# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
本文作者来自于中国人民大学,深圳朝闻道科技有限公司以及中国电信人工智能研究院。其中第一作者冯若轩为中国人民大学二年级硕士生,主要研究方向为多模态具身智能,师从胡迪教授。
引言:在机器人操纵物体的过程中,不同传感器数据携带的噪声会对预测控制造成怎样的影响?中国人民大学高瓴人工智能学院 GeWu 实验室、朝闻道机器人和 TeleAI 最近的合作研究揭示并指出了 “模态时变性”(Modality Temporality)现象,通过捕捉并刻画各个模态质量随物体操纵过程的变化,提升不同信息在具身多模态交互的感知质量,可显著改善精细物体操纵的表现。论文已被 CoRL2024 接收并选为 Oral Presentation。

人类在与环境互动时展现出了令人惊叹的感官协调能力。以一位厨师为例,他不仅能够凭借直觉掌握食材添加的最佳时机,还能通过观察食物的颜色变化、倾听烹饪过程中的声音以及嗅闻食物的香气来精准调控火候,从而无缝地完成烹饪过程中的每一个复杂阶段。这种能力,即在执行复杂且长时间的操作任务时,灵活运用不同的感官,是建立在对任务各个阶段全面而深刻理解的基础之上的。
然而,对于机器人而言,如何协调这些感官模态以更高效地完成指定的操作任务,以及如何充分利用多模态感知能力来实现可泛化的任务执行,仍是当前尚未解决的问题。我们不仅需要使模型理解任务阶段本身,还需要从任务阶段的新角度重新审视多传感器融合。在一个复杂的操纵任务中完成将任务划分为不同阶段的一系列子目标的过程中,各个模态的数据质量很可能随任务阶段而不断变化。因此,阶段转换很可能导致模态重要性的变化。除此之外,每个阶段内部也可能存在相对较小的模态质量变化。我们将这种现象总结为多传感器模仿学习的一大挑战:模态时变性(Modality Temporality)。然而,过去的方法很少关注这一点,忽视了阶段理解在多传感器融合中的重要性。
本文借鉴人类的基于阶段理解的多感官感知过程,提出了一个由阶段引导的动态多传感器融合框架 MS-Bot,旨在基于由粗到细粒度的任务阶段理解动态地关注具有更高质量的模态数据,从而更好地应对模态时变性的挑战,完成需要多种传感器的精细操纵任务。

