
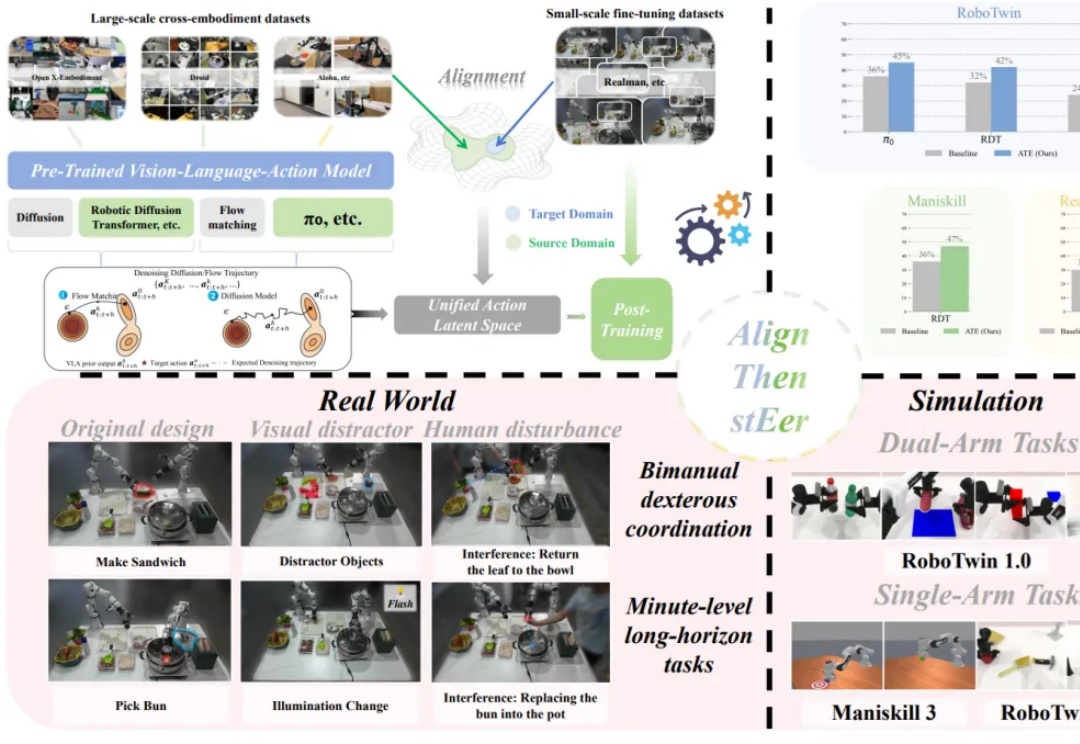
具身VLA后训练:TeleAI提出潜空间引导的VLA跨本体泛化方法
具身VLA后训练:TeleAI提出潜空间引导的VLA跨本体泛化方法在多模态大模型的基座上,视觉 - 语言 - 动作(Visual-Language-Action, VLA)模型使用大量机器人操作数据进行预训练,有望实现通用的具身操作能力。
来自主题: AI技术研报
7112 点击 2025-09-08 15:20
在多模态大模型的基座上,视觉 - 语言 - 动作(Visual-Language-Action, VLA)模型使用大量机器人操作数据进行预训练,有望实现通用的具身操作能力。
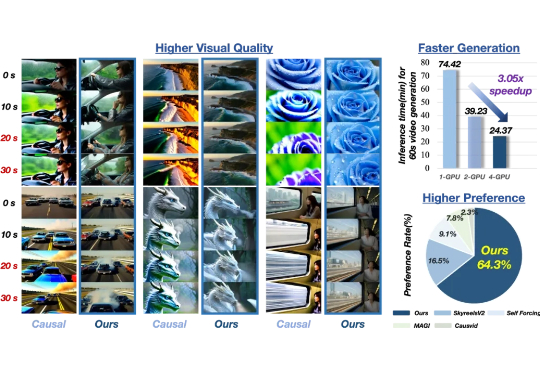
你是否曾被 AI 生成视频的惊艳开场所吸引,却在几秒后失望于⾊彩漂移、画面模糊、节奏断裂? 当前 AI 长视频⽣成普遍⾯临 “高开低走 ” 的困境:前几秒惊艳夺⽬ ,之后却质量骤降、细节崩坏;更别提帧间串行生成导致的低效问题 —— 动辄数小时的等待,实时预览几乎难以企及。

