# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
引言:TeleAI 李学龙团队提出具身世界模型,挖掘大量人类操作视频和少量机器人数据的共同决策模式。
当你在绿茵场上进行一场紧张刺激的足球比赛时,大脑会像一位精明的导演,不断地在脑海中预演着比赛的下一步发展。你会想象如何带球突破对方防线、如何与队友配合制造进球机会等。
这种内心的想象是基于丰富的比赛经验、对足球规则的深刻理解以及对队友特点的熟悉。
大脑能够迅速从记忆中提取信息,结合当前的比赛状况,预测未来可能出现的场景,并以近乎动画的形式在脑海中迅速闪现,帮助人类做出更好的决策。
正如足球比赛中展现的一样,大脑的预演能力实际上是一个精简版的“世界模型”,通过模拟未来可能发生的情景来指导人类行为。
受此启发,具身智能研究中有望通过构建类似的“视频预测模型”作为机器人“世界模型”,通过历史序列和实时观测,预测未来可能发生的事件,形成对机器人未来行为的视频预测。
世界模型给机器人提供了一个“内心预演”的工具,能够在实际采取行动之前评估可能的行动方案及后果,帮助机器人进行决策。
近期,中国电信集团CTO、首席科学家、中国电信人工智能研究院(TeleAI)院长李学龙教授带领团队基于长期以来在扩散噪声、正激励噪声、张量噪声等噪声分析的基础上,对具身世界模型构建中的样本效率难题进行了深入研究,在少样本驱动的具身世界模型构建方面迈出了重要的一步。
这项工作提出了全新的具身视频噪声扩散模型的训练方法,通过充分挖掘大量人类操作视频和机器人操作的共同模式,在仅使用少量具身数据的情况下训练高效的具身世界模型。
论文由TeleAI院长李学龙教授、TeleAI研究科学家白辰甲博士联合香港科技大学、上海交通大学、上海人工智能实验室等单位共同完成,近期被国际人工智能顶会NeurIPS 2024录用,HKUST在读博士何浩然为该论文的第一作者。

