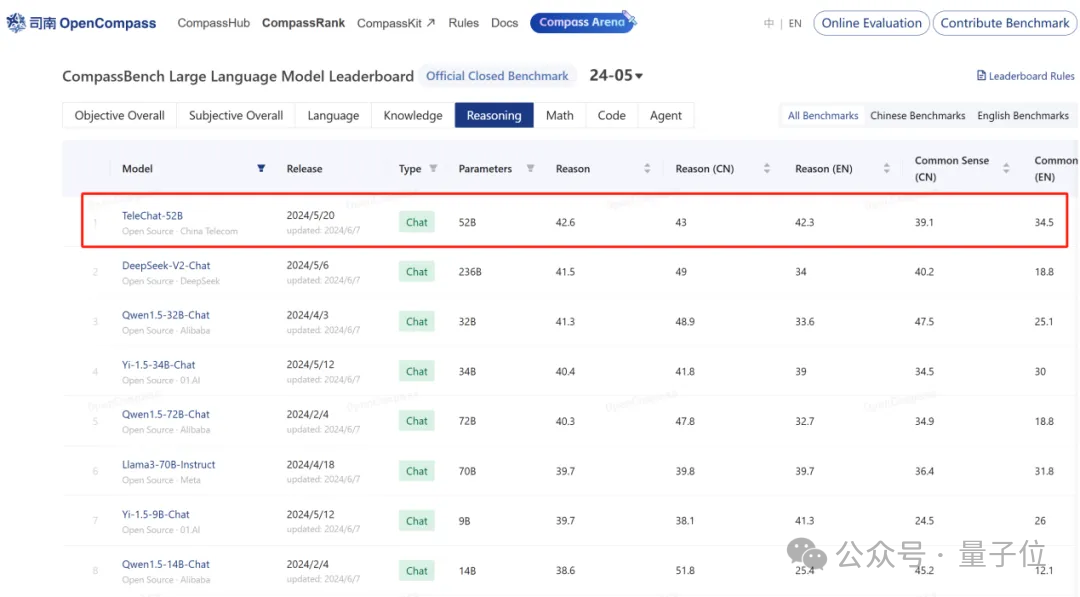
在九月份的 C-Eval 评测 Open Access 模型综合榜单中,TeleChat2-115B 以86.9分的成绩,一举拿下了榜单第一!

这已经不是 TeleAI 第一次在权威榜单高居榜首了。早在今年5月份的时候,其 TeleChat 系列模型的逻辑推理能力便在 OpenCompass 测试榜单中取得开源大模型排名第一。
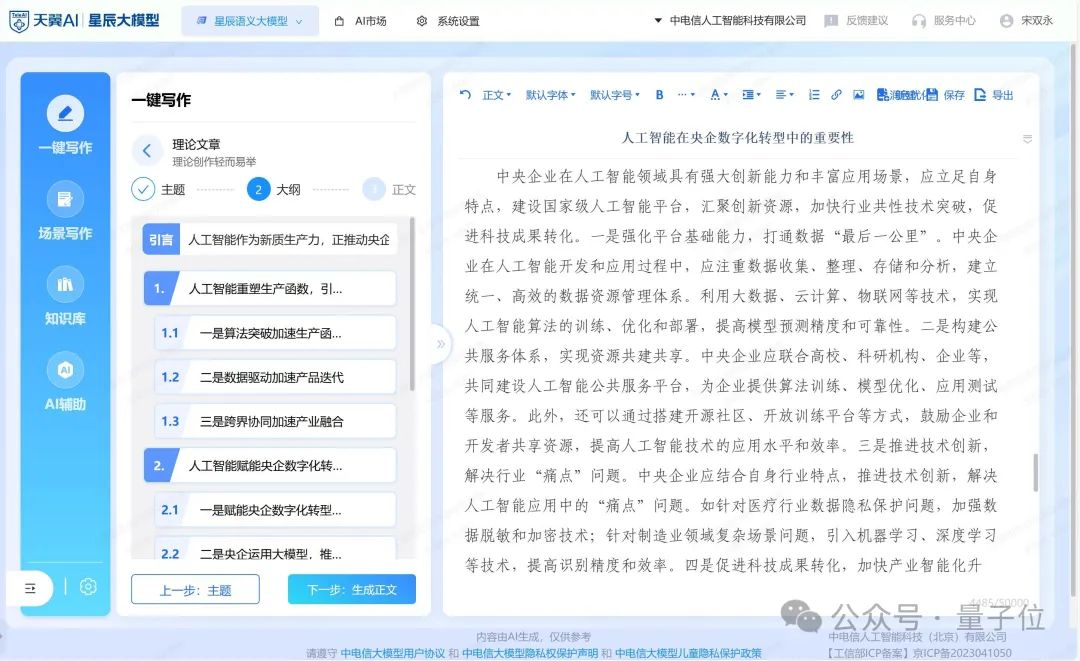
具体到应用,星辰语义大模型在长文本写作方面,是以“大纲写作+正文写作”这种模式展开,更加贴近用户习惯。
据了解,它还是逐段生成文本,这就有利于实现超长文章的写作。
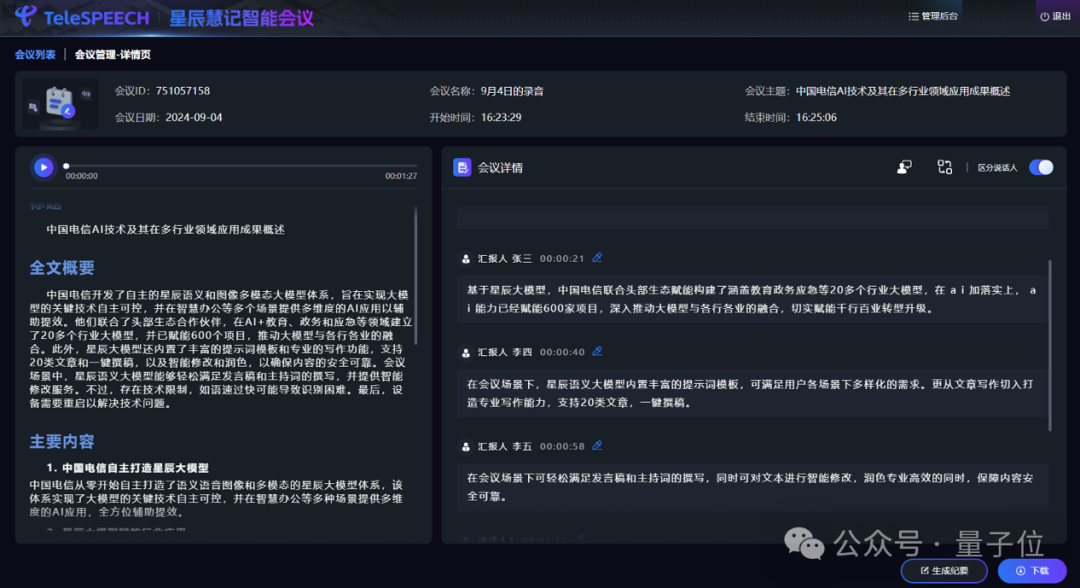
即使面对超长会议,星辰语义大模型也可以轻松实现纪要实时生成,在准确性、完整性、幻觉问题、逻辑性以及规范性等多个方面都能呈现高质量。
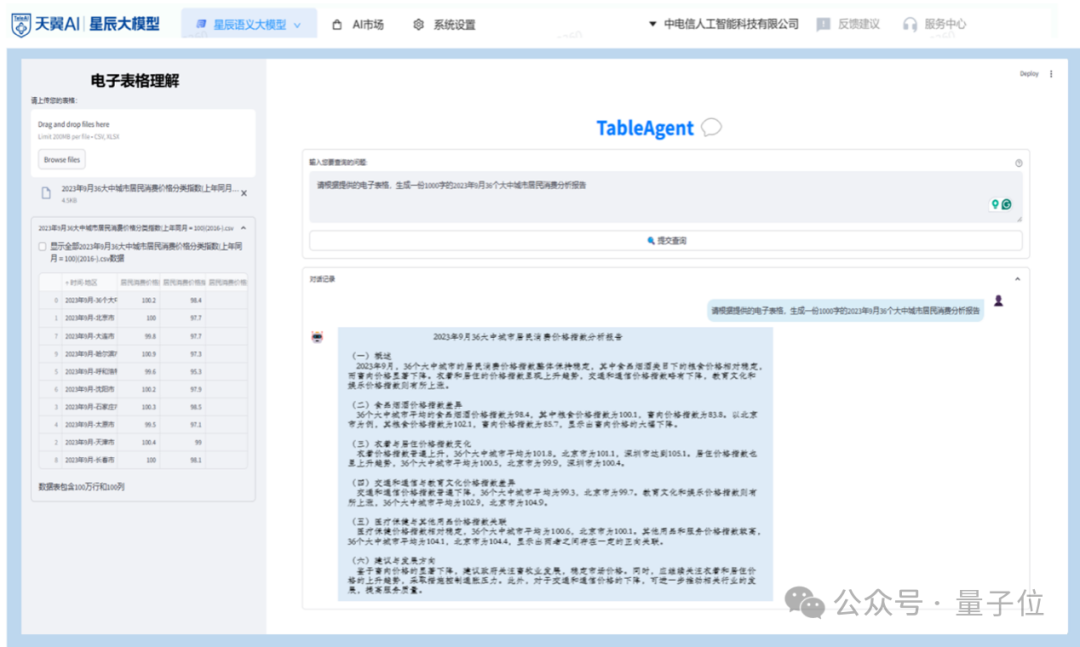
对于大型电子报表,星辰语义大模型还支持报表生文、报表问数、报表摘要、报表对应报告的风格化仿写等功能。
是百万行数据都可以轻松 hold 住的那种!
需要明确的一点是,实现万卡万参并非是一件易事,单单是全国产化的实现难度就是显而易见的。
首先的难点,便是提升万卡集群性能和稳定性。
为了提升训练性能,TeleAI 采用了多维混合并行,可以通过设置不同的并行模式,实现数据并行、模型并行和流水线并行的自动混合使用,支持万亿模型万卡集群高效分布式训练。
在本次训练中还采用以下关键技术进一步提升训练性能:
最终,国产算力万卡集群性能超过对应 GPU 93% 以上。