有点意思,能让香农和图灵又握上一次手的,竟然是一家央企。

与3D物理环境交互、适应不同机器人形态并执行复杂任务的通用操作策略,一直是机器人领域的长期追求。
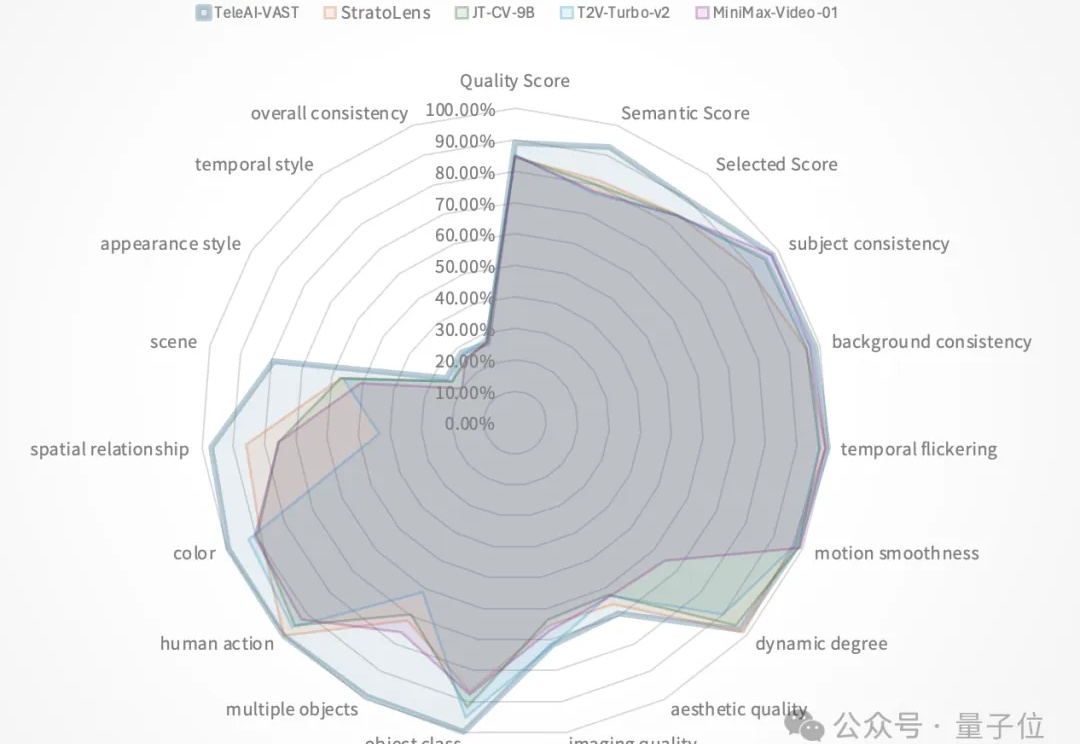
视频生成模型评测权威榜单VBench,突遭“屠榜”。

高难度武打视频,也能「手拿把掐」。

中国人民大学高瓴人工智能学院 GeWu 实验室、朝闻道机器人和 TeleAI 最近的合作研究揭示并指出了 “模态时变性”(Modality Temporality)现象,通过捕捉并刻画各个模态质量随物体操纵过程的变化,提升不同信息在具身多模态交互的感知质量,可显著改善精细物体操纵的表现。论文已被 CoRL2024 接收并选为 Oral Presentation。

TeleAI 李学龙团队提出具身世界模型,挖掘大量人类操作视频和少量机器人数据的共同决策模式。

首个由万卡集群训练出来的万亿参数大模型,被一家央企解锁了。

近年来,大模型在人工智能领域掀起了一场革命,各种文本、图像、多模态大模型层出不穷,已经深深地改变了人们的工作和生活方式。