构建通用的机器人世界模型是一项长期的挑战。尽管以Sora为代表的视频生成模型在通用视频生成中有出色的表现,但依赖于对大规模视频数据集学习。
然而,在具身智能领域,高质量的机器人操作视频的获取是非常困难的,且不同类型的机器人数据难以通用。具身世界模型的学习非常具有挑战性,亟需一种通过少量数据学习的通用具身世界模型构建方法。
本研究提出,能否利用在其他相似领域的大规模视频数据,特别是人类操作视频来帮助学习具身世界模型?人类在现实场景中第一视角的物体操作视频和机器人操作任务具有高度的相似性,包含了物理世界的交互信息,并具有多元的任务场景、复杂的视觉背景、多样的物体类型,能够帮助具身世界模型学习物体操作的先验知识。
近期部分工作开始利用人类操作数据来策略学习,然而局限于从人类视频中提取图像表征或Affordance区域,忽略了人类操作视频中蕴含的丰富的时序信息的行为决策信息,不同于现有方法,本研究提出构建基于人类操作的视频预测(video prediction)来进行世界模型构建,同时通过少量含有动作的机器人数据获得可执行的策略,充分挖掘在人类操作视频和机器人数据上统一的决策行为模式。
为了有效利用大量人类数据,本方法设计了预训练(pre-training)和微调(fine-tuning)的框架,前者可以遵循scaling law快速扩展到大规模的人类操作视频数据集,后者可以利用少量机器人数据快速迁移至下游任务。整体框架如图1所示。
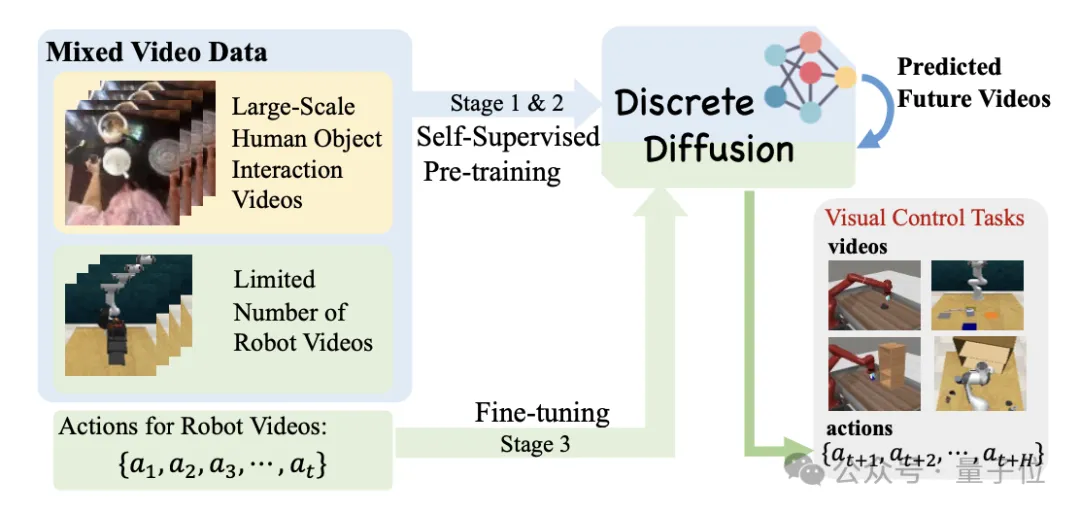
本方法从大规模人类操作数据集(如Ego4d)中学习统一的视频表征,使用大量无动作视频构建自监督的视频预测扩散模型作为预训练任务,并在少量有动作标记的具身数据上进行高效策略微调,能够使通用人类操作视频中编码的物理世界先验知识适应于具身环境模型构建,在下游任务中利用少量机器人轨迹即可在通用机械臂操作任务集合中获得优异的性能。
本文方法从三个方面利用人类操作数据构建具身世界模型,实现高效的具身策略学习:
为了从数据分布极广的各类视频数据中提取有效的信息输入进行世界模型构建,提出构建人类视频和机器人视频统一的视频编码。
使用VQ-VAE将高维视频片段压缩成信息丰富的离散化潜在token,不仅为混合视频提供了统一的码本,还减轻了人类和机器人视频之间的域差异。通过将连续特征转换为离散空间,提取出人类和机器人操作的共同模式。
此外,通过统一的动作离散化方法将动作空间的连续维度离散化成有序的整数,使机器人的动作可以通过离散的token来表示,为后续的预训练和微调阶段提供了便利。
通过这种方式,能够将人类视频中的动态行为模式和机器人的动作指令统一起来,构建出一个能够处理大规模视频数据并提取有用特征的框架。见图2第一阶段所示。
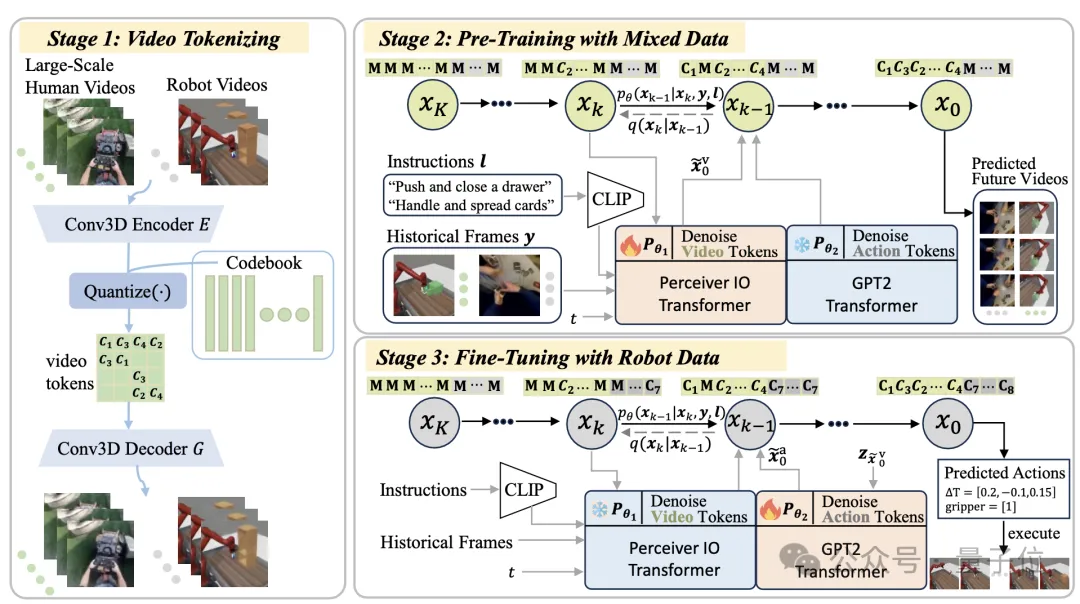
在视频预测模型的训练阶段,利用离散扩散模型从大量人类视频中提取与物理交互有关的普适知识。具体的,给定一段历史视频和文本作为 prompts,利用大规模扩散模型预测未来视频 token 序列。
当模型能很好地理解交互模式并预测到准确的未来轨迹时,智能体能够对未来可能发生的行为进行预估,从而用该信息去指导下游任务的决策过程。
为了处理信息量丰富的离散视频编码,并且支持提出的预训练及微调的两阶段训练模式,提出表达力极强的离散扩散模型(Discrete Diffusion)架构进行视频建模。
模型训练中通过引入一个掩码和替换的扩散策略,能够学习到视频中的动态变化规律,并生成在潜在空间中具有连贯性的未来视频token。
这一过程不仅涉及对视频内容的理解,还包括对视频上下文的深入分析,从而为机器人策略学习提供了丰富的先验知识。见图2第二阶段所示。
通过从大规模人类数据集中学习世界模型,模型已经编码了的普适的视频预测模式,在下游机器人任务中仅需要依赖少量机器人数据就能够快速的学习策略。
具体的,提出了基于少量样本的微调策略,通过冻结预训练模型并仅调整动作学习网络的参数,能够在有限的机器人数据集上快速适应并预测动作序列。
在预训练阶段模型使用Perceiver Transformer作为噪声扩散模型的主干网络,在微调阶段使用 GPT2作为主干网络以便于在小规模机器人数据集中进行策略学习。
这一微调过程有效地将从人类视频中学到的丰富视频预测知识转移到机器人控制任务中,显著提高了机器人在多任务操作中的性能和样本效率。见图2第三阶段所示。
本方法在单视角视觉观测的机械臂操作任务集和使用多视角观测的3D操作任务集合中评估有效性。
结果发现,论文提出的方法可以在人类物体操作和机器人物体操作中成功预测准确的未来运动轨迹,无论是单视角还是多视角,这些都通过一个离散扩散模型生成。
下方视频显示了方法在合成人类操作视频方面的效果。在复杂的人类物体操作场景中,本文方法能够精确的建模人类手部的运动细节和运动轨迹,从而在构建世界模型中为机器人末端的运动提供指导。