在复杂的操作任务中,各传感器数据的质量可能会随着阶段的变化而变化。在不同的任务阶段中,一个特定模态的数据可能对动作的预测具有重大贡献,也可能作为主要模态的补充,甚至可能几乎不提供任何有用的信息。
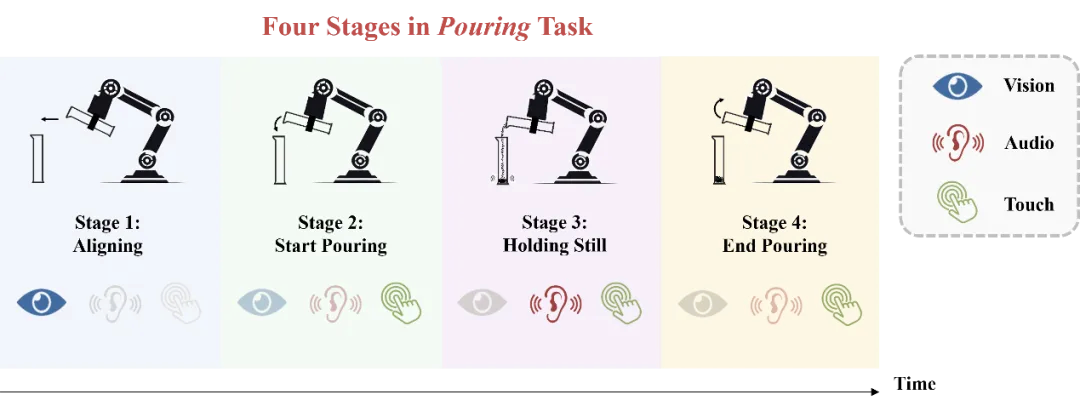
图 1 倾倒任务的模态时变性
以上图中的倾倒任务为例,在初始的对齐阶段中,视觉模态对动作的预测起决定性作用。进入开始倾倒阶段后,模型需要开始利用音频和触觉的反馈来确定合适的倾倒角度(倒出速度)。在保持静止阶段,模型主要依赖音频和触觉信息来判断已经倒出的小钢珠质量是否已经接近目标值,而视觉几乎不提供有用的信息。最后,在结束倾倒阶段,模型需要利用触觉模态的信息判断倾倒任务是否已经完成,与开始倾倒阶段进行区分。除阶段间的模态质量变化,各个阶段内部也可能存在较小的质量变化,例如音频模态在开始倾倒和结束倾倒的前期和后期具有不同的重要性。我们将这两种变化区分为粗粒度和细粒度的模态质量变化,并将这种现象总结为多传感器模仿学习中的一个重要挑战:模态时变性。
为了应对模态时变性的挑战,我们认为在机器人操纵任务中,多传感器数据的融合应该建立在充分的任务阶段理解之上。因此,我们提出了 MS-Bot 框架,这是一个由阶段引导的动态多传感器融合方法,旨在基于显式的由粗到细的任务阶段理解动态地关注具有更高质量的模态数据。为了将显式的阶段理解整合到模仿学习过程中,我们首先为每个数据集中的样本添加了一个阶段标签,并将动作标签和阶段标签共同作为监督信号训练包含四个模块的 MS-Bot 框架(如图 2 所示):
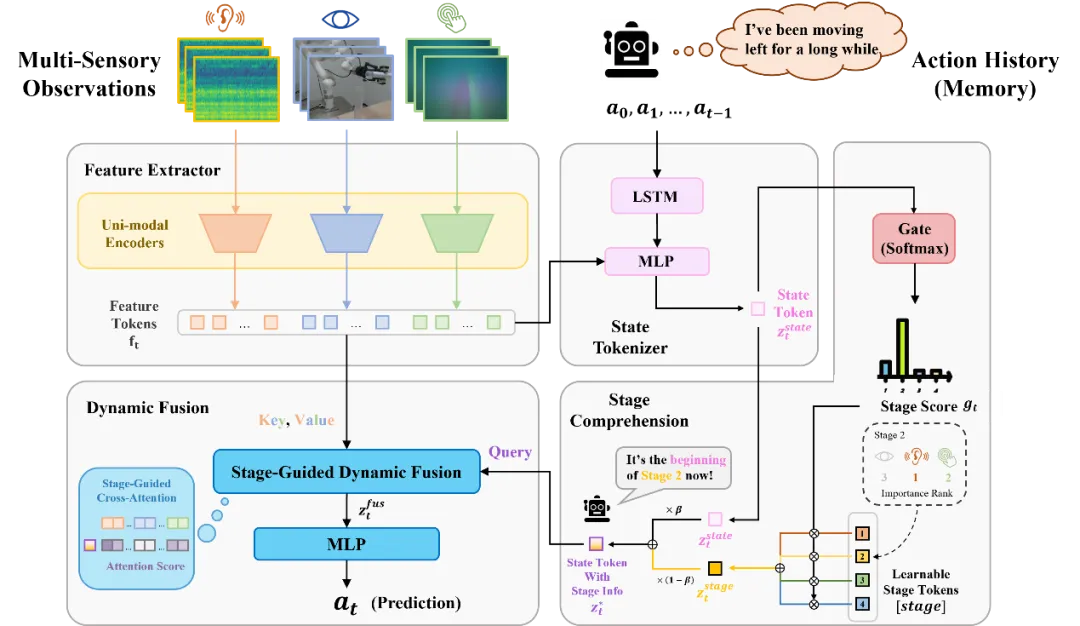
图 2 由阶段引导的动态多传感器融合框架 MS-Bot
为了验证基于由粗到细的任务阶段理解的 MS-Bot 的优越性,我们在两个十分有挑战性的精细机器人操纵任务:倾倒和带有键槽的桩插入中进行了详细的对比。
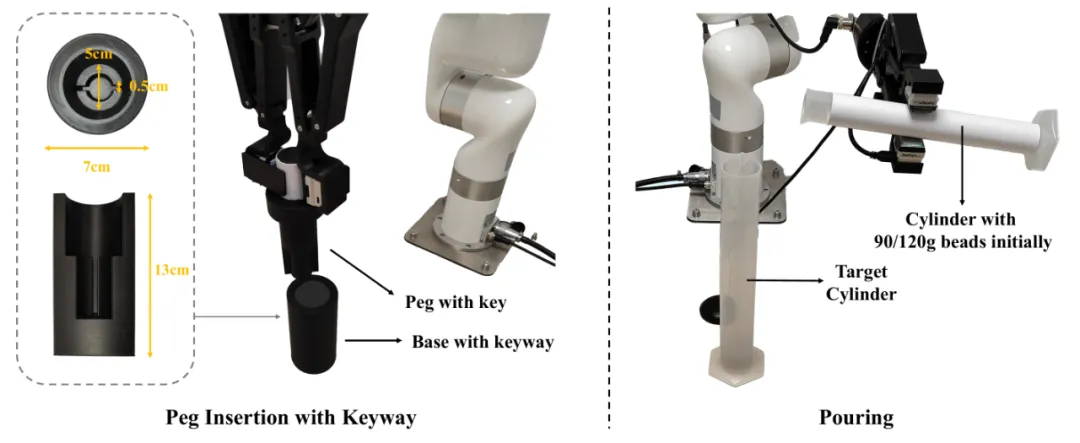
图 3 倾倒与带有键槽的桩插入任务设置