除此之外,为了提升训练稳定性,通过上线训练集群断点续训、CCAE 集群监控并快速隔离故障节点、多级存储优化等方法,达成集群98%的稳定可用,断点续训成功率 90%以上,单次断点续训时长 15min 左右。

其次的挑战,便是在于训练万亿参数的大模型。
在进行超大参数模型训练过程中,TeleAI 通过大量小模型训练对 Scaling Law(尺度定律)展开探索,对每个模型的噪声空间进行分析,构造正激励噪声来强化训练过程中的噪声管理。正激励噪声作为训练超大参数模型的核心技术,帮助研究人员确定最优模型结构,从而提高模型的整体能力与鲁棒性。
为此,TeleAI 采用了“四步走”策略。
首先在模型构建方面,利用多项技术进行优化。
其一,在位置编码方面,采用 Rotary Embedding 的位置编码方法,该方法具备出色的位置外推性,并且能够与 attention 计算加速技术良好配合,从而大幅提升模型的训练速度。
其二,激活函数层面,选用 SwiGLU 激活函数替代 GELU 激活函数。在实验过程中,TeleAI 也证实了 SwiGLU 相较于其他激活函数,拥有更好的模型拟合效果。
其三,层标准化环节,运用基于 RMSNorm 的 Pre-Normalization 。实验发现,该算法在训练进程中具有更佳的稳定性。
其四,将词嵌入层(embedding)与输出 lm head 层参数解耦。实验表明,这样做能够增强训练稳定性和收敛性。
其五,在大参数模型(TeleChat2-115B)上应用 GQA,可提高模型训练和推理性能。GQA 能大幅降低模型推理过程中的显存使用量,显著提升模型外推长度和推理性能。
此外,在基础训练数据构建方面,TeleAI 在工程实践中借助多级先导模型展开细致的追随训练以及数据调整实验,对数据清洗及数据混合策略的有效性予以充分评估验证。
其一,在数据清洗方面,运用语种识别、数据去重、文本格式规范化、无关内容过滤、低质内容过滤等手段来提升预训练数据质量。