进而,通过人类视频和机器人视频的统一token编码,人类操作视频的预测学习能够极大的帮助模型在少量机器人视频中学习具身世界模型。下方视频显示了机器人操作任务中,本方法能够准确根据自然语言指令对机械臂未来的轨迹进行预测和规划,从而指导下一阶段的机械臂动作预测。
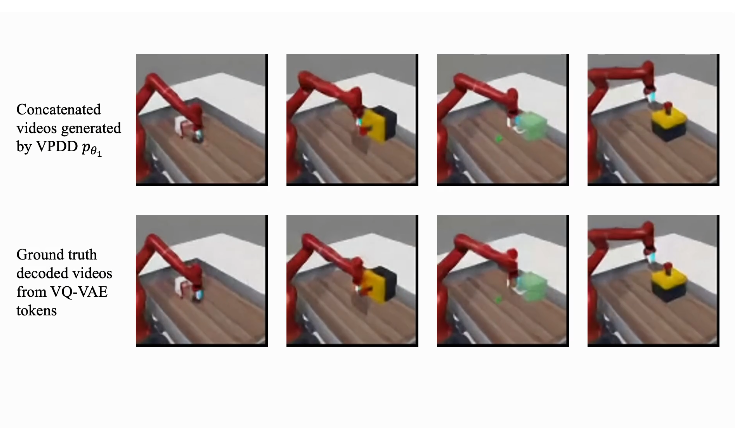
此外,通过对少量真实机械臂操作视频的学习,世界模型可以快速泛化到对真实机械臂视频产生准确的预测,从而指导真实机械臂的策略学习。

通过具身世界模型的构建,模型能够在少量带有动作标记的数据中进行快速微调,从而使模型能够产生实际的机器人动作决策序列,指导下游任务的学习。
下面显示了在RLBench任务中的策略执行效果。通过多视角的视频预测,世界模型能够全方位预测机器人的周围环境变化,从而指导机器人在三维空间中进行复杂的任务决策。


该成果提出了一种少样本的高效具身世界模型架构和训练方法,通过设计统一token编码、离散噪声扩散模型为基础的运动轨迹(视频)预训练、以及少量机器人数据的知识迁移和泛化,能够使用人类操作视频的行为模式指导机器人进行决策,从而解决了机器人数据代价昂贵的问题。
提出的方法可以灵活地处理各种视频输入的机械臂操作任务,包括单视角2D操作、多视角相机3D操作、真实机械臂操作等,为世界模型迈向机器人做出了重要贡献。
团队负责人介绍: 李学龙,中国电信集团CTO、首席科学家,中国电信人工智能研究院(TeleAI)院长。主要关注人工智能、临地安防、图像处理、具身智能、噪声分析。

论文名称:
Learning an Actionable Discrete Diffusion Policy via Large-Scale Actionless Video Pre-Training
论文链接:
https://arxiv.org/abs/2402.14407
项目地址:
https://video-diff.github.io
文章来自于微信公众号“ 量子位”,作者“ TeleAI”




【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