如表 1 所示,MS-Bot 在两个任务的所有设置上均优于所有基线方法。MS-Bot 在两个任务中的性能超过了使用自注意力(Self Attention)进行动态融合的 MULSA 基线,这表明 MS-Bot 通过在融合过程中基于对当前阶段的细粒度状态的理解更好地分配模态权重,而没有显示阶段理解的 MULSA 基线无法充分利用动态融合的优势。
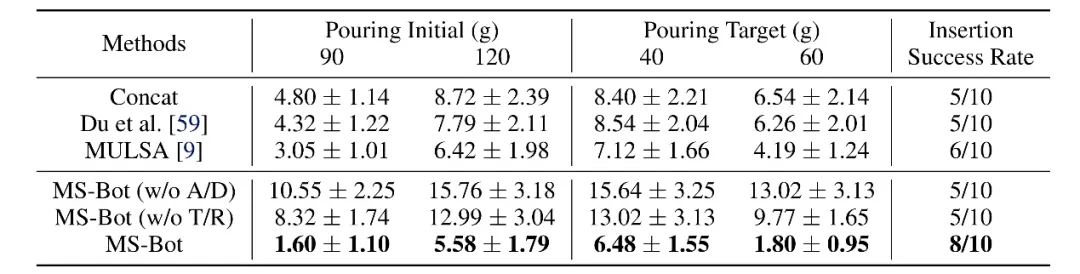
表 1 倾倒和带有键槽的桩插入任务上的性能比较
我们还对任务完成中各个模态的注意力分数和各阶段的预测分数进行了可视化。在每个时间步,我们分别对每种模态的所有特征 token 的注意力分数进行平均,而阶段预测分数是 Softmax 归一化后的门控网络输出。如图 4 所示,MS-Bot 准确地预测了任务阶段的变化,并且得益于模型中由粗到细粒度的任务阶段理解,三个模态的注意力分数保持相对稳定,表现出明显的阶段间变化和较小的阶段内调整。
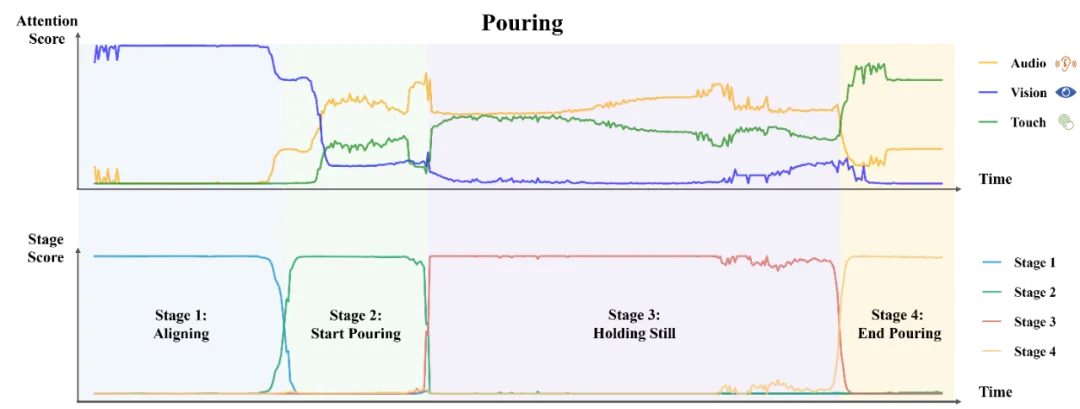
图 4 各模态注意力分数和阶段预测分数可视化
为了验证 MS-Bot 对干扰物的泛化能力,我们在两个任务中都加入了视觉干扰物。在倾倒任务中,我们将量筒的颜色从白色更改为红色。对于桩插入任务,我们将底座颜色从黑色更改为绿色(“Color”),并在底座周围放置杂物(“Mess”)。如表 2 所示,MS-Bot 在各种有干扰物的场景中始终保持性能优势,这是因为 MS-Bot 根据对当前任务阶段的理解动态地分配模态权重,从而减少视觉噪声对融合特征的影响,而基线方法缺乏理解任务阶段并动态调整模态权重的能力。
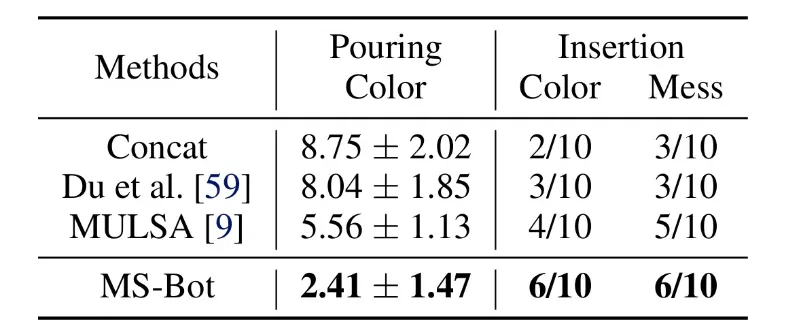
表 2 含视觉干扰物场景中的性能比较
本文从任务阶段的视角重新审视了机器人操纵任务中的多传感器融合,引入模态时变性的挑战,并将由子目标划分的任务阶段融入到模仿学习过程中。该研究提出了 MS-Bot,一种由阶段引导的多传感器融合方法,基于由粗到细粒度的阶段理解动态地关注质量更高的模态。我们相信由显式阶段理解引导的多传感器融合会成为一种有效的多传感器机器人感知范式,并借此希望能够激励更多的多传感器机器人操纵的相关研究。
文章来自于微信公众号 “机器之心”