同时,建设多模态结构化文档解析工具,有效提取公式和表格内容。实验发现,经过数据清洗后,模型训练损失更低,学习速度更快,能够节约 43% 的训练时间。
其二,关于数据混合,采用在线领域采样权重调整算法。在先导模型训练过程中,依据不同数据集的样本损失分布动态更新采样权重,进而获得效果最优的数据混合策略。
在模型训练初期,还会根据评测指标变化情况持续调整配比方案。实验表明,增加中文数据比例、增大数学与题库数据比例,有助于提升模型的文本理解和考试能力。
其三,在数据合成方面,针对数学、代码等特定领域任务,梳理细粒度的知识点体系,并构建复杂指令让大模型生成知识密度高的合成数据,例如试题解析过程、代码功能解释、代码调用关系等。

接下来便是SFT(模型微调)专项优化。
在低质量过滤方面,运用模型困惑度(PPL)、指令追随难度(IFD)以及可学习度(Learnability)等指标来衡量单条样本的回答难度,进而自动筛选并过滤掉文本格式规范性差、答案标注错误的样本。
对于高质量构建,将 SFT 划分为逻辑、认知、理解三个能力维度及二十多个子类。通过预先制定的标准评测集,定向筛选出对单项能力指标提升影响最大的高质量数据。
同时,提出基于黄金模板构建问答数据的两阶段标注方案,从规范性、新颖性、逻辑性、丰富性、完整性等维度总结每类问题的最佳模板,再依据模板标注符合要求的最佳答案。
在效果选择上,基于模型困惑度指标,能够快速评估不同版本的模型在小规模验证集上的拟合程度,从而挑选出表现较好的版本,以此降低计算成本。
然后是偏好对齐。
为最大程度确保指令数据的全面性与均衡性,TeleAI 分类并收集了涵盖总共300个类别的指令数据集。同时,为获取更高质量的指令数据,运用聚类和中心选择算法,从中挑选出具有代表性的指令。
随后,TeleAI 把来自不同训练阶段、不同参数大小的 TeleChat 系列模型的回复,按照安全性、事实性、流畅性等多个维度,归为高质量、中质量、低质量三个不同标签,形成 pair-wise 数据,用于奖励模型的训练。
DPO 算法因工程实现简便、易于训练而被广泛应用,在 TeleChat 训练阶段也采用了这一策略。在数据构建阶段,TeleAI 使用指令数据对当前 Chat 模型进行10至15次推理采样,并利用奖励模型对每个回复进行打分。
TeleAI 采用 West-of-N 的方式构建pair数据,即将模型回答的最高分作为 chosen response,最低分作为 rejected response,以此确保pair数据具有较强的偏好差别。
在训练阶段,除了使用常规的 DPO 损失函数外,TeleAI 还通过实验发现,引入对 chosen repsonse的NLL Loss(负对数似然损失),能够有效稳定 DPO 训练的效果,防止 chosen response 的概率降低。
最后,便是基于知识图谱降低语义大模型事实类幻觉。
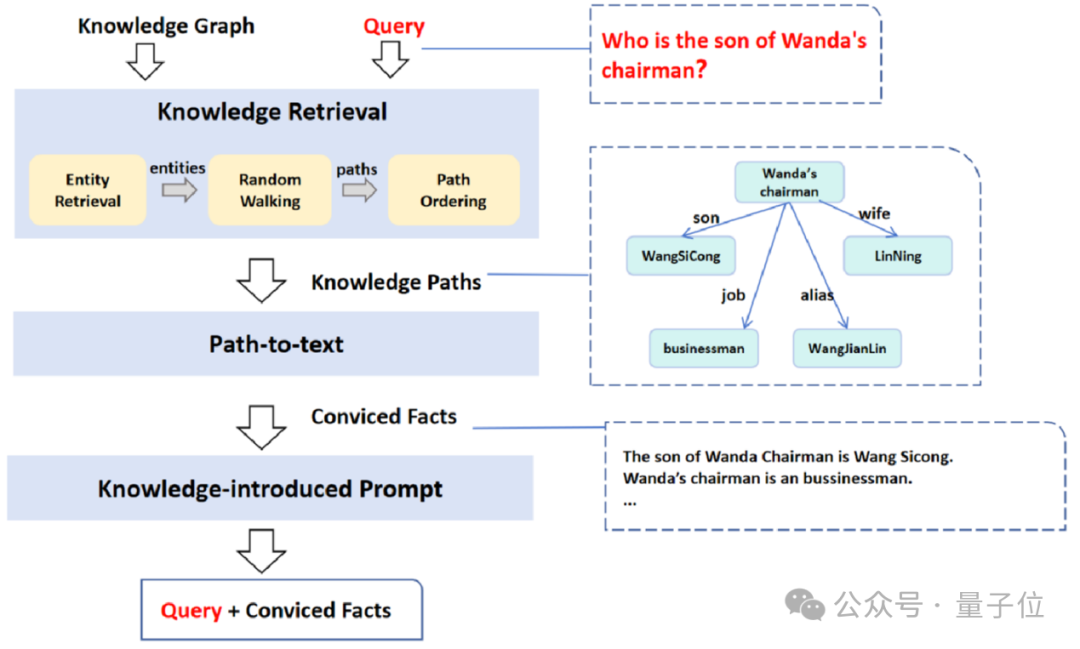
具体而言,TeleAI 是基于图谱结构化信息表示,将知识引入到问题提示中:根据与查询 n-gram 相似度检索候选实体,随后以此为基础进行随机游走,并计算游走路径与用户原始问题的相关性,选择 top 路径内容扩充至用户原始问题。
以上便是 TeleAI “炼”万卡万参的关键过程了。
不过现在还有一个问题值得探讨一下:
其实 TeleAI 在大模型上的布局并非是一蹴而就,实则是已有很长时间的打磨。
首先,是在态度上予以高度重视。
除了星辰 AI 大模型之外,在去年 11 月举行的数字科技生态大会上,TeleAI 还发布了12个行业大模型,并且推出了 “星辰MaaS生态服务平台”,以此实现定制化服务。
而这所有的一切,都是基于中国电信历经十年的 AI 能力建设。
其次,有人才方能有行业大牛助力。
为了搭建星辰 AI 大模型,中国电信迅速组建起一支近800人的研发团队。团队成员来自国内外顶尖高校,诸如清华、北大、斯坦福以及哥伦比亚等,平均年龄为31.79岁。
这批优秀人才助力中国电信在对内对外业务中取代外部算法能力,实现核心算法能力的自主可控。
在广泛吸纳基础人才的同时,中国电信也拥有一批行业大牛。其中,去年年底全职加盟中国电信集团担任 CTO 以及首席科学家的李学龙便是其中之一。
作为 AI 领域 Fellow 大满贯选手,李学龙创新性地提出噪声分析是解决大模型等一系列人工智能问题的核心关键,他将这一思想引入到万卡万参项目中,也将带领中国电信人工智能研究院继续开展基础和前沿研究。
而在 TeleAI 成立之际,便围绕“人”、“工”两大要素来重点打造。
据了解,TeleAI 现已引入多位海外TOP高校的教授、国内知名企业的 CTO 或科学家、科研机构的青年人才、以及拥有高影响力开源成果的天才学生。
而且还不止于 AI 和大模型,中国电信在很多技术上都进行了投入,并且也取得了同行优势,这也正是“工”为基所体现的点。
例如量子通信,中国电信不久前发布了具备“量子优越性”能力的“天衍”量子计算云平台,此前还开通了国内规模最大、用户最多、应用最全的量子保密通信城域网,并主导制定了中央企业第一牵头立项的7项量子通信行业标准(含团标)中的5项。
再例如在新一代信息通信技术上,中国电信实现“手机直连卫星”全面商用,发布了全球首个支持消费级 5G 终端直连卫星双向语音和短信的运营级产品。
由此可见,中国电信早已不是大家眼中的传统运营商,在前沿技术上的投入,是比我们认知要深得多。
这也就不难理解,为什么 TeleAI 可以率先做到万卡万参了。
文章来源于“量子位”,作者“金磊”




【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
